Structure Inference Net簡介 - Object Detection Using Scene-Level Context and Instance-Level Relationships
Yong Liu, Ruiping Wang, Shiguang Shan, Xilin Chen, “Structure Inference Net: Object Detection Using Scene-Level Context and Instance-Level Relationships”, arXiv:1807.00119
CVPR 2018 paper
Github Code:https://github.com/choasup/SIN
Github Code(核心部分)
- Model架構
line:40~129 https://github.com/choasup/SIN/blob/master/lib/networks/VGGnet_train.py
- Structure Inference 核心
line:333~418 https://github.com/choasup/SIN/blob/master/lib/networks/network.py
簡介
本篇論文主要是在展示透過理解圖片的內容架構,
來輔助物件偵測可以變得更準確。
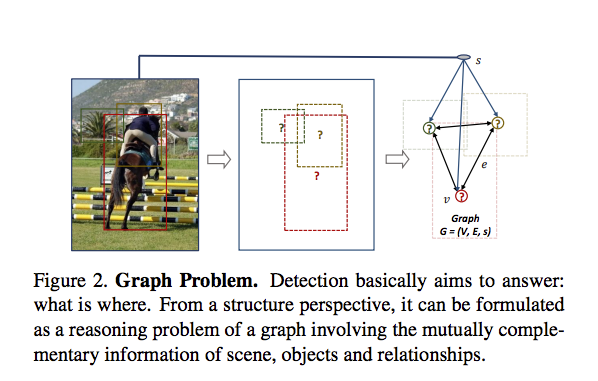
來看看以往的物件識別(Object detection)方法遇到什麼圖片會分類錯誤。

從上圖的左邊我們可以發現,該分類器將船誤分為車子(紅框),
但是如果我們人去看的話,基本上是不會誤判的,
因為我們會考慮場景,這邊的場景是在一個碼頭,
而我們知道車子不會在海上,在海上的通常是船。
而上圖的右方是在說明滑鼠沒有偵測到,
如果我們看到筆電能夠聯想到附近可能有滑鼠的話,
或許就會注意到這個滑鼠了。
因此本文提出結合下方兩個想法來輔助物件識別的任務。
理解圖片的場景(Scen context)
理解物件之間的關係 (Object relationships)
架構
整個模型的架構是基於 Faster-RCNN
對Faster-RCNN不清楚的可以看下面這篇Post,
之所以推薦這篇是因為我認為要學好一件事情,要明白他的歷史演變,
上面這篇有從 R-CNN -> Fast R-CNN -> Faster R-CNN
Faster R-CNN 基本流程
- Region Proposal Network(RPN)
會先給出一大堆有可能是物件的框框
- Non-Maximum Suppression(NMS)
從上面的一大堆框框選出128個(本篇training設定)最有可能的框框。
- 解析每個框框內的圖片資訊,萃取出特徵(Feature vector)
- 輸出最終結果。
而本篇的SIN的流程是在第3步與第4步之間加入Structure Inference的結構,
流程如下:
- Region Proposal Network(RPN)
- Non-Maximum Suppression(NMS)
- 解析每個框框內的圖片資訊,萃取出特徵(Feature vector)
- Structure Inference(本篇重點)
輸入整張圖片與各個框框(128個)的圖片特徵。
- 輸出最終結果。
整體架構:
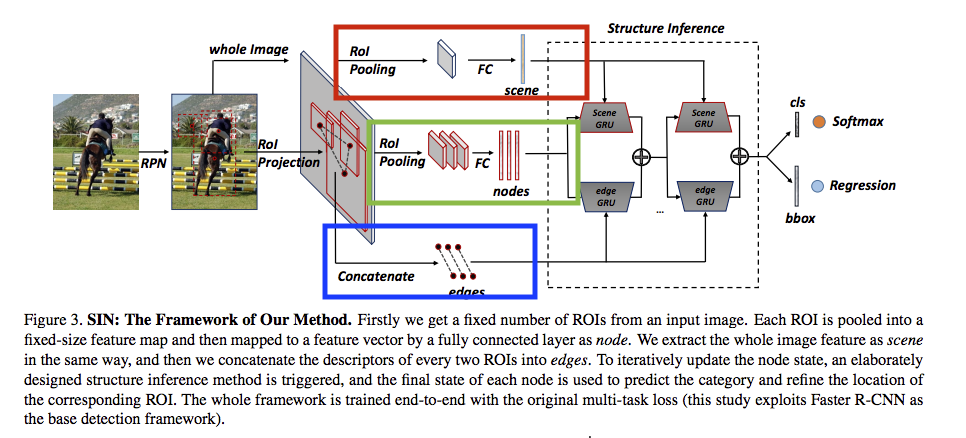
前半部說明(Structure Inference前)
- 紅框 - Scene info
將整張照片(Scene)的資訊透過 Fully connected layer(FC) 輸出一個 dim 為 4096 的 Feature vector,
Shape:(1, 4096)
- 綠框 - Object info
將128個有可能的框框(Object)中的圖片資訊透過 FC 各自輸出一個 dim 為 4096 的 Feature vector,
Shape:(128, 4096)
- 藍框 - Object Relation
計算每個物件(128個)兩兩之間的相關性,透過每個物件的寬(w)、長(h)、面積(s)、中心點(x, y)去做一些計算。
本文並沒有細講為什麼取這12個特徵。
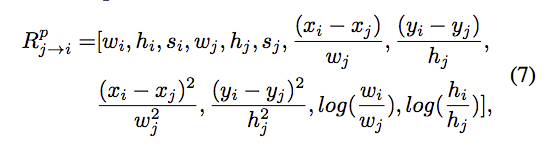
Shape:(128, 128, 12)
備註:
- 紅框與藍框的Fully connected layer(FC)是使用同一個。
- 藍框的 Nodes 與 綠框的 Edges 是希望透過圖論(Graph)的方式來解決物件的關聯性(Object relations),如下圖表示。
後半部說明(Structure Inference)
這部分採用RNN的方式,
原文說採用RNN的原因,其實我也不是很能夠理解,總感覺可以不需要RNN。
但還是硬翻出來,有興趣的看原文3.2 Message Passing的部分。
給出的原因是我們需要處理不同的node(不同的框框)以及scene(場景)的資訊,
因此需要接收不同的輸入,所以我們要有一個可以記住每個node資訊並且可以萃取出更有用資訊的功能。
我個人的簡單理解如下
首先丟入一堆資訊(實際上是丟入4096維的feacture vector):
Scene : 在草原上
Objects : 有著人、狗、羊、車、船。
這時候RNN記住了,有個大概的想像(hidden state)。
再輸入一次
Scene : 在草原上
Objects : 有著人、狗、羊、車、船。
這時候RNN突然醒悟了! 奇怪草原上會有船嗎?
因此將船的特徵去掉,應該是只有人、狗、羊、車吧?!
假設我上面說的有點道理,
採用RNN的觀念大概就這樣。
而此文採用的是GRU,為RNN的變形,
採用的原因是相較於LSTM來說,它更為輕量、有效率。
GRU細節跳過,我認為不影響整篇論文解讀。
有興趣的話Paper 3.2 Message Passing的部分
Structure Inference架構
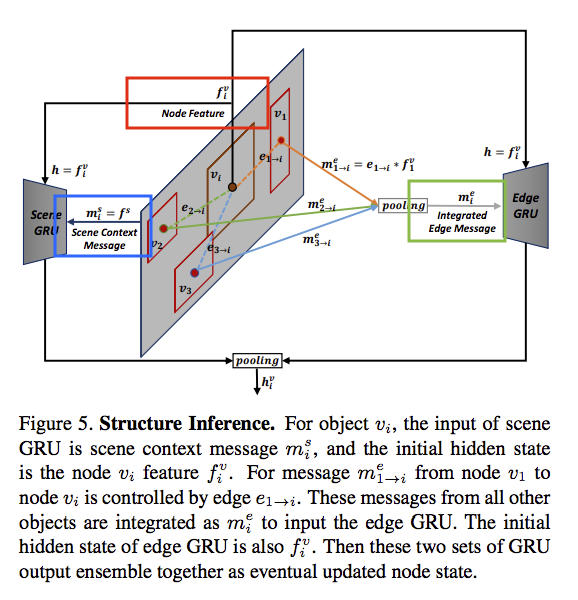
上面這架構有點複雜,我們一個一個來講解。
首先中間灰色的部分是一張圖片,
而一張圖片我們會選出128個候選框可能是最終的輸出,
我們會對那128個候選框都得到一個 dim:4096 的 feature vector,
因此Shape為(128, 4096) => fv
這fv擁有著128個框框的資訊。
我們會將 fv 當作 Scene GRU 以及 Edge GRU 的initial state(上圖紅框),
為什麼要這樣做呢?
以往的GRU的initial state都是random的,
而這邊給出的解釋是:以往的GRU都是著重於輸入序列(Sequece)資料,
但是我們這邊使用GRU是為了要記住每個物件的狀態(Object state),
因此 initial state 為每個物件的 feature vector。
Scene GRU 應用場景想像:
我們GRU紀錄著128個不同的框框,而每個框框代表著不同/相同的事物e.g. 人、動物、車、船。
當我們輸入場景為馬路(上圖綠框)時,
我們希望GRU可以忽視掉我們框框中有船(因為常理來說此物件與該場景吻合度很低,
藉此達成更高的準確率。
Edge GRU 應用場景想像:
我們GRU紀錄著128個不同的框框,而每個框框象徵(意味著分類可能分錯)著不同/相同的事物e.g. 人、高爾夫球、棒球棍、廂型車。
因為我們採用圖論的概念,我們會得到每個框框之間的距離/相關度,
透過這個相關度,我們可以調整各個事物的預測。
舉例來說:我們看到人和高爾夫球和棒球棍,
會開始思考奇怪,會不會這不是棒球棍而是高爾夫球竿呢!?
將上面得到的資訊 - 人、高爾夫球、高爾夫球竿、廂型車(上圖綠框)再經過一次GRU,
他這次會變成人、高爾夫球、高爾夫球竿、車,
然後再思考,會不會這個車是高爾夫球車呢?
再將上面得到的資訊(上圖綠框)再經過一次GRU,
得到最終的輸出為人、高爾夫球、高爾夫球竿、高爾夫球車,
一切看起來都更加合理了。
下方為上面邏輯的公式。
R : 明白物件之間的屬性(長寬、中心點等等)的相關性 。
e : 一個相關性分數(scalar純量),透過上方的 R 明白每個物件之間的相關性。
m : 透過上方的相關性分數(e)與每個候選框的feature(fv)整合起來當作物件的資訊,當作下次Edge module的輸入 。
計算每個物件(128個)兩兩之間的相關性,透過每個物件的寬(w)、長(h)、面積(s)、中心點(x, y)去做一些計算。
本文並沒有細講為什麼取這12個特徵。
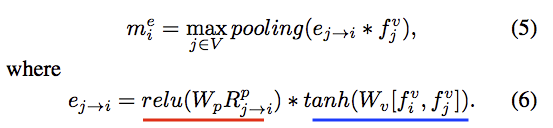
Wp 以及 Wv 為自己學習得來的參數。
eq6 的想法是我們可以知道哪些物體之間是較有關聯的,
如:滑鼠與鍵盤的相依性 > 杯子與鍵盤的相依性
而eq6的前半部(紅色底線)是空間上的相關性,距離近不近之類的。
eq6的後半部(藍色底線)是視覺上的相關性(visual clues),這邊就只能想像不能舉例,畢竟他是 Feature vector。
最終我們的 e 是一個 scalar,代表著一個相關性的分數。
透過這個分數我們可以代入 eq5 ,獲得對每個框來說,其他的框哪些是對他有影響的。
而這個 eq5 得出的 m ,才是我們輸入進 Edge GRU 的東西。
最終我們會結合 Scene GRU 與 Edge GRU 所輸出的 hidden state 結合後做狀態(Hidden state)更新以及最後的分類。
所以這邊其實很有趣,我們不是使用 GRU 的 Output, 而是使用最終的 Hidden state做分類,
這邊其實是呼應的一開始的想法,
GRU 的 Initial hidden state 設為每個框框的 Feature vector 用於記錄每個物件的狀況(Object state)。
因此最後也是使用 Hidden state (代表著每個物件的狀況) 做分類。
備註:
看架構圖,Structure Inference 的 Scene GRU 以及 Edge GRU 各有2個,
實際上是各1個, 上圖的兩個代表t = 0, t = 1時不同的時序。
t = 0 時先算出 Hidden state 再傳入同一個GRU(此時t = 1),
最後再將 Hidden state 輸出為最後的結果。
實驗結果:
在 PASCAL VOC 以及 COCO Dataset做實驗,
主要與Baseline(Faster-RCNN)相比。
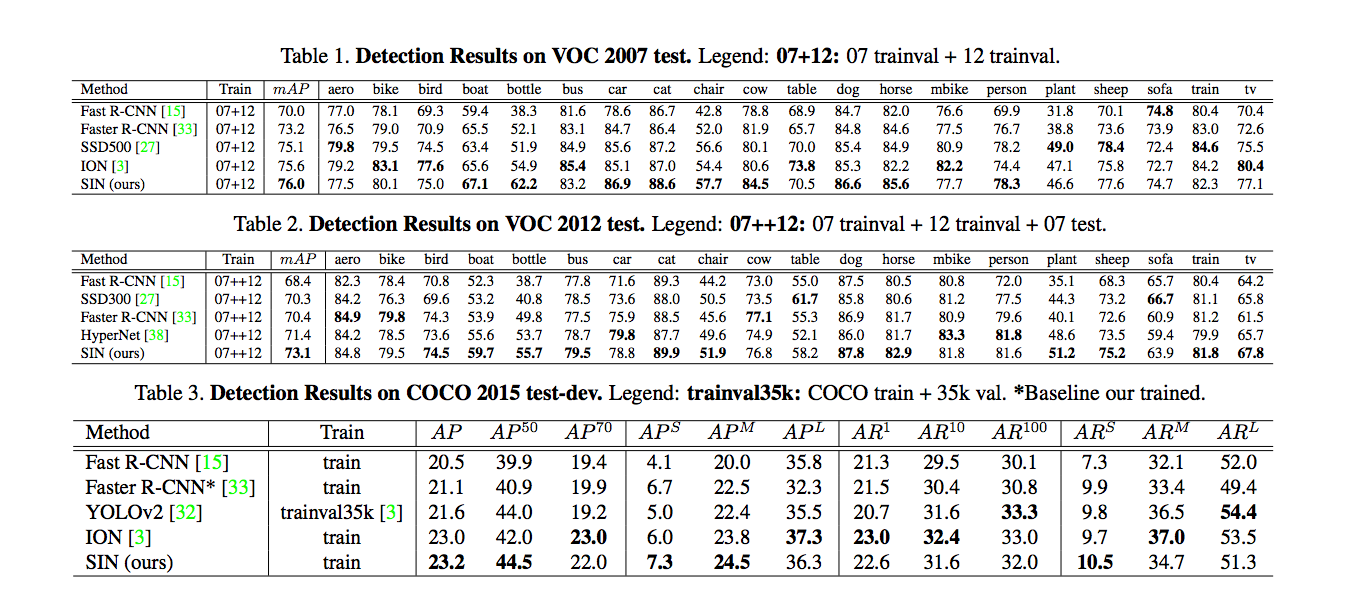
Scene/Edge ablation study
可以看出 Scene module 對船的準確度提升得很顯著。

Scene module 優勢
下圖上方為baseline的方法,而下方為本文SIN的之結果。
左1上為 Faster-RCNN 將船誤判為車子,但左1下SIN方法卻沒有誤判。
中1上為 Faster-RCNN 將並沒有認出椅子,但中1下SIN方法卻有認出。
最右方的是兩個方法都有錯誤的(Failure case), 右上為 Faster-RCNN 有認出飛機,但是多誤判了一個船,而右下SIN方法誤判為船。
而最右方也是本文有提到的問題,當使用 Scene module 時,遇到這種特殊例子會誤判,因為直覺上河出現的是船而不是飛機。

Edge module 優勢
在 Faster-RCNN(下圖左方) 當同一個物件相似很多不同類別時,它會在該物件上框出很多物件,
而基於 Faster-RCNN 加上 Edge module(下圖右方) 後就避免了這種問題的產生。

而下方這張圖是展示使用了 Edge module 後的關聯性視覺化(紅色虛線)。

如何結合 Scene 以及 Edge module
可以知道使用 Mean-pooling 做結合效果最好,
以及顯現出當 Time steps 越多不見得越好的問題。

結論:
本文提出基於 Faster-RCNN 加上 Scene / Edge module 來輔助物件識別的任務,
而看到上方的實踐結果,可以明白使用 Scene module 可理解該該圖片的場景和預測的物件之間是否有相依,藉此提升準確度。
而 Edge module 也展現出了它可以解決某些問題。
但整體而言還是有些問題,
當圖片出現有些不合邏輯的情況時就會分類錯誤,
如上面有提到的當河邊有飛機的情況。
參考資料:
Structure Inference Net: Object Detection Using Scene-Level Context and Instance-Level Relationships