圖片Domain轉換 - Domain Stylization- A Strong, Simple Baseline for Synthetic to Real Image Domain Adaptation
Aysegul Dundar, Ming-Yu Liu, Ting-Chun Wang, John Zedlewski, Jan Kautz,“Domain Stylization: A Strong, Simple Baseline for Synthetic to Real Image Domain Adaptation”, arXiv:1807.09384
尚未登上 Conference - Nvidia團隊提出
此Paper於 26 Jul 2018 提出,
本文撰寫於 1th Aug 2018,
這幾天才出的,所以才沒登上 Conference 。
簡介
本篇論文的目標是將合成的CG圖片轉為真實世界的的圖片。
為什麼要這樣做呢?
因為我們如果使用合成的圖片去訓練一個模型,
當那個模型套用到真實世界的圖片時,準確度往往會下降。
而將合成圖片套用到真實世界的圖片,造成準確度下降的問題稱作:covariate shift problem。
為了解決這個問題,很直覺的想法就是將CG合成的圖片轉換得像真實世界的圖片。
此篇是基於現有的相片仿真演算法(Photorealistic style transfer algorithm)做延伸的。
github : FastPhotoStyle
Yijun Li, Ming-Yu Liu, Xueting Li, Ming-Hsuan Yang, Jan Kautz, “A Closed-form Solution to Photorealistic Image Stylization”, arXiv:1802.06474
此篇也是由Nvidia團隊提出的,
有興趣的可以看我寫的簡介,相片風格轉換 - A Closed-form Solution to Photorealistic Image Stylization簡介
第二個貢獻是提出可以透過FID(Frechet Inception distance)來評估此方法的好壞。
概念
提出Domain Stylization (DS)將CG圖片轉為真實圖片,
整體是基於FastPhotoStyle的方法,
他的想法是透過Semantic segmentation作輔助,來讓整個圖片做的越來越漂亮。
下圖是來自Paper:“A Closed-form Solution to Photorealistic Image Stylization”

事實上透過Semantic segmentation輔助的想法在上面這篇paper就已經有揭露了。
概念是A, B照片都是風景畫,
我們會希望 A 照片的山要像 B 照片的山的style,
而不是讓 A 照片的山去考慮 B 照片的天空的。
透過各個 semantic segmentation 的 label 去做限縮,
可以達到更好的 style transfer 。
做法
先將定義說清楚
我們會有2個Dataset
- Ds : CG合成的dataset - synthetic image dataset (Xs, Ms)
- Xs : 圖片
- Ms : Segmentation mask - 因為是CG合成圖片,所以可以知道每個pixel屬於哪個類別。
- Dr : 真實世界圖片的dataset - real image dataset (Xr, Mr)
- Xr : 圖片
- Mr : Segmentation mask - 我們其實沒有 Real world 的 mask,因此會透過一個Semantic segmentation model做預測。
- SSL : Semantic Segmentation Learning
- 為了 Dr 我們要訓練一個Semantic segmentation model(此模型代號為 : s)
- DS : Domain Stylization
- 畫風轉換 - 就是FastPhotoStyle的方法。
想法是這樣
- 首先我們透過FastPhotoStyle的演算法,將合成(Synthetic)的圖片畫風轉換到真實世界(Real world)的圖片。
- 透過上面轉換過的圖片訓練一個Semantic Segmentation Model - s
- 透過 s 去預測出真實世界(Real world)圖片的 Semantic segmentation mask。
- 將 Segmentation 當作輔助,再使用FastPhotoStyle的演算法,會得到比步驟1更好的結果
- 重複2-4步驟,會得到越來越相似真實世界的圖片,做個2次(T = 2)就差不多收斂。
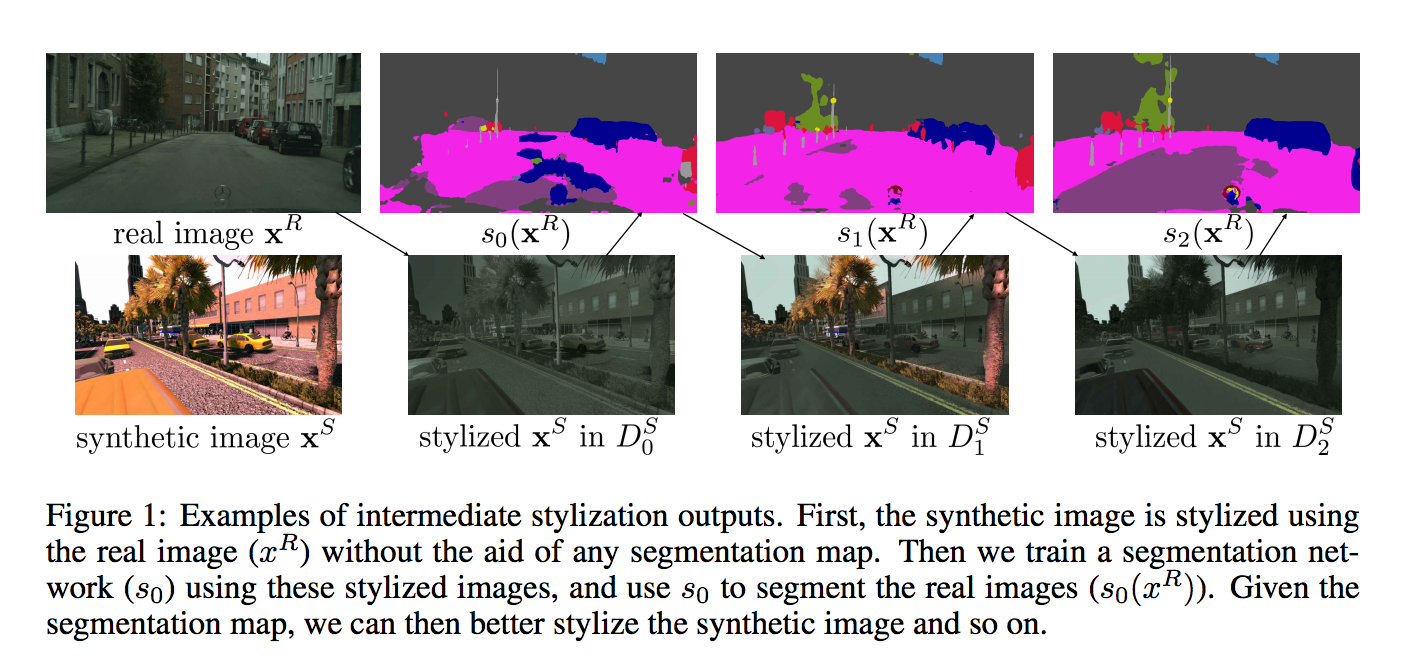
上面的第1步驟寫成公式,如下:
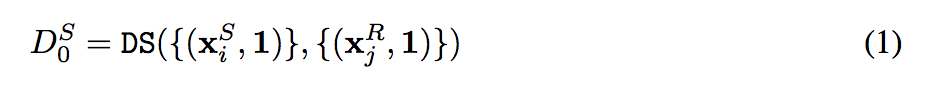
在這邊大家會好奇 { } 的後半部的 “1” 是什麼意思,
定義上是 { 圖片, Mask },
而 Mask = 1 代表的是沒有限縮範圍,
e.g.
A、B圖片都是風景畫,
依照我們剛剛的想法,我們會希望天空會和天空的樣式轉換,
但是這邊我們不使用 Semantic segmentation 作輔助,
因此這邊只是單純的圖片和圖片之間的畫風轉換。
大家可能會覺得那這樣的轉換結果會好嗎?
其實不錯呢,可看下圖,
下圖是FastPhotoStyle的方法,來自Paper:“A Closed-form Solution to Photorealistic Image Stylization”

將上面的第2,3,4 步驟寫成公式,如下:
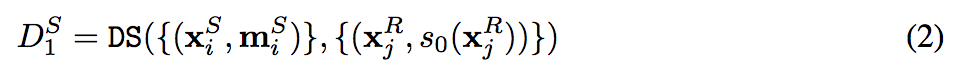
- s0 : 透過合成圖片所訓練出的 Semantic segmentaion model
- s0(Xr) : 透過上面的 Model 所預測出的 Semantic Semantation mask。
而上面兩個公式會發現都有小標 i 、 j,
是因為我們會 Sample 出 N(set : 10) 筆圖片做訓練。
e.g.
我們從真實世界和合成的圖片挑選各10張圖片,
當我們從Ds挑選第i張時,從Dr挑選第j張時的的數學表達式如下:
output:
後面還是Ms是因為 Semantic segmentation 的 mask 還是保留一致,
畫風轉換-FastPhotoStyle當初的構想就是希望畫風的轉換後還是要保留空間上的資訊。
依照上述公式可以得知,我們挑選最終會輸出 10 X 10 = 100張圖片
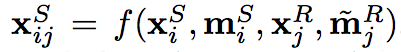
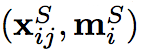
而為什麼要抽樣 N 呢?
這邊給出的說明是:
事實上合成圖片和真實世界的圖片有些可能是很相近(色彩、圖片的結構等等),
但是並沒有一個很好的機器衡量標準,通常還是要透過人眼辨別,
但使用人眼的話就很麻煩,
可是如果每一張合成圖片要和整個Real world的dataset去做生成,那計算資源也太過昂貴。
因此後面會做ablation study,以結果論來說得出 N = 10 。
演算法流程:
- T(幾次iteration) : 2
- N(樣本數): 10

第5行:因 N = 10,所以會產生100張的套用現實畫風的合成圖片用於下一次的Semantic segmentation model訓練。
最終會輸出 St:Semantic segmentation model,
透過這個 St:Semantic segmentation model 對真實世界圖片做出mask,
透過這mask來輔助生成相似於真實世界的合成圖片。
實驗(下面不細講,有興趣自行看論文):
本文設定
- Semantic Segmentation model : 26-layer Dilated Residual Network DRN-C-26
- Pretrained on : ImageNet
- Optimizer : SGD
對兩個主題做實驗
- 室外的街道
- 室內場景
主要和 image translation 的方法做比較((其中還包含GAN-based的方法。
- Domain Randomization
非原本的model,此文還有對此model還有再作修改。
- CycleGAN
- UNIT
- CyCADA
- FCNs-ITW

下面比較的方式是透過各個方法的畫風轉換後,
照理來講用畫風轉換後的圖片訓練Semantic segmentation model,
再套用到真實世界的測試集後,
準確度應該是 > 合成圖片(SYNTH) 並且有很大的機率 < 原本真實世界的training data(REAL) 。
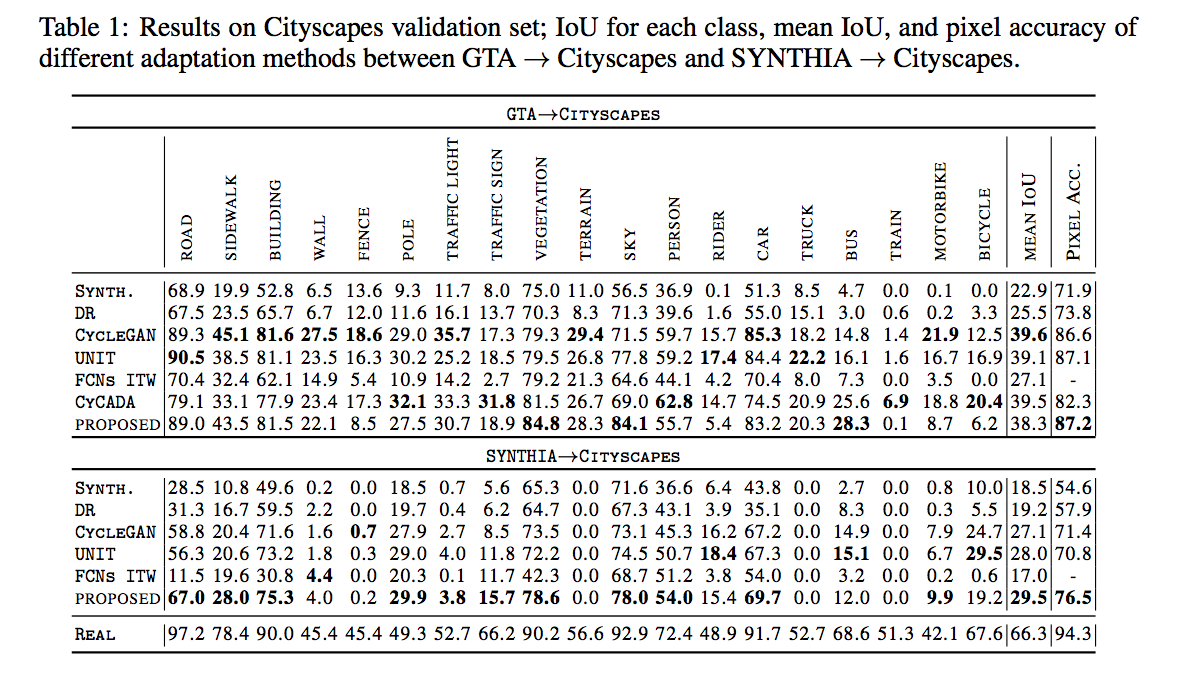
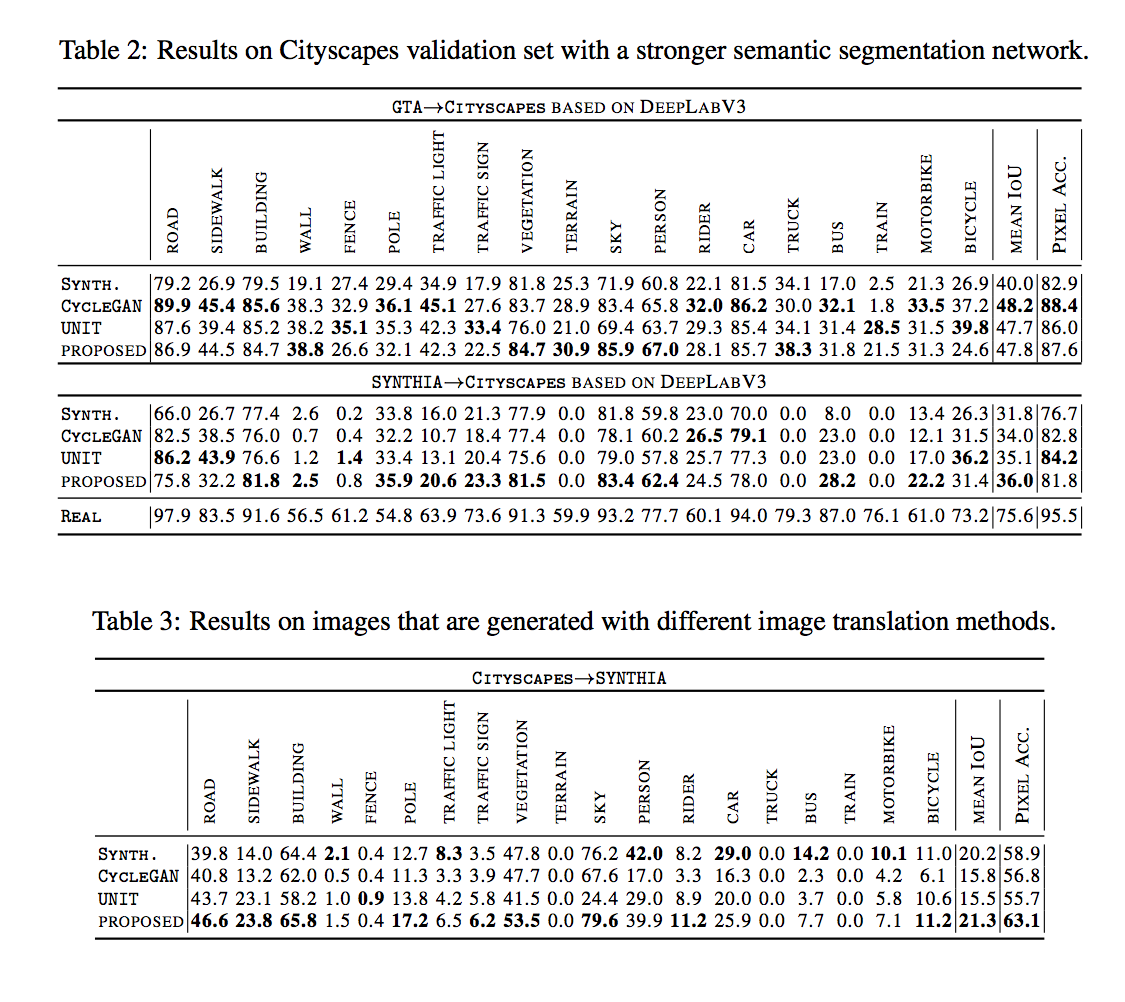
值得一提的是最後面的表格,
用CycleGAN和UNIT轉換後的圖片訓練model,
反而比用原本的合成圖片(SYNTH)還差。
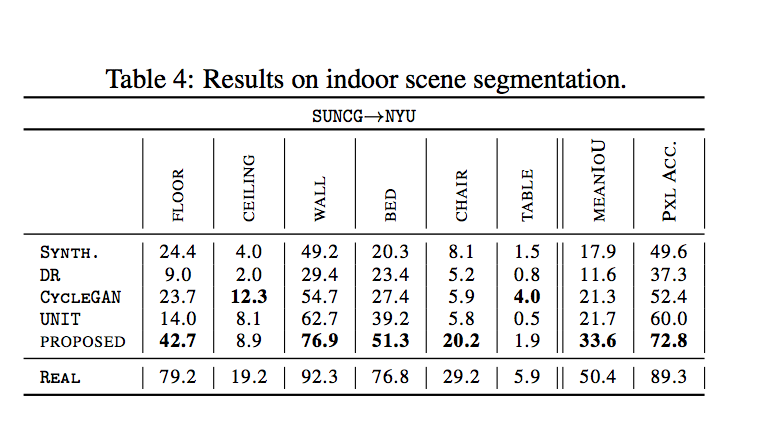
除了對Semantic segmentation做比較之外,
還有對Object detection做比較。
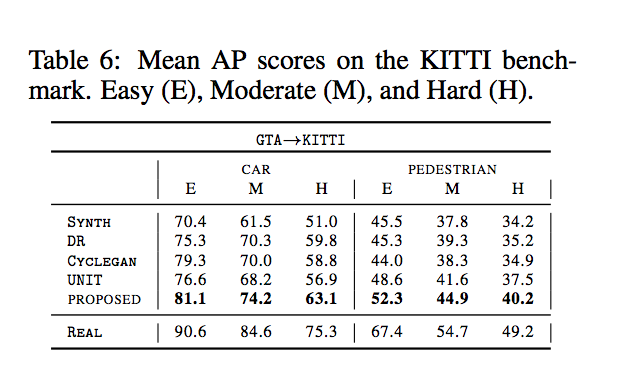
結果是都做得不錯。
討論:
提出透過 Frechet Inception distance (FID) 來量化圖像合成的結果好不好,
簡單來說是透過fetures vector去做比對,
比對 mean 和 co-variance matrix,
這部分有興趣的自己去看論文。
參考資料:
Domain Stylization: A Strong, Simple Baseline for Synthetic to Real Image Domain Adaptation