AC-GAN簡介 - Conditional Image Synthesis With Auxiliary Classifier GANs
Augustus Odena, Christopher Olah, Jonathon Shlens, “Conditional Image Synthesis With Auxiliary Classifier GANs”arXiv:1610.09585
ICML 2017 paper
我這篇文章是看20 Jul 2017 (v4)版本
後續有cgans with projection(ICLR 2018)也是在做相同的任務,
有興趣的可以看這篇我寫的cGANs with projection簡介
摘要
此篇論文提出一個新的圖像合成(image synthesis)方法,
它可以產生 128 X 128 解析度的圖片,
並且這個方法會學會一些特徵,
可以保留這些特徵轉換到其他的類別。
舉例來說要生成一個笑臉,
可以保持著笑臉的屬性,
然後產生不同人在笑。
除了提出圖像合成的方法外,
還提出如何基於每個物種(class)來測量圖片的辨識率(discriminability)以及判別生成的圖像是否擁有多樣性(diversity)。
最終在ImageNet - 1000 classes的dataset上展示此方法生成的 128 X 128之圖片,
辨別率:生成的128 X 128之圖片,為32 X 32辨識率的2倍, 從此可知並非單純的放大,
多樣性:用他的評測多樣性的方法,用此方法生成的圖片有84.7%的物種(class)比ImageNet中的物種(class)圖片更具多樣性。

簡介
以往的cgan都會將c(class label)輸入至Discriminator,
而AC-GAN不這樣做,
他做的事情反而是讓Discriminator有一個分類器當作輔助,
這就是為什麼就做AC-GAN(Auxiliary Classifier)
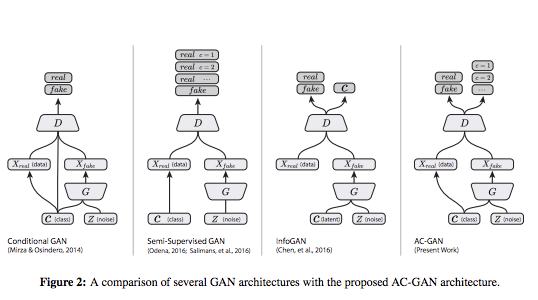
在這篇paper中會依序介紹下方的概念。
- 對ImageNet - 1000的dataset做訓練,可產生128 X 128的圖像
- 測量高解析度的圖像是否有實際的效果又或是單純從32X32進行bilinar放大而來
- 測量圖片是否具有多樣性,或是只會用幾張圖片(mode collapse)騙過辨別器
- 顯示AC-GAN的圖片合成方法並非只透過記憶幾張圖片
架構
先看架構,會有比較好的理解,
概念
- latent variables z
z有100個,可以理解成每個z都是不同的特徵,
如眼睛、鼻子等等的,
希望model可以讓這些z學到不同的特徵,
- classes variable
在AC-GAN的Generator model都只訓練10個classes,
將10個class轉成one hot encoding當作輸出。
Generator
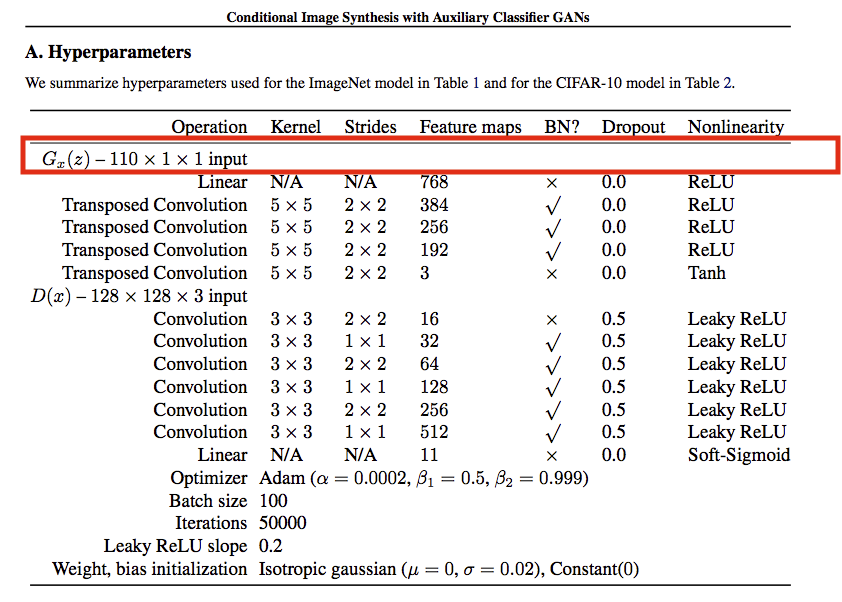
G input = z(100) + c(10) = 110
因此可以看到下圖, 輸入的維度為110。
之後再透過FC layer輸出至784維(28X28),
再進入一連串的Deconv來轉成高解析度的圖片。
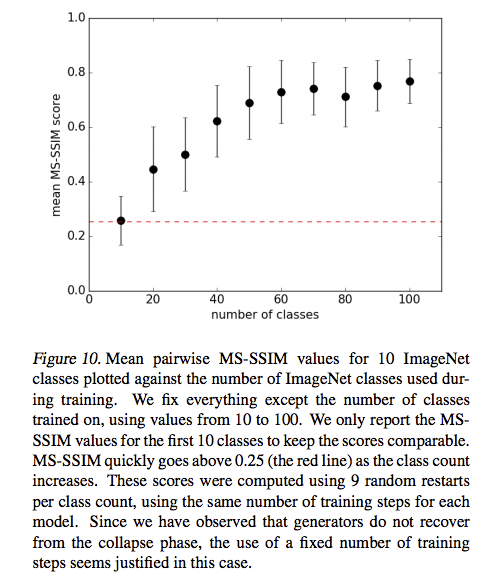
如何生成ImageNet的1000個classes
每個AC-GAN訓練10個classes(物種),
透過訓練100個AC-GAN來拼湊出ImageNet的1000個物種,
那為什麼要這樣做呢?
可以先看下面這張圖,總之y軸的MS-SSIM(等等會解釋)在這邊越低越好,
所以可以看到在classes數=10的時候,
分數最好。
測量高解析度的圖像是否有實際的效果
要將一張低解析度的圖片轉成高解析度的圖片,
最簡單的方式是透過bilinear放大,
但其實這會造成邊緣的模糊,
綜觀來說其實資訊量也沒有變多,
因此我們要做的事情是要確認說我們生成之 128X128 圖片,
是比32X32的圖片經由bilinear放大後有著更多的資訊量,
讓我們更能夠準確的辨認圖片。
因此這邊所採用的方式是 pre-trained Inception network (Szegedy et al., 2015)
給定一張圖片,它會對基於輸入的class(物種)給定一個分數,分數越高越好。
下方這張圖做的事也挺有趣的,
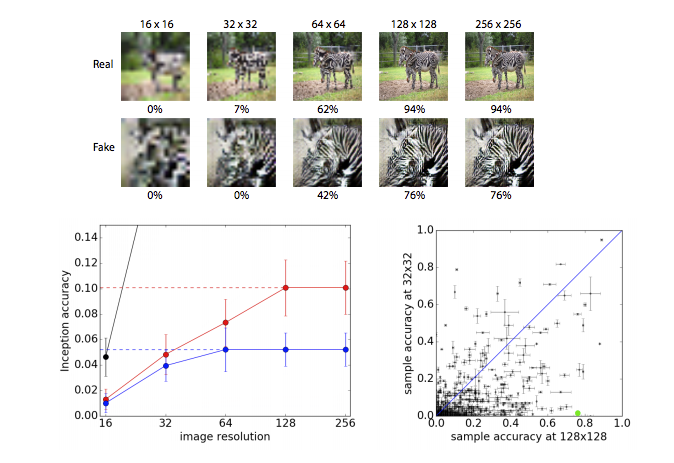
上方的圖
給定不同解析度的斑馬,算Inception的分數,
128 X 128的解析度是原本的大小,
我們將128X128透過bilinear放大至256X256會發現分數沒有上升,
但是將128X128縮小成64X64會發現準確度降低了,
因為有些資訊被丟掉了,因此分數降低很合理,
透過這種方式我們可以知道如果單純放大分數不會上升,
透過這種方式我們可以用來量測我們所生成的128X128的影像,是否真的擁有更多的資訊。
下方的圖
左下為給定 128X128(紅線) / 64X64(藍線) 的圖片將他透過bilinear放大縮小
看得出來剛剛在上方所講述的論點。
右下在說明ImageNet 1000有有84.4%的class使用128X128的解析度得出來的準確度會比32X32的準確度高。
測量圖片是否具有多樣性
GAN有個著名的問題是Mode collapse,
簡單來說就是Generator知道生成某一張圖片就能夠騙過Discriminator,
所以每次就是生成那一張,
那你看loss function就會覺得很棒,
等到實際上使用才會發現,怎麼都是同一張。
那因為我們的任務是圖像生成,
我們總不能每次都生成同一張,
因此要有一個判斷基準。
這邊所提出的想法是MS-SSIM(Multi-Scale-Structural Similarity Index):多層級結構相似性
MS-SSIM原本是用來評測圖像品質的,
這邊卻用來檢測Mode collapse的問題,
MS-SSIM大致的思維是給定2張圖,評斷兩張的像不像,如果感覺差不多分數就高。
用這種想法來檢測((論文提到好幾個點,這邊不贅述。
因為我們是基於class的label做生成,
因此圖片已經被限縮成某個範圍(class)了,
那如果同一個class的兩張圖片經由MS-SSIM評定的分數很低的話,
這樣就是說不像,那如果整個class的平均(隨機抽樣100組, 每組2張圖片)MS-SSIM分數低的話,
代表整個class沒有mode collapse的問題。

從上面這張圖能看到,右上角的artichoke(中譯:朝鮮薊)因為長得都很像所以平均的MS-SSIM分數很高,
ImageNet的1000個class,MS-SSIM分數最高class數值為0.25(不算像)。
顯示AC-GAN的圖片合成方法具有多樣性以及辨別性
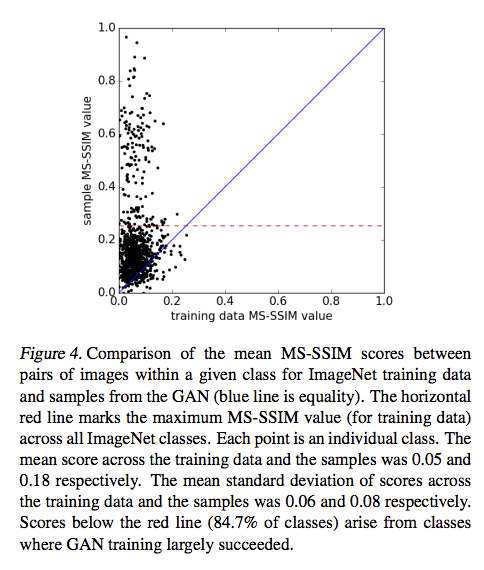
下圖為MS-SSIM分數的圖表,越低越好。
- x軸dataset
- y軸AC-GAN生成圖片
有84.7%的生成圖片低於0.25的分數。
training data的平均MS-SSIM分數為0.05,
AC-GAN所產生的圖片平均MS-SSIM分數為0.18並不算太差。
至於辨別性則透過Inception-v3的分數做評斷,
AC-GAN所生成的1000個classes之圖片平均分數達到了78.8%挺高的。
我的結論
這篇paper我覺得最大的問題是,
每個AC-GAN竟然只能產生10個類別,
需要透過訓練100個AC-GAN才能夠生成ImageNet的1000個物種。
可能是因為我先看ICLR 2018的cGANs with projection discriminator才回來看這篇,
難免會覺得弱弱的吧!?
有興趣的可以看這篇我寫的cGANs with projection簡介