影像分割的 Foundational Model 簡介 - Segment Anything(SAM)
Kirillov et al., “Segment Anything, ” In Arxiv Preprint.
Project page: https://segment-anything.com/
Paper link: https://arxiv.org/abs/2304.02643
Demo link: https://segment-anything.com/demo
Facebook 研究團隊 FAIR 提出 Segment Anything,釋出影像分割(Segmentation)的 Foundation Model 稱作 Segment Anything Model(SAM),以及對應的訓練數據集(SA-1B),SAM 可支援不同的線索(Prompt)來預測出不同的種類的 Image Segmentation(Interactive Segmentation、Semantic Segmentation、Instance Segmentation、Foreground Segmentation 等等),在實驗中顯現 SAM 模型可以 Zero-shot 適應到訓練集沒看過的任務(如:Edge Segmentation、Object Proposal、Instance Segmentation)。
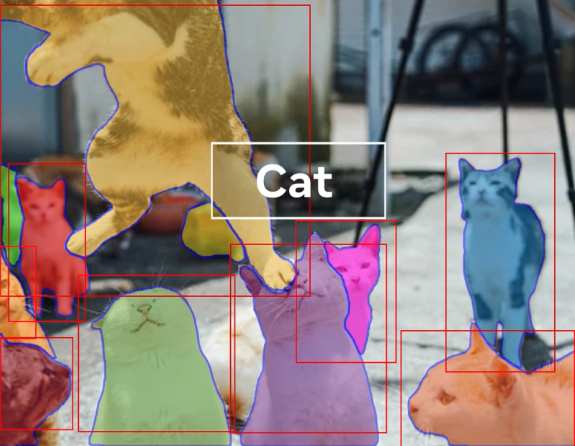
由於網路上缺乏大量的 Segmentation Dataset,因此論文中花了不少的篇幅在討論如何收集大量的資料集。雖然這篇論文才剛推出,但社群上已經有許多結合 SAM 的相關應用,如:圖像生成模型 Stable Diffusion 結合 SAM 所預測的 Mask 進行生成,更衍伸出可基於 Mask 來更改生成的類別或是顏色等等的,非常建議大家先看 Project page: Segment Anything 來玩玩看 SAM 所提供的互動式 UI 能達成怎樣的效果。

概念補充
- Foundational Model:透過訓練在大型的資料集來,並且可以適應到不同的資料集/任務。概念雖然和近年 Pre-trained Model 的概念相似,但 Foundational Model 更強調的是收集資料集的大小。此外還會希望模型具備泛化性,更準確地來說是 Zero-shot 的能力,即便模型在訓練中沒有學習過這種任務,但透過給定適當的 Prompt 也能獲得出對應的結果。因此在設計 Foundational Model 時會探討三件事情(任務、模型、資料):
- 要學習什麼任務才可以讓模型具備 Zero-shot 的泛化性?
- 要選用什麼模型架構?
- 要怎麼收集多樣性的資料?
Prompt(線索):現有的 Foundational Model 都會提供 Prompt 來讓使用者可輸入不同種類的 Prompt 來執行不同的下游任務,而 Prompt 不僅限於文字的資訊(文字-Text)更可結合空間上的資訊(Bounding box, Point, Mask, Layout 等) 。
- Compositionality(組合性):近期的模型趨向高組合性來進行發展,像是近期有許多圖像生成模型如:DALL·E、Stable Diffusion 都結合了 CLIP 模型,因此論文中也提到希望未來 SAM 也能作為一個插件來對多個模型進行擴充,像是基於 RGB-D 的圖片去對沒看過的物件進行 3D 模型的重建,或是結合穿戴式的裝置來對視線所看的物體擷取出物體並顯示其對應的資訊。

模型設計理念
本篇在設計模型時圍繞下方三個問題
- 要學習什麼任務才可以讓模型具備 Zero-shot 的泛化性?
- 要有適當的 Objective function 來讓模型可以適應到廣泛的下游任務
- 要設計 Promptable segmentation,可以透過 Prompt 來執行 Zero-shot、Few shot 來快速適應到新的資料集以及任務
- Prompt 要支援文字以及空間的資訊
- 要選用什麼模型架構?
- 要能夠支援彈性的 Prompt,並且為了讓使用者可以即時的基於 UI 調整 Prompt,因此希望可以即時地輸出分割影像
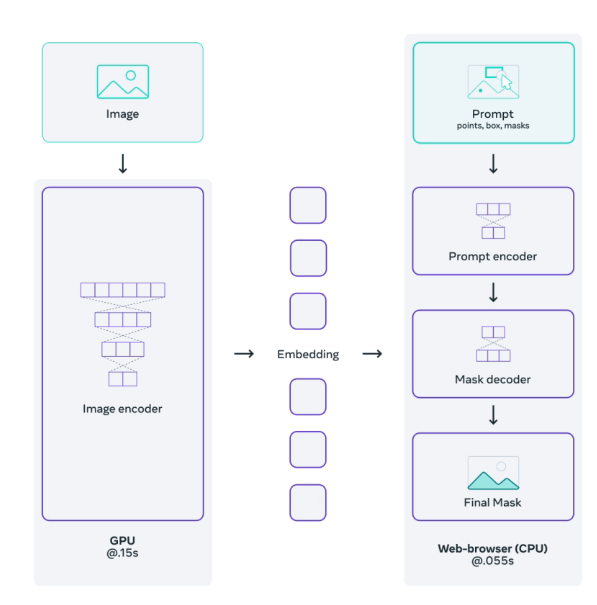
- 模型會有三個階段,圖片的特徵萃取 Image encoder、可供輸入 Prompt 的模組 Prompt encoder、預測圖像分割的結果 Mask decoder。考量互動式設計時使用者會不斷地調整 Prompt,但是 Image encoder 出來的特徵可以重複使用以及模型的好壞主要取決於強大的 Image encoder,因此認為 Image encoder 要是強大的模型,並且可交由雲端的主機進行計算,但是 Prompt encoder 以及 Mask decoder 的模型架構要要輕量化,這樣才可以透過 CPU 直接在瀏覽器上執行並運算時間要 < 50ms,這樣使用者在操作起來才不會覺得不好使用。
- 要怎麼收集多樣性的資料?
網路上並沒有這麼大規模的影像分割資料集,主要是因為標註像素等級的資料相當的費時,因此本篇提出一個 Data engine 用來收集資料,概念是先透過現有的模型先預測出影像分割的結果,再經由人進行微調,透過不斷地循環收集越來越多的資料,同時模型的準確度也會越來越準確。
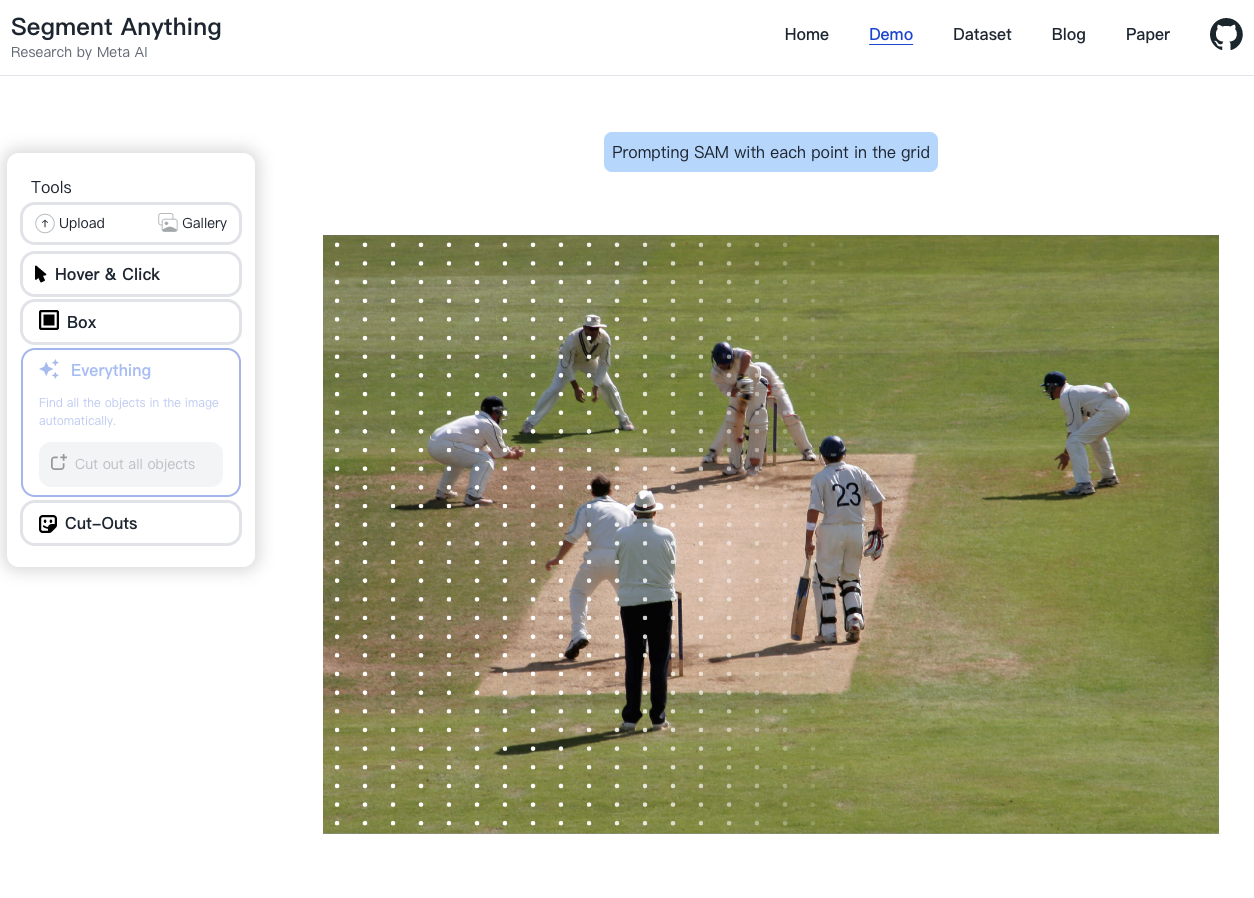
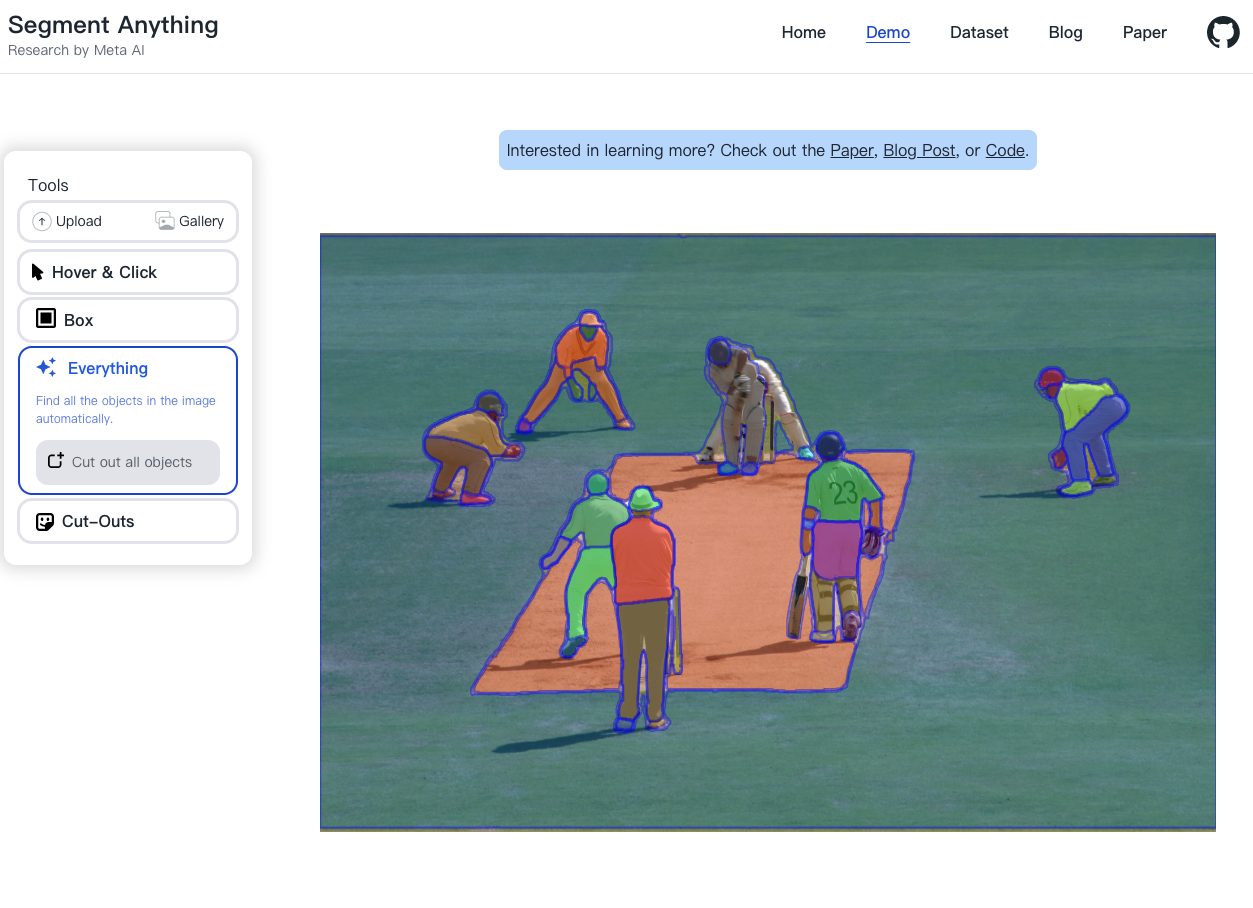
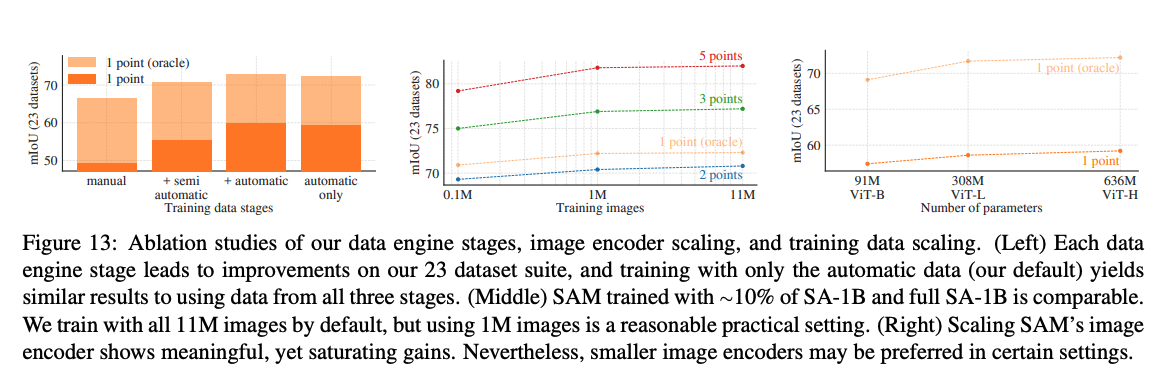
Data engine 主要可分為三個階段,輔助手動標註、半自動標註、全自動標註。第一階段為輔助手動標註,使用現有的模型進行預測,並透過互動式的方式來協助人員進行標註、第二階段透過第一階段訓練好的模型已經可以自動標註一部分的物件,此時人員再標註剩下的類別就好,第三階段 SAM 已經可以透過使用 Prompt 對於圖片中的每一個小格子來自動進行標註,可以將一張圖片分割為 32x32 的小格子,在每個格子中心標註一個 Point 視為一個 Prompt 模型就能基於那個點來生成對應的 Mask,在這個階段平均每張圖片都能自動產生出 100 個高品質的 Mask,透過這種方式不斷優化模型再不斷自動生成高品質的訓練圖片來產生一個數據收集循環,最終提出了目前為止最大的影像分割數據集 SA-1B,其中包含了10億個遮罩(Mask)和1,100萬張經過授權的圖像,影像平均的大小為 3,300 x 4,950。
在後續的實驗中表明模型約使用 100 萬張(1M)圖片訓練的準確度大概就逼近於 1,100 萬張圖片的準確度。
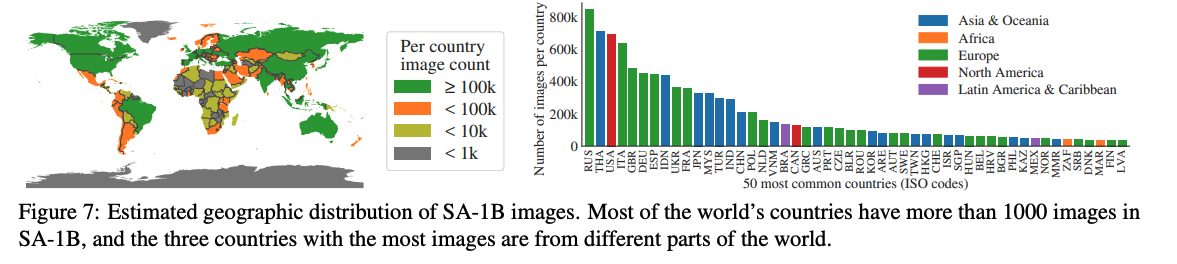
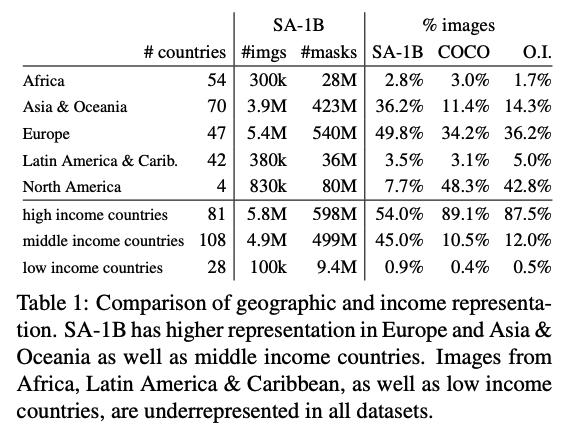
由於近年 Foundational Model 可快速適應到不同的下游任務,並且實際部署到不同場域,因此大多數的公司在模型發表前都會善盡 Responsible AI(RAI) 的責任,避免模型會有潛在的不公平,或是避免預測的結果會有錯誤、偏見,此處為了確保資料的多樣性,因此統計各個國家的圖片分佈,可以看到大多數的國家所收集的圖片都超過 1,000 張,可以發現相較於 COCO 資料集,SA-1B 的資料集在中等收入以及低收入國家所收集的資料比例佔據較多,並不像 COCO 資料集有大多數的資料比例都來自於高收入的國家。
模型架構
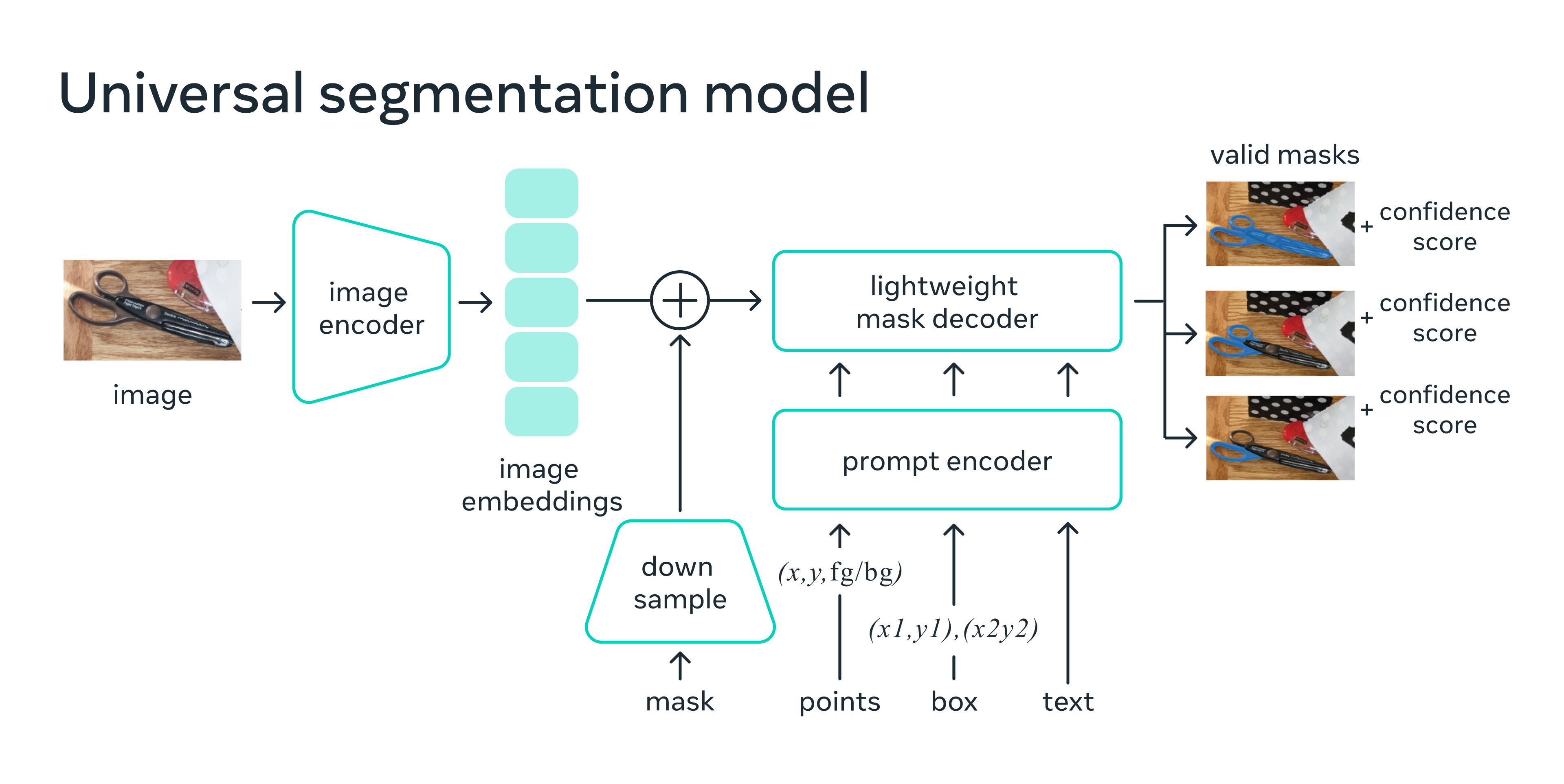
模型可分為三個階段
Image encoder 萃取圖片的特徵 Embedding,這邊使用基於 MAE(Masked AutoEncoders) 訓練好的 ViT(Vision Transformer) 作為模型,圖片基於該模組輸出後的特徵稱作 Image embeddings。
- Prompt encoder Prompt 不僅要支援文字還要支援空間的資訊,空間的資訊可以分成兩個種類稀疏(Sparse)型態的 Prompt,如 Points, boxes,以及密集(Dense)型態的 Prompt,如 Mask。這邊為了要讓使用者有良好的互動體驗,因此要降低運算時間,在轉換各個 Prompt 到 Embedding 的設計上較為簡單。
- 針對密集(Dense)型態的 Prompt,是先將 Mask 結合 Convolution 進行 Downsampling 後,成為 Mask embedding,直接與 Image embedding 相加。
- 針對稀疏(Sparse)型態的 Prompt,會基於空間上的座標進行轉換後變成 Positional embedding,再加上各自型態所學出的 embedding(Box embedding, Point embedding 等),直接與 Image embedding 相加。
- Mask decoder 參考 DETR 以及 MaskFormer 的 Mask Classification 架構,可以同時預測出 Semantic 以及 Instance-level 的影像分割結果,整體訓練方式簡單,使用 Focal Loss + Dice Loss 進行訓練。
上述其實有個細節是模型除了會學習不同型態的 Prompt Embedding(Box embedding、 Point embedding) 以外,在 Mask decoder 時也會學習不同的 Embedding,可以看做 Class 的 Token(如:iou_token、mask_tokens),概念可參考 ViT(An image is worth 16x16 words: Transformers for image recognition at scale) 的論文。
任務的困難的探討
為了要達成不同的下游應用,模型需要支援不同種類的 Prompt,如文字、物件框、點、Mask等等,甚至可以一次提供多個種類的 Prompt。像是下面的任務是 Interactive segmentation,可以點擊感興趣的位置(綠點),以及不感興趣的位置(紅點)來提取出 Mask。
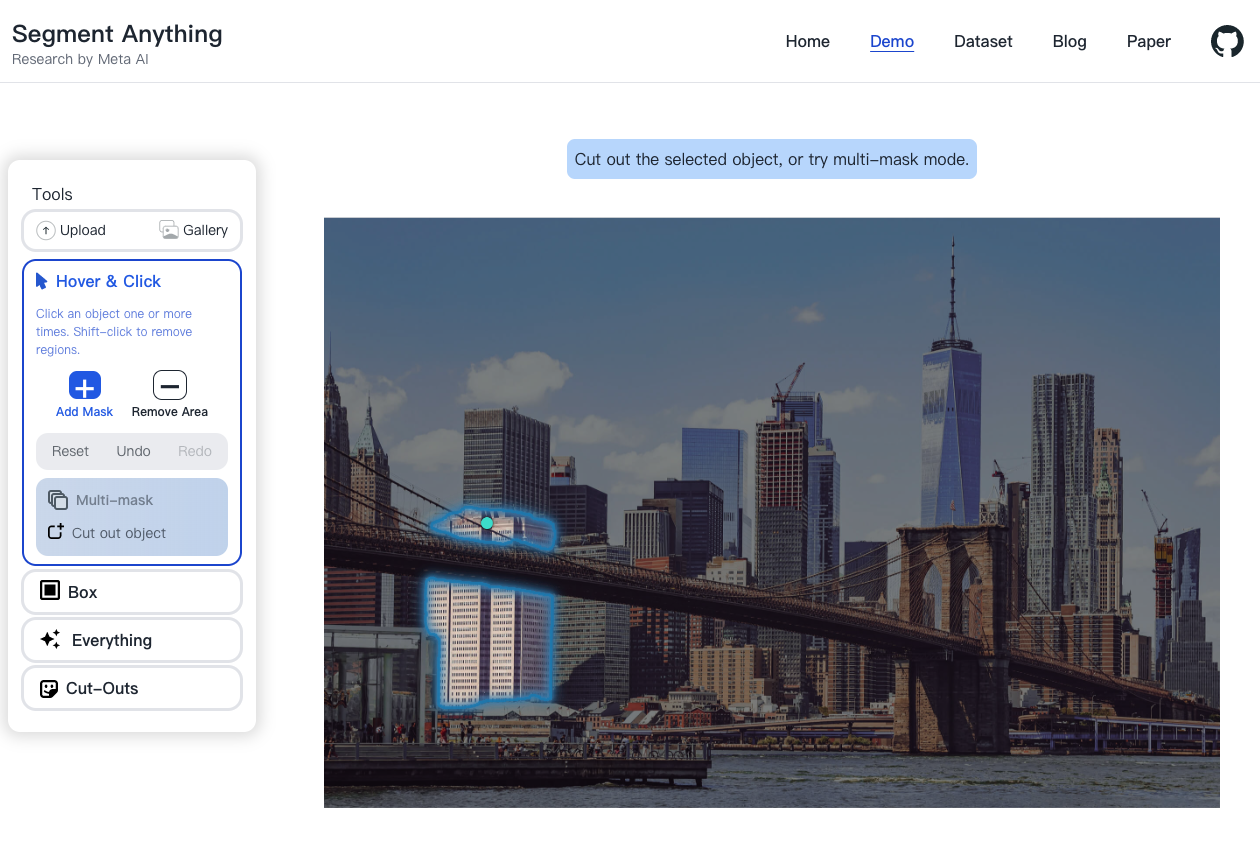
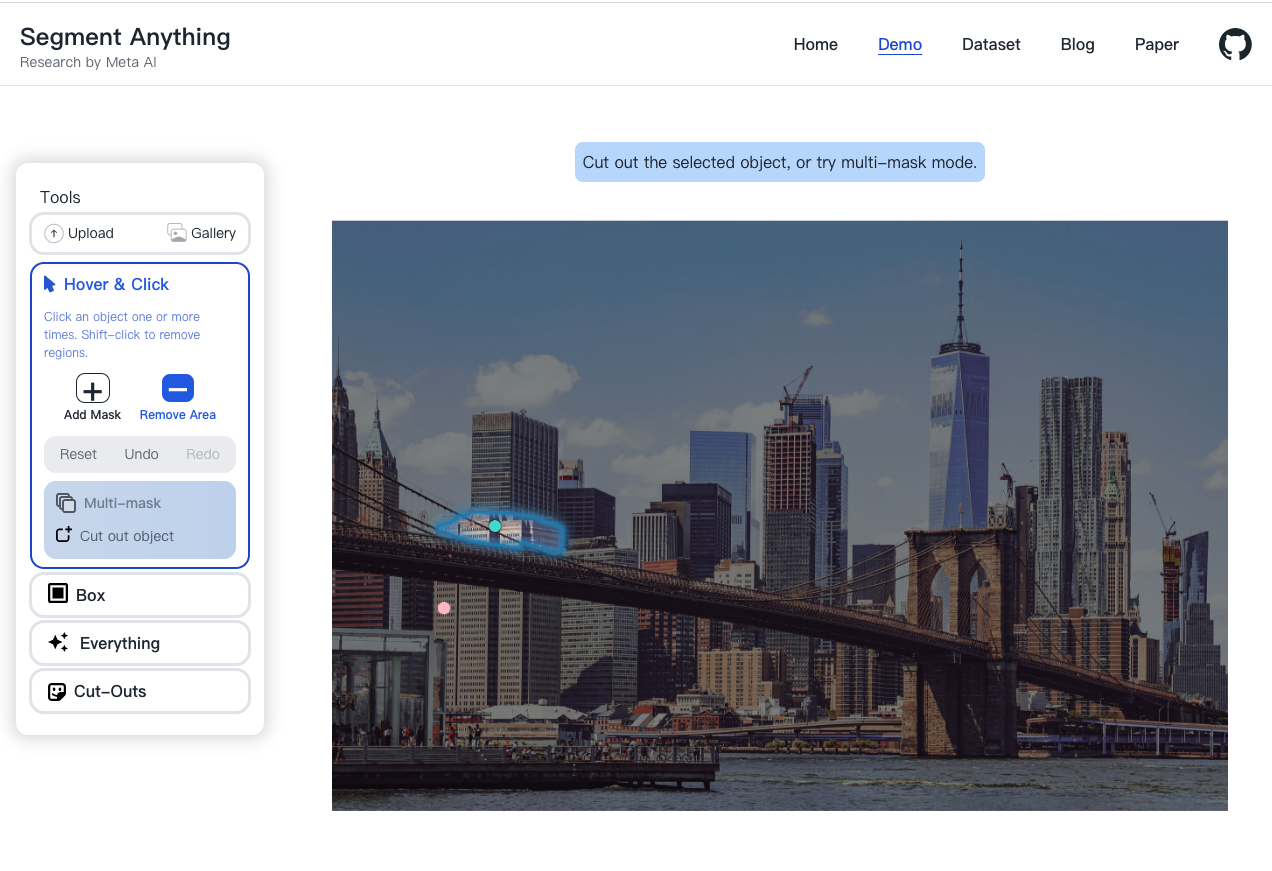
- Prompt 是模糊的提示
從下面這個例子可以看出 Prompt 所給的提示是相對模糊的,像是下面這張圖片的第三欄點選人的手臂,你可以說這個點應該是要將整個人物給框選起來,也可以說是要只要框選他的雙手,又或是只要框選他的左手。現實中的例子也有相當多,像是當一個點點在襯衫上面,那他可能代表襯衫,也可能代表穿著他的人,因此如何讓模型在訓練的時候如何應對這種模糊的情形,並且確保在面對不同的的 Prompt 都要給出正確的 Mask 是需要特別設計的。

這邊也列出部分的 Failure cases,實際在使用時常常會使用文字作為輸入,但有時候單純使用文字沒辦法獲得正確的結果,但透過結合不同種類的 Prompt 就可以獲得正確結果。

為了讓模型的生成具備一定的模糊性,模型會生成多個不同的 Mask,在訓練時只會選擇預測出的 Mask 與 Ground Truth 的 Mask 最小 Loss 的 Mask 來進行 Backpropagation,實驗中發現預測 Mask 的個數可以設定為 3,因為這 3 個不同的 Mask 往往對應到的是物體的全身、部分、細節(Whole、Part、Subpart),所以為了要讓模型知道最終的輸出到底要選擇哪個,因此有一個預測 IoU 的小模型,透過分數的高低來決定最終輸出的 Mask,因此實際訓練 Mask decoder 時還會增加一個 Mse Loss 來預測各個 Mask 與 Ground Truth 的 IoU。
訓練流程
訓練時使用了 256 個 GPU,圖片大小為 1,024 x 1,024,並且參考 Interactive Segmentation 的訓練流程,會隨機的選擇使用 Point 或是 Bounding box 作為 Prompt 的輸入,那實際的作法是從 Ground Truth 中挑選出一個物體,隨機從 Mask 的 Pixel 中亂數挑選 1~多個點或是基於物體的 Bounding box 隨機的放大 10% 作為輸入,加入適當的 Noise 來讓使用者實際在操作的時候可以保留一點彈性。訓練時不見得一次就會預測出最好的結果,因此會循序的基於前一次預測的 Mask 再加入沒預測準確的部分添加 Positive/Negative points 當作下一次的輸入,這個訓練流程確保了未來使用者基於目前的結果進行互動式的操作。
訓練時所使用到的 Loss 為 Focal + Dice + MSE,並在實驗時發現 Auxiliary deep supervision 無法改善 Decoder 的訓練成果,也沒有使用資料擴增的技巧,主因是該訓練資料集已經足夠大了,更多細節請參考論文的 Appendix。
雖然目前官方只有釋出預測的程式碼,並沒有釋出訓練的程式碼,但大家可以看看這個 blog 的說明 How To Fine-Tune Segment Anything 就是透過 MSE loss 來微調。
Zero-shot Transfer
SAM 模型可以透過結合不同的 Prompt 來獲得對應的影像分割結果,像是使用物件框框選出貓咪的本體後,模型會返回貓咪的 Mask,此時就可以看作是實例分割(Instance Segmentation)的結果。
實驗中也顯示即便是沒有訓練過的任務一樣能夠透過輸入適當的 Prompt 預測出來。
- 低階的視覺任務: 邊緣檢測(Edge Segmentation)
- 中階的視覺任務: 提取出可能的物件框(Object Proposal Generation)
- 高階的視覺任務: 實例分割(Instance Segmentation)
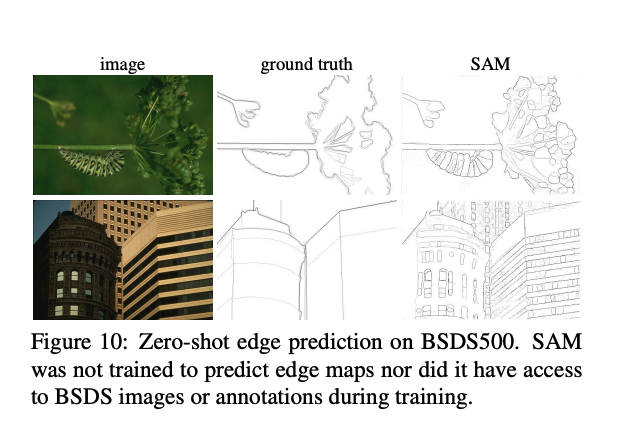

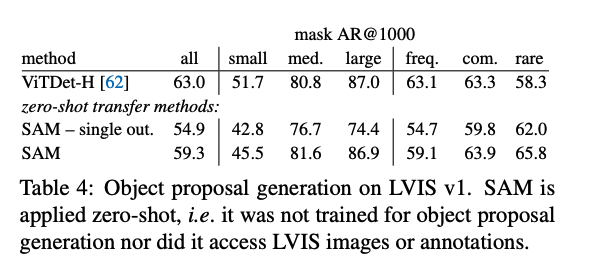
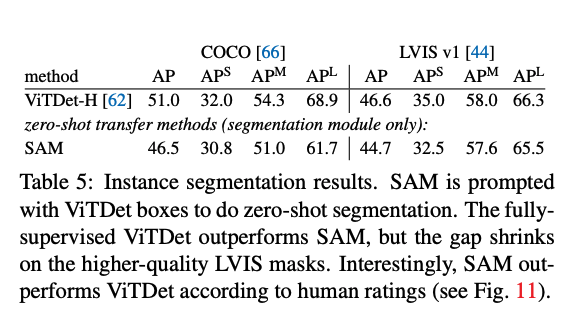
論文中參考了 Interactive Segmentation 的評估設定,透過從 Ground Truth Mask 中提取出中心點當作為 Prompt 的輸入,比較 23 種不同的資料集,會發現在大多數的任務中都能贏過 RITM

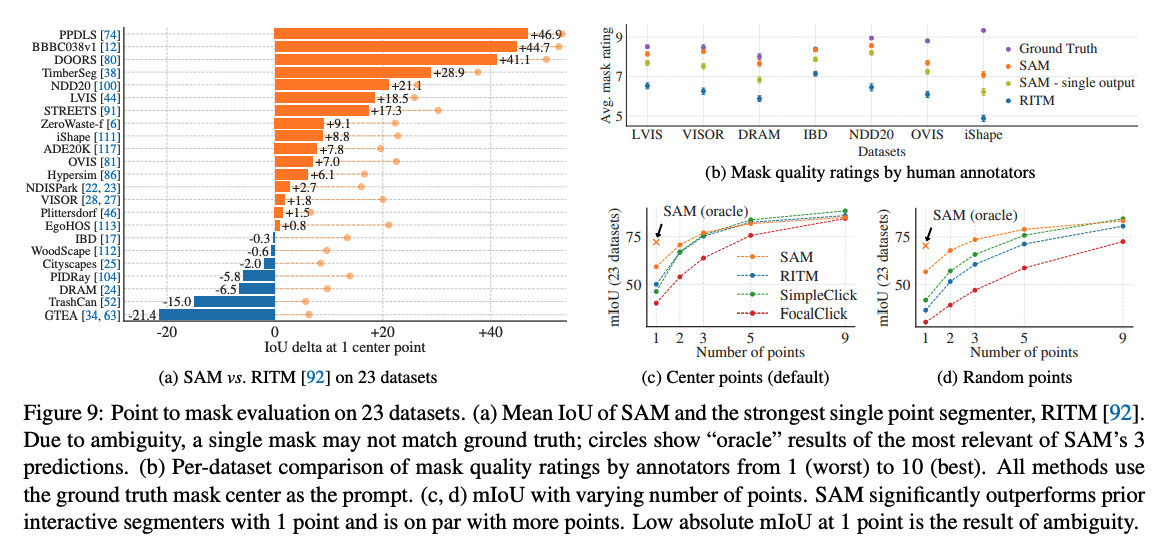
SAM 近期衍伸應用
網路上已經有許多結合 Segment-Anything 與圖像生成 AI 來對特定位置生成不同物件的應用了。
- IDEA-Research 發布 Grounded-Segment-Anything,透過結合 SAM 以及 GroundingDINO(Openset object detection)來讓使用者可以快速的了解圖片上有哪些物件以及顯示對應的 Mask,並整合圖像生成 AI 去對 Mask 來替換物件,或者是針對該衣服去替換顏色等。

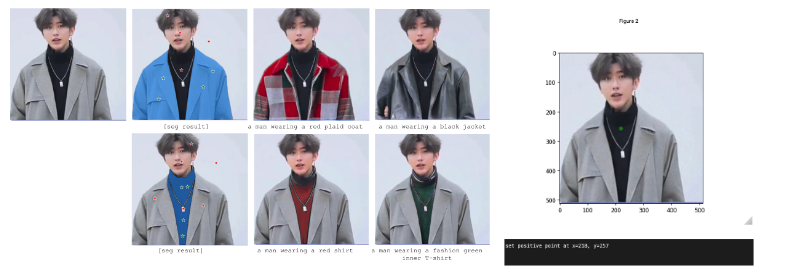
- Inpaint Anything - Inpaint Anything: Segment Anything Meets Image Inpainting 也是基於類似的流程,透過 SAM 解析出 MASK 並結合 Stable diffusion 生成圖片。
- 此外也有團隊在 SAM 論文發布後兩個禮拜發表 SAM Fails to Segment Anything? – SAM-Adapter: Adapting SAM in Underperformed Scenes: Camouflage, Shadow, and More 來說明 SAM 對於迷彩以及陰影偵測等任務表現不佳,因此提出 Adapter 的方式來微調 SAM 至特定的任務上,未來大家也能基於該方法快速適應到不同 Domain 的資料集。
Reference
Project page: Segment Anything
Introducing Segment Anything: Working toward the first foundation model for image segmentation