UNIT 介紹 - Unsupervised Image-to-Image Translation
Ming-Yu Liu, Thomas Breuel, Jan Kautz, “Unsupervised Image-to-Image Translation Networks” NIPS 2017 Spotlight, arXiv:1703.00848 2017
UNIT 是我認為在GAN領域中的一個很大的進展。
UNIT - Unsupervised Image-to-Image Translation
由Nvidia團隊Ming-Yu Liu提出,被刊登在NIPS2017.
我們可以先看一下 Two Minute Papers當中如何的介紹他。
作者有將程式碼釋出 Github:
請注意,目前版本的實作可能會和論文的有出入,要將branch切去version_02
成果圖


簡介
本文是在說圖片的風格轉換(style transfer),如貓轉成狗,
這幾年風格轉換(style transfer)在GAN領域中算是很火紅的話題,
大概從2015年紅到現在,相關的論文不少,有興趣的可以自己理解。
概念
Unsupervised
標題為:Unsupervised Image-to-Image Translation
這邊的Unsupervised的概念如下
- 將兩個不同的dataset的圖片一起訓練, 例如:貓和狗
- 以往都是成對的資料輸入,以手勢來說,就是兩個人都比同樣的手勢,而這篇論文是可以不用成對的輸入。
Latent Space
此paper的核心概念為Latent Space(共同特徵)。
假如我們輸入的dataset是貓和狗,
他們其實會有一些共同的特徵,如眼睛、鼻子、嘴巴、耳朵。
我們的目標是希望可以學會這些特徵,
如我們輸入大眼睛的狗狗,可以生成出大眼睛的貓咪照片
架構如下
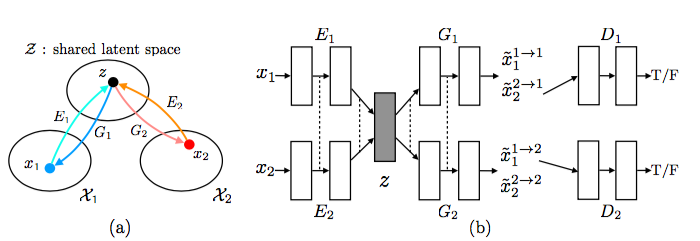
如上圖我們可以看到
- 2個encoder(下方稱作 Encoder-A, Encoder-B)
- latent space(中間灰色部分)
- 2個decoder(下方稱作 Decoder-A, Decoder-B)
- 2個discriminator
作者很貼心的幫我們列出每個model的結合,如Encoder + Decoder(Generator) = VAE。

這部分就屬於歷史演進了,有興趣的可以去研究GAN的進展。
大家都是站在巨人的肩膀上做研究。
Model 細節
VAE => Encoder + latent space + Decoder(Generator)
- Encoder-A, Encoder-B
- 會學到各自dataset(A, B)的特徵,映射到一個latent space。
- Decoder-A, Decoder-B
- 會學到如何透過latent space還原出一張符合我們期望的圖片。
- Discriminator-A, Discriminator-B
- 會告訴Decoder說,這張圖片是不是好的,不好就給我再努力。
舉例
目標:輸入大眼睛的狗狗,要輸出大眼睛的貓咪。
Dataset-A為狗,Dataset-B為貓
我們期望Encoder可以學會如何找到共同的特徵,如眼睛、鼻子、嘴巴、耳朵。
希望Decoder可以從latent space解碼出各自的特徵,
因為latent space包含了貓和狗的各自特徵,
那我們的decoder-B 要找出如何還原貓的圖片,還要像輸入之狗的特徵。
此時Discriminator做的事就是當個嚴師,encoder和decoder越來越棒。
weight sharing
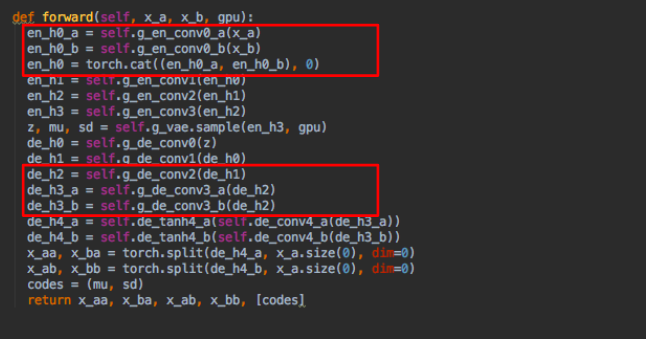
如果認真再認真看架構圖,會發現有虛線的部分。
虛線的部分是weight sharing
- Encoder的前幾層是分開的,但後面的會連起來,
- Decoder的前幾層是連起來的,但後面的會分開,
透過這方式學習共通的特徵(latent space)。
weight sharing 核心程式碼
略過的部分
論文前面講了一堆數學,
簡單來說就是推測latent space的分佈為Gaussian
本paper都是基於這概念作延伸
略過loss function => 有興趣的自己看論文,有點多。
文末小結
The current framework has two limitations.
First, the translation model is unimodal due to the Gaussian latent space assumption.
Second, training could be unstable due to the saddle point searching problem.
那對於第一點的unimodal
在2018年時Nvidia團隊又提出一個MUNIT的論文,解決這了unimodal的問題。
MUNIT近期會再寫一篇文章介紹。