相片風格轉換 - A Closed-form Solution to Photorealistic Image Stylization簡介
Yijun Li, Ming-Yu Liu, Xueting Li, Ming-Hsuan Yang, Jan Kautz, “A Closed-form Solution to Photorealistic Image Stylization”, arXiv:1802.06474
ECCV 2018 - Nvidia團隊提出
本文章介紹v4版本,於26 Jul 2018提交的版本,
看完之後出了v5的版本,於27 Jul 2018提交的版本。。。
Github Code:https://github.com/NVIDIA/FastPhotoStyle
題外話:
之所以看這篇文章是因為看到Nvidia團隊新提出的Paper(發表於24 Jul 2018),
Aysegul Dundar, Ming-Yu Liu, Ting-Chun Wang, John Zedlewski, Jan Kautz,“Domain Stylization: A Strong, Simple Baseline for Synthetic to Real Image Domain Adaptation”, arXiv:1807.09384
未來看完再把簡介的連結補上。
簡介
本篇論文主要是在展示 相片/仿真 的風格轉換(Photorealistic image stylization),
而相片風格轉換和近年來常見的風格轉換(style transfer)相近,
但是相片風格轉換主要的訴求是在保留空間資訊下的風格轉換,
以往的風格轉換為了要有很顯著的轉換效果,所以會讓圖像的空間資訊扭曲/破壞等等等的,
等等看圖片就能明白差別了。
輸入:
- A : 1張風格(style)圖片
- B : 1張內容(content)圖片
輸出:
- C : B仿造A圖片之風格後所產生的圖片
我們的目標是要讓生成的 C 圖片有著 A 圖片的風格,但是又不希望 B 圖片的空間資訊遭到扭曲/破壞。

本篇主要與Luan et al.所提出的方法做比較,
該方法論文連結
Luan, F., Paris, S., Shechtman, E., Bala, K.: Deep photo style transfer. In: CVPR.(2017)
該方法為上圖的(d),
可發現在圖片在某些區塊中當周圍材質類似時,有時候會空間資訊還是會丟失。
架構
主要是兩個步驟
- 風格轉換(Stylization) - F1
將圖像轉換至另一種風格
- 仿真平滑化(Photorealistic Smoothing) - F2
確保生成的圖像保留原本圖片的空間資訊

- Ic:Content Image
- Is:Style Image
- F1:風格轉換(Stylization)
- F2:仿真平滑化(Photorealistic Smoothing)
流程如下: 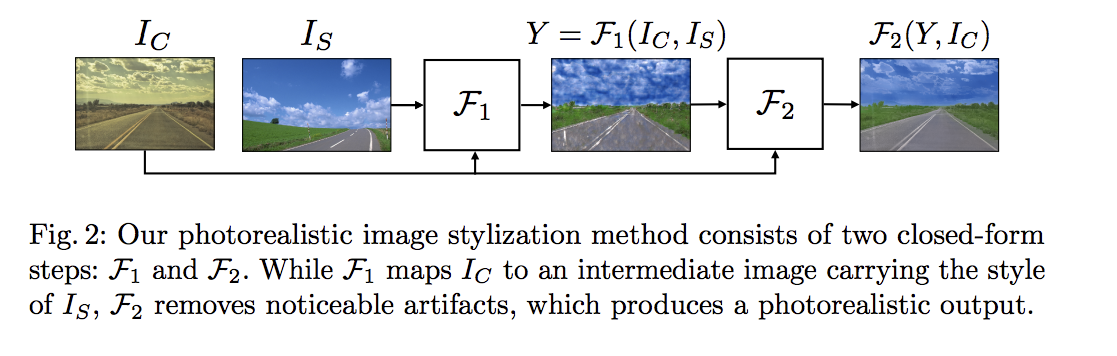
風格轉換(Stylization) - F1
提出 PhotoWCT 的風格轉換方法,而它是基於WCT,因此會從WCT開始介紹。
WCT
此方法的paper如下:
Yijun Li, Chen Fang, Jimei Yang, Zhaowen Wang, Xin Lu, Ming-Hsuan Yang: Universal Style Transfer via Feature Transforms. In: NIPS.(2017)
核心想法:
透過VGG Network萃取出特徵,對特徵做線性轉換(WCT),
找出Encoder(Ic)以及Encoder(Is)的correlation,
而不是透過Network作轉換,這樣可以省去建網路調參數的辛酸之路。
註:
Ic 與 Is 的 VGG Net 相同,並非各自獨立的訓練。
訓練方式:
1.透過VGG的架構做圖像重建的任務。
2.基於已訓練好的VGG Net輸入Ic的圖片,將Encoder的最後一層的輸出提出。
3.基於已訓練好的VGG Net輸入Is的圖片,將Encoder的最後一層的輸出提出。
4.將Ic基於Is的資訊做WCT轉換,稱為A。
5.將A當作Decoder的輸入,Decoder後,會輸出風格轉換後的圖片。
整體流程為下圖(出自Paper:Universal Style Transfer via Feature Transforms. 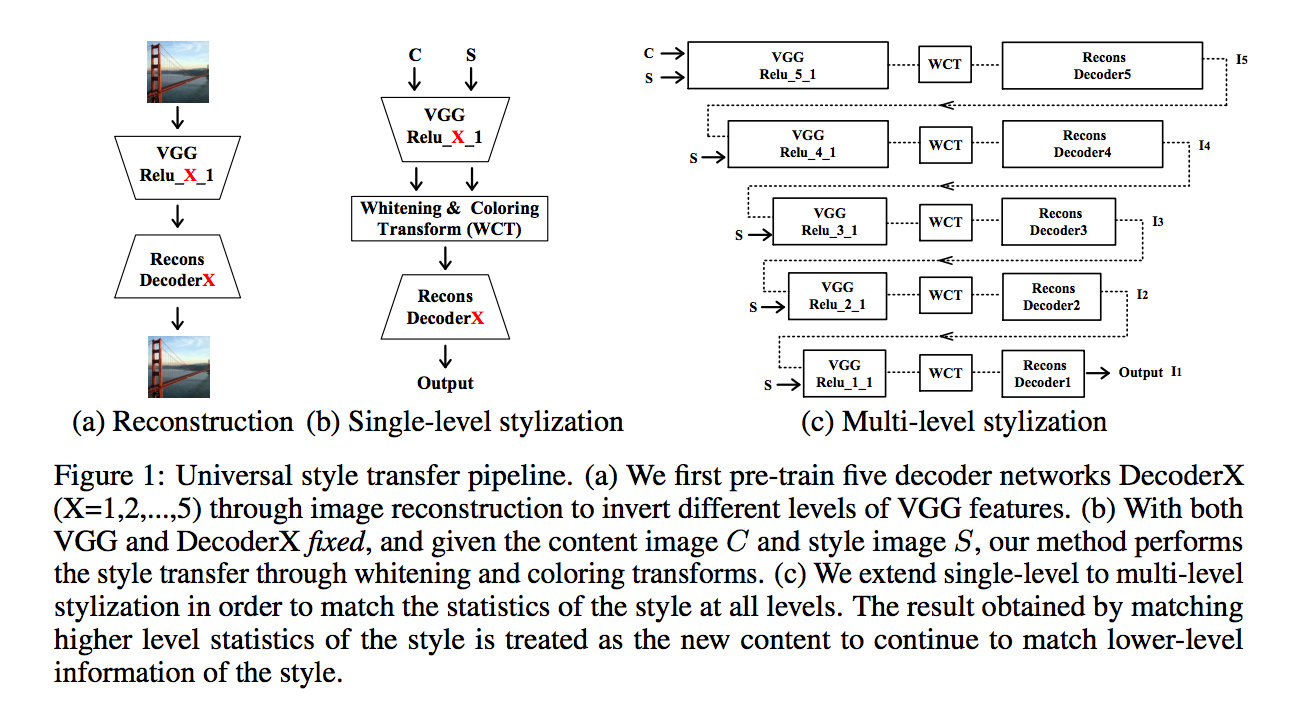
Multi-level stylization
而上圖的右方 Multi-level stylization 也是本篇Paper有使用的trick,
他會對每個layer都做WCT轉換 ((原本只對encoder的最後一層,
而透過這種方式可以獲得更好的風格轉換。
WCT方法細節
有興趣的可以看Paper:Universal Style Transfer via Feature Transforms.
這邊不細講。

PhotoWCT
本文提出的PhotoWCT只是架構上的微調,
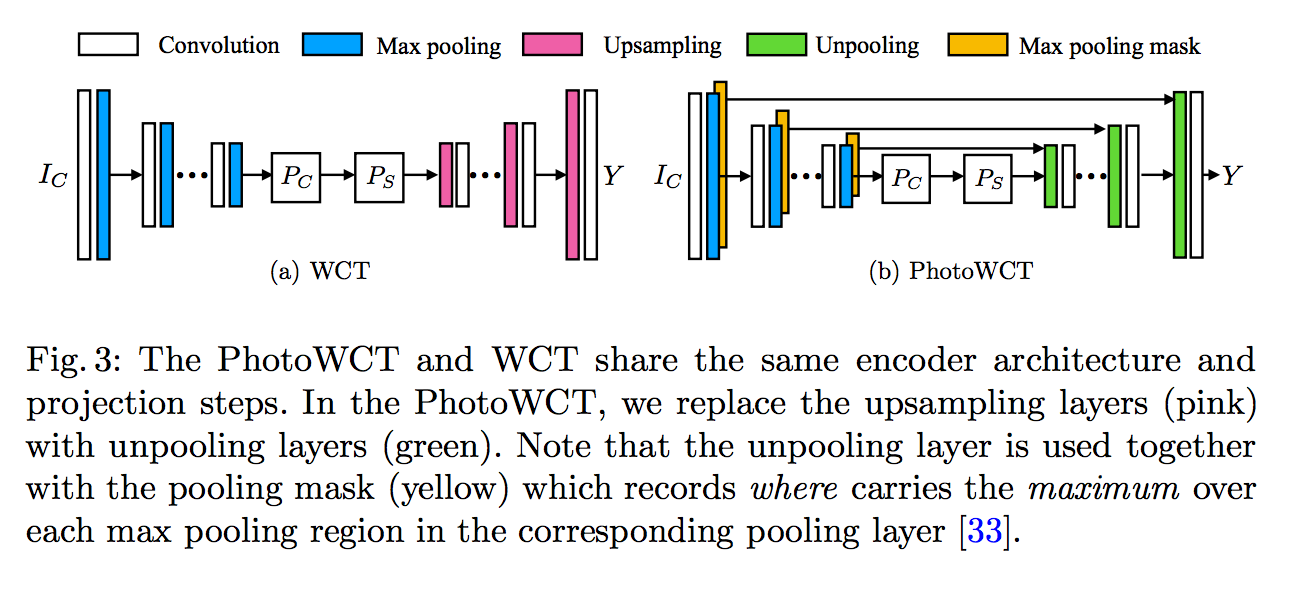
主要是用Unpooling(綠色)取代原本的Upsampling(粉色)。
先說 WCT 為什麼要 Upsampling,
因為 Encoder 有做 Maxpooling,
圖片轉載自:Medium - [資料分析&機器學習] 第5.1講: 卷積神經網絡介紹(Convolutional Neural Network) 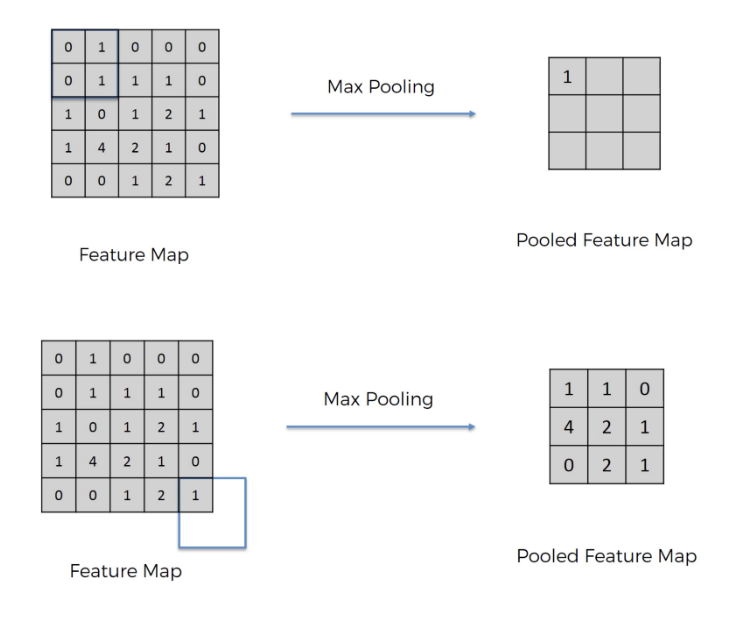
而Maxpooling會讓圖片的尺寸縮小一倍,
這個舉動也將空間資訊破壞掉了,
原本 WCT 是使用 Upsampling 還原,
而單純透過 Upsampling 來做還原的話一些細節其實沒辦法被還原得很好,
因為在Maxpooling時空間資訊就是被丟失了。
而本文提出Max pooling mask 和 Unpooling 做搭配,
透過這個操作其實是可以保留被maxpooling所丟失的空間資訊。
因此最終公式如下:
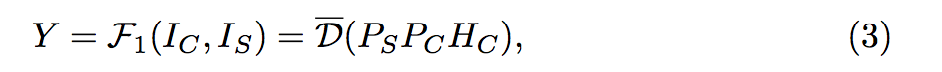
註:Unpooling方法並不是創新的方法,原本就有人用了。(作者有列出下面幾篇論文
Zhao, J., Mathieu, M., Goroshin, R., LeCun, Y.: Stacked what-where auto-encoders. In: ICLR Workshop. (2016)
Zeiler, M.D., Fergus, R.: Visualizing and understanding convolutional networks. In: ECCV. (2014)
Noh, H., Hong, S., Han, B.: Learning deconvolution network for semantic segmentation. In: ICCV. (2015)
仿真平滑化(Photorealistic Smoothing) - F2
事實上單純靠 PhotoWCT 空間得資訊還是保留得不夠好,如下圖:

主要構想:
風格轉換後的圖片應該要像原始圖片Ic。
目標:
- local:周圍pixel間的風格化效果應該要是差不多的。
- global:經過平滑化後,整體圖像的風格轉換應盡量的保留。
最佳化公式ver1.(後面有closed-form的公式,沒興趣的可以跳過這個):
此公式的前半部是解決上方的local問題,後半部則是global的問題,
而 λ 取決於希望要平滑化多一點還是要風格化多一點,
此文後面會用grid search來尋找怎樣的 λ 較適合,並給出圖片比較。

備註:公式的想法來自於graph-base ranling algorithm
Zhou, D., Weston, J., Gretton, A., Bousquet, O., Sch¨olkopf, B.: Ranking on data manifolds. In: NIPS. (2004)
Yang, C., Zhang, L., Lu, H., Ruan, X., Yang, M.H.: Saliency detection via graphbased manifold ranking. In: CVPR. (2013)
- Y:
經過F1後所輸出的基於Ic的風格圖片
- R:
最佳化後的圖片((未知希望求得的
- W:
將每個pixel看成是graph中的node,因此能夠定義出一個 affinity matrix “W” 來表達pixel之間的相似程度。
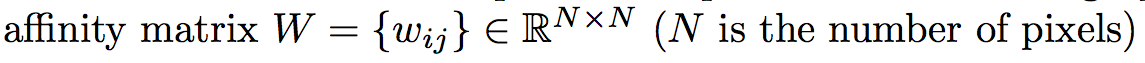
這邊其實也挺有學問的,
使用8-connected image graph 採用 Matting affinity, 並不是 Gaussian affinity,
採用前者是要避免過度平滑,因為他基於local window的,再詳細的我就沒有去理解了,附上引用的 Mattting affinity paper
Levin, A., Lischinski, D., Weiss, Y.: A closed-form solution to natural image matting. PAMI 30(2) (2008) 228–242
Zelnik-Manor, L., Perona, P.: Self-tuning spectral clustering. In: NIPS. (2005)
原文如下:

最佳化公式ver2.(closed-form的版本):
而上方的最佳化公式v1其實很複雜,是個quadratic problem,因此提出closed-form的公式

有興趣的搭配最佳化公式ver1.中的 W 一起看。
經過仿真平滑化(Photorealistic Smoothing) - F2 的結果

λ取捨 - grid search
這邊使用一個技巧:透過Object detection作輔助。
如果在風格轉換過後還能夠偵測物品的前提下,
透過比對bounding box是個不錯的想法,
如果風格轉換過去的兩張圖片(Ic, output)所輸出的bounding box越相近,
代表空間上的資訊都還保留著。
註:
ODS 和 OIS都是 boundary detection metrics的方法,
只要記得分數越高代表兩個bounding box越相近,
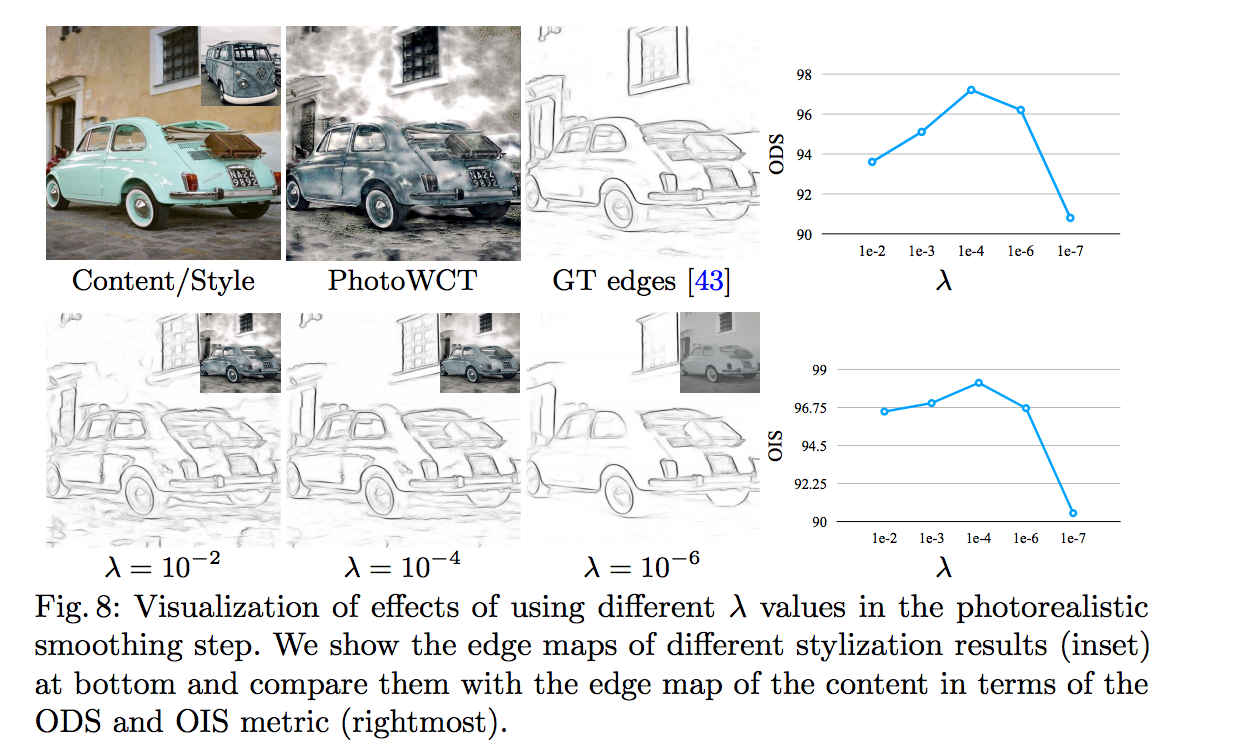
依據上圖所示,我們之後的 λ 都採用1e-4
實驗:
使用 VGG-19 的 conv1_1 ~ conv4_1 當作 Encoder,
此 Encoder 有套用 ImageNet-Pretrined weights了,
而 Decoder 的架構是 Encoder 的反向,
整個 Encoder + Decoder 是在做圖片重建的問題,主要是透過Microsoft COCO dataset做訓練。
Loss function : L2 + perceptual loss。
也採用了前面 WCT 有使用到的 multi-level stylization 的技巧。
結果 :((單純轉換不使用Segmentation作輔助


失敗的Case

這邊作者提出的說法是因為Ic的茶壺表面過於平滑,
而 Smooth step - F2 會偏好讓平滑的面輸出平滑的顏色,反而讓他的畫風轉換的效果變得不明顯了。
可增強的部分:
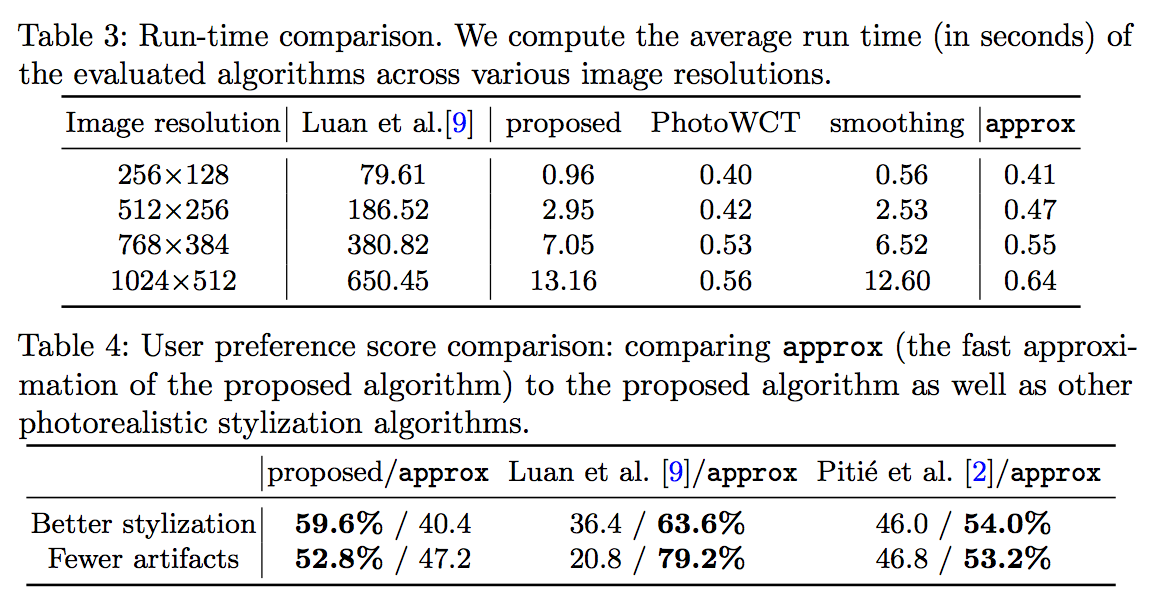
運算速度
使用近似的方法(guided image filtering)的方法取代 Smooth step - F2 加快速度,
後方將近似的方法名稱設為approx
paper : guided image filtering
He, K., Sun, J., Tang, X.: Guided image filtering. PAMI 35(6) (2013) 1397–1409
可利用Segmentaion做增強
其實我是因為這部分才來看這篇paper的。
他的想法很簡單,透過每個 pixel 上的 semantic label 做每個類別的 mask,
而轉換的時候搭配各個 label 的 mask 做畫風轉換,
並且說因為有 Smooth step - F2 所以 Semantic segmentation 不用太準確也沒關係。




結論:
提出新的相片畫風轉換,
而他的User study結果好,效能也好。