PixMatch簡介 - Unsupervised Domain Adaptation via Pixelwise Consistency Training
Luke Melas-Kyriazi, Arjun K. Manrai. “PixMatch: Unsupervised Domain Adaptation via Pixelwise Consistency Training”. In CVPR 2021.
In CVPR 2021.
Paper link: https://arxiv.org/abs/2105.08128
Github(Pytorch): https://github.com/lukemelas/pixmatch
簡介
近年來 Unsupervised domain adaptation(UDA) 領域自適應任務已被廣泛探討,
在 Unsupervised domain adaptation(UDA) 的任務中會有兩個資料集 Source 及 Target Domain,
Source Domain 有圖片(Xs)以及標註(Ys - GT),而 Target Domain 只有圖片(Xt)沒有標註,
其目標是希望讓模型在兩個 Domain 都能表現的不錯,
為了要達到這件事,模型要學會不同 Domain 的特徵(Domain-invariant features)。
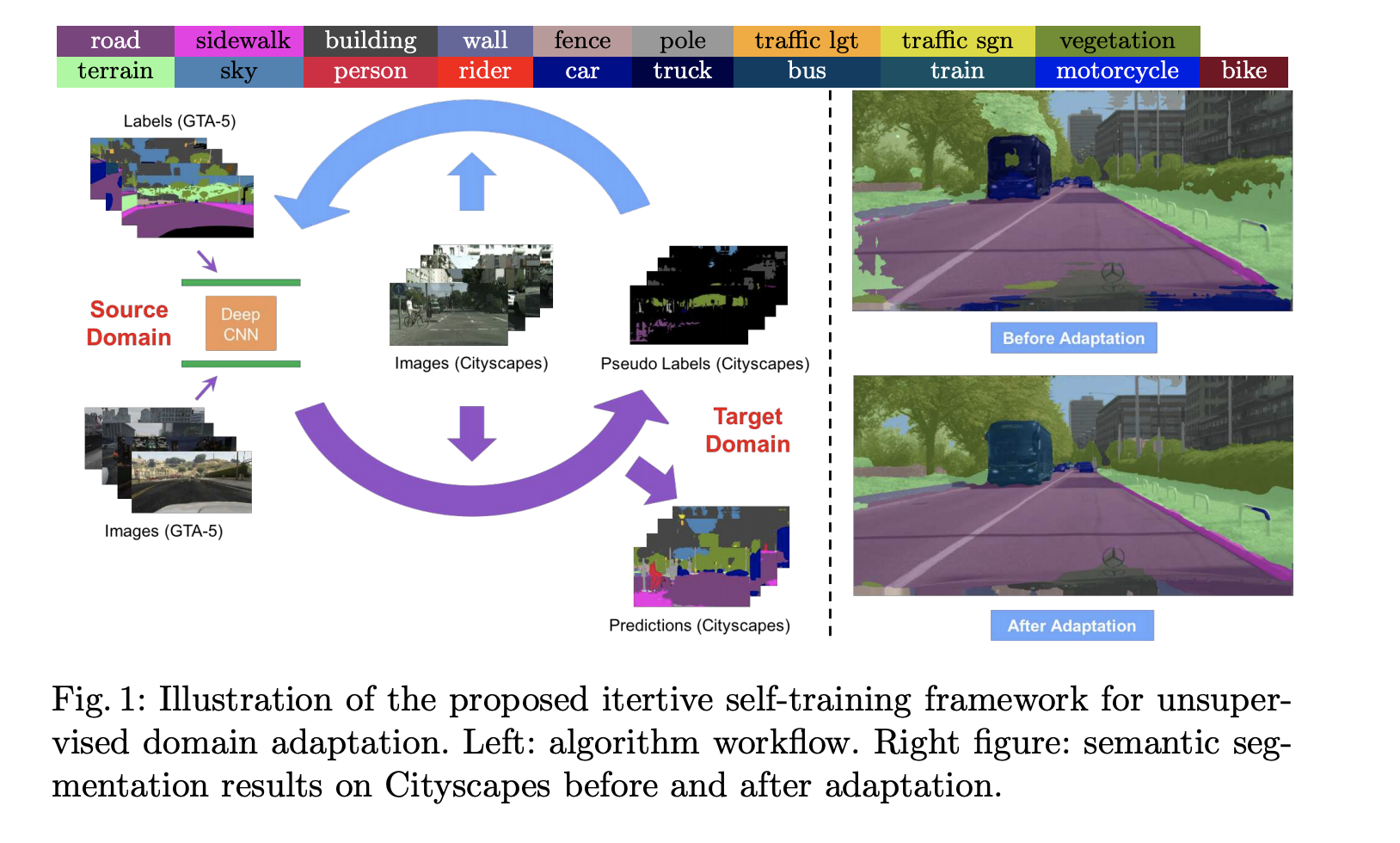 上圖取自 ECCV’18 Unsupervised Domain Adaptation for Semantic Segmentation via Class-Balanced Self-Training。
上圖取自 ECCV’18 Unsupervised Domain Adaptation for Semantic Segmentation via Class-Balanced Self-Training。
本論文提出利用透過不同的 Data augmentation 對 Target domain 的圖片進行擾動,
並利用 Consistency loss 來確保擾動前與擾動後的圖片都能產生相似的預測結果,
藉此使模型可以適應不同情況,最終達成 UDA 的效果。
本方法策略簡單,並不像以往需要調整模型結構(e.g., GAN 框架、Auxiliary netowrk 衍伸的輔助任務、Multi-stage 的訓練流程),
整體概念簡單結果卻相當的不錯。
方法
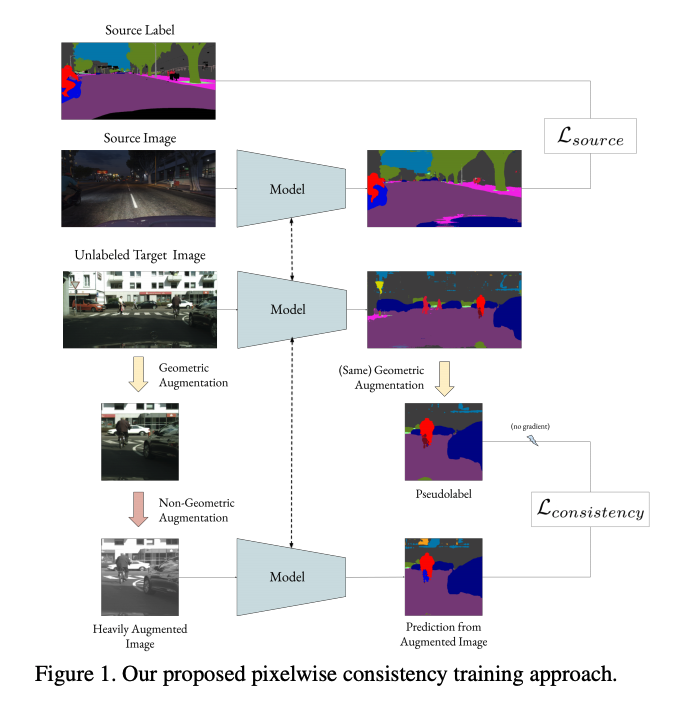
整體的概念圖如下:
Loss source
基於 Source Domain 進行訓練,由於 Source Domain 有 Ground truth - Y,因此進行監督式的學習,下方簡單來說就是 Cross-entropy loss。
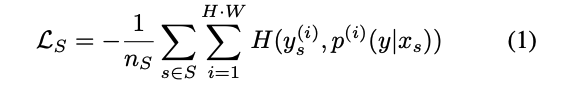
Loss consistency
基於 Target Domain 進行訓練,
希望我們的模型在不同的環境下也能夠具備一定的泛用性,
利用對資料擾動(Perturb) 的方式,
對資料進行改動藉此模擬不同的狀況。
以 Crop 的資料擴增方式為例,
首先輸入 Target domain 的一張圖片 x 至模型中預測出 y_hat,
接著使用 Perturbation Function 對 x 圖片及 y_hat 進行 Crop 後產生 x_pert、y_pert。
模型再透過輸入 x_pert 來生成 y 的預測結果,
最終我們會希望 y 與 y_pert 的結果要相近。
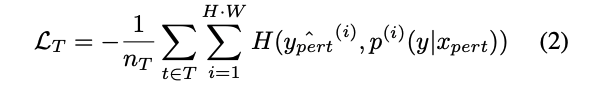
Perturbation Functions

本論文中嘗試 4 個不同的 Perturbation Functions:
- Augmentation:對圖片進行 Crop 或是縮放的動作。
- CutMix: 將兩張圖片作拼貼,是一種數據增強的方式。
- Style mixing: 希望 Target domain 的圖片畫風要變成 Source domain 的畫風,藉此來減緩 Domain shift 的問題,這招在原本的 UDA 就是很常見的一招,此處採用 AvatarNet 的模型。
- Fourier Domain Adaptation:採用 CVPR 2020 FDA: Fourier Domain Adaptation for Semantic Segmentation 所提出的 UDA 方法,將 Source domain 的圖片基於 Spectral transfer 的方法,將 Source domain 的低頻資訊替換為 Target domain,使 Source domain 的畫風變成 Target domain,藉此來獲得相似於 Target domain 的樣本。
這邊補充一下 FDA - Fourier Domain Adaptation 的原論文圖片
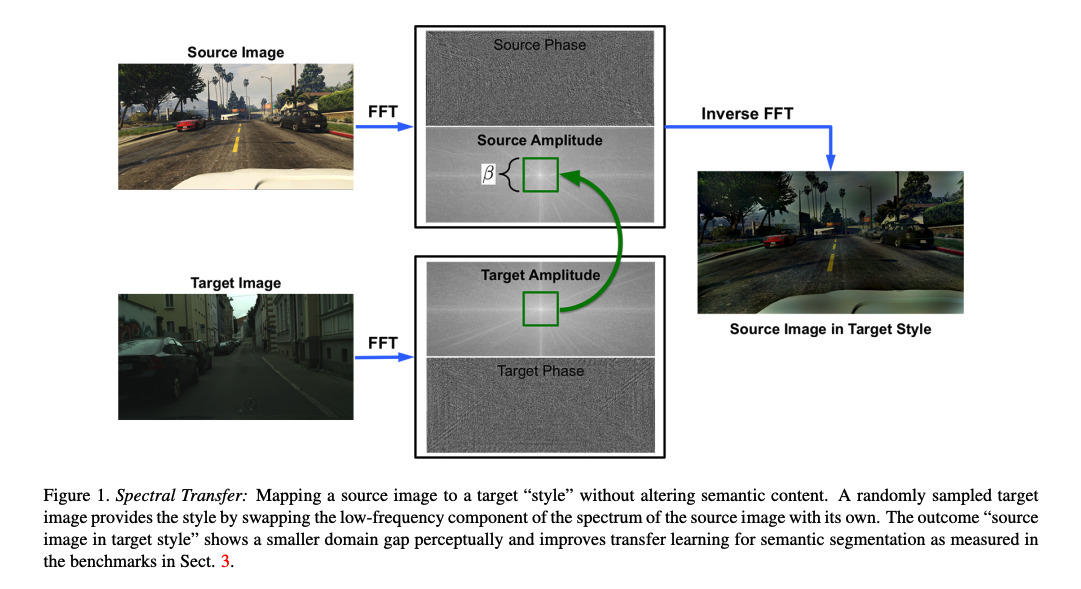
最終實驗結果表明: CutMix 與 Fourier Domain Adaptation 兩個方式組合可獲得最好的效果。
Result
本模型是基於 DeepLab v2 作為語意分割模型,
Backbone 為 ResNet-101,
只需要一張 2080Ti 就可以進行訓練。
本論文驗證在 GTA5-to-Cityscapes 以及 SYNTHIA-to-Cityscapes 都有相當好的效果。
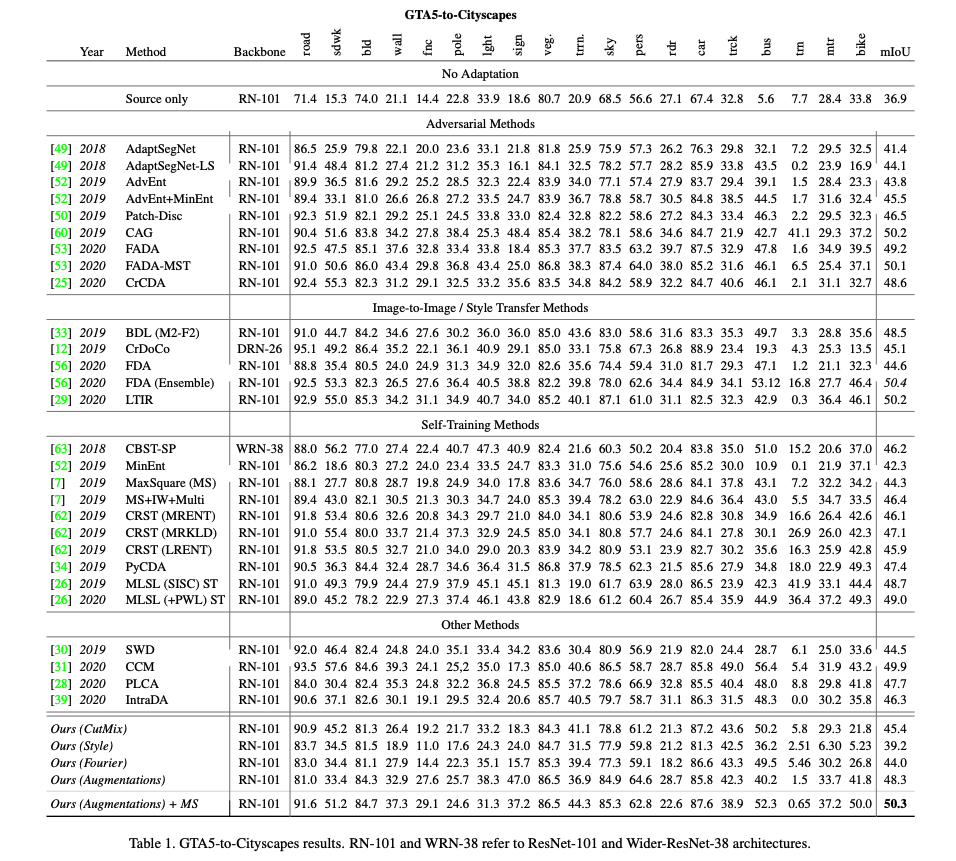
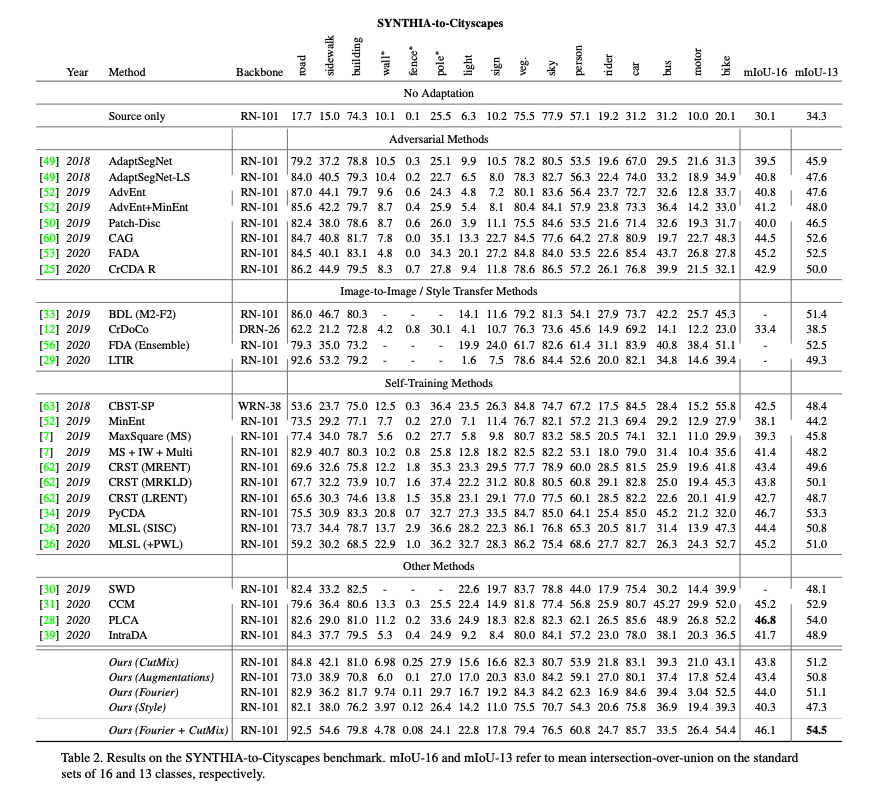
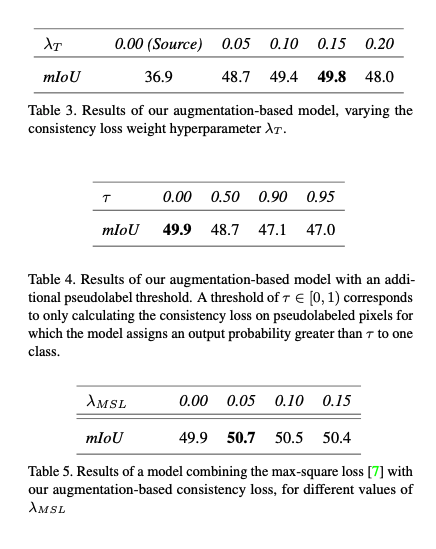
參考資料:
PixMatch: Unsupervised Domain Adaptation via Pixelwise Consistency Training
Unsupervised Domain Adaptation for Semantic Segmentation via Class-Balanced Self-Training
CBST簡介 - Unsupervised Domain Adaptation for Semantic Segmentation via Class-Balanced Self-Training