Synthesizing Images of Humans in Unseen Poses簡介
Guha Balakrishnan, Amy Zhao, Adrian V. Dalca, Fredo Durand, John Guttag, “Synthesizing Images of Humans in Unseen Poses”, arXiv:1804.07739
CVPR 2018
Github Code:沒找到,如果有的話歡迎留言,我會再做更新。
因為沒有Code,所以我有說錯的地方請指正。
簡介
本篇論文主要是在展示基於Pose(姿勢)的圖像合成,
主要的想法是透過一張輸入圖片+一張2D的骨架圖片就可以合成出一張圖片。
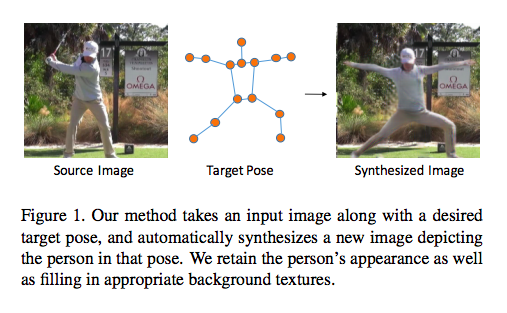
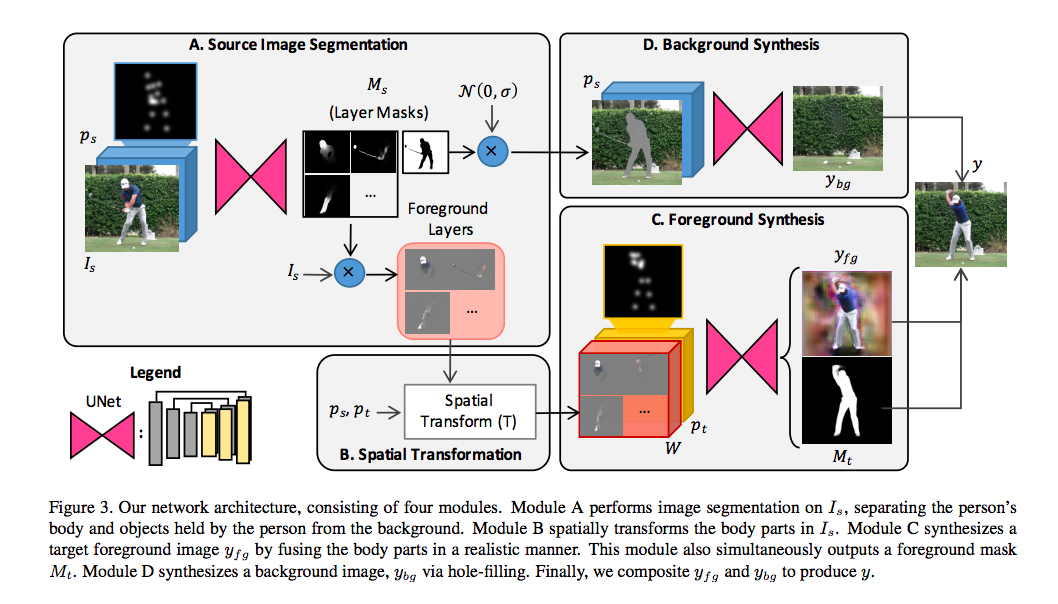
本篇不同以往的是採用了模組化(最下方額外補充)的架構,
以往都是訓練一個非常強大的Model,
而這次是採用多個Model做不同的工作,
最後再結合。
整個任務困難的點是在
- 前景合成:人物合成的細節(邊緣、陰影)。
- 背景修補:因人物動作改變,要如何填補空缺的部分。
訓練是透過Youtube上面的影片,
挑選3個不同的運動當作classes(瑜珈、高爾夫、網球),
而挑選這些動作也是有原因的,
因為這幾項運動的影片的背景不太會變動,
因此可以透過這個特性,學會Pose以及背景修補。
架構
主要是透過U-Net做不同的模組,
如果對U-Net不清楚的可以去看這篇【深度学习论文】:U-Net,
或是搭配程式碼做觀看U-Net Github Pytorch版本。
而這邊採用U-Net的原因是因為每個模組的輸入和輸出的圖像並不會移動,
而U-Net在這類型的圖像合成任務上很成功。
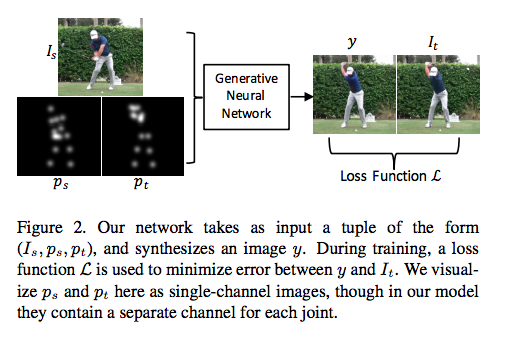
輸入
(example, label) = ((Is, ps, pt), It)
可以理解成用同一個影片,但是不同的圖像(不同的時間點的圖像)做訓練,
s = source - 在影片i秒的frame
t = target - 在影片j秒的frame
整個任務是希望輸入Is這張圖以及Pt的骨架可以生成出一張圖片,
不過這邊是training,所以都要丟進去學習。
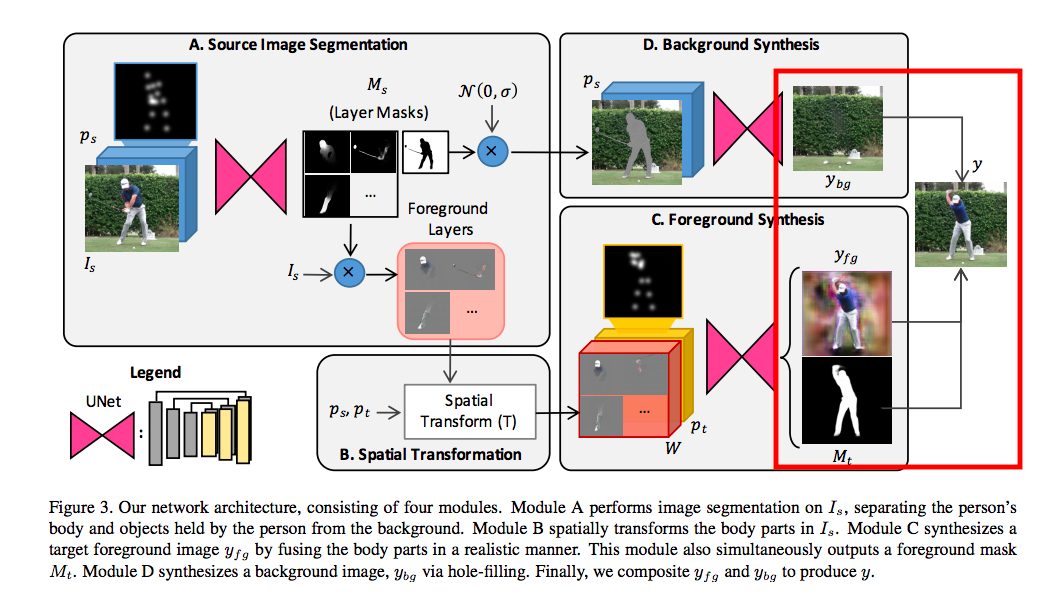
Source Image Segmentation
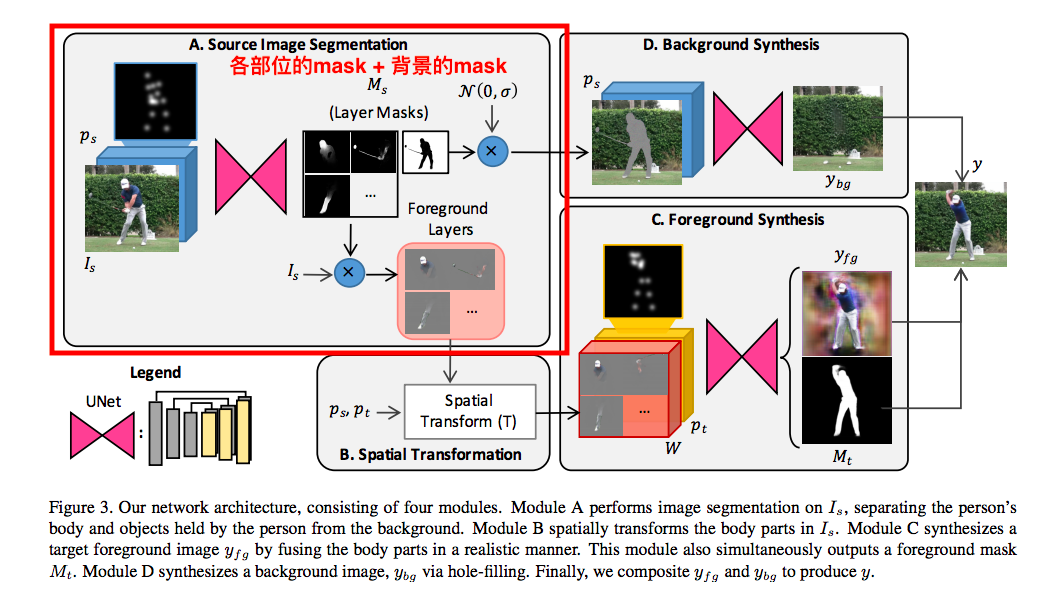
step1.
先將2D的Pose(H X W)拆解成 J 個 2D Pose = (H X W X J)
備註:
J = 14,
joints: 頭, 脖子, 肩膀, 手軸, 手腕, 臀部, 膝蓋 以及腳踝。
step2.
透過2D Pose(Ps - H X W X J) + 2D Image(Is - H X W X 3) 當作輸入,
學會每個Pose是在圖片中的哪個部分,
透過上面的資訊,輸出骨架中的 L 個位置 + 1個(背景)的Mask,輸出為(∆Ms - H X W X (L+1) ),
Mask中白點為我們要的,黑點為我們不要的。
再透過下方公式求得上方圖片的Ms(下方有圖)
最後一個參數不知道怎麼來的,論文中的解釋是residual component,有興趣的去研究研究。
推測是用UNet的特性Crop and Copy才得出這個公式,
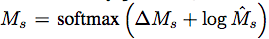
備註:
L = 10
將身體分成L = 10個部位:頭部,上臂,下臂,上腿,下腿和軀幹。 身體部位與關節不同; 前9個部分由2個關節組成,軀幹包含4個關節。
輸出的Mask如下圖:
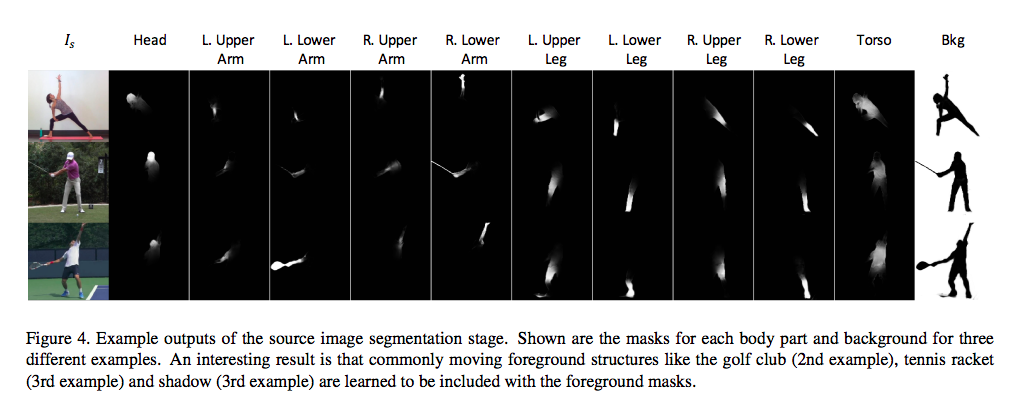
透過這個Mask,對原本的圖片做相乘,
就可以拿取前景的各個部位,得出Foregrounds Layers。
Spatial Transform
![]()
這部分並不是透過U-Net做學習,
而是過簡單的轉換,將上面的每個Layer(L+1)做位移、旋轉、縮放等等。
bilinear interpolation functio放大後,
給出一個基於 Target Pose 轉換後的 Foreground Layer (W),
這邊的 W 還不能直接使用,
因為他是對每個L+1個的身體各部分(Foreground Layers)去做姿勢的轉換,
但我們不知道實際上Is套用Target Pose後,會影響到原始圖片中的哪些pixel。
Foreground Synthesis
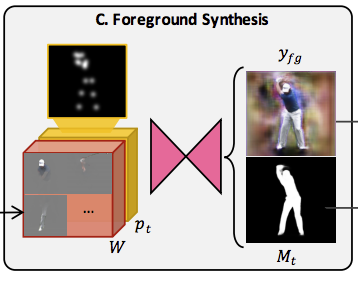
為了解決上面的問題,我們要得出基於Is的target pose合成圖,
做法就是將 W 和 Pt 結合(concatenated)在一起丟入U-Net去做訓練,
這樣看起來是可行的。
這邊輸出的兩個東西 Yfg / Mt 是使用同一個U-Net,
只是在同一個模型中的不同layer做輸出。
Background Synthesis
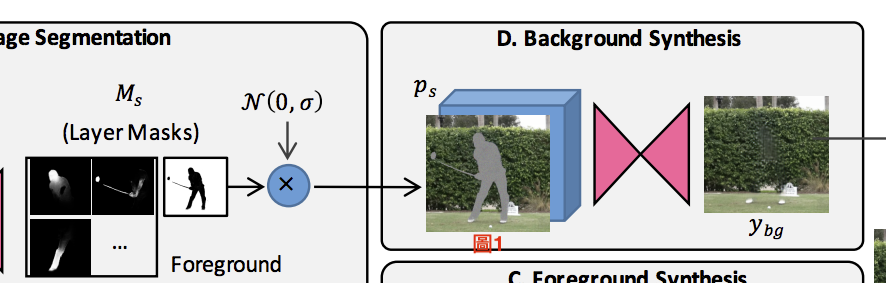
首先將Ms的最後一層背景層拿出來,
之後將背景層填補雜訊再與Is做結合可得出圖1。
透過輸入Ps以及圖1讓UNet學會填補那些位置得出Ybg,
可以看出Ybg其實沒有做得很好,
但是也沒關係,因為之後前景會把我們Ybg自行合成的多數位置都給蓋掉,
所以也不用太講究。
Foreground/Background Compositing
結合的方式也很簡單,透過這三個輸出做結合。
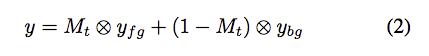
展示一下輸出的結果,
儘管身體依照target pose改變了,
但是整體的感覺還算像,
可惜的是高爾夫球竿和球拍這種細節卻沒學好。

Loss funtion

VGG
指的是VGG19中的前16個layer,
主要想法:當兩張圖片背景相同、人物相同就只有姿勢不同,
那麼兩張圖片透過VGG這個特徵萃取的模型,輸出的值應該也要差不多。
所以採用VGG這個loss function。
GAN
GAN主要是添加Discriminator,
作者的想法是透過Discriminator去做細節的判別,
因此給出了最終的loss function,
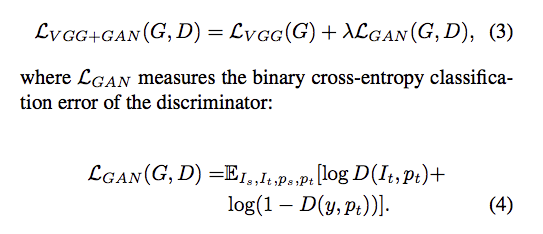
備註:
這邊的 λ 設為 0.1
Discriminator:
這邊paper沒有提到他的架構。
實驗
- 同個類別不同pose
舉例:做瑜珈但是不同動作。
使用VGG+GAN當作loss function其實做得不錯,
在一些細節處都做的比較好 e.g. 服裝、陰影


- 合成影片
透過輸入一連串的pose來合成出一段影片,
影片的背景是基於輸入圖片的背景,
而每個frame會隨著輸入的pose骨架而改變。

- 不同類別不同pose
舉例:瑜珈 to 網球
那為什麼要這樣做呢?為什麼不一起訓練?
因為如果我們每個pose都訓練一個model的話,
他能夠學到那個類別的細節,e.g.高爾夫手套

結論
這篇提出了將pose合成的任務拆解成各個部分,
e.g.前景、背景。
而出來的成果也不錯,
但是還是有改進空間的,
舉例來說像是物品(球拍、高爾夫球竿)常常都沒有出來,
還有人臉也沒有合成的很好((畢竟合成人臉這件事本身就不簡單。
以及2D pose給的資訊畢竟有限,
未來如果有3D的pose應該能訓練得更好。
額外補充-模組化
模組化的設計是參考自VQA(Visual Question Answering)的這塊領域
他在相關研討提到兩篇paper
J. Andreas et al. Learning to compose neural networks for question answering. arXiv preprint arXiv:1601.01705, 2016.
J. Johnson et al. Inferring and executing programs for visual reasoning. arXiv preprint arXiv:1705.03633, 2017.
我之前也看過幾篇VQA的論文
- Tbd-net(CVPR 2018)
- Inferring and executing programs for visual reasoning
- Neural module networks
我認為模組化的概念比較建議閱讀 Neural module networks(與第一篇Learning to compose neural networks for question answering同作者)。
J. Andreas, M. Rohrbach, T. Darrell, and D. Klein. Neural Module Networks. CoRR, abs/1511.02799, 2015.
不過整體其實也沒用到什麼概念拉,
未來如果有再回去研究VQA的話,我再來重看順便補上簡介。
參考資料:
Synthesizing Images of Humans in Unseen Poses
U-Net: Convolutional Networks for Biomedical Image Segmentation