Grad-CAM 介紹 - Grad-CAM:Visual Explanations from Deep Networks via Gradient-based Localization
Ramprasaath R. Selvaraju, Michael Cogswell, Abhishek Das, Ramakrishna Vedantam, Devi Parikh, Dhruv Batra, “Grad-CAM: Visual Explanations from Deep Networks via Gradient-based Localization”arXiv:1610.02391
此篇為介紹CNN視覺化的一種方法Grad-CAM, 看完後會對Attention或是CNN視覺化有個概念。
前言
會看這篇論文主要是希望對Attention的機制做一個了解。
前陣子看了兩篇Paper
- 2018 CVPR - TbD-Net
- 2018 CVPR - DA-GAN
所以對於Attention的細節挺感興趣的。
不過網路上看到許多質量很高的Grad-CAM的文章,
有興趣的人去參考連結那邊看。
看完這篇對一些類似的工具LIME github/論文“Why Should I Trust You?” Explaining the Predictions of Any Classifier
會比較有感覺!
成果圖

左1是輸入圖片
左2是Guided Backpropagation是別的paper提出的方法,可參見Paper:Striving for Simplicity: The All Convolutional Net
左3開始都是Grad-CAM所能達到的結果。
簡介
近期在圖像識別的領域都是使用CNN,
但是以往大家不相信Deep learning是因為大家都說他是黑箱,
如果你說你的模型準確度很高,
那麼總要說一下為什麼這麼厲害吧,或是為什麼有些圖片辨認不出來。
因此論文提出視覺化後能解決幾個問題
能夠理解model在學什麼
能夠理解為什麼model會失敗
在ILSVRC-15中做weakly-supervised localization task有著不錯的表現
可以知道model是不是沒有學到物體的特徵,而是偷吃步(舉例來說資料集中有狗和貓,準確度很高,結果有可能是因為那個資料集中,狗就是有項圈,貓就是沒有。結果整個model都是在分辨有沒有項圈而已
可以讓model更穩健,從下圖可以知道AI系統其實會被騙,儘管你人眼看不出來,但有paper指出只要增加一些人眼看不出的Noise,就能讓AI的分類分錯。如果有興趣的話,可以看這個影片Two Minutes Paper:One pixel attack defeats neural network

除此之外在做圖像描述/圖像問答的工作中也表現得很好。
相關論文介紹
Paper:Network In Network - ICLR 2014
這篇是CNN的經典論文 提出了
- multilayer perceptron(MLP)
- 1X1 conv
- Global average pooling(GAP)
那我們這篇所需要的的概念是(GAP)
下面我們轉載凭什么相信你,我的CNN模型?(篇一:CAM和Grad-CAM)中的一部分做解說。
他這部分寫得太好,用他圖片的做解說
我們要先有一個概念,在CNN的最後一層所學習的通常是較為高階的資料。
舉例來說CNN前幾層可能是學會紋理,而後幾層就會學會哪邊是眼睛、嘴巴。
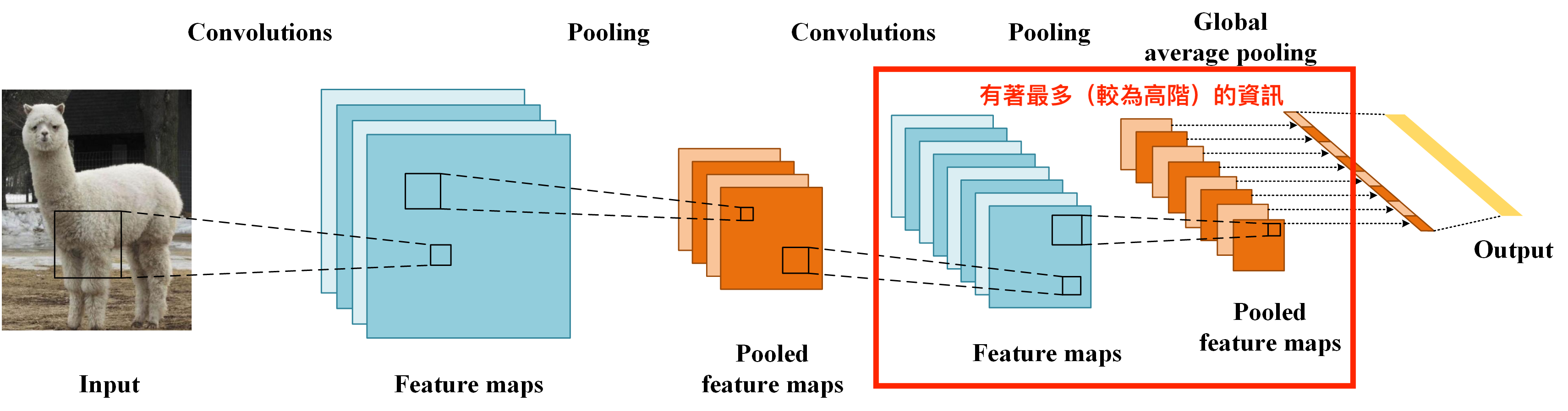
那只要我們經過GAP後,其實是在做下面這件事。
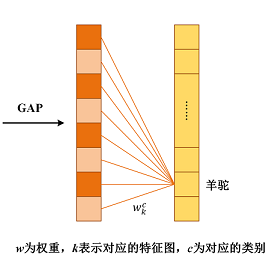
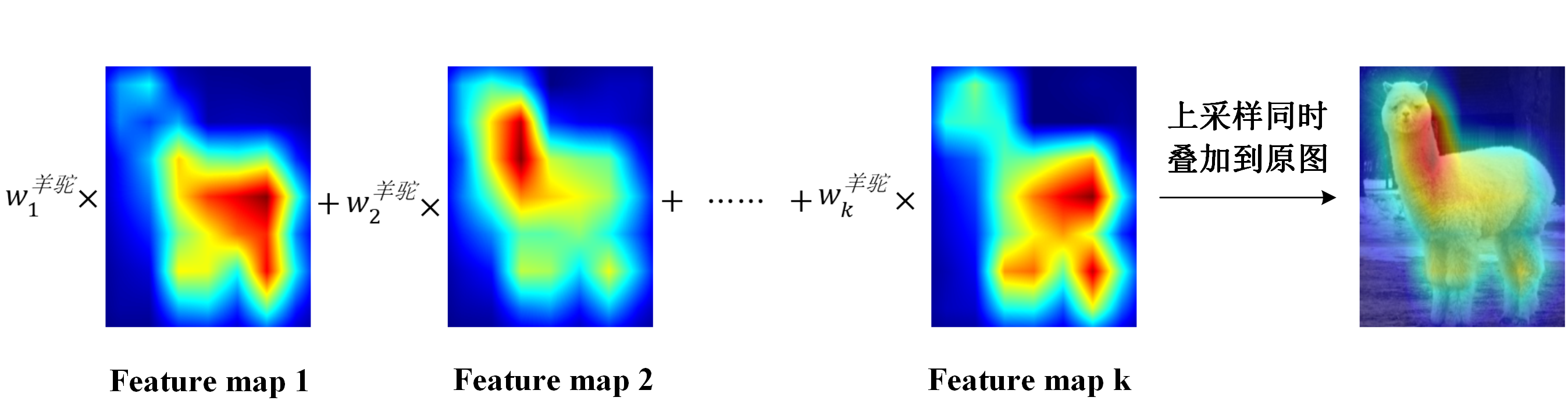
我們可以知道羊駝這個類別,是每個feature map搭配上各自的w權重而來的。
Paper:Striving for Simplicity: The All Convolutional Net
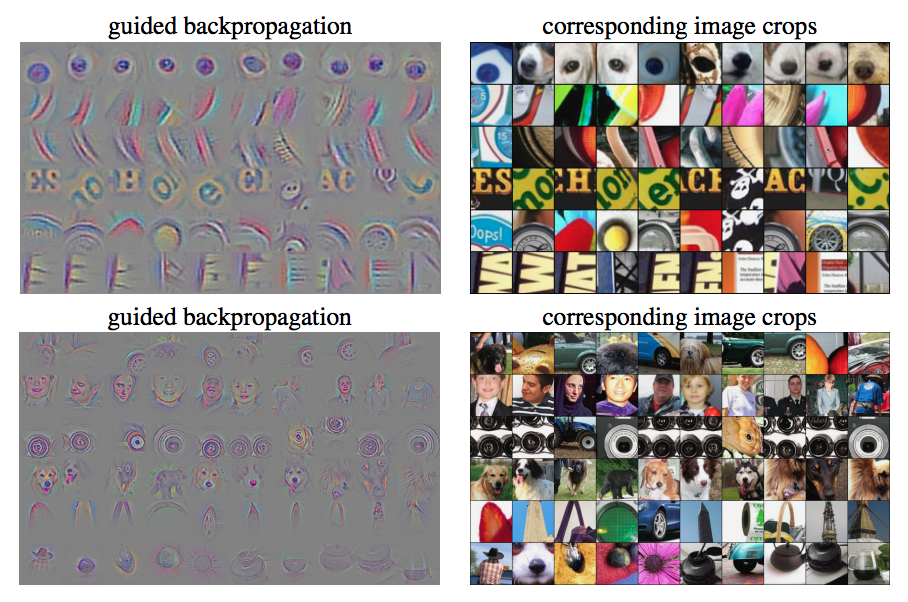
這篇的重點是Guided backpropagation。
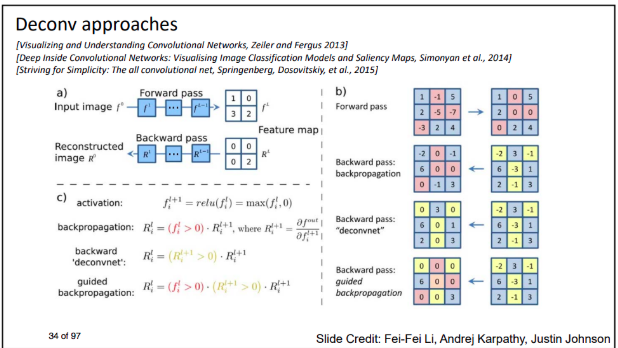
9宮格為CNN的某一層(3X3),
那右邊是在講解relu的forward以及backpropagation(BP),
Guided backpropagation的定義是們不只是要forward的時候,值為正的以外,
BP後的值也要是正的才會為正的,
其他皆為0。
概念大概為對feature map做BP(backpropagation)時,
如果某一個feature map的某個位置(x,y),
對該類別(classes)的相關度越高時,
那BP回去的話,
那個值通常會是正值,
因為要讓那個class的那些feature map權重調高。
結果圖為下圖。
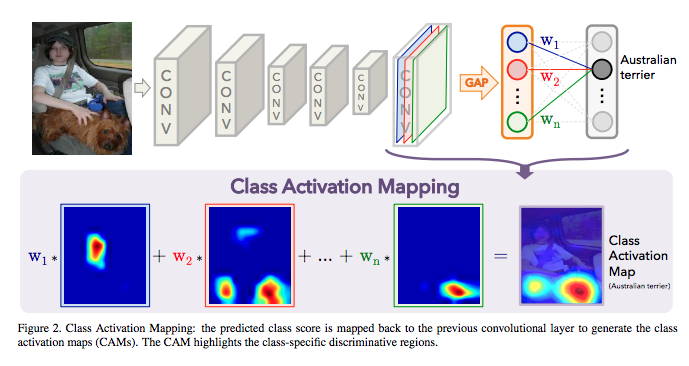
Paper:Learning Deep Features for Discriminative Localization - CVPR 2016
提出了Class Activation Mapping (CAM) 的方法,
目的也是理解/視覺化CNN。
他是透過最後CNN都接上GAP然後直接softmax,
獲得每個class的視覺化特徵。
本論文介紹
本文是改進CAM方法,
我們再來看一下CAM
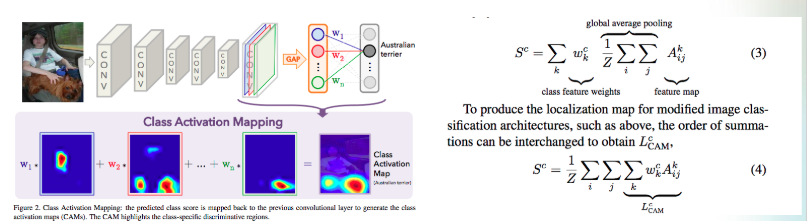
如果對Deep Learning有研究的話,
會知道並不是每個model最後都是GAP然後softmax。
因此CAM方法還不夠泛用。
那我們知道其實並不是GAP擁有最高階的資訊,
而是最後一層的feature map有最高階的資訊。
因此下方是我做的Grad-CAM表示,
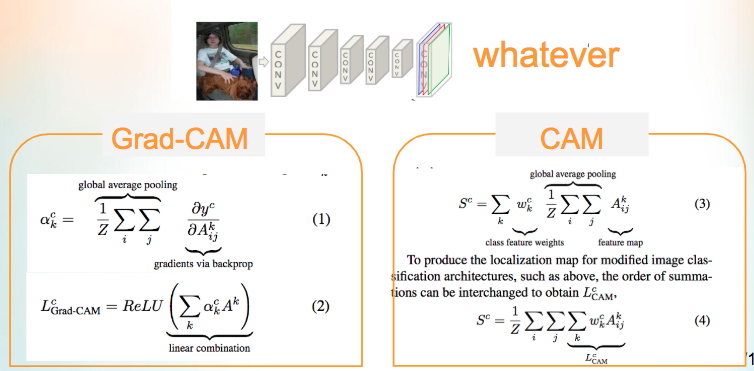
其實不需要GAP,只要透過從y propagation回來的數值,
其實就是在做跟GAP一樣的事情,
所以論文寫道Grad-CAM as a generalization to CAM.
(1)式所述說的事情是對k個feature map做BP(backpropagation),如果1…k的某一個feature map對該類別的相關度越高,那其實他(1)式的值是高的。
(2)式的ReLU做的事情是,將每個feature map相加,我們只對(x,y)為正數的值做處理。註:正數是基於公式1的結論。
這也很直覺,如果一張圖片和類別有正相關的話,那個那個值為正值。
那下圖是他提出的架構,其實左邊的圖片是一個比較細節的BP,
不過這圖片看不出來,建議去論文看圖會比較清楚
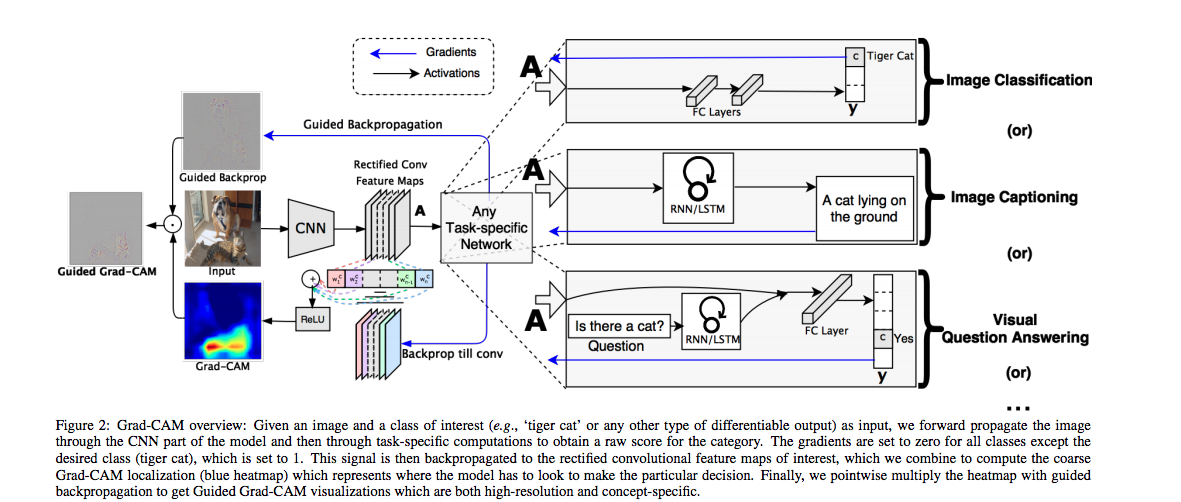
不管後面是接什麼工作,
我們都能夠拿CNN的最後一層來做視覺化的工作
VQA task(圖像問題回答)

Image captioning task(圖像語意理解)

參考資料:
paper:Grad-CAM: Visual Explanations from Deep Networks via Gradient-based Localization
Paper:Striving for Simplicity: The All Convolutional Net
Paper:Learning Deep Features for Discriminative Localization
Explainable AI 是什麼?為什麼 AI 下判斷要可以解釋?
凭什么相信你,我的CNN模型?(篇一:CAM和Grad-CAM)
“Why Should I Trust You?” Explaining the Predictions of Any Classifier