cGANs with projection介紹
Takeru Miyato, Masanori Koyama, “cGANs with Projection Discriminator arXiv:1802.05637
ICLR 2018 paper
作者有將程式碼釋出 Github
使用深度學習框架Chainer實作。
還有使用ICLR2018的Spectral Normalization的方法。
成果圖


簡介
基於cGANs,提出一個能增強cGANs模型的一個方法,
在Image generation 以及 super resolution的方法在這篇paper都有不錯的成果。
cGANs => conditional GAN
可以想成是給discriminator透過concat的方式加入一個condition(正解y),
讓discriminator訓練得更好,
從而讓G也能夠有更好地發揮。
而原本cGANs都是使用concat的方式串起y,
cGANs with projection就是將concat的部分改成projection,
就是拉出一條路,與y做inner product。
歷史演進
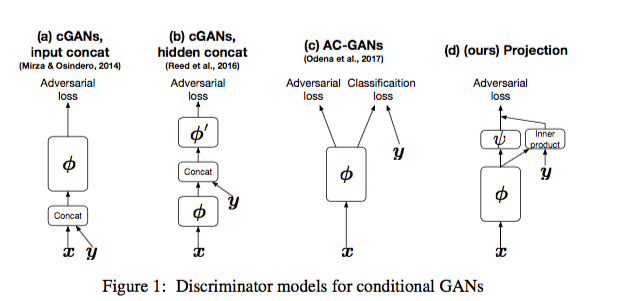
- (a) cGANs input concat
以往我們在GAN中, discriminator輸入的都是Generator產生的東西(x), cGANs 就是在discriminator中的input改為x加上y(ground truth), 讓discriminator可以被訓練得的更好更加的穩定 簡單且有效的方法!
- (b) cGANs hidden concat
發現了在hidden layer 和 y 做concat的結果會更好
- (c) AC-GANs
他不只是有adversarial loss, 在最後還有輸出一個classify的結果, 這樣變成有兩個loss可以bp, 結果是比較好。
- (d) Projection
可以看到就是在hidden layer的時候拉出來(引用了b的優點) 並且和y做inner product, 最終比單單使用concat結合y相比, 此方法達到比較好的結果。
概念

下方簡略帶過可跳過。
紅色的框框是cGANs的想法,
給定x中y發生的機率,
| 因為p(y | x)我們不知道, |
因此會希望訓練一個model,
| 用q(y | x)來逼近他 |
希望兩個模型的distribution輸出的要很像
(likelihood的想法)。
那他的做法是藍色框框的部分,
為什麼是這樣呢,我們下面再做介紹。
這部分是在做inner product,
Y: one hot encoding label V: denote the matrix consisting of row vector Vc Embeding matrix - 64dim

藍色的框框是指,如果我們真的將q(我們訓練的model),
真的和訓練的測資集p夠像的話,
那學會的feature相減的話,那個值應該要是小的。
而我們知道類神經網路可以逼近function,
因此我們可以希望藍色的框框有著紅色的框框的想法。
那(6)的式子其實就是我們的model概念。
2018/06/12 - update
今天我突然覺得這部份怪怪的,我覺得這部分一直都不是很能夠理解
目前我的理解是
其實這邊根本都不用管,
你就想成是 one hot 的 y 對 embedding 的 V 拿到專屬於自己class的feature vector。
左邊的這個φ(x)會學到要如何與右邊的各自的class vector來做到讓inner product變小。
透過hinge loss來做一個評分依據。
模型架構
Image generation
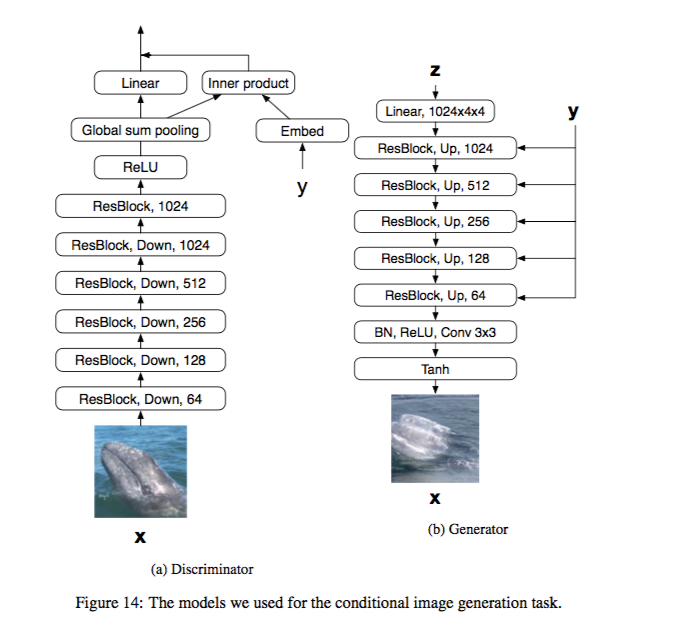
挺有趣的是他還有做一個category morphing。
只要將G輸入的Y值做改變(舉例category 1 = 0.7, category 2 = 0.3),
就可以產生這樣的效果。

Super resolution
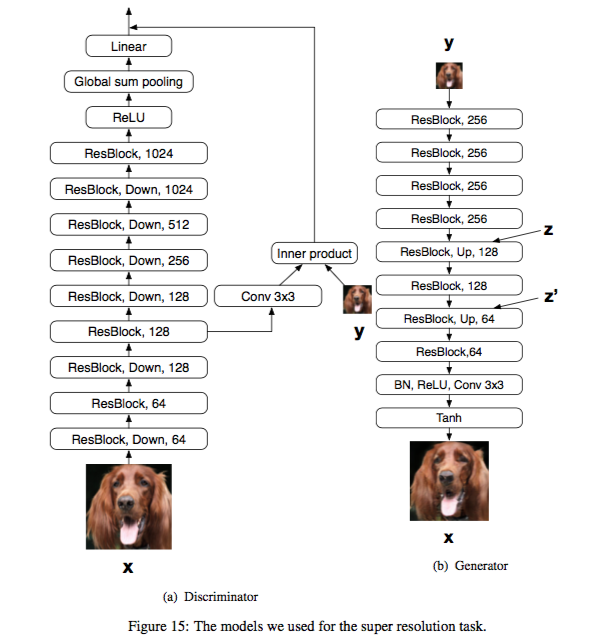
這邊值得一提的是,
discriminator那邊的conv 3X3,
其實是將128 channel -> 3 channel,
這樣才能和輸入圖片做inner product。