Transferring GANs簡介 - Transferring GANs generating images from limited data
Yaxing Wang, Chenshen Wu, Luis Herranz, Joost van de Weijer, Abel Gonzalez-Garcia, Bogdan Raducanu, “Transferring GANs: generating images from limited data”arXiv:1805.01677
ECCV 2018 paper
這篇是在探討Transferring與pretrained model間的關係,以及搭配conditional GANs的結果探討。
程式碼:https://github.com/yaxingwang/Transferring-GANs
摘要
此篇論文主要是在探討遷移學習(Transferring),得出下方結論。
只要使用事先訓練好的模型(pretrained)能夠有效的縮短訓練時間(收斂)。
對於圖像產生(generating images)的任務,生成圖像之品質有改進。
對於conditional GANs(cGANs)的模型也可以透過pretrained model去做改進。
使用分類數(classes number)較少的模型當作事先訓練好的模型(pretrained)看來是較好的選擇。
簡單介紹基本的名詞
遷移學習(Transferring)
對於不同的應用做微調(finetuning),
舉例來說:我們當初可能是要分辨貓和狗,但是有一天我們要改為分辨貓和猴子,
這時候我們使用遷移學習就能夠快速的得到一個準確度不差的模型。
而近期如果要用遷移學習,會搭配GAN的Discriminative model對原有的模型做微調,
因此這篇論文是對遷移學習(Transferring)、事先訓練好的模型(pretrained)及GAN做探討,
生成對抗網路(Generative Adversarial Networks) - GAN
通常是由1個genertator(生成器)以及1個discriminator(辨別器)組成。
多半是隨機生成(scratch = random initialize)的權重進行訓練,
尤其在discriminator中使用隨機生成(scratch)的權重更是常態。
條件式生成對抗網路(Conditional Generative Adversarial Networks) - cGAN
通常是在Generator以及discriminator中加入目前需要生成的y(類別/文字/圖片)當作參數,
因為多了個參數(condition),讓整個model多了個限制,就能讓整個model被訓練得更好。
評估圖像生成結果(Evaluation Metrics)
評估GAN是一件相當難的事情,有興趣的可以看[1]這篇論文,
對於圖片生成的任務來說,其實直接生成圖片來看也是個方法,
這是這樣子太過主觀了而且不容易評估生成的多樣性(diversity)。
圖片生成通常在意的是
- 圖片品質
- 生成圖片的多樣性
- 人眼是否能夠覺得這是張好的圖片
總之能因為[4], [5]兩篇論文所說,
因此下方使用兩個方法做評估。
- Fréchet Inception Distance [2] - FID
採用Fréchet distance (also known as Wasserstein-2 distance)
用於檢測生成之圖片品質以及多樣性,
此分數越低越好。
- Independent Wasserstein (IW) critic [3] - IW
使用一個Discriminator來做評估,而這個D主要是用來計算 Wasserstein distance。
計算生成出來圖片與validation set和的差異
此分數越高越好。
遷移學習至GAN(Transferring GAN representations)
主要是使用WGAN-GP架構[6],在G和D都使用ResNets。
在WGAN-GP中有探討到,這model其實”不會”有訓練不穩定及mode collapse(生成的多樣性不夠)的問題。
探討Generator/discriminator 與 pretrained model的影響
FID分數越低越好
IW分數越高越好
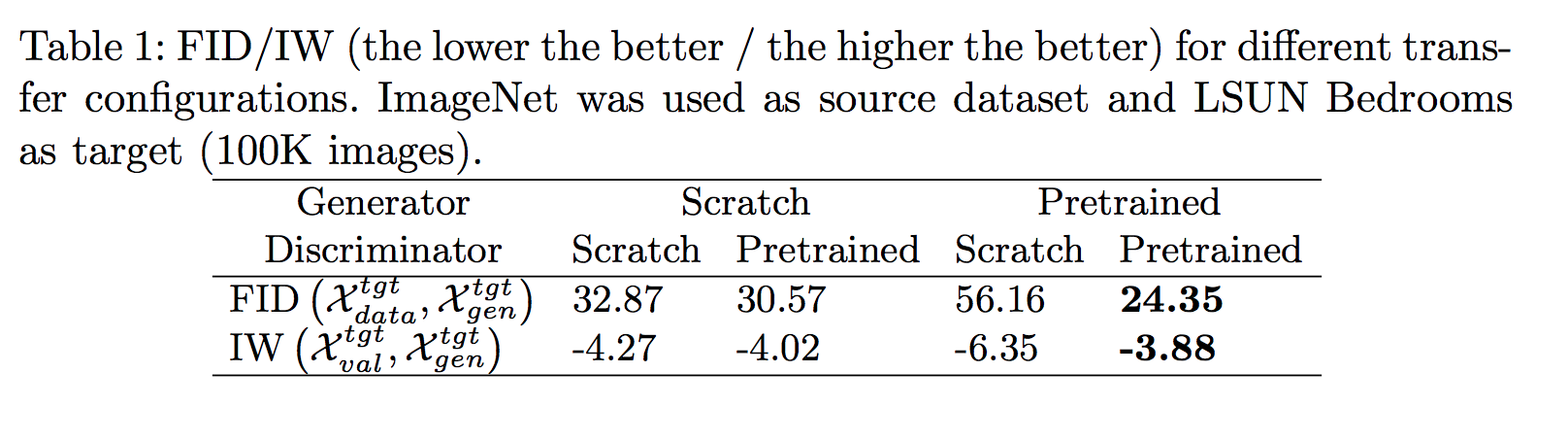
從上圖我們觀察到一個很有趣的現象,
比起在Generator做pretrained,
還不如在Discriminator做Pretrained。
這邊的想法是這樣的,如果discriminator沒有被pretrained的話,
其實一開始discriminator做訓練的時候,
也是會把generator所pretrained的權重給用壞,
因此單純在generator中做pretrained的功用其實不大,
尤其在IW的分數可以看出G - Scratch D - Scratch 反而比 G - Pretrained D - Pretrained更好。
探討 GAN 以及 cGAN與 pretrained model 的影響
左圖分為兩個部分
- IW - 黑線 越高越好
- FID - 紅線 越低越好
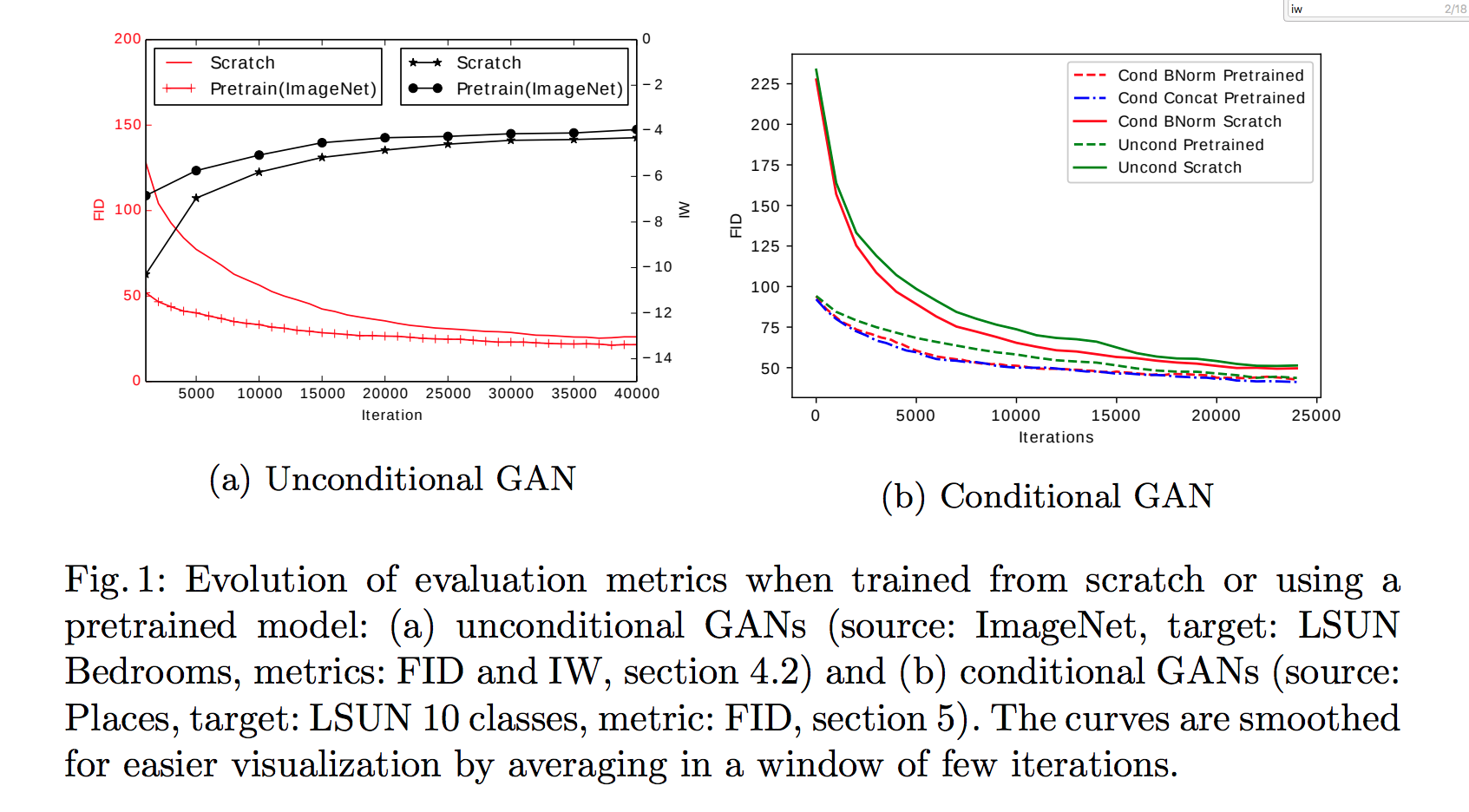
上圖我們可以看出,在訓練次數(iterations)少的時候,
可以明顯的發現不管是一般的GAN或是cGAN來說,
pretrained真的有用,即使是到後面也是比沒有pretrained的model好一點點。
探討目標的dataset的大小

可以看出如果目標的dataset的樣本數很少時,
使用pretrained model是非常有用的。
探討每個dataset的相關性
評估使用不同source domains的dataset與不同source domains的dataset的相關性,
看看要挑選哪個dataset做pretrained是最好的。
簡單介紹幾個可能有人不知道的dataset
- CelebA - Large-scale CelebFaces 人臉資料庫
- LFW - Labeled Faces in the Wild 人臉資料庫
- Cityscape 城市路況
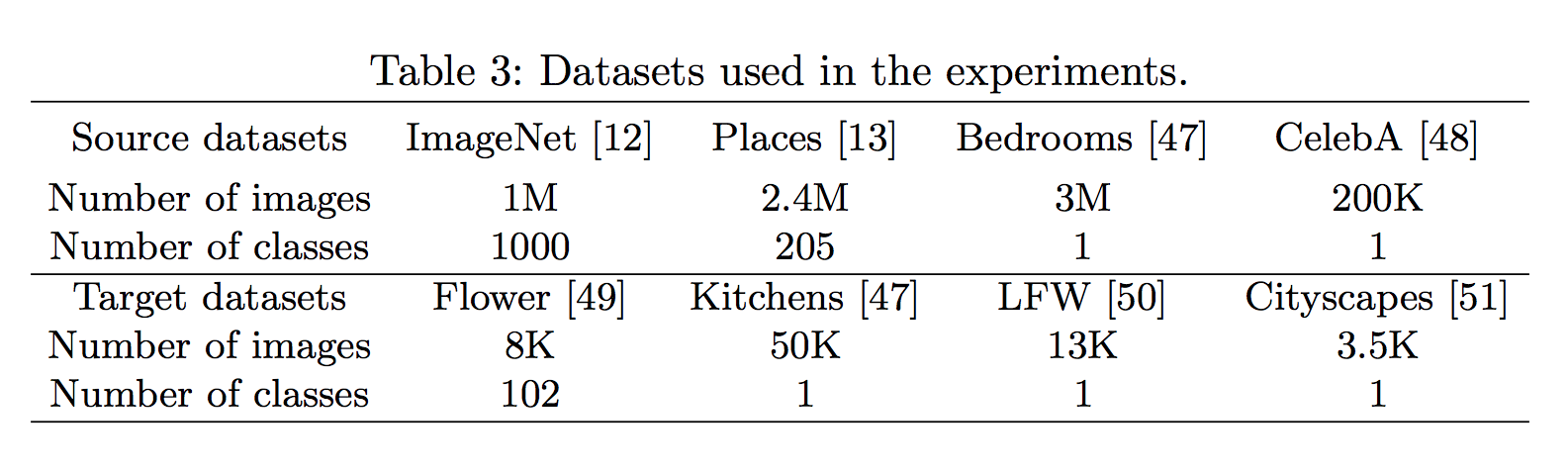
這邊要注意的是 ImageNet 和 Places 都有著超過200個不同的classes。
而另外兩個 LSUN Bedrooms 與 CelebA 的classes數量較少,因此學到的特徵較為集中。
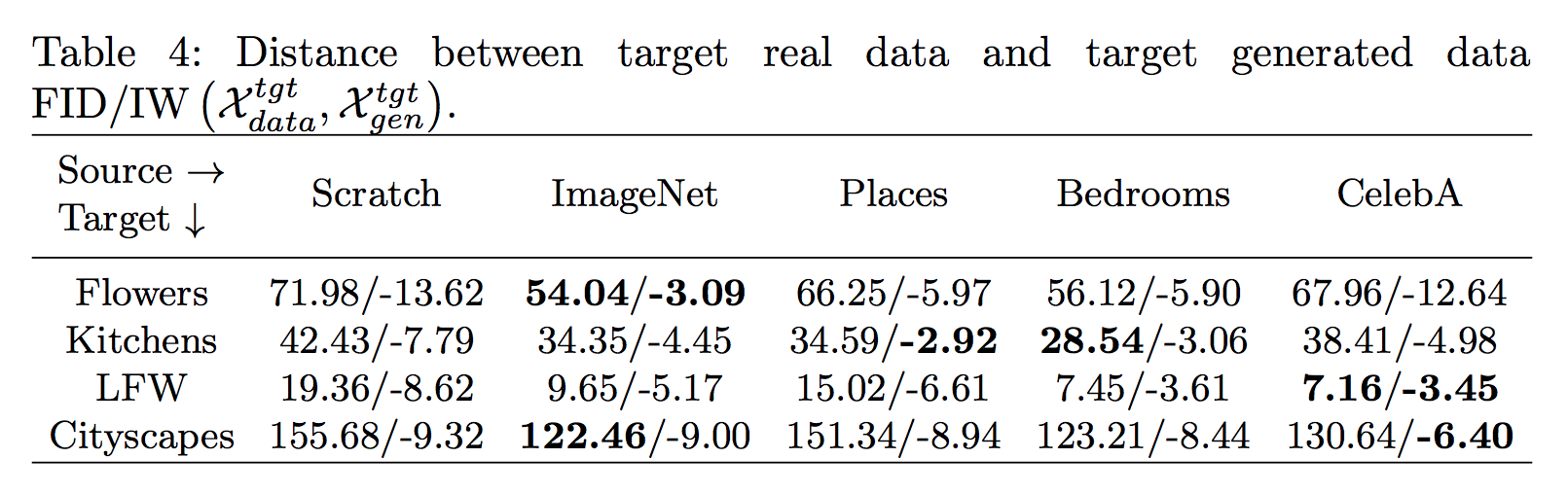
我們可以看出,不管在哪個dataset,比起從頭訓練(scratch)不如採用pretrained model的訓練較好。
Flowers
對於Flowers的dataset來說,ImageNet的FID/IW的分數最好,因為ImageNet中包含了花朵的classes。
Kitchen
對於Kitchen的dataset來說,
Places的IW分數高,
可能是因為Places的dataset中其實有幾千張Kitchen的圖片,
但反過來說其實有幾百萬張是與kitchen不相干的。
令人意外的是,如果採用Bedrooms當source他的FID分數是最高的,
這邊認為是因為臥室和廚房其實結構相似以及視覺上來說也相似,
雖然是不同的類別但是遷移學習的結果很好。
LFW 人臉資料庫
這邊不意外是CelebA的結果最好,因為CelebA就是人臉資料庫。
但是Bedroom的結果也出乎意外的好。
Cityscape 城市路況
這邊其實每個都差的有點多,
或許是因為這個dataset和source dataset都差太多了。
如何挑選pretrained model
看完上面的結果大家一定覺得怎麼沒有一個是最通用的,
這樣就不知道要從挑選哪個當作source domain做pretrained的動作。
其實對於discriminator來說,
如果是目標是物體為中心的話可以選擇ImageNet,
如果是場景為中心的話那就是 Places。
但是以generator的model來說,就沒這麼簡單了,
因為通常generator所做的事情比較複雜,
沒辦法用這麼簡單的結論去概括。
但從上面那張表格發現,
如果原本的dataset與目前的dataset並沒有太多的相關性的話,
指的是dataset的主題不同,source的測資沒有與target的測資相似。
這時候其實採用classes數小的(如bedroom),
往往能獲得不錯的成績。
這也衍生出一個問題,
其實目前還沒有找到適合model的演算法,
因此只能夠先推薦使用since narrow yet domain(狹窄且密集)的dataset是較好的。
如果我們用FID來測量目前model與target model的FID距離的話,
我們會發現普遍來說Places的數值是相對穩定的,
但是會發現實際上套用過去的時候,反而是Bedrooms的dataset當作source來說的話,才是相對穩定的。
因此FID或許不適合當作量測的方式,或許還需要考慮其他因素。
透過圖像生成來驗證transferring的好處
其實這想法也很簡單就是因為方便視覺化,
因此秀出一些結果。

遷移學習至cGANs(Transferring to conditional GANs)
這邊是要呈現如何將一般的GAN所學會的pretrained model遷移至cGANs(conditional GAN),
GAN 適應至 cGAN
這邊會採用Conditional Image Synthesis With Auxiliary Classifier GANs - AC-GAN 的架構作延伸,
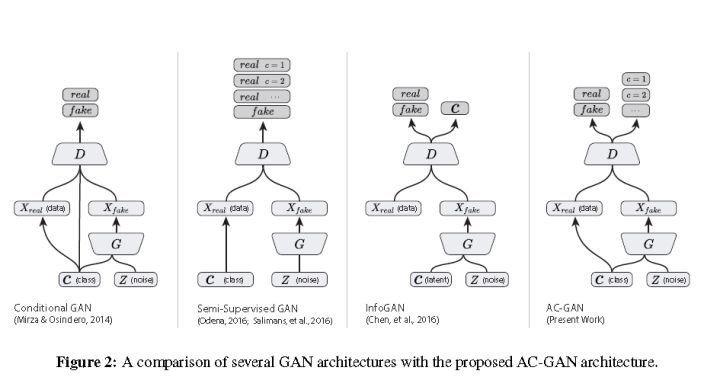
圖片轉載自github : buriburisuri/ac-gan
AC-GAN 是將condition條件(label/text/image)只添加在Generator,
我們將AC-GAN的condition 稱作 Cond Concat,
那要如何將一般的 GAN 轉換至 AC-GAN(Cond Concat)呢?
原文如下:We randomly initialize the weights which are connected to the conditioning prior.
我的理解就是在連接Cond Concat的那一層(第一層fc),weight隨機給就好了,
其他層就直接複製過去。
也有另一種變形叫Cond BNorm[7],簡單來說是在batch normalization中將condition透過embedded的方式加進去,
有興趣的自己去看論文[7]。
那如何從一般的GAN轉換至AC-GAN(Cond BN)呢?
在這情況下,每一個class都會對應到不同的batch normalization參數,
原文如下:there are different batch normalization parameters for each class. We initialize these parameters by copying the values from the unconditional GAN to all classes.
所以這邊其實就是將原本的GAN那一組BN,複製到每一個class當作Cond BN,
讓他們之後再自己去學習。
結果探討
在訓練mode的前幾個iterations,
如果有使用pretrained model的話,
準確度會顯著的提升。
那我們再看下面這張之前看過的圖
從這張圖我們發現3件事(這些都作者說的喔,雖然我第三點看不太出來。
- AC-GAN的兩個變形 Cond Concat vs. Cond BNorm其實差不多。(所以之後的 AC-GAN 都採用 Cond BNorm
- 有使用pretriained model的結果不管是在前幾個iterations 甚至到最後的結果都比scratch的好。
- AC-GAN比unconditional GAN的結果好一點點。
下面這張圖可以看到每個class對於有沒有使用pretrained model的成績
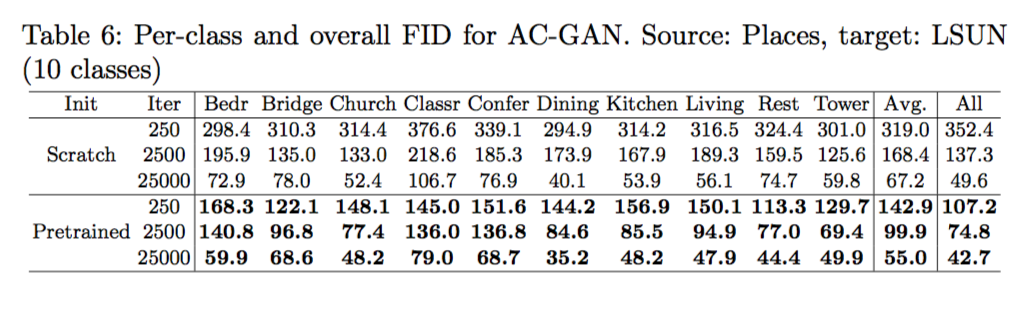
分析target dataset的樣本數量影響,
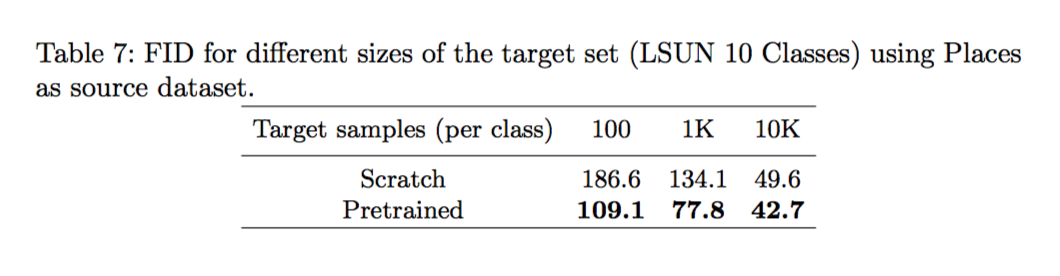
可以知道在樣本數少的時候pretrained的重要性也很明顯。
結論
在這篇paper展示了遷移學習(transfer learning)以及適應不同領域(domain adpatation),
可以在圖像生成(image generation)的任務中被採用。
藉由使用pretrained model可以在短時間(shorter time / iterations)或是dataset樣本數少時,發揮很好的效果。
更重要的是在GAN中,pretrained model套用至generator 以及 discriminator時,能獲得最好的成果,
有點不直覺的想法是如果我們單單在generator中套用pretrained的話,結果其實和scratch差不多,
反之在discriminator中套用pretrained model時卻能得到好的結果。
此外在這篇論文中展示了如何將unconditional GANs 的 pretrained model 轉換至 conditional GANs。
最終提出了我們其實是需要一個評斷目前的任務需要採用哪個pretrained model的機制。
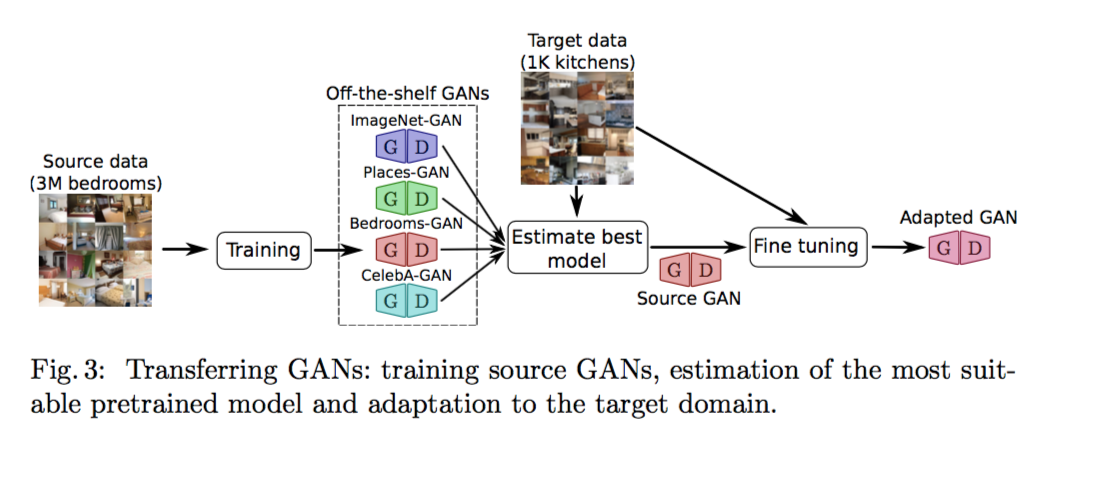
作者展示了他的想法, 我們有幾個已經訓練過的model(pretrained model),
我們需要有一個Estimate best model的功能,
來評估哪個pretrained model套用至我們目前的target model成效會最好。
參考資料:
[1] Theis, L., Oord, A.v.d., Bethge, M.: A note on the evaluation of generative models. arXiv preprint arXiv:1511.01844 (2015)
[2] Heusel, M., Ramsauer, H., Unterthiner, T., Nessler, B., Klambauer, G., Hochreiter, S.: Gans trained by a two time-scale update rule converge to a nash equilibrium. arXiv preprint arXiv:1706.08500 (2017)
[3] Danihelka, I., Lakshminarayanan, B., Uria, B., Wierstra, D., Dayan, P.: Comparison of maximum likelihood and gan-based training of real nvps. arXiv preprint arXiv:1705.05263 (2017)
[4] Im, D.J., Ma, A.H., Taylor, G.W., Branson, K.: Quantitatively evaluating gans with divergences proposed for training. (2018)
[5] Borji, A.: Pros and cons of gan evaluation measures. arXiv preprint arXiv:1802.03446 (2018)
[6] Gulrajani, I., Ahmed, F., Arjovsky, M., Dumoulin, V., Courville, A.C.: Improved training of wasserstein gans. In: Advances in Neural Information Processing Systems. (2017) 5769–5779
[7] Dumoulin, V., Shlens, J., Kudlur, M.: A learned representation for artistic style. In: Proc. of ICLR2017. (2017)