Attentive-GAN簡介 - Attentive Generative Adversarial Network for Raindrop Removal from A Single Image
Rui Qian, Robby T. Tan, Wenhan Yang, Jiajun Su, Jiaying Liu, “Attentive Generative Adversarial Network for Raindrop Removal from a Single Image”arXiv:1711.10098
CVPR 2018 Spotlight
這篇文章是看6 May 2017 (v4)版本
作者有將程式碼釋出 Github
這篇文章主要是在做將車窗上的水滴清除,
我們直接看圖片就能夠理解了。

簡介
如果開車的時候車窗上有雨滴,
其實是會阻礙視線而且水滴中的景象會變形。
此篇Paper就是為了解決這個問題,
主要是使用GAN搭配Attention的方式解決。
如果不太清楚Attention的概念,
可以看一下我之前寫的Grad-Cam簡介
那為什麼要使用Attention呢?
因為水滴不只影響水滴的部分,
連水滴周圍會也有一點影響。
因此需要Attention這種能表達介於0~1之間能量強度的方式。
而這篇論文主要的貢獻是將Attnetion使用在Generator和Discriminator中。
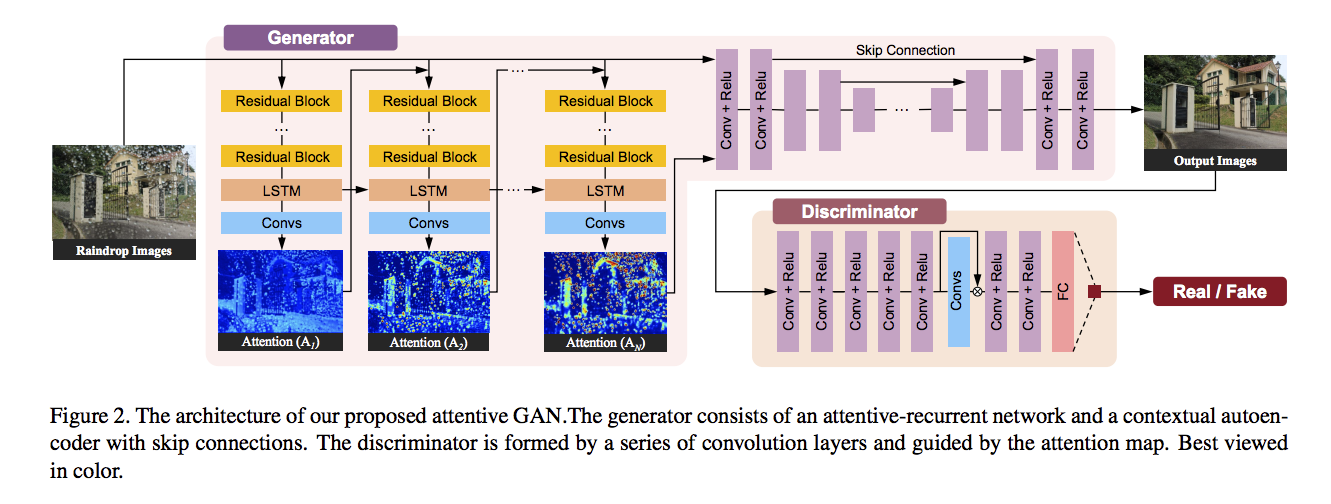
架構
先看架構,會有比較好的理解。
概念
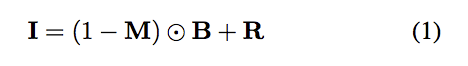
- I : 輸入影像
- M : 水滴的能量強度
- B : 沒有水滴的圖片(最終我們希望獲得的)
- R : 水滴帶來的效果(模糊,放大等等)
我們可以將一張圖片(I)看為沒有水滴的部分以及有水滴的部分。
有水滴的部分,透過Attention獲得能量強度(M),判斷是否為水滴。
因此使用(1-M)來看看要拿多少能量的背景圖片,
如果那個Pixel的水滴能量為0,
那麼我們其實可以直接將那個Pixel視為沒有被水滴干擾的影像(B),
如果有被水滴影響(R)的話,
那就要經由我們的Generator去做修正,
最終希望獲得一張乾淨的圖片(B)。
Generator
訓練時給定2張圖片,
- 有水滴的圖片
- 沒有水滴的圖片
備註:兩張圖片是同樣的背景,差不多的各種環境因素。
透過上述的兩張圖片,做簡單的相減,獲得有水滴的mask(M)
Conv LSTM + Attention part
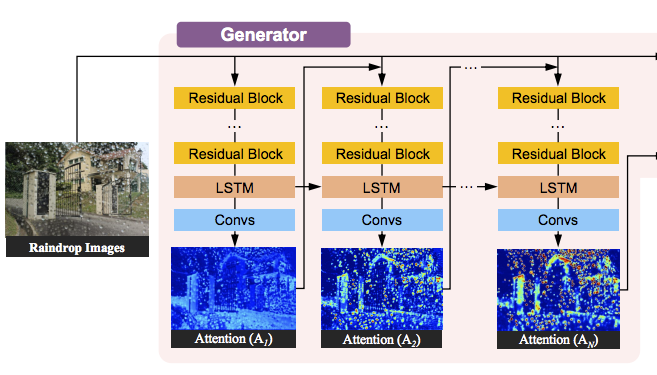
我們先將每層各自看,
每一層的輸入為上一層的Attention + Input Image
備註:Attention第一層沒有的話就設定整張圖都為0.5
前面有用了5個Residual block來將特徵萃取出來,
之後透過convlolutional LSTM[1] 以及一個Convlution layer製作出Attention mask。
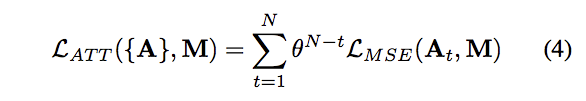
這邊採用的是對每次輸出的Attention都做Mean squared error (MSE)
這邊的設定是N=4, θ=0.8
下圖可看出在越後面的Time step輸出的準確度越高。

2018/07/17 更新
雖然我把ConvLSTM看完了ConvLSTM簡介,但我還是不清楚這邊將attention用concat的方式餵進LSTM的想法是從哪來的。
Contextual Autoencoder
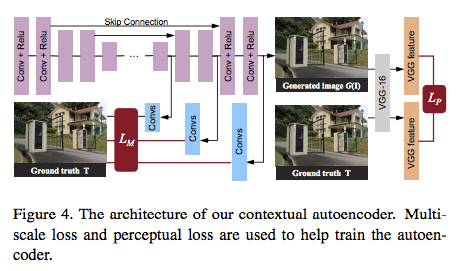
輸入為最後輸出的Attention + Input Image
autoencoder是由16個conv-relu blocks組成,
以及有Skip connections被用來防止會有的模糊(blur)的輸出。
在這邊有兩個loss function
- multi-scale losses
S:Generator產生的Attention
T:Ground Truth
對不同layer的輸出進行MSE loss做調整。
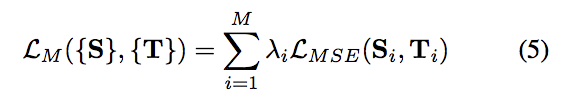
λ 設定為 0.6, 0.8, 1.0.
- perceptual loss
這部分是希望可以透過VGG16來檢測圖片的整體差異
O = G(I)
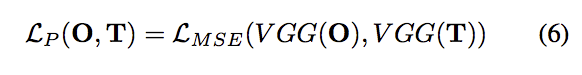
Generator整體的loss如下:
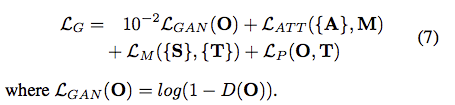
Discriminator
為了要辨認真假,
Discriminator不只是要對於水滴來做偵測,
還要確保整個圖片看起來是正常的,沒有不協調的地方,
因此需要有對local(水滴處)和global(整體)這兩個概念做檢測。
- local
如果我們知道哪邊是假的話,
我們就可以針對某個區域做處理,
但是對於移除水滴的問題來說,
我們並不清楚哪些區域是有水滴的,
因此換個想法,
我們在Discriminator中能夠找到哪邊是水滴就好了。
因此也在這邊採用Attention用於偵測水滴。
值得一提的是雖然LSTM那邊的Convs為淺藍色,
但是他的架構又和Discriminator的淺藍色Convs架構不同,
目前的理解為淺藍色Convs代表Attention,
他會透過loss function讓這個Attentive conv越來越像LSTM的Attentive conv
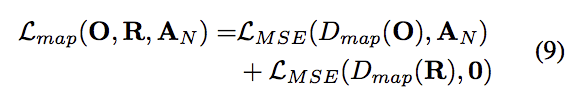
Dmap指的是Discriminator的Attentive conv所產生的2D map
Discriminator整體的loss如下:
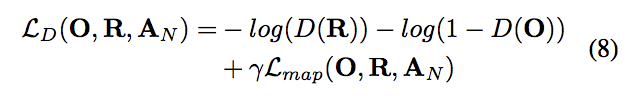
R : 從training data sample出一張Groundtruth的圖片
0 : 指的是這張圖片是乾淨的,map偵測不到有水滴的部分,全填為0。
γ : set to 0.05
Raindrop Dataset
這部分是作者自己搜集的,
搜集了1119 pairs(有水滴和沒水滴)的圖片,
對細節有興趣的自己去看論文。
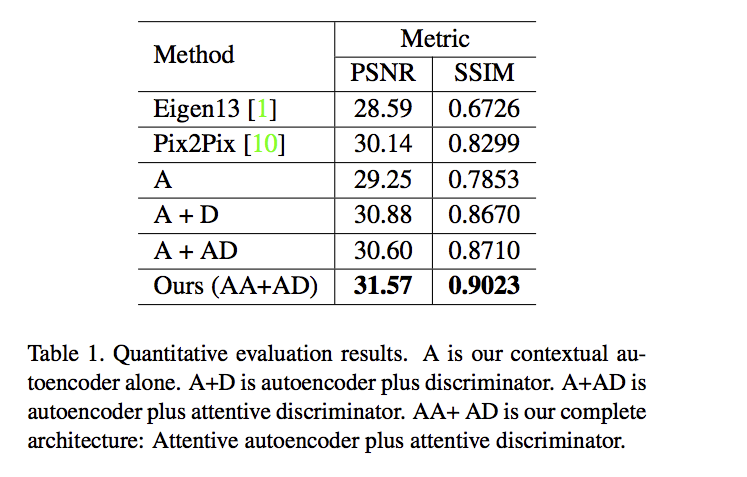
成果比較


參考資料:
[1] S. Xingjian, Z. Chen, H. Wang, D.-Y. Yeung, W.-K. Wong, and W.-c. Woo. Convolutional lstm network: A machine learning approach for precipitation nowcasting. In Advances in neural information processing systems, pages 802–810, 2015. 2
Attentive Generative Adversarial Network for Raindrop Removal from A Single Image