微調大型語言模型LLM的技術LoRA及生成式AI-Stable diffusion LoRA
Hu et al., “LoRA: Low-Rank Adaptation of Large Language Models, ” In ICLR 2021.
LoRA: Low-Rank Adaptation of Large Language Models 簡介
Paper link: https://arxiv.org/abs/2106.09685
Github(Pytorch): https://github.com/microsoft/LoRA
這篇文章會介紹
- Microsoft 所提出的 LoRA 技術可大幅減少微調大型語言模型的參數
- 使用 LoRA 技術與沒使用之間的記憶體用量比較
- LoRA 技術簡介
- LoRA 可與 Stable diffusion 進行結合 - Stable-diffusion-LoRA
- Stable-diffusion-LoRA 可透過分享 LoRA 的權重檔,就能與網路上的大家分享自己的模型成果,實現補丁/插件的想法。
簡介
近年的大型語言模型(Large Language Model, LLM) 或稱作 (Foundational Model),多使用大量的資料集與有龐大參數的模型進行訓練,如常見的 GPT-3(175B 的參數)。從 ChatGPT 的橫空出世,也可看出目前 LLM 的泛化程度,通用型 LLM 在常見的問題已有不錯的表現。但要使用到特定領域的狀態下,雖可透過少數的例子(Few-shot)來進行 In-context Learning,不過最理想的情況還是使用 Fine-Tuning 對模型進行微調效果會更好。
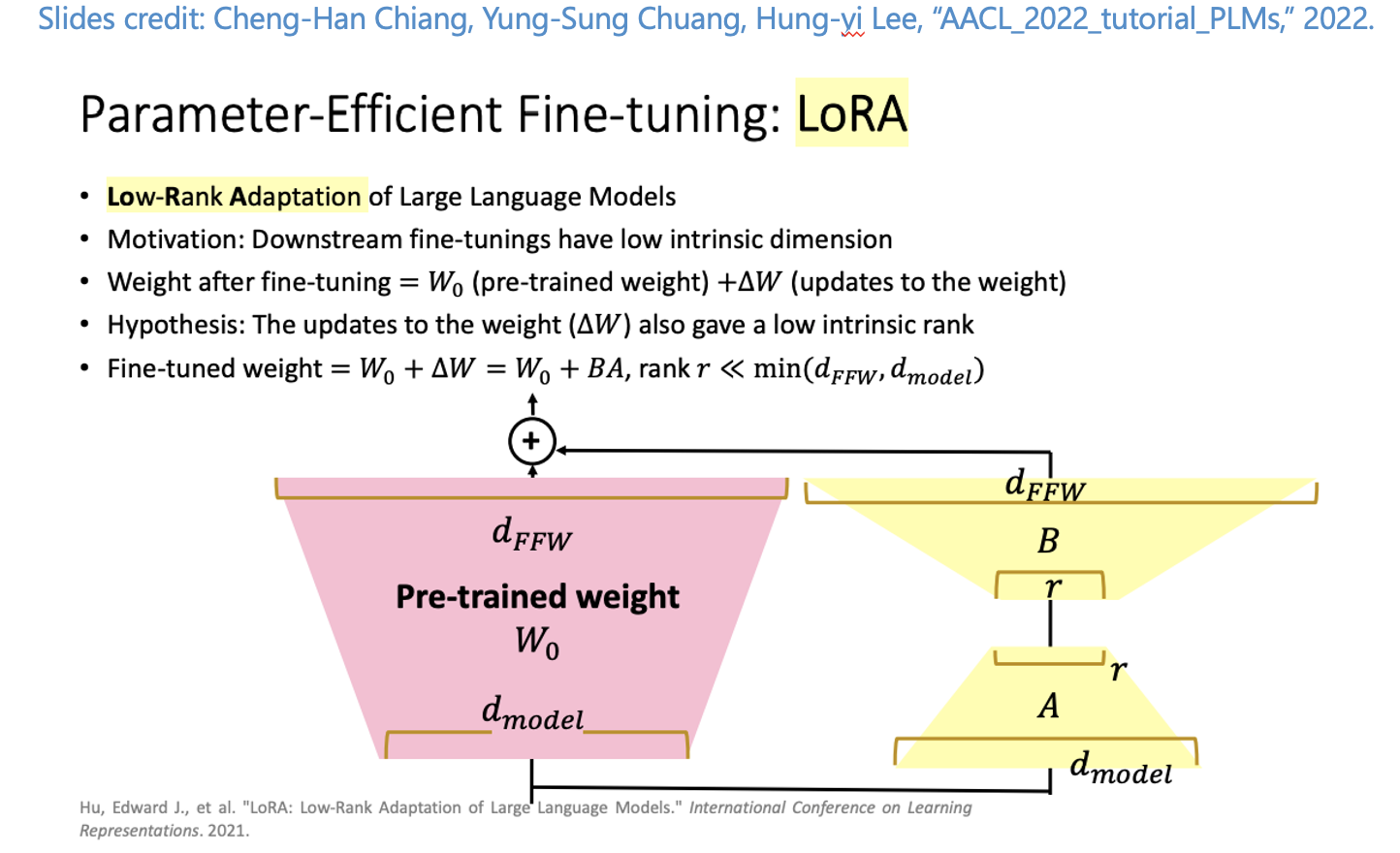
而近年隨著模型越來越大,直接使用 Fine-Tuning 對所有參數進行訓練的成本是相當高昂的。因此近年來大家開始研究有效率的 Fine-Tuning,稱作 Parameter-Efficient Fine-Tuning (PEFT),本次要介紹的是 Microsoft 團隊提出的 Low-Rank Adaptation(LoRA),概念是透過凍結原本的預訓練模型(e.g., GPT-3) 的權重,搭配一個小的模型進行微調就可以達到很好的 Fine-Tuning 效果,同 Adapter 的概念:透過 Freeze LLM 僅透過微調新增的小型網路,當作補丁或是插件。整體想法如下圖:在特定層之中插入小型的 LoRA 網路,來讓模型可適用不同的任務。
也補充一下 Cheng-Han Chiang, Yung-Sung Chuang, Hung-yi Lee, “AACL_2022_tutorial_PLMs,” 2022. 在這篇教材中有很好的解說,如下圖
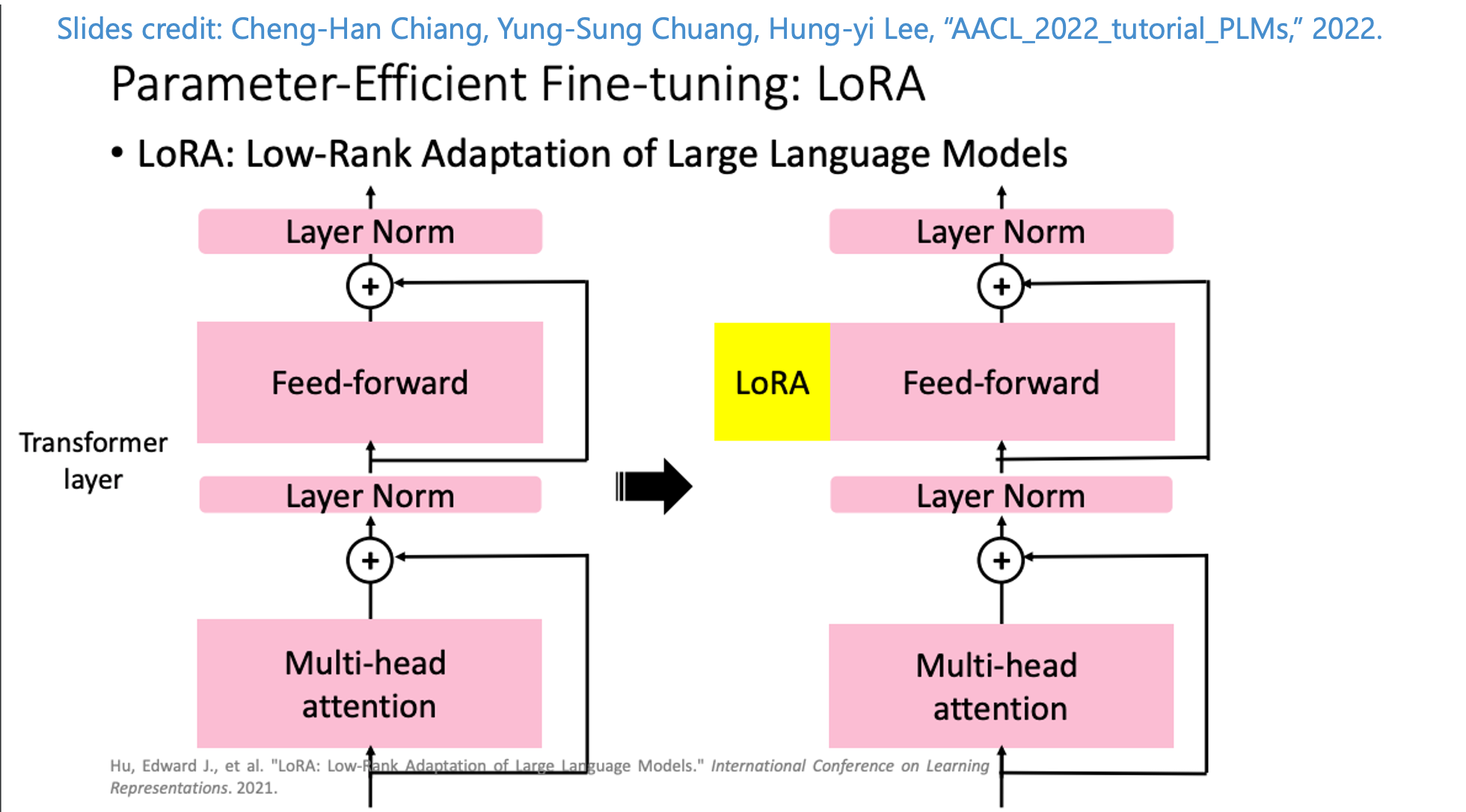
在未來就不需要調整大型網路的模型,而是改為訓練一個小型的模型/權重,透過結合這些權重和原先 LLM 中特定 Layer 的權重來進行組合,和 Fine-tund GPT-3 模型相比,該方法所需的訓練參數量節省 10,000 倍,並且只需要 1/3 的 GPU 使用量,而該技術除了應用在 LLM 上,更被大量運用在訓練高解析度的圖像生成 AI - 如 Stable-Diffusion 的生成式模型。
使用 LoRA 技術與沒使用之間的記憶體用量比較
下圖可看到使用了 LoRA 模型僅需要 Θ 數量僅需要 0.5M、11M 的訓練參數,是遠小於原本的 LLM 模型(此處使用 GPT-2 Medium, 參數量 345M),並且使用 LoRA 的技術在 Batch size = 1 的 Inference 情況下,他的推論效率是比過往的 Adapter 技術還要好的。

為什麼模型的參數量/大小這麼重要?首先要了解的是在訓練模型的時候,到底會使用到多少的 GPU Memory,細節大家可以看這篇貼文 Jacob Stern: A comprehensive guide to memory usage in PyTorch。
訓練時最大的模型用量(不考量混合精度 Mixing Precision):
- 計算公式:模型所需記憶體 + Forward 所需記憶體(較為彈性) + Gradient 所需記憶體(模型所需訓練參數的記憶體)+ 優化器所需儲存的變數 * 模型所需訓練參數的記憶體(通常最大,Adam 可視為所需 2 倍模型所需記憶體)
- Forward 運算取決於 Batch size、輸入的內容大小以及是否有用混合精度、也可以透過 PyTorch 的 Checkpoint 機制來降低此部分的記憶體消耗 ,屬於彈性可調整的)
- 優化器所需儲存的變數取決於不同的優化器(SGD:0, RMSProp:1, Adam:2),常見的優化器 Adam 會紀錄模型過往的 EMA 以及 Momentum 的 Gradient,因此對於 Adam 優化器來說,他會儲存 2 個模型大小的參數量!
下面是給出使用 Adam optimizer 以及不使用混合精度的估算(有錯再請指正!): 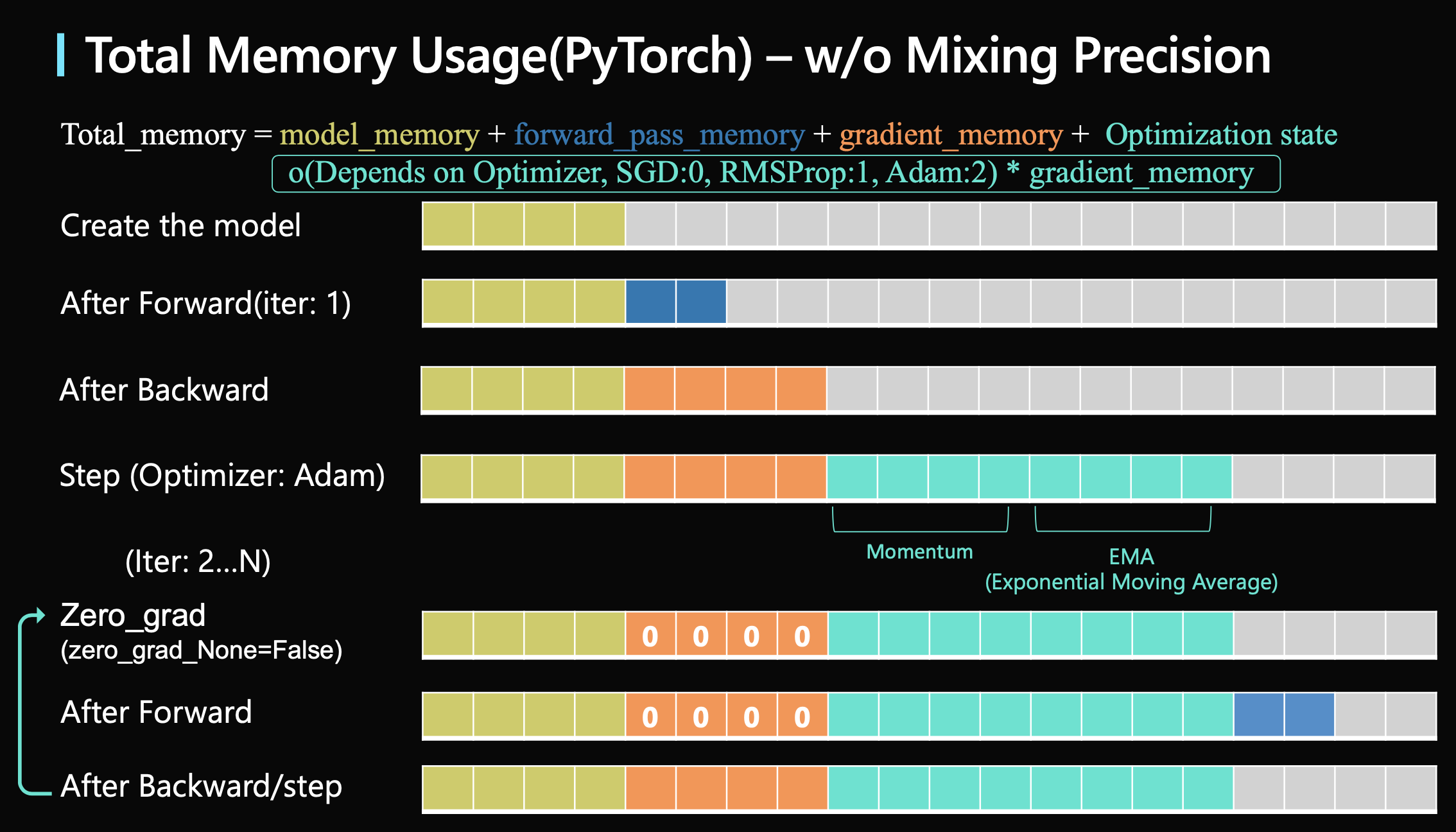
假設大型模型的記憶體佔用了 4 格,為了要對整個模型進行訓練,因此 Gradient 也需要一份模型大小的記憶體佔 4 格,而為了訓練模型需要優化器,優化器(Adam)又需要 2 份模型大小的記憶體,因此佔 8 格,此處還不包含 Forward 所需的記憶體就需要 4 份模型大小的記憶體,那可以想到的是如果使用的是超大模型 GPT-3, 175B 的模型大小那所需的記憶體是超級大!!
雖然實務上在使用的時候會搭配混合精度(Mixing Precision)以及一些技巧,不過訓練要使用到的記憶體大小會取決於要進行訓練的參數量,實際上我們對大型模型進行微調時,通常會用 Adapter 來訓練部分的參數,並不會對整個模型進行訓練 ,透過 Freeze 住 LLM 的模型權重,只需要訓練一小部分的擴充模型,這種情況下我們的 Optimizer 以及 Backward 所需儲存的參數量就會瞬間減少很多,我們用下面的例子來讓大家看一下,若只使用 LoRA 模型僅需要的 Θ 數量(通常訓練的參數會 < 0.1 % 的 LLM),此時的記憶體用量會變成下圖,當然實際上是更少的,因為所添加的可訓練參數會非常少,並且所造成的額外運算成本也很低:

LoRA 方法
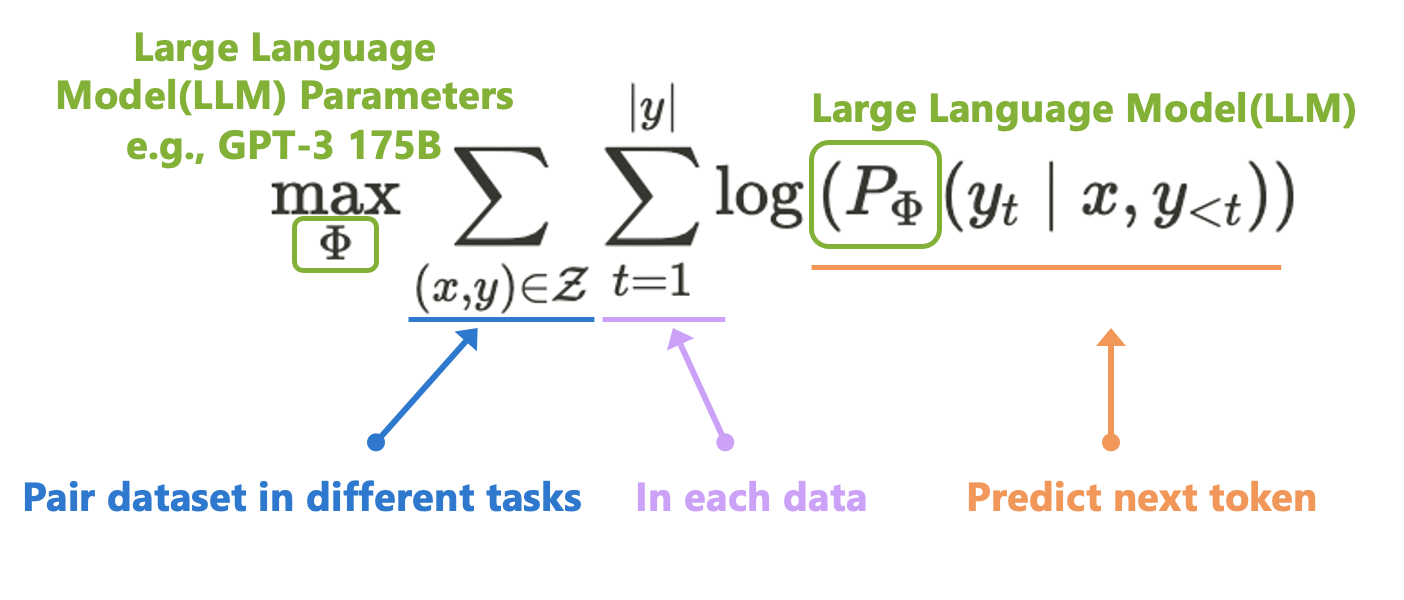
過往為了要使 LLM or Foundataion Model (如 GPT 系列)可適用於不同的下游任務(Downstream tasks),因此訓練模型(Φ)的目標就是讓模型在處理多個不同任務(Z)準確度都要很好。
下圖為 GPT-1 所制定的下游任務,有常見的 NLP 任務:分類任務、假設任務、相似性比較、多選題等,透過輸入不同的 Prompt 來訓練模型。
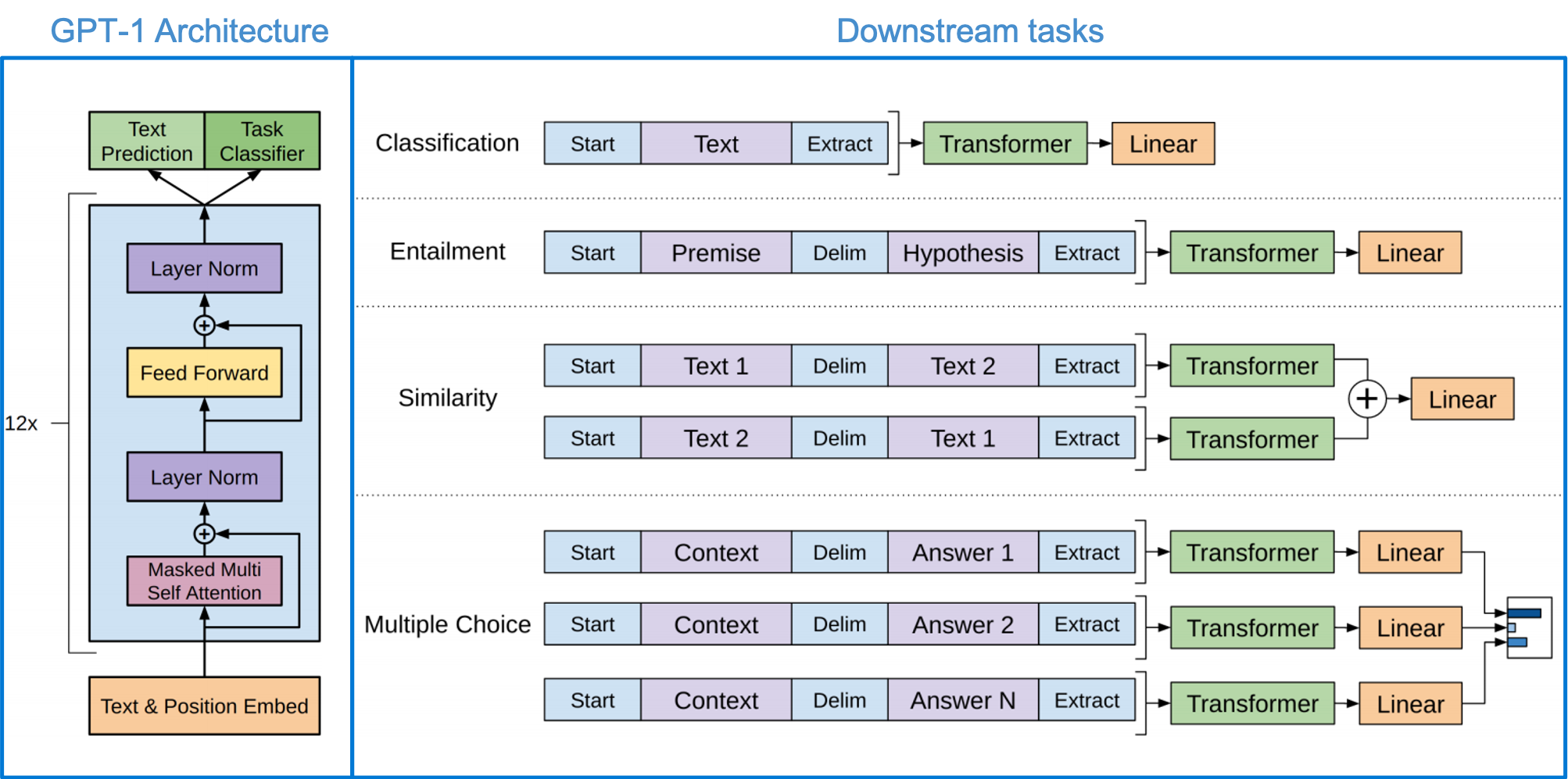 Radford et al., “Improving Language Understanding by Generative Pre-Training”, in 2018.
Radford et al., “Improving Language Understanding by Generative Pre-Training”, in 2018.
過往針對不同下游任務所進行的 Parameter-Efficient Fine-Tuning 做法有兩種
- Adapter: 透過添加些許的模型架構,並固定 Freeze LLM 的模型參數,進行訓練。
- Prefixing: 在 Prompt 的前半部添加 Token 來讓模型對於特定任務可以做得更好。
這部分可以看 Hung-yi Lee 教授的【生成式AI】Finetuning vs. Prompting:對於大型語言模型的不同期待所衍生的兩類使用方式 (1/3)
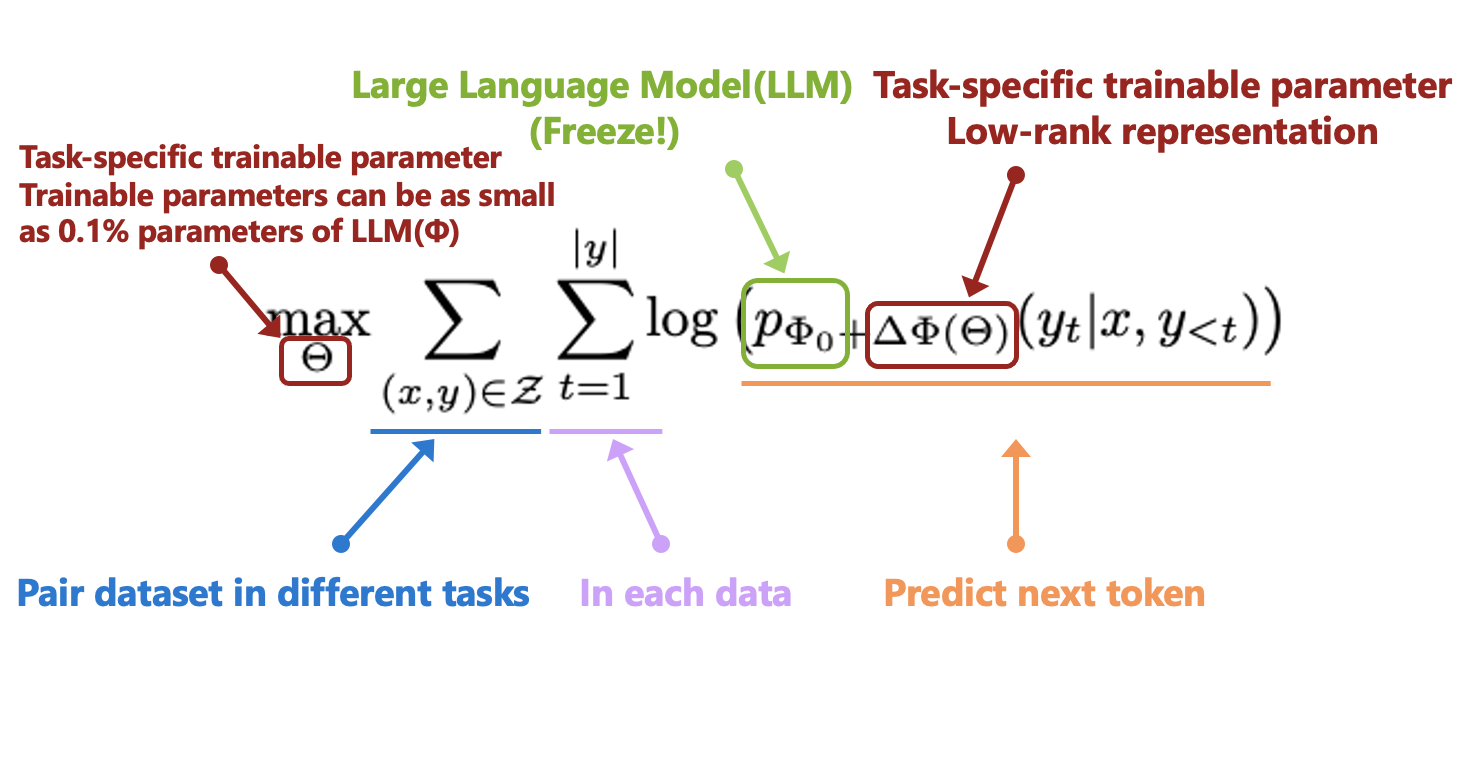
本文所介紹的 LoRA 屬於 Adapter 類型,而 LoRA 的概念是:既然 LLM 適用於不同任務,那代表模型對於不同任務會有不同的神經元/特徵來處理這件事,如果我們能從眾多特徵中找到適合那個下游任務的特徵,並對他們的特徵進行強化,那我們就能對特定任務有著更好的成果。因此透過 LLM 模型 - Φ ,來搭配另一組可訓練的參數 Trainable Weight - Θ(Rank decomposition matrices) 進行組合,藉此最佳化下游任務的成果,
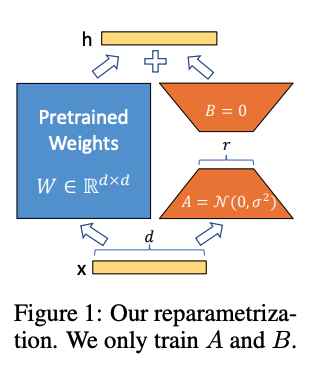
右邊橘色模組為我們要訓練的模型權重 \(\hat{L}_{\text {LoRA }}\) ,透過中間 Rank - r 的限縮,可以大幅地降低訓練的參數量,特徵的維度:\(r << d\),整體參數量可變成:\(|{\Theta}|=2 \times \hat{L}_{\text {LoRA }} \times d_{\text {model }} \times r\), 而 \(\hat{L}_{\text {LoRA }}\)為整個模型有用到的 LoRA 模組數量,論文中是在 Transformer 架構中的 Attention 中都插入 LoRA 模組,而 r 的大小會基於不同的任務而定,不過在實驗中多半使用 2~4 就有不錯的成果。 最終我們的模型是想要透過 LoRA 模組來最佳化下游任務,如下方公式。
實驗
- LoRA 多數的成果比 Fine-tuning 的成果還要好,並且訓練的參數量遠小於 Fine-tuning。
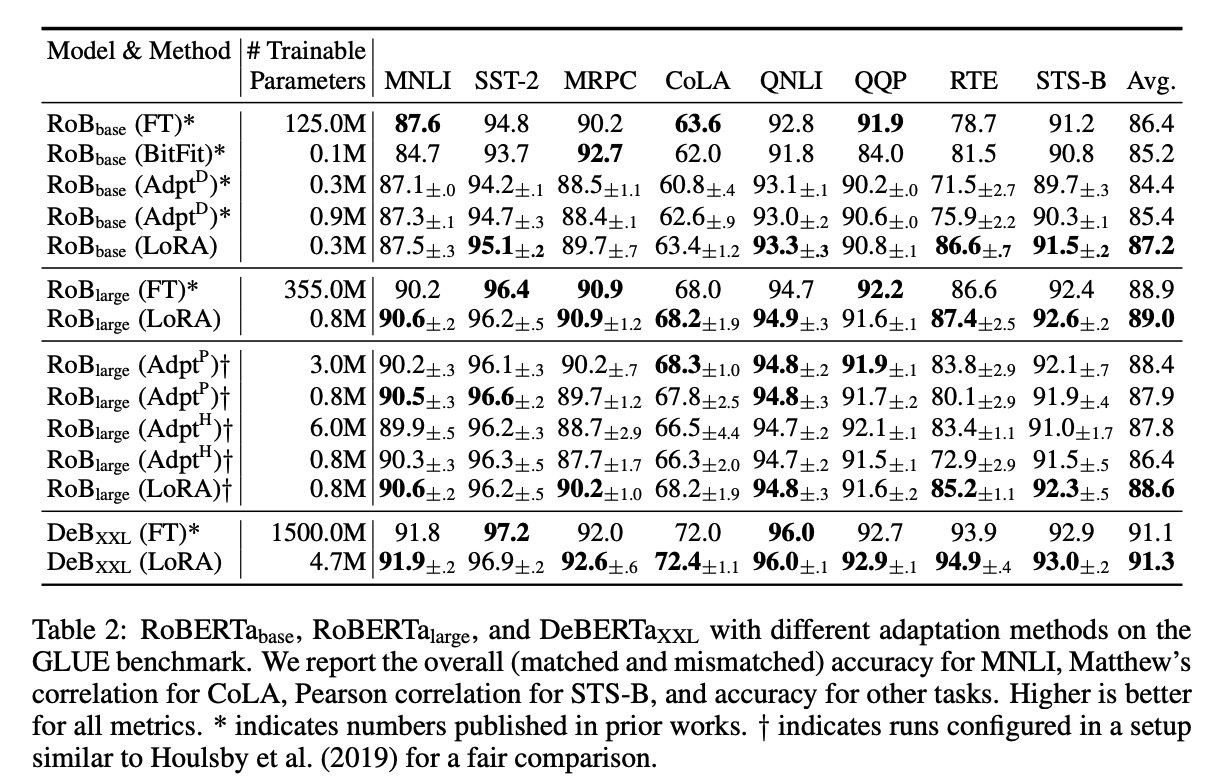
- 相較於其他有效率的 Fine-tuning 方法,LoRA 獲得最好的準確度。
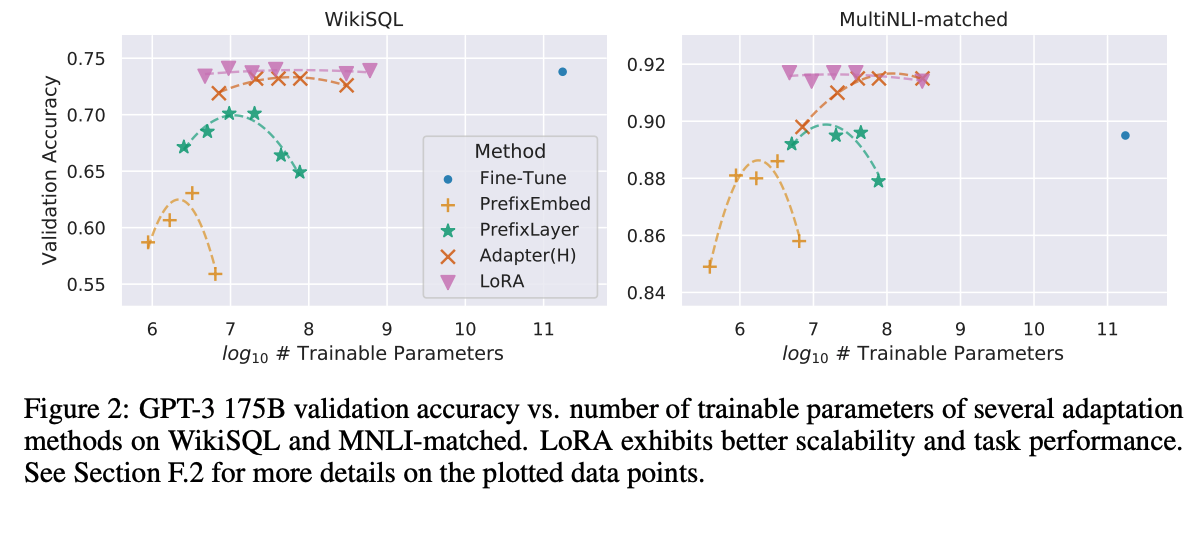
- 在實驗中僅評估在 Attention 中加入 LoRA 模組的成果,並且在固定參數量的情況下評估在 Q、K、V、O 那個區塊添加 LoRA 會有最好的效果。
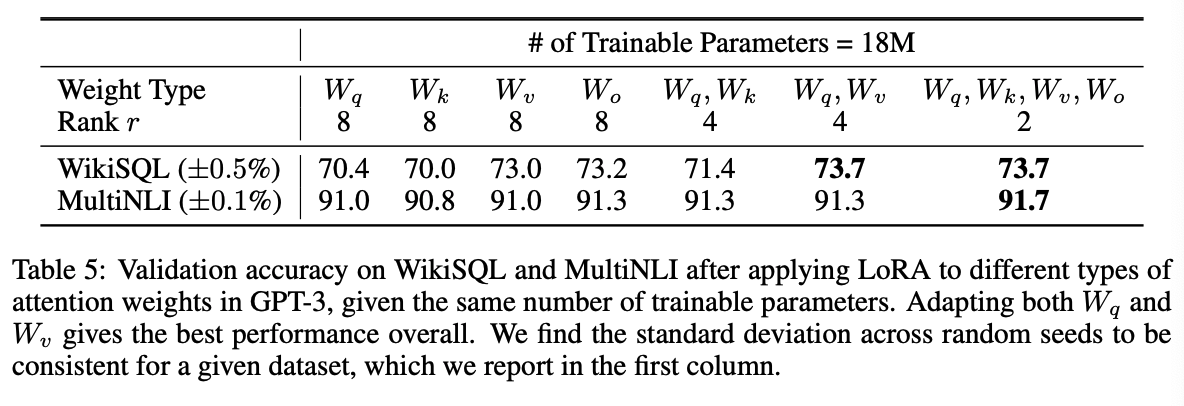
- Rank 數量的選擇。
LoRA 指令快速看
可參閱 Github: https://github.com/microsoft/LoRA
其實細節的實作是挺困難的,但是他封裝的很好。
目前也整合至HuggingFace Parameter-Efficient Fine-Tuning (PEFT)
- 如果模型要將特定層數替換成 LoRA,需要調整模型的架構,但呼叫很簡單:
# ===== Before =====
# layer = nn.Linear(in_features, out_features)
# ===== After ======
import loralib as lora
# Add a pair of low-rank adaptation matrices with rank r=16
layer = lora.Linear(in_features, out_features, r=16)
- 在訓練之前要把原本的 LLM 模型 Freeze 住,並且設定只有 LoRA 的參數是可訓練的
import loralib as lora
model = BigModel()
# This sets requires_grad to False for all parameters without the string "lora_" in their names
lora.mark_only_lora_as_trainable(model)
# Training loop
for batch in dataloader:
- 儲存模型時也可以只儲存 LoRA 所訓練的權重,這特性將方便大家分享自己的權重/補丁
# ===== Before =====
# torch.save(model.state_dict(), checkpoint_path)
# ===== After =====
torch.save(lora.lora_state_dict(model), checkpoint_path)
讀取 LoRA 或是原本 LLM 的權重時,要將 strict 設定為 False
# Load the pretrained checkpoint first
model.load_state_dict(torch.load('ckpt_pretrained.pt'), strict=False)
# Then load the LoRA checkpoint
model.load_state_dict(torch.load('ckpt_lora.pt'), strict=False)
LoRA 論文小結
- 共用大型的 LLM 模型是未來的趨勢,如果要適應到某個任務,只要訓練 LoRA 模組即可,而他也帶來方便替換性,未來大家只要儲存 LoRA 的模型權重,就可以快速分享或是切換不同至任務。
- 透過大量降低訓練的參數,來大幅降低了硬體的訓練門檻,並且與完全 Fine-tuning 的模型相比,推論速度的增加是相當少的。
- 缺點:由於 LoRA 是訓練模型去最佳化每個任務,如果一個 Batch 之中包含不同任務,需要調整程式架構,讓不同的輸入推論在對應的模組上。
使用更少的設備去訓練大型模型的技巧,除了本篇介紹的 Parameter-Efficient Fine-Tuning (PEFT) 中的 LoRA 方法以外還有其他的研究方向:如 Microsoft 的 DeepSpeed 中有整合的 ZeRO-Offload: Democratizing Billion-Scale Model Training 以及可以在單一 GPU 上面推論 GPT-3 175B 模型的 FlexGen 都是近年的技術,大家有興趣都能了解看看。

Stable-diffusion-LoRA(Low-rank Adaptation for Fast Text-to-Image Diffusion Fine-tuning)
近年來生成式 AI 從 DALLE 再到 Stable-diffusion,都顯示了現在的 AI 可以生成高品質以及高解析度的圖片,但是讓人詬病的還是需要大量的運算資源才能夠訓練得了這種高解析度的模型,因為要訓練一個高解析度的擴散模型是需要相當多記憶體的,即便 Stable-diffusion 將原本的 Pixel-level Diffusion 變成 Latent Diffusion Model 已經大幅降低訓練的記憶體,但仍無法訓練在單一張 11 GB 的 GPU 上,但現在不一樣了,有人將 LoRA 技術整合到 Stable-diffusion,推出了 Stable Diffusion LoRA!

整合 LoRA 至 Stable-diffusion 直接帶來了下方的好處:
- 訓練快很多
- 可直接訓練在 11GB VRAM
- LoRA 權重的保存只有 3MB~200MB,易於分享
HuggingFace 也將使用的教學分享在這邊 Hugging Face: LoRA Tutorial
這個技術上的突破也使得 Stable Diffusion 的社群多了許多生成模型,甚至可將模型上傳至網站 CivitAI,可以看到上面有許多模型是使用 LoRA 進行訓練的:
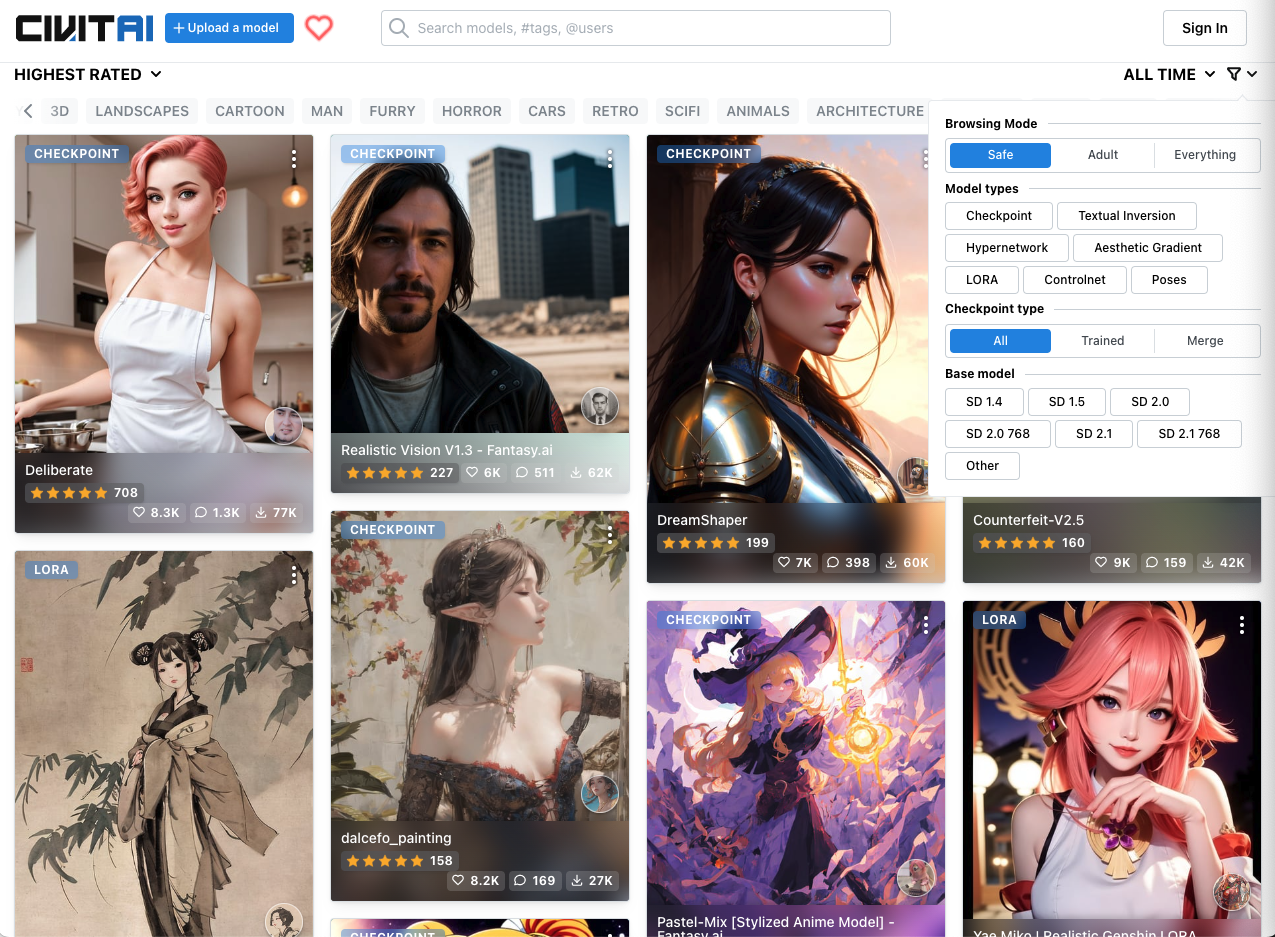
網路上也有許多資源是使用 Colab 或是在個人 PC 上面生成/訓練模型,最近 Stable diffusion 的社群已經開源相當多專案,並提供 GUI 介面,甚至不需要懂程式碼就可以訓練好生成式 AI。
如果只是想來摸看看 Stable-diffusion 的人建議使用 WebUI,不僅能使用官方釋出的模型,更直接連動到 CivitAI,可以直接下載別人的生成模型:
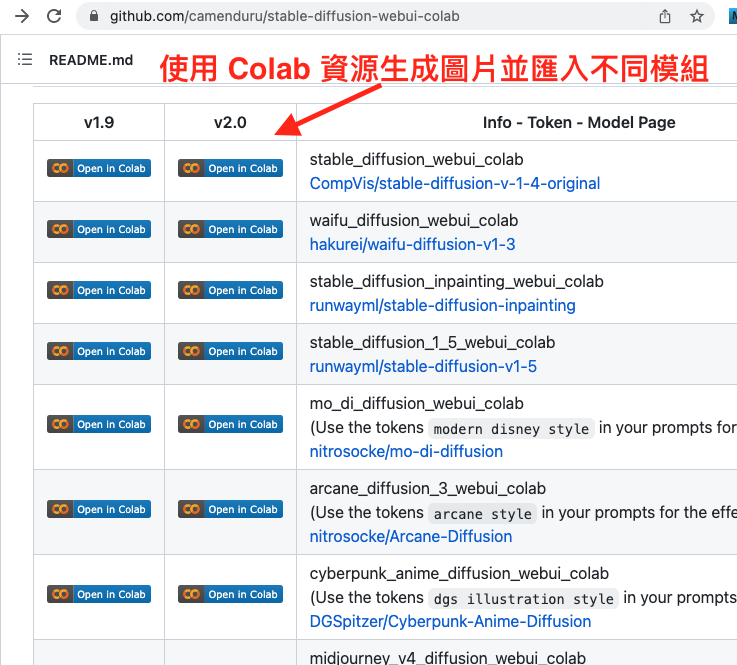
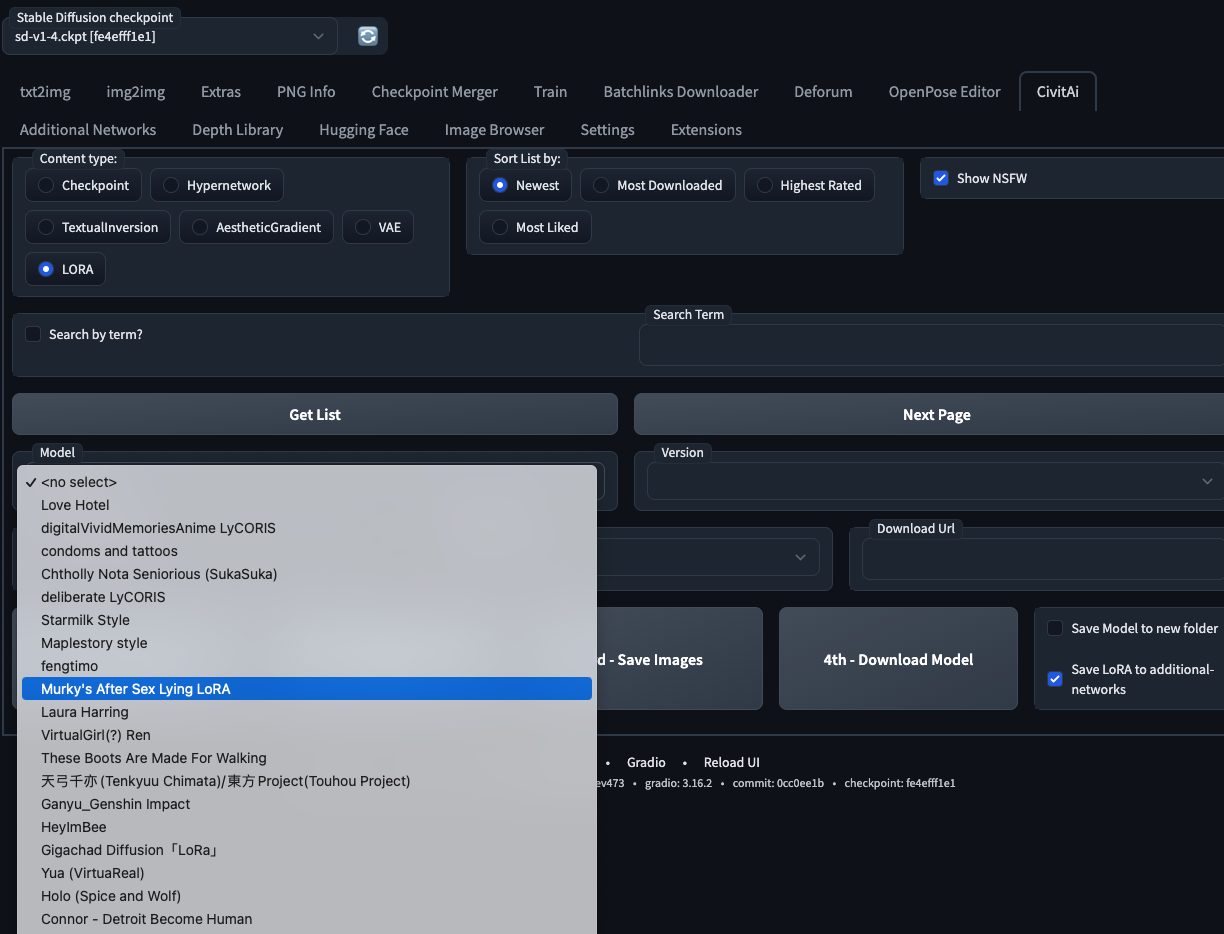
下方補充一些資源:
Stable-diffusion-webui Online Services
GitHub - AUTOMATIC1111/stable-diffusion-webui
GitHub - camenduru/stable-diffusion-webui-colab: stable diffusion webui colab
https://mnya.tw/cc/word/category/ai-drawing
題外話
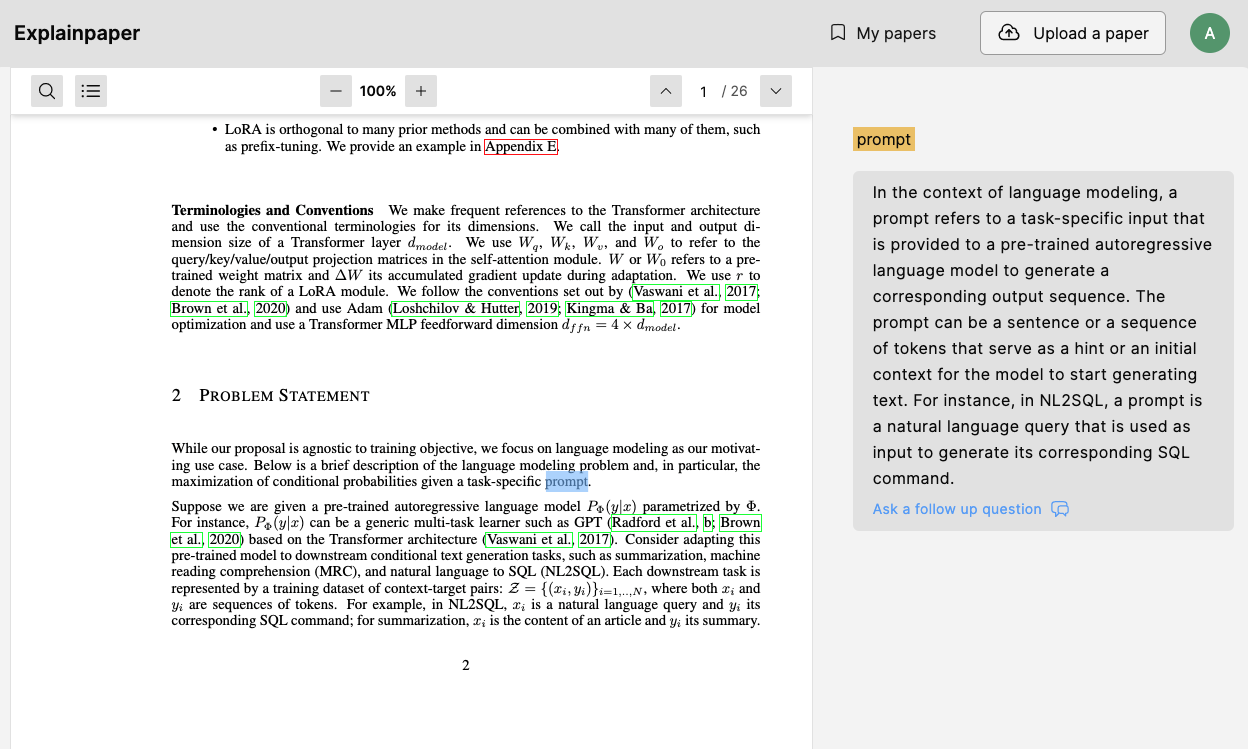
最近有相當多的 AI 工具,在未來要如何有效利用這些工具決定了生產力的多寡,這邊推薦大家一個看論文可以幫助閱讀的網站 Explainpaper,只要反白你看不懂的文字,AI 就會基於整篇文章幫你解釋。雖然我也是偶而才用而已,而且不見得每次的解釋都很好,但這是個趨勢,論文這麼多,讓 AI 看比較快。。。
在我被 AI 取代之前貢獻點微薄的知識,希望能幫到大家:)
參考資料:
Cheng-Han Chiang, Yung-Sung Chuang, Hung-yi Lee, “AACL_2022_tutorial_PLMs,” 2022.