AdaptSegNet簡介 - Learning to Adapt Structured Output Space for Semantic Segmentation, CVPR 2018 (spotlight)
Yi-Hsuan Tsai, Wei-Chih Hung, Samuel Schulter, Kihyuk Sohn, Ming-Hsuan Yang, Manmohan Chandraker, “Learning to Adapt Structured Output Space for Semantic Segmentation”arXiv:1802.10349
這篇是CVPR 2018的spotlight
作者有將程式碼釋出 Github
CVPR 18還有一篇也是在做domain adaptation的
Fully Convolutional Adaptation Networks for Semantic Segmentation
資料集都一樣,我有介紹過FCAN簡介有興趣的可以去看看。
那篇準確度更高,不過沒code。
簡介
AdaptSegNet主要是透過GTA5這款遊戲所獲得的dataset做訓練,
目標是在Real world的場景中也希望有很高的準確度。
做的事情就是domain adaptation,
想法也挺簡單的,就是透過一個discriminator,
最終目標是讓discriminator分辨不出來,
這樣就達成了domain adaptation的任務了。
問題介紹
對於semantic segmentation的任務需要基於pixel level 的資料,
但是如果要用人工標籤這些資料是相當耗時的,
因此希望可以透過遊戲中的場景的影像資料套用到實際場景。
但這件事情為什麼難呢?
你可以想像如果我們把澳洲的道路影像套用到台北來的話,
可想而知的是準確度會下降,很直覺的想法就是台北一直下雨,
整個影像看起來的樣子就是不太一樣。
但是經由上面的講法,我們不太可能為了每個城市都去搜集一份dataset,
所以整個任務的目標就是適應場景(domain adaptation)的問題。
Model介紹(簡單重製版,非原本的)
下面這張是我做的,先用簡單的架構作介紹,之後再看原本論文的。
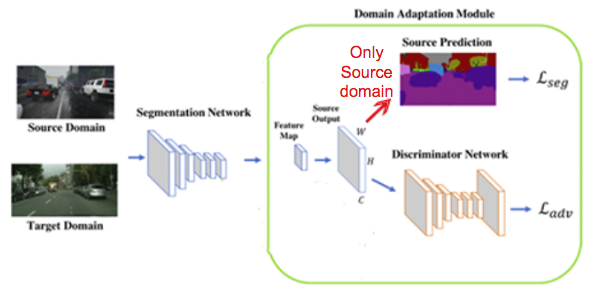
Segmentation Network
我們會將Source Domain(GTA5) 以及 Target Domain(Real world)的影像都丟進Segmentation Network,
Segmentation Network是基於Deeplab v2的架構,
model pretrained on ImageNet省去一些時間。
採用了Atrous Spatial Pyramid Pooling(ASPP)作為輸出,
這部分有興趣的可以去看deeplab v1~v3論文。
Domain Adaptation Module
- Lseg
如果我們輸入的影像是從Source domain的話,
我們Seg Network所輸出之影像,會與Ground truth做binary cross entropy的loss。
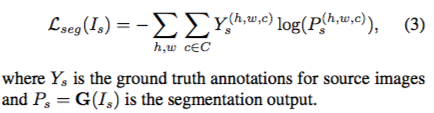
如果你說你要把這個架構應用到實際的場景,但是自己的場景也不能做得差啊,不然怎麼說服別人。
- Ladv
希望Seg Network所產生出來的影像可以讓discriminator分不出來,
透過這個loss讓SegNetwork可以將target domain所生成的影像也能夠盡量的相似source domain所生成的影像,
最終期望透過adversarial來達到domain adaptation的成果。
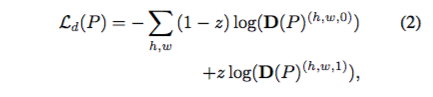
如果是target domian的image z = 0
如果是source domian的image z = 1
這部分屬於GAN的基本想法,我就不多說了。
Model架構
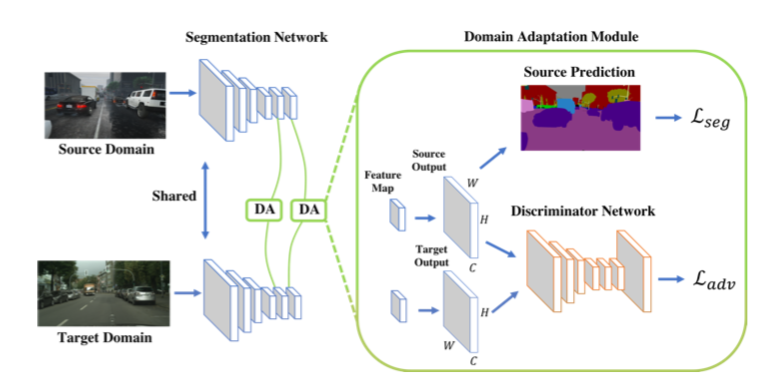
實際上model所用的是2層DA,
作法就跟上面介紹的單層差不多,
想法就是再倒數第二層也接上一個DA,
讓倒數第二層就能夠有一點點像,
那這樣我們的最後一層就能學到更像,又或著是說因為前一層已經有一點像了,所以我們最後一層可以學的比較輕鬆。
總之最後的結果是2個DA的mIOU高出一個DA的mIOU 1%左右。
因此出來的loss function如下
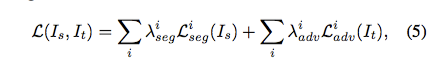
i <= 是第幾層(1…2)
這邊lambda基本上是倒數第二層的權重為0.1
最後一層的權重為1
成果
下圖的feature方式是指單純的feature maps輸出,
single / mulit level的輸出並不單單是feature map,
而是採用了Atrous Spatial Pyramid Pooling(ASPP)作為輸出。
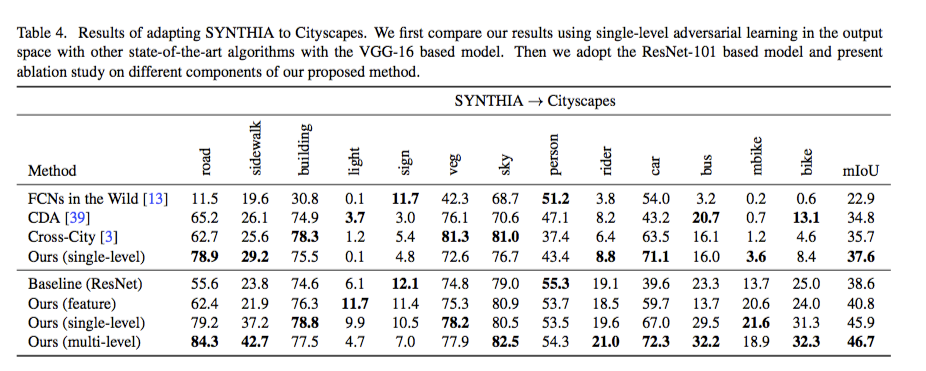
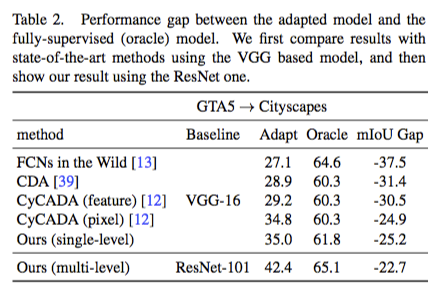
參考資料:
Learning to Adapt Structured Output Space for Semantic Segmentation