Effective Use of Synthetic Data for Urban Scene Semantic Segmentation簡介
Fatemeh Sadat Saleh, Mohammad Sadegh Aliakbarian, Mathieu Salzmann, Lars Petersson, Jose M. Alvarez, “Effective Use of Synthetic Data for Urban Scene Semantic Segmentation”, arXiv:1807.06132v1
ECCV 2018 paper
Github Code:沒找到,如果有的話歡迎留言,我會再做更新。
簡介
本篇論文在展示如何有效的使用合成(Synthetic)的圖片訓練語意分割模型(Semantic segmetation model),
以往的語意分割模型若只使用合成的資料訓練再將其應用於實際場景的資料集時,
那個準確度會低很多,
因爲合成的資料集與現實世界的資料集還是會有差異性的,
兩者間有著 Domain shift 的問題,
為了解決上述的問題,
近年有個研究領域為 Domain adaptation,
但是 Domain adaptation 需要現實世界的資料集作輔助,
而這篇論文主打著不需要現實世界的資料集,
僅憑合成圖像訓練後,
直接應用於現實世界的資料集也能夠獲得相當高的準確度。
我們先來看看現實的資料集-Cityscapes 和合成的資料集-GTA5的差異,

可以看到前4個的背景其實是挺相似的,
但是後3個的前景其實只有形狀相似,圖片材質就差很多了。
本篇所給的概念是我們前景的 Segmentation 要利用形狀來學習,
因此提出使用 Detection-based 的方法 - Mask R-CNN
背景的部分因為形狀、材質都很相似,
因此使用常見的 Semantic segmentation model - Deeplab 來學就好。
下方這張圖也給出一個證明,使用 Detection-based 的方法在前景物品的偵測是較為準確的(除了motorcycle的類別。
備註:
下方的分數為mIOU,分數越高越好。

方法
下方會依序介紹這兩項:
- Detection-based Semantic Segmentation
僅依靠合成的圖片做訓練
- Leveraging unsupervised real images
利用真實的圖片做訓練,使用 Weakly-supervised 的概念。
方法 - Detection-based Semantic Segmentation 架構
先看步驟,讓你有個大方向。
- Deeplab : 先透過 DeepLab 切出整張圖片的 Segmentation (會使此Segmentation當做基底)
- Mask R-CNN : 再透過 Mask R-CNN 將前景的 Segmentation 切出來 (會使用這部分的前景)
- Conbime : 將 Mask R-CNN 的前景預測直接蓋在 Deeplab 所預測的圖片上面
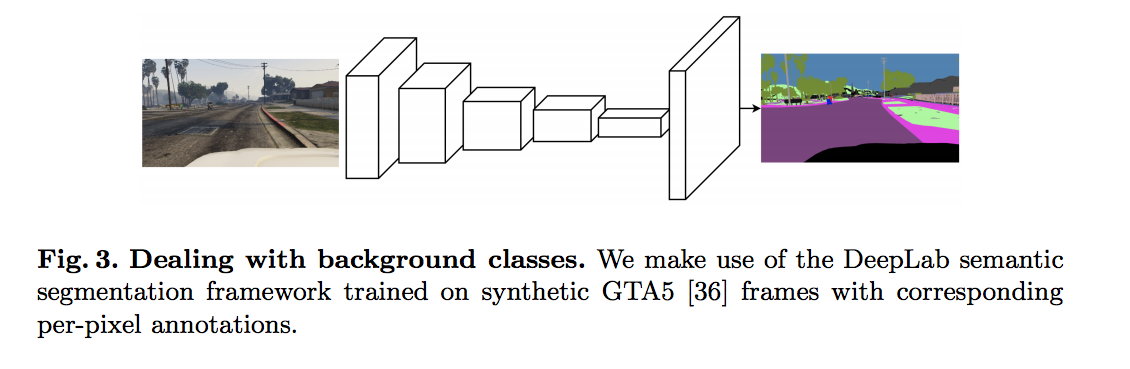
Step 1 - DeepLab
將圖片輸入進 VGG16-based DeepLab model,
並且使用 dilated convlution layer(這不多做介紹了,有興趣去看DeepLab系列)。
此 Model 的輸出會和 Ground truth label 做 Cross-entropy。
備註:
因為原始圖片的解析度很高,實際上訓練時會先 Resize 成一半的解析度。
Step 2 - Mask R-CNN
使用的是:Detectron Framework github
對 Mask R-CNN不清楚的可以看下面這篇Post,
之所以推薦這篇是因為我認為要學好一件事情,要明白他的歷史演變,
上面這篇有從 R-CNN -> Fast R-CNN -> Faster R-CNN -> Mask R-CNN
將圖片輸入進 64 × 4d ResNeXt-101-FPN 的 Mask-RCNN 得出前景(Foreground 的 Semantic segmentation),
如下圖:
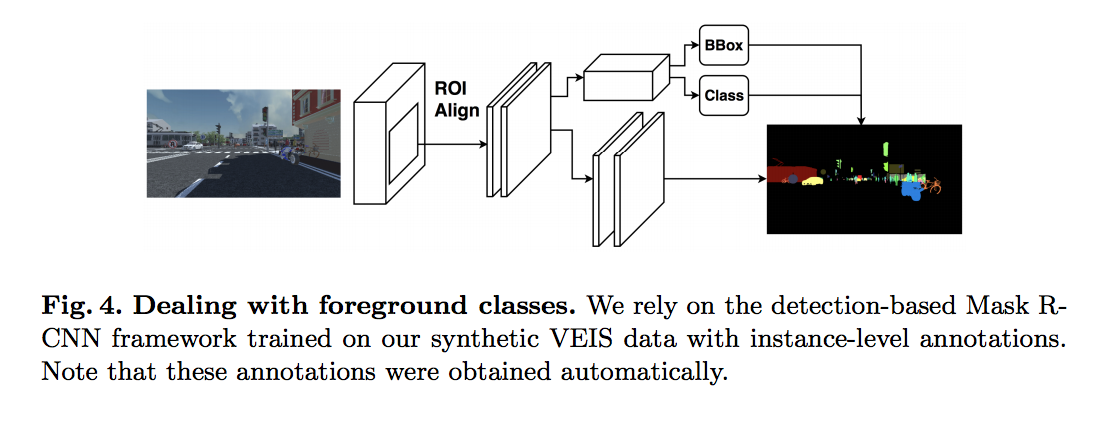
備註:
單憑 GTA5 的資料集是無法訓練 Mask R-CNN的,
因此之後會介紹本篇論文的第 2 個貢獻 VEIS dataset,
Pretrained on ImageNet,並且會透 VEIS dataset做訓練。
Step 3 - Combine
這邊有對 Mask R-CNN 的方法做類似 Non-Maximum Suppression(NMS) 的方法 ,
對 NMS 不清楚的可以去研究一下, 這在 Semantic segmentation 很常見,這邊不贅述了。
最終將 Mask R-CNN 沒有輸出到的 pixel 都用 DeepLab所輸出的 Pixel 做填補,
此時的輸出就是 Mask R-CNN 的預測(著重前景) + DeepLab 的預測(負責整張圖片) 做結合。
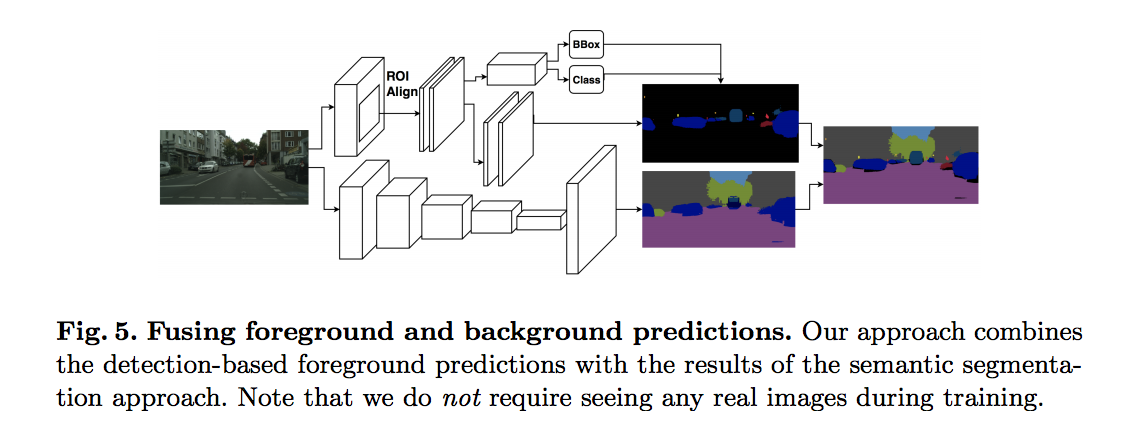
方法 - Leveraging unsupervised real images
這邊的想法很簡單,
就像是 Domain adapatation ,
上面的方法只使用合成的圖片做訓練,
而這邊也會使用真實世界的圖片做訓練。
但是是有策略地做訓練,
基於一開始的結論,
合成圖片的背景部分和現實世界的背景圖片是相似的,
因此我們會使用 DeepLab 所預測的真實世界圖片label(僅限背景部分 - 馬路、人行道、建築等等 )做 loss function。
此時我們的 Model 不只是對合成圖片的 Ground truth label 做 cross-entropy loss,
還會對我們預測出來的 label(僅使用背景部分)做 cross-entropy loss。
備註:
因前景的材質長得不一樣,
因此剛開始的 Mask R-CNN很爛,
還需要學習,
所以不使用它所預測的結果。
而使用 DeepLab 所預測出來結果當 label 是個險招,
這必須確保他一開始並不是太爛,才能夠慢慢的進步,不然只是找自己麻煩。
結果顯示:這招有用。
貢獻2 - VEIS
如果我們使用 Detection-based 的方法,
那我們就必須知道每個物件(Instanced level)的pixel在哪邊。
你可能會想說 Segmentation 的資料集不就有每個 pixel 的 label 了嗎?
我們來看看 GTA5-dataset 的圖片
Richter, S.R., Vineet, V., Roth, S., Koltun, V.: Playing for data: Ground truth from computer games. In: European Conference on Computer Vision. pp. 102–118. Springer (2016)

雖然知道每個pixel的label是什麼,
但是他不知道每個物件(instance)的bounding box,
e.g.
想像當兩台車連在一起時,
這時單從 label 來看,
我們無法得知有兩台車,
可是若要使用 detection-based 的方法,
我們應該要知道每台車的 bounding box 才能訓練。
因此此篇的第二個貢獻是 VEIS (Virtual Environment for Instance Segmentation),
透過遊戲引擎 - Unity3D 生成都市的合成圖,
藉由這種方式可以輕鬆地取得每個物件的Segmentation,
用來訓練 Detection-based 的方法,
但你可能會想說可是這生出來的和現實的圖片差這麼多,
但其實是沒關係的,藉由最一開始的想法,
前景的偵測我們只要形狀相似就好了。
下圖為 VEIS 的示意圖。

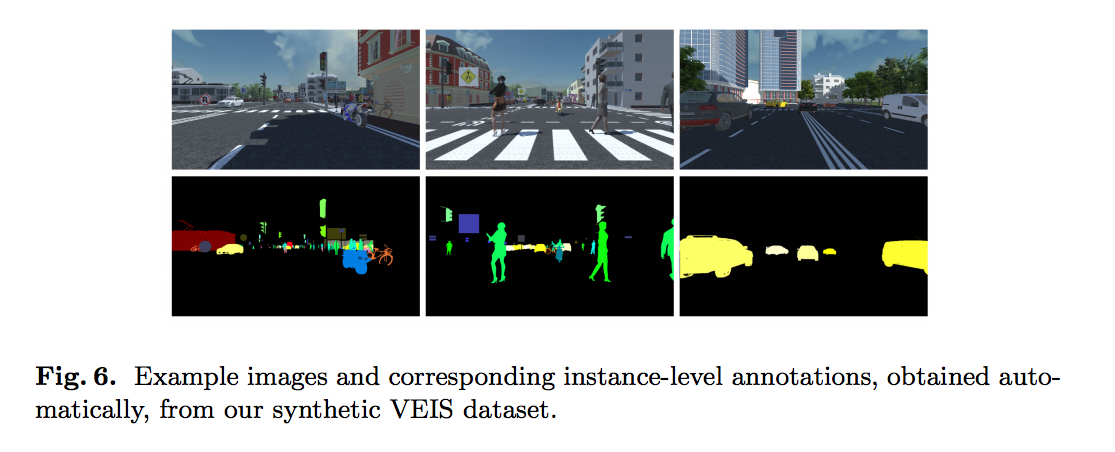
VEIS 會生成2種場景
- 複雜的場景 : 多個類別,像是真實世界一樣會有很多不同的物件。 - 30180張圖片
- 簡單的場景 : 單一類別,結合不同的背景(天空、道路、人行道、建築物)。 - 31125張圖片
透過少量的樣本數(不同的人物、車子等等),利用姿勢(pose)及各個角度的變化重複使用至各個場景。

備註:
其實有類似功能的專案 - CARLA Simulator
但作者認為並不需要用到上面提到的這個,
因為上面這個比較複雜,
我們的任務只是要利用前景的形狀而已。
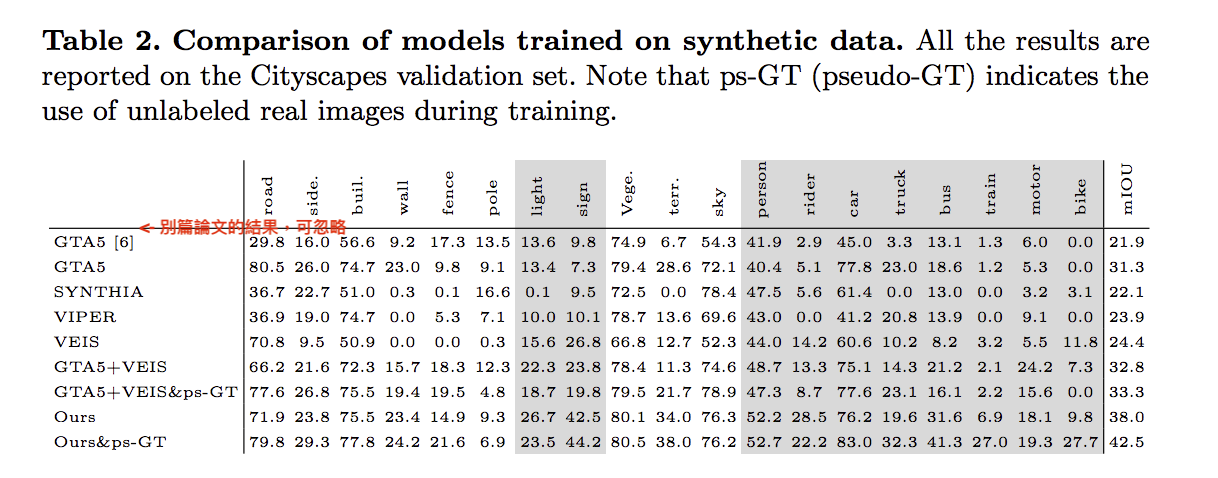
實驗結果:
下方表格主要在述說用哪種資料集訓練 DeepLab model,
而表格下方的 Ours : DeepLab model + Mask R-CNN,
表格方法若有 ps-GT : 就是有利用真實世界的資料去做學習(先預測然後用背景當Ground truth)。
而表格中的分數是使用 Cityscapes 資料集做驗證。
值得一提的是當使用 GTA5 + VEIS 並沒有比較好,因為VEIS所生成出來的材質其實和真實世界也不相同。
但若是採用本文的方法(Ours),透過偵測前景的話結果則有很顯著的提升。(mIOU:32.8 -> 38)
再結合 ps-GT 會更好。(mIOU:38 -> 42.5)
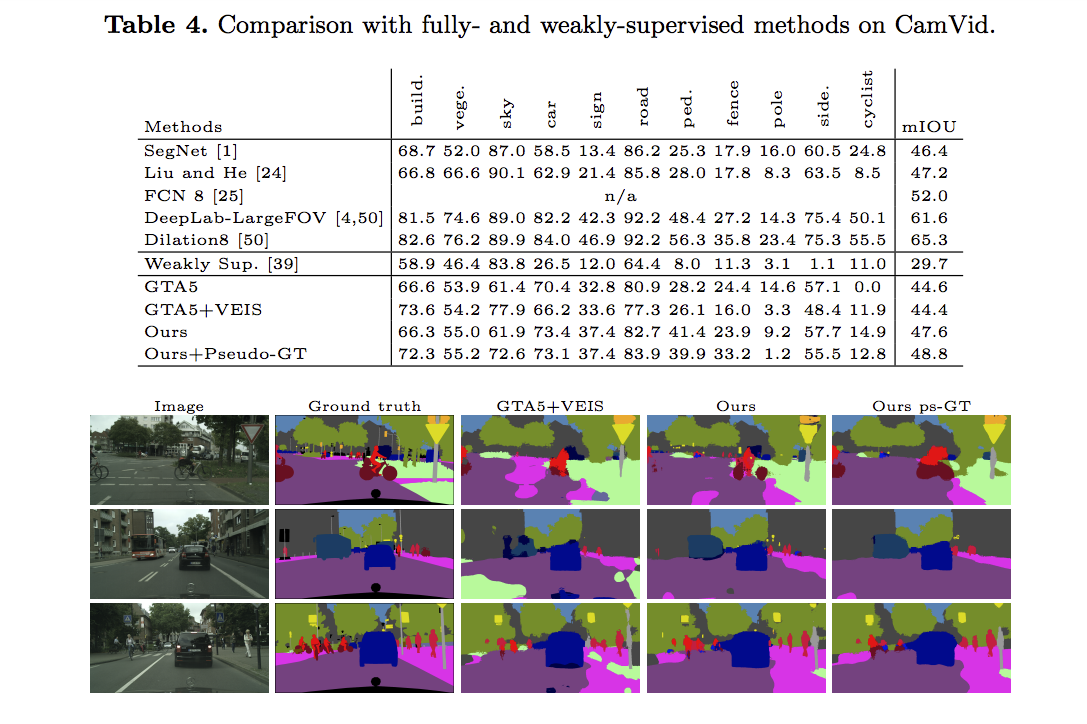
和其他 fully- and weakly-supervised的方法比較
提出形狀相對於材質更能夠解決Domain Shift的問題
實驗方法1:訓練VGG-16的分類器去分辨一張前景圖片的輪廓是合成的圖片還是真實世界的圖片,
本文說他們很努力訓練就是只有70%的準確率,
而達到70%這件事,其中還有點作弊,因為使用合成圖片的輪廓會更加清晰,
但是儘管如此,單憑輪廓還是不易區分出兩者的差別。
而當我們使用同樣的架構去分類一張圖片的紋理材質是來自合成的圖片還是真實世界的圖片,
此時分類器準確度達到了95.1%,
這顯現出材質紋理比形狀更容易認出是哪個domain,
換句話說當使用輪廓去區分物體的時候,
是較不容易受到圖片風格的不同而受到影響的,
透過這特性可幫助 Domain adaptation 做得更好。
實驗方法2:訓練多類別的分類器,分辨這物件是哪個類別。
使用 VEIS 的資料集訓練。
透過輪廓區分:
- 真實世界圖片的準確度 : 81%
- 合成圖片的準確度 : 89.2%
透過材質紋理區分:
- 真實世界圖片的準確度 : 83.7%
- 合成圖片的準確度 : 94.2%
這邊提出的說法是材質紋理的準確度落差比較大,
因此透過形狀辨認是相對穩定的。
備註:
我個人對實驗 2 所得出的結論還是有點疑惑的。
結論:
本文提出利用 detection-based 的方法來輔助城市的 Semantic segmentaion 任務,
而僅憑合成的圖片就可以達到這種準確率真是令人驚艷。
參考資料:
Effective Use of Synthetic Data for Urban Scene Semantic Segmentation