MUNIT 介紹 - Multimodal Unsupervised Image-to-Image Translation
Xun Huang, Ming-Yu Liu, Serge Belongie, Jan Kautz, “Multimodal Unsupervised Image-to-Image Translation” arXiv preprint arXiv:1804.04732
ECCV 2018 paper
作者有將程式碼釋出 Github
本文的介紹的程式碼版本 Github_version_9199eaa
成果圖


簡介
本文是在說1對多的圖片的風格轉換(style transfer),如貓轉成多張狗的圖片,
提出可透過學習圖片的 content code 以及 style code,之後透過這兩個變數做圖片生成。
此篇是從UNITarXiv:1703.00848 2017演進的
我之前有寫過UNIT的介紹,如果有興趣的話可以看看UNIT介紹
原本UNIT可以看作是貓和狗的 1 to 1 對應
但MUNIT,多了一個 M -> Multimodal,可以看作是 1 to Many。
相關論文介紹
此篇概念為UNIT + Bicycle GAN的結合
UNIT
unsupervised learning (不需pair instances)
可以學到兩個dataset共同特徵,
如貓和狗就會學到眼睛、鼻子、嘴巴。
Bicycle GAN - NIPS 2017
supervised learning 透過 pair instances
學到共通特徵,然後經由random一個數值來改變輸出,
以達到 1 to Many,
btw這篇提出的訓練方法也挺有趣的,
使用兩種model做訓練,
但是兩種model的部分component相同的。
btw,
Bicycle GAN是為了解決 2017 CVPR的paper : pix2pix
因pix2pix只能的1對1的輸出
Augmented cyclegan
同一時間,也有人做了一個類似功能的model,有興趣的可以看看。
概念
Multimodal
標題為:Multimodal Unsupervised Image-to-Image Translation
這邊的Multimodal指的是給定一張圖片可以生成多個圖片。
專業一點的說法就是stochastic model -> 每次都會出現不同的圖片
stochastic model 的對比為 deterministic model
deterministic model 每次都會生出固定的圖片 1 to 1 Mapping
Unsupervised
標題為:Multimodal Unsupervised Image-to-Image Translation
這邊的Unsupervised的概念如下
- 將兩個不同的dataset的圖片一起訓練, 例如:貓和狗
- 以往都是成對的資料輸入,以手勢來說,就是兩個人都比同樣的手勢,而這篇論文是可以不用成對的輸入。
content code / style code
此paper的核心概念為content code / style code
content code
我們可以想成是每個class共有的特徵,如狗和貓都有眼睛 嘴巴 鼻子
convolution layer使用Instance Normalization(IN)
近年來style transfer方面的工作,使用IN能得到較好的結果
不過看文章的時候記得注意這篇文章的日期,這領域進步的太快。。。
style code
我們可以想成是每個class各自的特徵,如狗有柯基犬和哈士奇,雖然都是狗,但外表差很多
convolution layer使用Batch Normalization
論文指出,這邊不用IN是因為,每個style有各自的特性分佈。
如果使用IN會將mean和variance移除。
這樣不管S1, S2怎麼train, 可能都會產生差不多的圖片。
概念如下 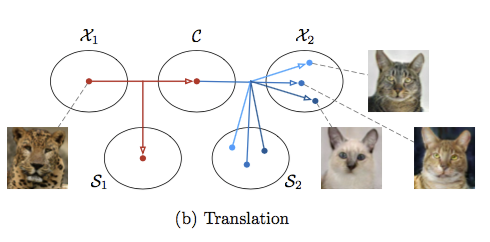
如上圖我們可以看到
- X1 - input image
- X2 - output image
- C - conten code,每張圖片映射到一個content code, 記錄共有的特徵。
- S - style code,X2的圖片產生是基於S2的style code(這部分為random產生),不同的style code產生不同的圖片。
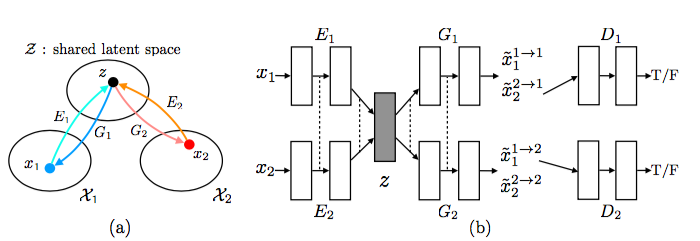
model 架構
encoder - decoder 架構如下 
這邊的MLP是multilayer perceptron,可看作是linear model。
MLP結合AdaIN那段太過複雜,有興趣的自己去看程式碼。
但是這model是GAN,不過論文中沒有整體架構的圖片
因此用UNIT的做示意圖,因為架構差不多,除了前半部有點改變
可以自己腦補想說 z -> content code + style code
loss function
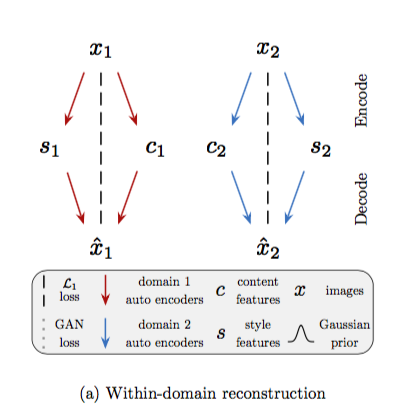
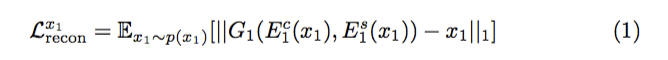
上圖可看作我們希望自己的reconstruction error要最小,
意思是一張圖片(x)進入encoder再進去decoder出來的結果(y)
希望x和y相近。
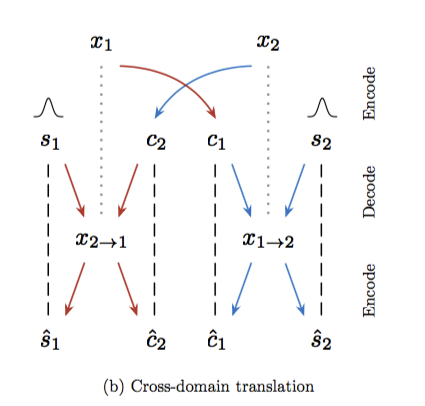
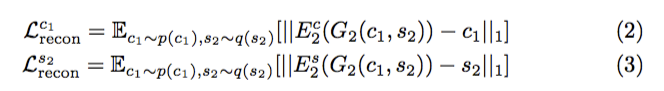
上圖可看作我們希望自己的latent reconstruction error要最小,
(2)意思是大眼睛的狗狗丟進model也要生出大眼睛的貓咪 希望x和y的content code相近。
(3)意思是科基狗丟進decoder解碼後再編碼還能夠知道這style code是柯基狗 希望x和y的style code相近。
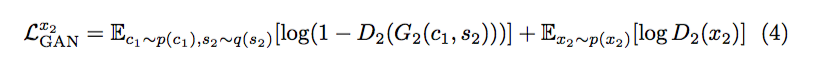
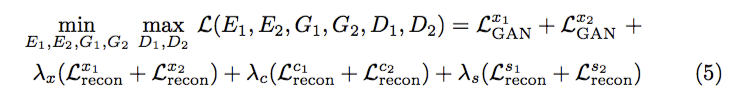
λ為自定義變數,可參考github中的.yaml檔案。
程式碼 拆解
config以edge2shoes_folder.yaml為例
Style code
隨機產生style code,
舉例狗的dataset,透過style code決定該生成出哈士奇或者是柯基。
- parameters:
- style dim : int
- config set : 8
- description:
- 這邊設定 2個domian的style code -> random
- sample出 (8, style_dim, 1, 1) 個ramdon value當作style encode
- output:
- self.s_a : ndarray or float
- self.s_b : ndarray or float
- code:
self.style_dim = hyperparameters['gen']['style_dim']
# fix the noise used in sampling
self.s_a = torch.randn(8, self.style_dim, 1, 1).cuda()
self.s_b = torch.randn(8, self.style_dim, 1, 1).cuda()
gen_update
- description:
- loss_gen_adv_a - 前兩個就是gan的基本loss - lsgan
- loss_gen_recon_x_a = xa encoder 經過fa decoder 的差別
- loss_gen_recon_s_a = xa encoder 經過fa decoder 再encoder style code的差別
- loss_gen_recon_s_a = xa encoder 經過fa decoder 再encoder content code的差別
-下面的weight config設定為0 可以不用看
- loss_gen_cycrecon_x_a = cycle loss xa ->fb(xa) ->fa(_) 後和 x的差別 - loss_gen_vgg_a = 圖片經過vgg 獲得的feature map相減 - code:
self.gen_opt.zero_grad()
s_a = Variable(torch.randn(x_a.size(0), self.style_dim, 1, 1).cuda())
s_b = Variable(torch.randn(x_b.size(0), self.style_dim, 1, 1).cuda())
# encode
c_a, s_a_prime = self.gen_a.encode(x_a)
c_b, s_b_prime = self.gen_b.encode(x_b)
# decode (within domain)
x_a_recon = self.gen_a.decode(c_a, s_a_prime)
x_b_recon = self.gen_b.decode(c_b, s_b_prime)
# decode (cross domain)
x_ba = self.gen_a.decode(c_b, s_a)
x_ab = self.gen_b.decode(c_a, s_b)
# encode again
c_b_recon, s_a_recon = self.gen_a.encode(x_ba)
c_a_recon, s_b_recon = self.gen_b.encode(x_ab)
# decode again (if needed)
x_aba = self.gen_a.decode(c_a_recon, s_a_prime) if hyperparameters['recon_x_cyc_w'] > 0 else None
x_bab = self.gen_b.decode(c_b_recon, s_b_prime) if hyperparameters['recon_x_cyc_w'] > 0 else None
# reconstruction loss
self.loss_gen_recon_x_a = self.recon_criterion(x_a_recon, x_a)
self.loss_gen_recon_x_b = self.recon_criterion(x_b_recon, x_b)
self.loss_gen_recon_s_a = self.recon_criterion(s_a_recon, s_a)
self.loss_gen_recon_s_b = self.recon_criterion(s_b_recon, s_b)
self.loss_gen_recon_c_a = self.recon_criterion(c_a_recon, c_a)
self.loss_gen_recon_c_b = self.recon_criterion(c_b_recon, c_b)
self.loss_gen_cycrecon_x_a = self.recon_criterion(x_aba, x_a) if hyperparameters['recon_x_cyc_w'] > 0 else 0
self.loss_gen_cycrecon_x_b = self.recon_criterion(x_bab, x_b) if hyperparameters['recon_x_cyc_w'] > 0 else 0
# GAN loss
self.loss_gen_adv_a = self.dis_a.calc_gen_loss(x_ba)
self.loss_gen_adv_b = self.dis_b.calc_gen_loss(x_ab)
# domain-invariant perceptual loss
self.loss_gen_vgg_a = self.compute_vgg_loss(self.vgg, x_ba, x_b) if hyperparameters['vgg_w'] > 0 else 0
self.loss_gen_vgg_b = self.compute_vgg_loss(self.vgg, x_ab, x_a) if hyperparameters['vgg_w'] > 0 else 0
# total loss
self.loss_gen_total = hyperparameters['gan_w'] * self.loss_gen_adv_a + \
hyperparameters['gan_w'] * self.loss_gen_adv_b + \
hyperparameters['recon_x_w'] * self.loss_gen_recon_x_a + \
hyperparameters['recon_s_w'] * self.loss_gen_recon_s_a + \
hyperparameters['recon_c_w'] * self.loss_gen_recon_c_a + \
hyperparameters['recon_x_w'] * self.loss_gen_recon_x_b + \
hyperparameters['recon_s_w'] * self.loss_gen_recon_s_b + \
hyperparameters['recon_c_w'] * self.loss_gen_recon_c_b + \
hyperparameters['recon_x_cyc_w'] * self.loss_gen_cycrecon_x_a + \
hyperparameters['recon_x_cyc_w'] * self.loss_gen_cycrecon_x_b + \
hyperparameters['vgg_w'] * self.loss_gen_vgg_a + \
hyperparameters['vgg_w'] * self.loss_gen_vgg_b
self.loss_gen_total.backward()
self.gen_opt.step()
dis_update
- 簡介:
訓練discriminator
輸入兩張圖片,各自轉成不同的domain。
使用各自的content code,
但是使用隨機的style code,
去encode出一張圖片,
希望能騙過discriminator
- code:
self.dis_opt.zero_grad()
s_a = Variable(torch.randn(x_a.size(0), self.style_dim, 1, 1).cuda())
s_b = Variable(torch.randn(x_b.size(0), self.style_dim, 1, 1).cuda())
# encode
c_a, _ = self.gen_a.encode(x_a)
c_b, _ = self.gen_b.encode(x_b)
# decode (cross domain)
x_ba = self.gen_a.decode(c_b, s_a)
x_ab = self.gen_b.decode(c_a, s_b)
# D loss
self.loss_dis_a = self.dis_a.calc_dis_loss(x_ba.detach(), x_a)
self.loss_dis_b = self.dis_b.calc_dis_loss(x_ab.detach(), x_b)
self.loss_dis_total = hyperparameters['gan_w'] * self.loss_dis_a + hyperparameters['gan_w'] * self.loss_dis_b
self.loss_dis_total.backward()
self.dis_opt.step()
參考資料:
“Multimodal Unsupervised Image-to-Image Translation” arXiv preprint arXiv:1804.04732