MSDNet 介紹 - Multi-Scale Dense Networks for Resource Efficient Image Classification
Gao Huang, Danlu Chen, Tianhong Li, Felix Wu, Laurens van der Maaten, Kilian Q. Weinberger, “Multi-Scale Dense Networks for Resource Efficient Image Classification”arXiv:1703.09844
ICLR 2018 oral(不過我在網路上沒找到影片),
在open review中得分相當的高,
此作者為CVPR 2017 Densenet的作者。
針對Image classifier的問題,
提出了二維的CNN模型架構,
帶給大家一個新的思維。
作者有將程式碼釋出 Github
簡介
MSDNet是基於CNN提出一個新的模型,
特色就是他的輸出分類層不只一個,
他可以依據你的計算資源多寡,決定你要計算的量。
不管如何到最後你一定能夠獲得一個結果。
可是為什麼我們以前會想要在CNN的最後面做分類呢?
因為這樣最準確,可以運用最多得資源做判斷。
因此可以知道如果我們分類層不在最後面,
而是每過幾層就輸出一個分類結果,難免會有些誤判。
因此後面會介紹了一連串的問題以及解法,
才能夠了解整個架構的設計理念。
整篇論文的兩大目標。
- anytime classification
不管怎樣程式運行到最後總要有個結果。 如果想像到智慧型手機就會有感覺, 如果我們的runtime限制是1秒, 有的人用新款的手機就能夠算比較多, 但是有人用幾年前出的手機,這種狀況也要顧慮到, 總不能1秒後跟我說抱歉算不出來。
- budget batch classification
如何用有限的資源將一堆圖片達到最好的分類效果。 資料集中會有簡單/困難的圖片(如下面馬的圖片), 何必每張圖片花費同樣的資源計算。

先看架構圖,等等大家才比較有想像空間
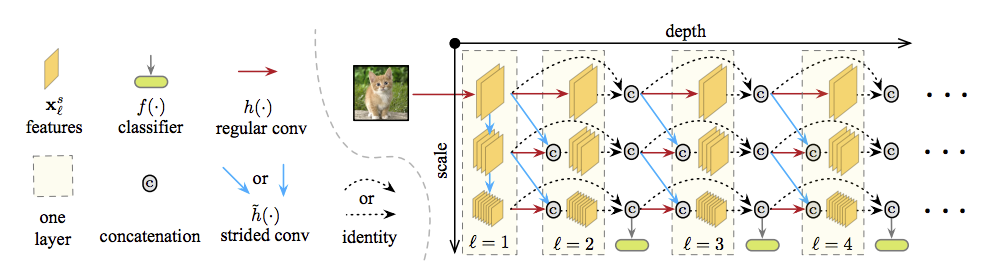
簡單介紹一下,
X軸
x軸是深度,可以理解的是越深學到的東西就越多,
這時候再接classifier就會有較高的精準度。
Y軸
y軸是scale,因為在前幾層的CNN,對於多尺度(scale)的理解並不是很好,
因此透過這種方式,讓整個model在前幾層也能夠有一定的多尺度適應能力。
讓前期的分類結果能更好一些。
下方的分類層
就是對圖像分類的動作,但這就是整個模型的關鍵!!
以往的CNN都是在最後才做分類的動作,
因為最後能學到最多的資訊,
那在前面分類總會有點風險,
詳情請見後方的問題探討。
Anytime classification
你可以想像有個老闆說:我們要開發一個圖像分類的APP,
於是你做得很開心做完了,給老闆驗收,
老闆就說怎麼我手機跑這麼久,可以1秒內就輸出結果嗎?
如果把圖像分類的功能是使用CNN的模型去做運算,有辦法讓所有手機都在1秒內輸出結果嗎?
一年出產那麼多不同型號的手機,我們沒辦法對每一支手機做調整。
更不可能為了每支手機都訓練一個model,
因此這部分的解法就是有多個輸出層,
並不用等到最後才有一個結果,
而是依據你能跑多少,輸出最後遇到的輸出層的結果。
這邊我們會假設我們所需的計算資源 B = Budget
我們其實無法明確知道B為多少,
因為每個case(Test Image)會讓我們花費的B是不一樣的,
但我們的Loss Function的目標是希望可以最小化B((base on 目前的dataset
L(f) = E [L(f(x), B)]P (x,B)
L(.) => loss function
B => 自定義
x => 一批輸入圖片
Budget batch classification
你可以想像Facebook上一天有多少人上傳圖片嗎?
我們隨便假設為10萬張,如果一張處理1秒的話,全部處理完要10萬秒。
當量大的時候,我們就會對效能開始要求,
一張照片能快0.001秒,我們都會開心。
因此提出了這個觀念,在一個批次中盡可能的把圖片分類好,並且又快。
解法也是有多個輸出層, 但是如果我們在前面的輸出層就有著可靠的結果,
那我們就開始處理下一張,不會繼續跑下去了。
你可以看看上面那張馬的圖片就知道,
有得圖片很容易分類(輸出層的該類機率極高),
但是有的要到很後面的分類層才能準確分類。
這邊我們會假設我們所需的計算資源 B = Budget
有一個dataset D = {X1, X2 … Xm}
我們會希望我們可以在B的計算資源中,處理完m筆資料。
L(f(Dtest), B)
L(.) => loss function
想法是他可以做到將簡單的測資壓在B/M的資源下做分類,
比較困難的測資可以使用B/M得資源下做分類。
這邊屬於soft constraint.
小結
所以發現不管是
- anytime classification
- budget batch classification
雖然看起來是兩個完全不同的問題,
但其實最後都導向了同一個結論,
就是在model中加入幾個輸出層。
相關論文
Adaptive Neural Networks for Efficient Inference
Tolga Bolukbasi, Joseph Wang, Ofer Dekel, Venkatesh Saligrama, “Adaptive Neural Networks for Efficient Inference”arXiv:1702.07811
有興趣的可以去看他在2017 ICML oral 演說的影片ICML2017 oral:Adaptive Neural Networks for Efficient Inference
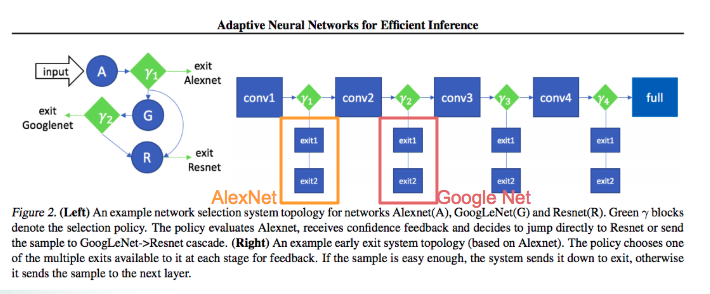
上圖為”Adaptive Neural Networks for Efficient Inference”的圖片,
並非本文的MSDNet架構
只是說這篇文章在做的事情又不太一樣,
他想要做的事情是讓綠色的r判斷說,這個測資簡單還是困難
如果簡單的話,就丟到前面比較簡單的模型做分類,
這篇論文的目標是屬於不降低原有的準確度,卻要加速model分類速度。
與anytime classification有點不同。
問題探討
Q1.對於Adaptive Neural Networks for Efficient Inference這篇paper有什麼問題能改進的呢?
A:
MSDNet的作者提出:這樣子前面AlexNet所學會的東西,
後面的Google Net/ ResNet沒辦法把那些資訊拿來用,
覺得有點虧,要想個辦法拿來用。
Q2:如果我們加上Early exits會遇到什麼問題嗎?
A:
MSDNet的作者提出:主要有兩個問題,
1.在前幾個classifier其實是透過少量的CNN去做判斷,
因此缺少了coarse scale(不同尺度)的分辨能力
2.如果加上Early exits其實會阻礙feature的訓練過程,
可以想到的是我classifier1希望辨認馬,所以馬的feature提高,
但是classifer2就會很困擾啊,因為這樣它又要微調一下他後面的參數。
我們可以從下方的圖看到說,如果在既有熱門的CNN模型中直接加入early exits
準確度的曲線會如何?
右邊的圖是說如果我們在某個位置加入了一個early exits, 對我們原先沒有加入分類器時的準確度比較。
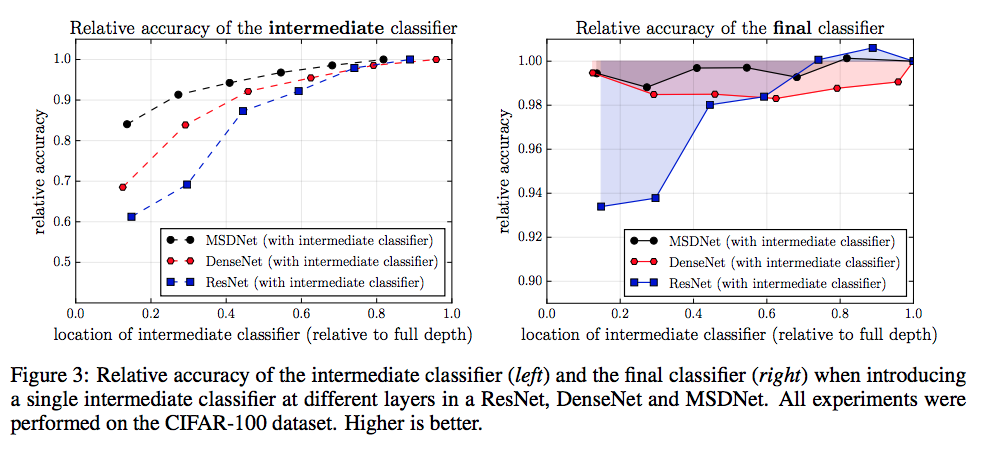
Q3:缺乏不同尺度的特徵(coarse-level features)要怎麼解決?
A:
我們可以從上圖(左)發現一件事情在Resnet有突然攀升的跡象,
為什麼呢?因為他在那個地方有經過pooling layer,
看看下圖有做筆記的會比較清楚
因此我們知道準確度提升的關鍵是要能夠適應不同尺度的特徵(coarse-level features)
那我們知道使用pooling Layer可以解決這件事情。
我們可以再往一開始的MSDNet架構圖去看就會明白為什麼要在y軸做所謂的縮小動作,
因為要讓前幾層有辦法處理coarse-level的問題。
Q4:前面的分類器會影響到後面的分類器怎麼解決?
因為從上上圖的右圖,
可以假定是因為我們在中間加入了early exits的分類器,
所以會影響到最終的準確度,
ResNet在早期加入一個early exits的影響最大,
會讓最終結果準確度降低7%
A:
使用DenseNet,因為我們發現,其實DenseNet就算用了early exits後,
他的準確度比較不會影響到最終的輸出分類準確度,
前面的layer會被classifier影響的話,
那就把更前面的layer資訊拿回來就好。
這好處是我們可以讓classifer前面的那個CNN專心的改進他的分類準確度。
綜合前面幾個問題的解答,我們可以用下面這張圖來表示,
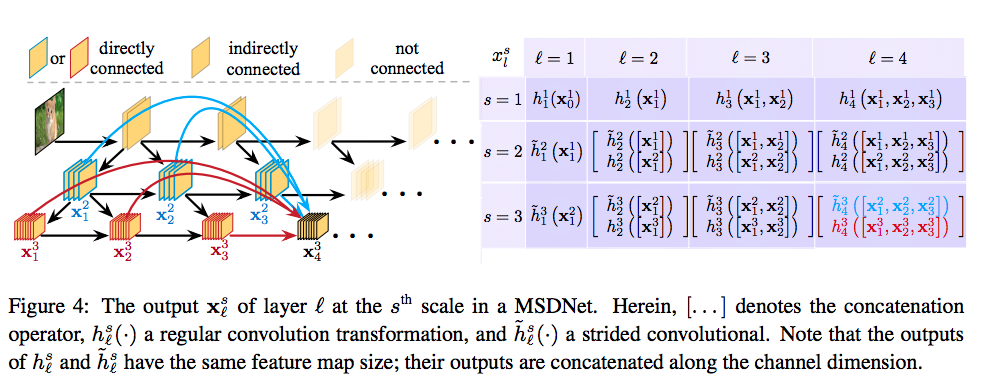
MSDNet 架構
將MSDNet拆解成5個部分作介紹
- First layer
- Subsequent layers
- Classifiers
- Loss function
- Network reduction and lazy evaluation
First layer
縱向y軸的連結,
主要是在處理Scale的問題,
就是做downsample的處理,
解決以往CNN早期無法處理不同尺度的特徵(coarse-level features)的問題
如上圖,我們的S-layers = 3 , 因此y軸有3層。
備註:只有第一層有垂直的連結
Subsequent layers
橫向x軸的連結
這邊我們可以注意到,當S>1的時候
他會有個對角線的連接,
將feature map做一個concatenation的動作。
Classifiers
每個綠色橢圓形的classifer是經由conv -> conv -> averaging pooling -> linear layer輸出分類結果
這時候再回想起一開始我們所說的兩個目標
- anytime classification
- budget batch classification
anytime classification
我們會一直跑,直到資源(Budget)用盡,會輸出最後輸出的classifier結果。
budget batch classification
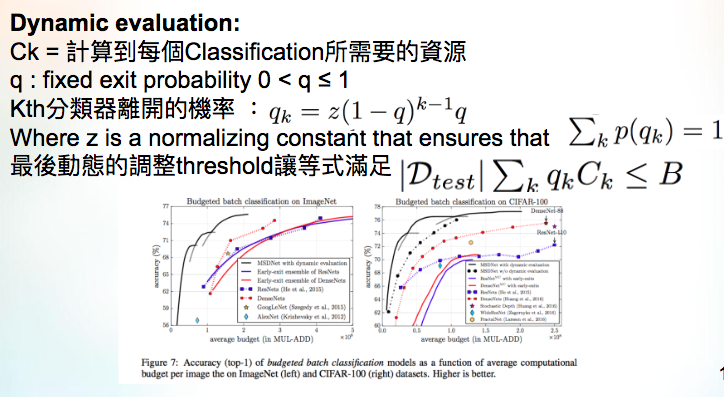
計算資源 B = Budget B單位 -> FLOPS (基於不同dataset給定不同的值,ImageNet為0.1~1.4 X 10的10次方)
當我們的分類輸出的某個分類超過一個threshold,這時候我們就確定離開。
決定每個classifier要大於多少thresholds theta-k有兩種方式
1.自己給定0~1之間,準確度要到達多少才離開。
2.Dynamic evaluation
可以想像,我們在訓練時在training set的準確度都高的可以,
但是我們在實際使用validation / test測試時,
準確度會下降,
因此當初所訂定的threshold,
沒辦法確保我們訂定的threshold真的可以提早的讓分類輸出,
因此我們需要動態調整,假如我們當初覺得應該要80%準確度就ok,
現在我們不是訂定threshold為80%,
而是定義每個classifier離開的機率為80%
因此我們看到下面這邊我整理的圖
Loss function
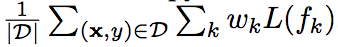
D => training set
k => 第k個classifier
w => classifer的權重,經驗法則來說全給1的結果還不錯。
L(fk) => cross entropy loss function
Network reduction and lazy evaluation
這邊是給出兩個方法減少MSDNets的計算資源
####Network reduction
看圖比較能理解,
我們不用整個X * Y的feature maps
我們只需要一個梯形的形狀可以讓最後一個classifier計算完就好了。
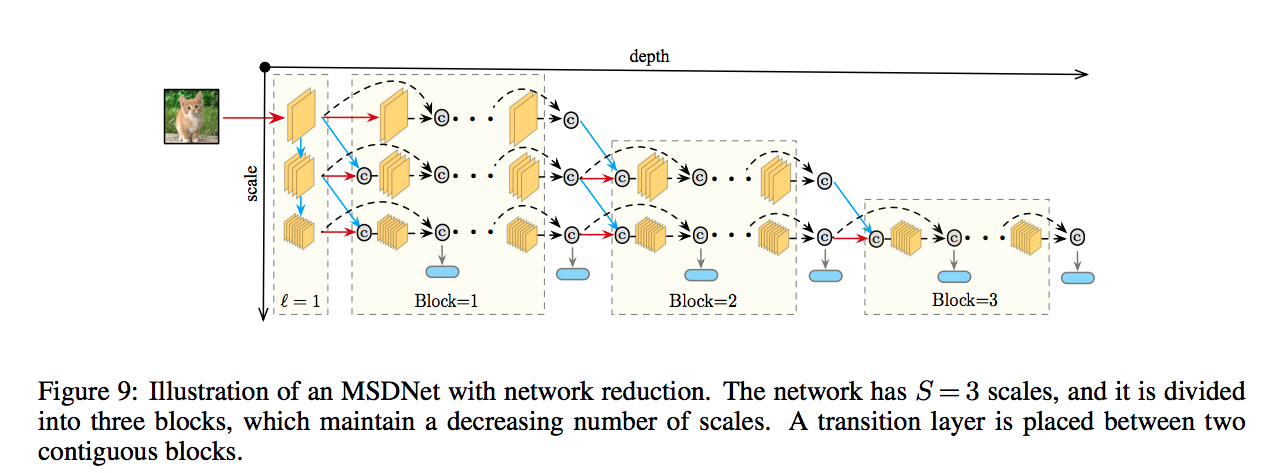
####Lazy evaluation
跟上面那張圖類似的概念,
我們知道影響第k個classifer的就是他的左上角那塊,
因此我們每次計算到下個classifer時,不會做多餘的計算。
夠用就好的概念。
實驗部分
在CIFAR-10, CIFAR-100, ILSVRC 2012上做測試,
各種結果很好。
下面看圖說故事好了,
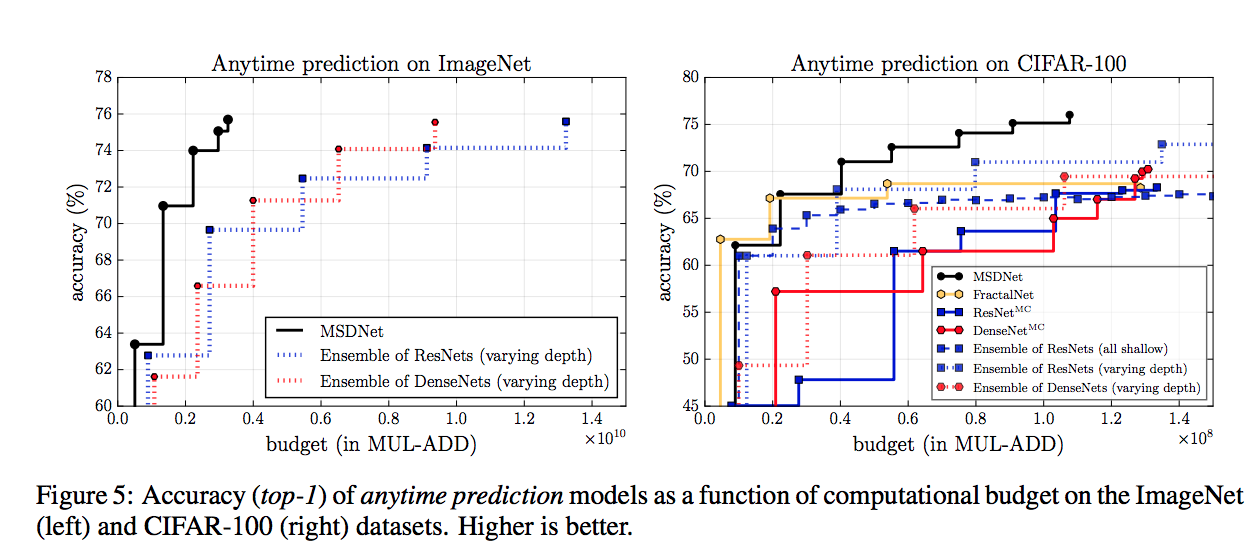
這邊的ResNet-MC 以及 DenseNet-MC 是指加入多個分類器(multiple classifiers,
可知在計算資源相同的比較下,
同樣都有多分類器(可以Anytime prediction)的情況下,
MSDNet的準確度比較下是相當高的。
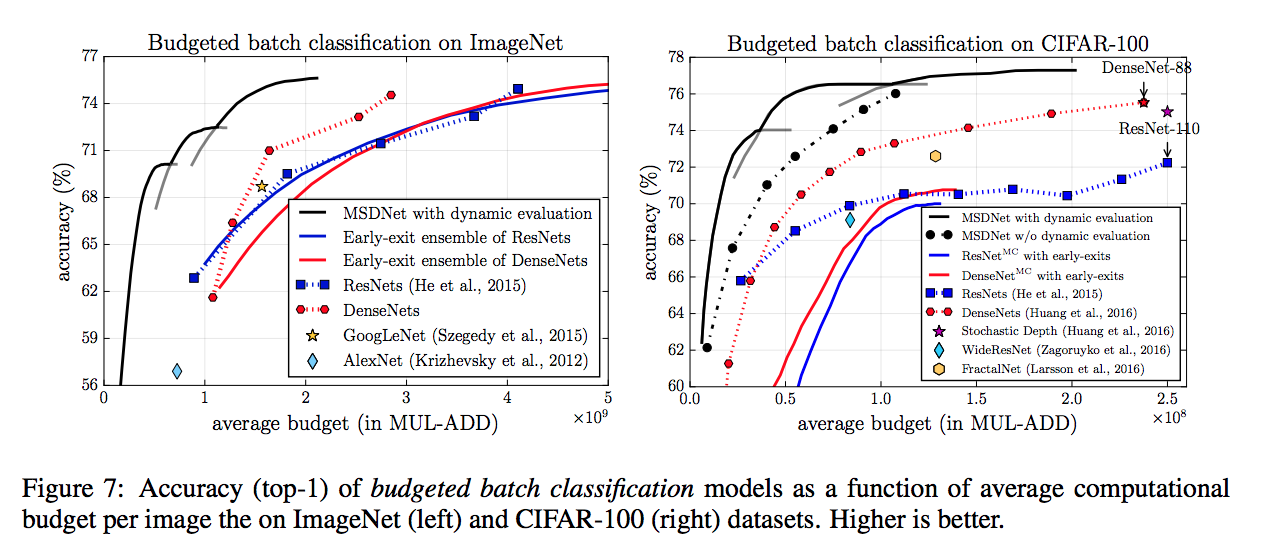
Dynamic evaluation的方法可以往前看。
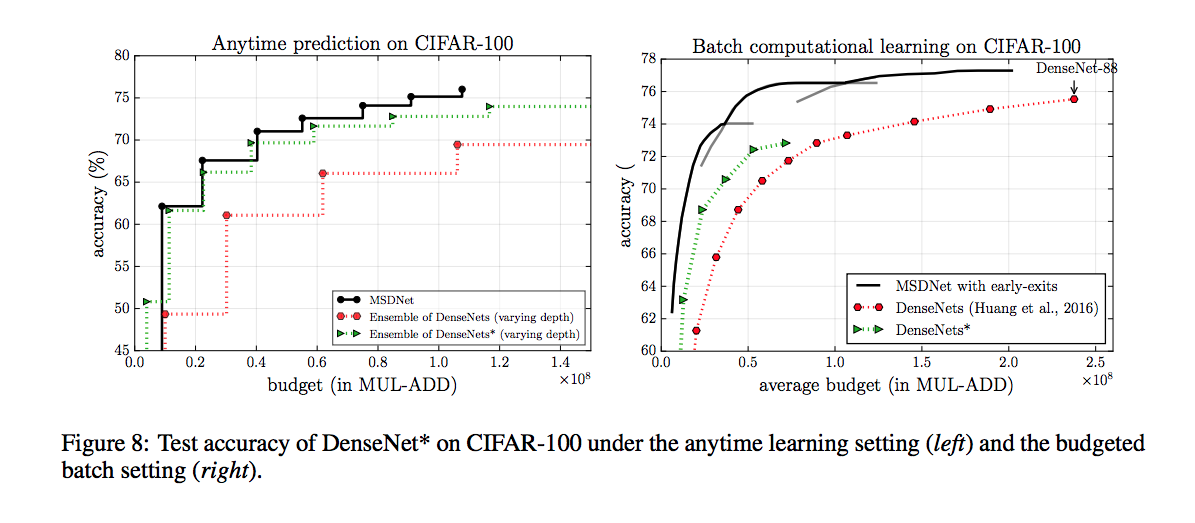
值得一提的是上面這張圖 DensNet*
連作者都說覺得有趣了,
大神都這麼說了,那我們已要覺得有趣啊,不然會被別人笑不懂。
他的想法是這樣的
在ResNet、DenseNet中,
以往我們是盡可能的保留high Resolution高解析度(前幾層)的資訊(feature map),
在high dimension資料可能會拉的權重高一點。
感覺比較可靠,但也會大量的消耗計算的資源
但這次在將DenseNet改成類似MSDNet的功能時,
在transition的時候採用更多low resolution低解析度(中後段)的feature maps,
讓最後面的時候可以吃到較多的低維度資料,
不像原本這麼依賴高維度的多feature map。
總之結果卻比較好了。
好到讓人驚訝!
結論
提出一個新的CNN架構 - MSDNet
這個Model基於兩個設計原則
- 可以適應多尺度的問題,在前期的輸出層能保持準確度。
- 內部的連接用DenseNet,可以確保多分類器不會互相影響
並且透過這個model,就可以達成budgets ranging 以及 CPU 限制的問題
作者也提出了未來的方向,
希望可以應用於 image segmentation
還有給出三個方向來改進目前的架構
- Model compression (Chen et al., 2015; Han et al., 2015)
- Compressing Neural Networks with the Hashing Trick((Chen et al., 2015)
- A deep neural network compression pipeline: Pruning, quantization, huffman encoding. (Han et al., 2015)
- Spatially adaptive computation (Figurnov et al., 2016)
- Spatially Adaptive Computation Time for Residual Networks, CVPR 2017
- More efficient convolution operations (Chollet,2016; Howard et al., 2017)
- Xception: Deep Learning with Depthwise Separable Convolutions(改良Inception v3)
參考資料:
Multi-Scale Dense Networks for Resource Efficient Image Classification
Adaptive Neural Networks for Efficient Inference
ICML2017 oral:Adaptive Neural Networks for Efficient Inference