Yue Liao, Si Liu, Fei Wang, Yanjie Chen, Chen Qian, Jiashi Feng. PPDM: Parallel Point Detection and Matching for Real-time Human-Object Interaction Detection. In CVPR’20.
CVPR 2020 paper
Paper link: https://arxiv.org/abs/1912.12898
Github(Pytorch): https://github.com/YueLiao/PPDM
簡介
本文是針對人與物件間的關係(Human Object Interaction - HOI)的偵測任務,
這是首個可即時偵測(Real-time)的 HOI 模型,
以往的模型之所以無法達成即時偵測是因為採用 Two-stage 架構,
大致作法是先透過目標偵測模型(如 Faster RCNN)偵測出圖片中的所有目標,
再透過額外的模型來辨別/配對各個物件(假設有 M 個)與人(假設有 N 個)的交互關係,
而這樣的話就需要處理 M X N 個之間的配對關係。
而本文提出新的思維捨棄舊有架構,
提出 Single-stage 的模型 PPDM - Parallel Point Detection and Matching。
基本的概念是包含兩個平行的分支,
分別處理兩種任務偵測物件以及配對人與物件的關係。
- Point detection branch 點偵測
可把他視為取代了以往物件偵測的部分。 會預測出下方的三種資訊。
- 人的中心位置及長寬 (Human point)
- 物件的中心位置及長寬 (Object point)
- 交互的作用點位置及長寬 (Interaction point) 這邊交互點其實算是一個很特別的存在,模型會藉此理解到物體和人之間的關係 TODO
- Point matching branch 點配對
會預測出下方的三種資訊。 預測 [交互的作用點(Interaction point), 點到人的位移,點到物體的位移] 當點到人以及物體的位移有配對到人的中心點以及物件的中心點,這樣該配對就代表成功。
以往的 GAN-based 的圖像轉換模型當訓練完成後會將 Discriminator 捨棄掉,
而本文提出不同的思維,
認為要重複利用此 Discriminator。
提出將以往的 Encoder 部分改用 Discriminator 的前幾層去替代。
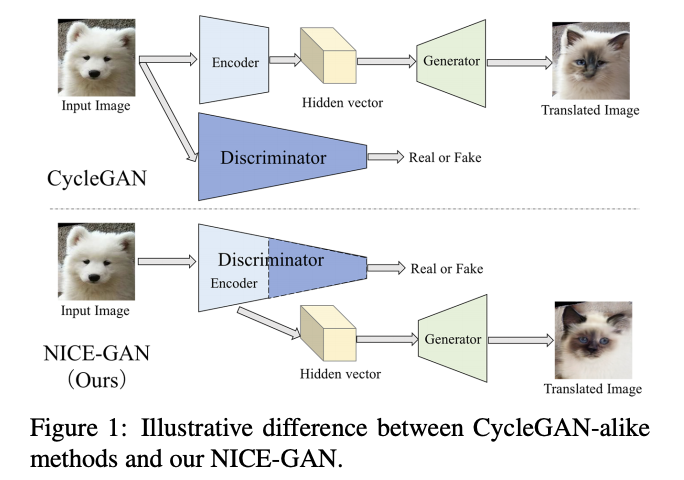
其想法是基於
- 以 Unsupervised image-to-image translation 任務而言 Encoder 的功用是將圖片轉換成一個低維度的 Embedding(可以理解成特徵),而 Generator 再基於該特徵去生成/仿造出一張新的圖片。
- 以 Unsupervised image-to-image translation 任務而言 Discriminator 的功用是判斷該輸入圖片是真實的圖片或是仿造的圖片,但要做到這件事之前,Discriminator 在做的事情是先抽取出語意(Semantic)上的特徵,在將此特徵透過最終幾層來判斷是否為真實或仿造。
基於上述的觀察,作者提出 Discriminator 其實是具備兩種能力
- 抽取特徵(Encodeing)
- 分類(Classifying)
因此提出可使用 Discriminator 的前面幾層作為 Encoder 使用。
而這好處有幾個
- 模型整體變得更簡潔,因可捨去原先獨立的 Encoder 部分,以及這樣子 Discriminator 訓練完還能保有一點用處,因為前幾層就是 Encoder。
- Encoder 可以被訓練得較好,因為是直接基於 Discriminator 去做訓練,而非從 Generator。此外近年來 Unsupervised image-to-image translation 常在 Discriminator 上用到一個 Trick,稱為 Multi-scale 的訓練,而現在 Encoder 的架構因為是被包含在 Discriminator 內,因此使用此 Trick 也可直接受益到 Encoder。
Multi-scale Trick 可以去看這篇論文 pix2pixHD, [High-Resolution Image Synthesis and Semantic Manipulation with Conditional GANs]
模型架構
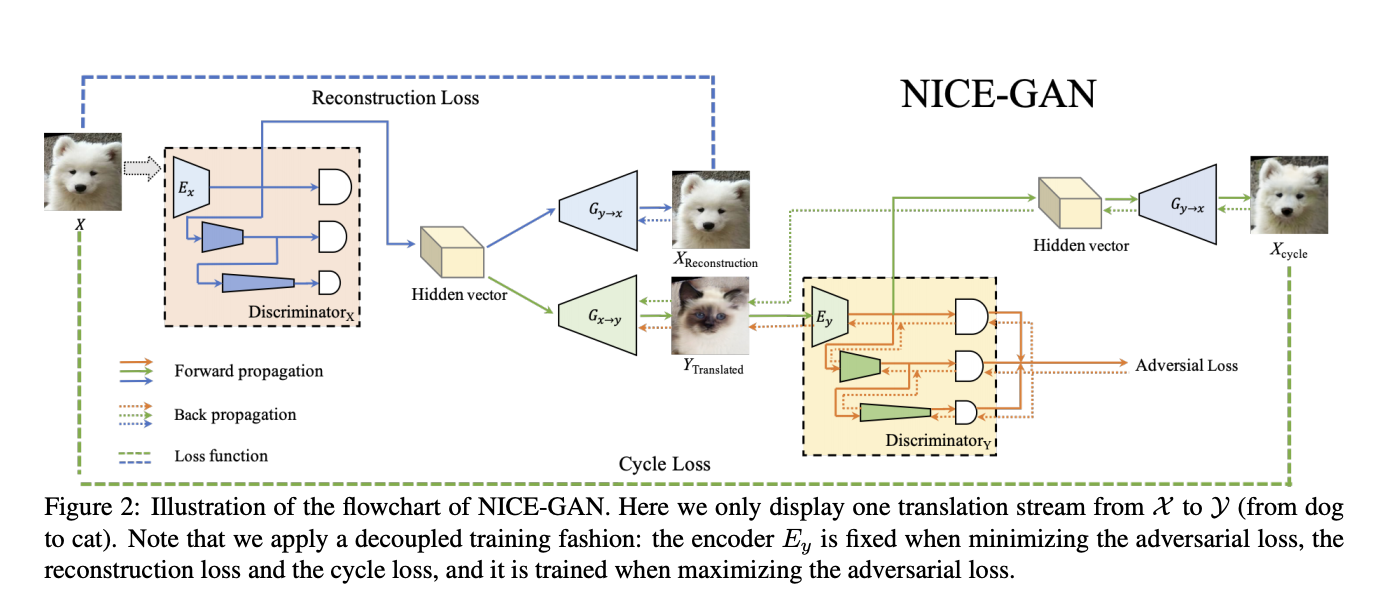
整體流程就是在 Unsupervised image-to-image translation 常見的流程。
首先會將一張圖片經過 Encoder(這邊是 Discriminator 的前半部),
藉此獲得出 Hidden vector 特徵,
我們目標是訓練出一個可以將 Hidden vector 的特徵經由 Generator 模型生成出以假亂真的圖片。
訓練方式大概是下面這種感覺
Generator 希望所生成出的圖片可以騙過 Discriminator,
那 Discriminator 又會希望可以識別出圖片是真的還是偽造的,
藉此訓練兩個都會不斷的進步,
最終可得出一個能夠以假亂真的 Generator。
以數學式表達會變成這樣,
這邊是基本套路,
使用 LSGAN 做訓練。 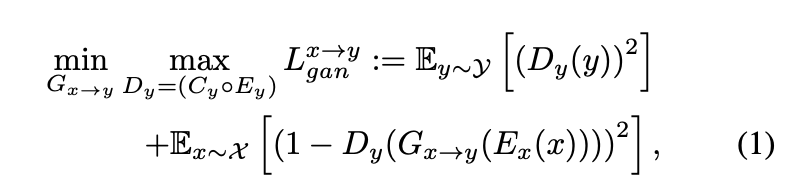
這邊簡單說一下概念,
當大眼睛的狗狗轉換經過 Encoder 後,
我們會希望他把大眼睛這特徵保留下來,
藉此希望能轉換成大眼睛的貓咪,
接著再將那隻貓的圖片再轉換成狗類別時,
我們也希望貓咪的 Encoder 也可以保留大眼睛這特性,
藉此再生成出一隻大眼睛的狗狗,
確保兩個模型生成間的一致性。
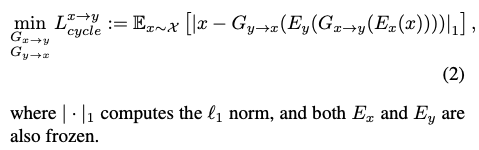

當我們使用原本圖片 X 輸入至 Encoder 所得到的特徵,
會希望 Generator 可以學會生成出相像原本的圖片 X 。
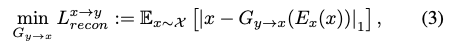
最終 Generator 的 Loss function 如下,挺簡單的。 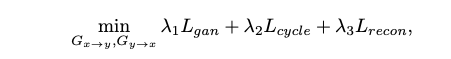
只是這邊其實有個細節,
就是這架構使用傳統的訓練過程會導致不穩定,
因為我們的 Encoder 其實是 Discriminator 的一部分,
而 Encoder 在訓練生成圖片時我們會希望它可以 Minimize error,
但在訓練 Discriminator 時卻希望要 Maximize error。
這兩個同時訓練的話對 Encoder 是很矛盾的。
因此實際上 Encoder 只有在訓練 Discriminator 時才會做訓練(Eq 1.),
其他時候權重是被凍結(Freeze)的。
補充:此處的 Discriminator 還有搭配 [U-GAT-IT: Unsupervised Generative Attentional Networks with Adaptive Layer-Instance Normalization for Image-to-Image Translation] 的想法,給定 Encoder 所輸出的 Feature maps 不同權重,將其加總後為最終的 Adversial Loss,只是這邊又再延伸,在 Discriminator 模型中多訓練一個可學習的參數 γ 當作一個權重 => Adversial Loss = γ * Adversial Loss
成果


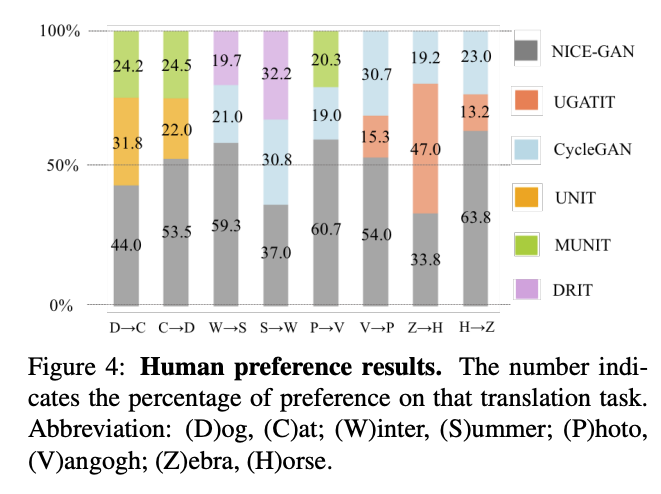
參考資料:
PPDM: Parallel Point Detection and Matching for Real-time Human-Object Interaction Detection