SA-GAN 介紹 - Self-Attention Generative Adversarial Networks
Han Zhang, Ian Goodfellow, Dimitris Metaxas, Augustus Odena, “Self-Attention Generative Adversarial Networks”arXiv:1805.08318
PMLR 2019 paper
發文日: 2018 Apr 15
更新日: 2019 Dec 7
單純是因為我對這主題有興趣,
所以才看這篇的,
Github - Tensorflow : https://github.com/brain-research/self-attention-gan
第三方的重製 Github - Pytorch : https://github.com/heykeetae/Self-Attention-GAN
簡介
SA-GAN 提出透過 Attention 的機制來生成圖像,
傳統的 CNN-based GAN 是依靠鄰近並有限的 Pixel/Feature map 來生成該點,
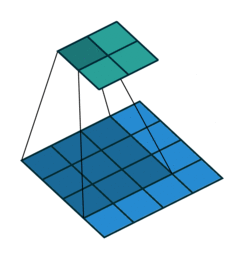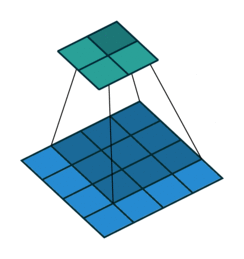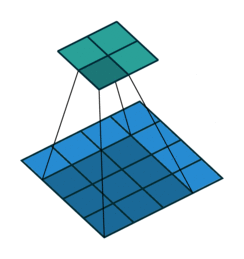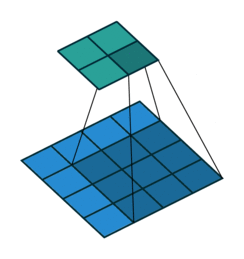
圖片出自: https://github.com/vdumoulin/conv_arithmetic
而此文提出使用 Self-attention(SA) 的機制來利用每個 Pixel 的資訊來生成該點。
簡單來說 SA 做的事就是找出該點與其他點之間的相關性,
我們可以來看到 SA 在 Semantic segmentation 上的視覺化。
下圖出自 OCNet: Object Context Network for Scene Parsing

其最右邊黑白的圖展示了該 Pixel (紅色十字架之處)與其他 Pixel 之間的相關性。
我們可以看到第一列的圖片是指在車子部分,
因此 Self-attention 會基於該點的 Feature map 去對其他點的 Feature map 去計算他們之間的相關性,
而此任務是語意分割模型,
因此我們會希望同個類別之間的相關性要是很高的,
而圖片中展示的就是該點當對應到其他 Pixel 是屬於同樣類別時,
他就會給予較高的能量表示這兩點是相關的(圖片中深藍的部分)。
而這就是我們希望 SA 所能夠達成的功能,
超越以往 CNN 只對周圍區域的理解,
將其改為全局的理解,
藉此來生成更精細的圖像。
但缺點是這樣子對每個 Pixel 去做計算之間的相關性是非常花費記憶體的,
因此 SA 的架構通常是在網路的深層,
其解析度已經被降低後才有辦法套用的~
SA-GAN透過上述的優點,在圖像生成(Image synthesis)的任務中達到了不錯的分數。
除了在 Generator 可以產生不錯的圖片之外,
在 Discriminator 中也可以透過 Self-Attention 的機制,
偵測整張圖片的一致性,
促使 Generator model 變得更好。
CNN 對於圖像生成的問題
如果你有認真的看過一些圖像生成的任務,
通常會發現背景都處理得不好,
儘管你的生成目標做得不錯(e.g.人臉 or 動物
但是如果圖片有這種大範圍(Long range)區塊(e.g.顏色 or 背景(天空)
往往這種部份生成的會不好。
因為 CNN 是透過 Filter(3X3 or 5X5的 Kernal size)經由 Sliding windows的概念,
然後透過每個 Filter 學習特徵,
可以想到的透過這種方式學習,
當要處理大範圍的影像時,
並不是一層 Layer 可以處理的,
因為通常需要好幾層 Layer 一起做搭配才能夠偵測出大範圍的區塊。(這也代表了訓練的困難性。
也因此可以想像到,為什麼 Long range的偵測是多麼的困難。
Attention 優勢
透過 Attention 可以偵測大範圍(Long range)區塊,
我們先看一下成果圖片 感覺一下

看到上方圖片的紅色框框那張圖,
因此我們可以知道該對該點做 Attention,
他會尋找整張圖片與該點相似的 Pixel/Feature map,
所以視覺化過後可發現背景是藍色的部分都給予了高權重,
這邊也展現出他的特性可以繞過去狗的頭!!
可以把這邊理解成 Non-local 的概念。
Model 架構
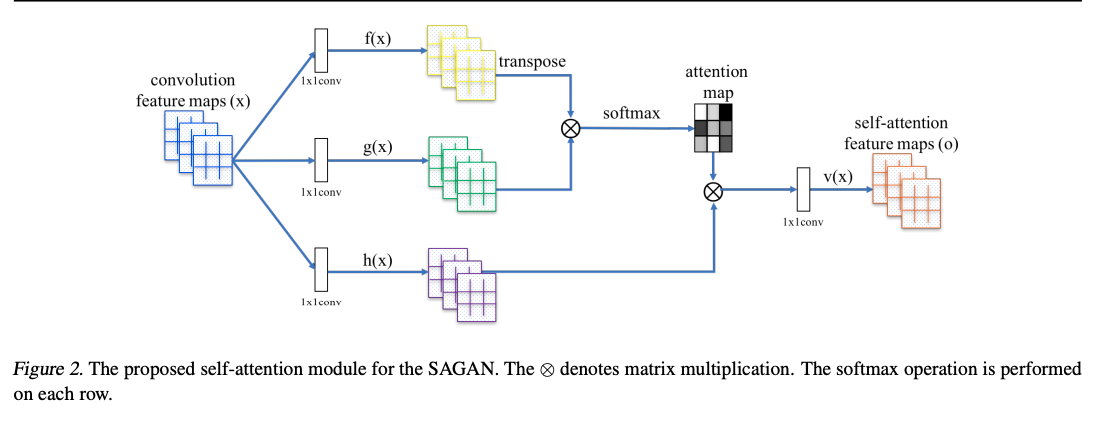
2018/07/17 更新
如果會好奇為什麼架構長這樣的話,可以閱讀相關的論文Attention Is All You Need簡介。
簡而言之 Self-attention 就是基於同一個 Feature map(x) 去做 Attention,
而上方的 f(x) 和 g(x) 所相成得出的結果就是 Attention,
可以先理解成該點 (0, 0) 與其他 Pixel 的相關性。 => Shape = (1 x N)
因此將它套用到整張圖片與其他 Pixel 的相關性。 => Shape = (N x N)
這邊其實有個小技巧,
就像上面說的 SA 的架構往往需要大量的記憶體,
所以這邊 f(x) 以及 g(x) 都會進行 Channel 的縮減,
來降低記憶體的用量。
原本維度可能是 (C, H, W) 經過後會變成 (C//8, H, W) =>此處會依照任務不同而改變。
這邊的 “X” 是指 Matrix multiplication。
大家看圖片可能會不知道為什麼要把 Feature map 做相 X 的動作。
一開始想會覺得 f(x), g(x), h(x)出來的維度是 C X H X W,
那是要怎麼相乘???
但是實際上看了程式碼時做卻是這樣。
C = Channel size
H = image height
W = image width
那 H X W 和 H X W 相乘, 想不通到底在幹嘛。
程式碼其實是將 N = H X W
所以目前的圖片已經被展開了,變成 C, N
那之為什麼轉置也很明顯了,
就是基於 C(每個不同的 Feature map),對每個 Pixel 做相乘。
這邊所出來的維度是 (N, N),即為每個 Pixel 間的相關性。
這邊又能延伸探討說 (C, N) x (N, C) 及 (N, C) x (C, N)不同的含義。
上方的探討可以去看 DA-Net, Dual Attention Network for Scene Segmentation (CVPR2019)
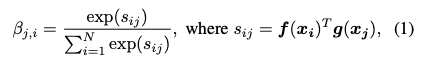
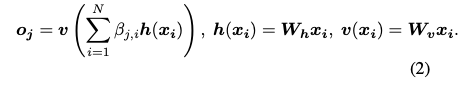
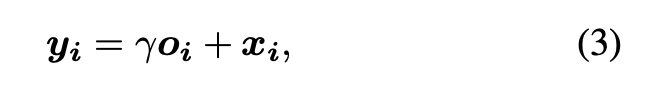
在公式(3),也給了一個很有趣的想法,
r 一開始為 0, 慢慢的才會給權重,
因為一開始的 Attention 可能還不穩定不能直接套用,要慢慢的讓他學,比重會越來越高。
這篇揭露 GAN 穩定的 tricks
Spectral normalization for both generator and discriminator
ICLR 2018的 Spectral normalizarion for generative adversarial network.
簡單來說就是比 BN 更新的方法,
這一兩年被廣泛使用於 GAN 架構,
概念就是不透過參數,
可以讓整個 Layer的 Spectral norm的權重為1
在Spectral normalization openreview中,挺多人回應的,看起來是真的不錯用。
不過原本 Spectral 適用於 Discriminator,
這邊他說其實SN用於Generator也可以。
Gans trained by a two time-scale update rule converge to a local nash equilibrium
NIPS 2017的Gans trained by a two time-scale update rule converge to a local nash equilibrium
論文裡面滿滿的數學。
簡單來說,以往 GAN 比較常用的 trick 是 Discriminator 每訓練個5次,Generator才 訓練一次。
那這篇文章是說給 Discriminator 多一點 Learning rate(2~5倍 e.g. G lr = 0.001 D lr = 0.005),
也是達到差不多的效果。
成果
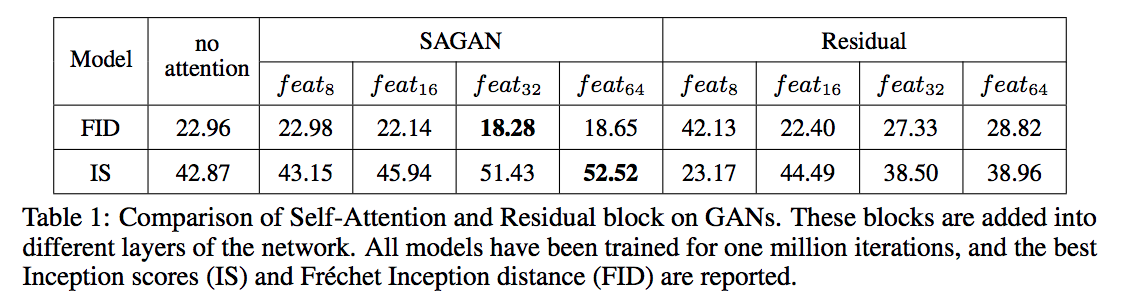
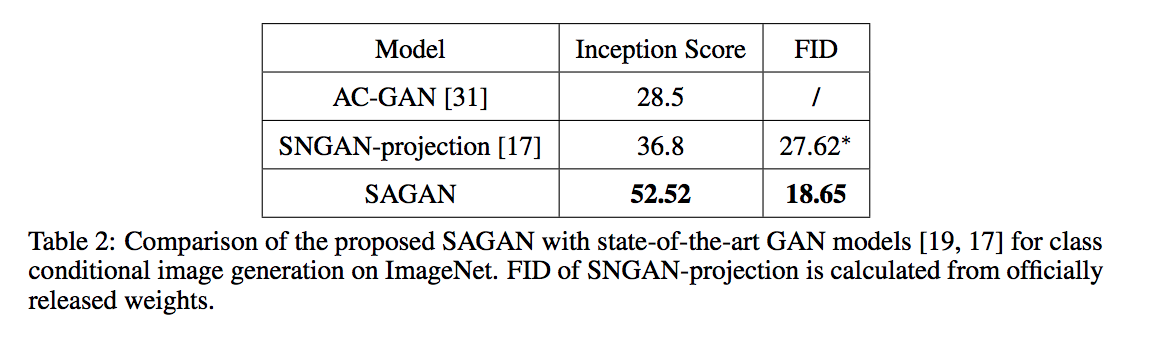
結果不錯呢!
其實他有幾個圖表在探討上方提到的 2 個 Trick,
如果有興趣的話就自己去翻論文吧~

最後這個結果作者給了一些挺有意思的說明,
首先說明一下這張圖,
每一格的最左邊是照片,上方都會有一些點,
每個點會經過一個 Attention 輸出結果(右邊3張圖)。
- 藍框
- 紅點:清楚地將鳥的身體依照顏色用 Attention 分了出來。
- 綠點:將背景的綠色顯現出來,甚至是穿過了鳥!!!
- 藍點:翅膀。
- 紅框
- 藍點:將前腳清楚的劃分出來
- 黃框
- 紅點:作者說這個展示出把背景劃分出來的能力,儘管顏色都不同。不知道各位怎麼看,我是覺得這個有點太浮誇。
參考資料:
Spectral normalization for both generator and discriminator
Spectral normalization openreview
Gans trained by a two time-scale update rule converge to a local nash equilibrium