SPG簡介 - Self-produced Guidance for Weakly-supervised Object Localization
Xiaolin Zhang, Yunchao Wei, Guoliang Kang, Yi Yang, Thomas Huang, “Self-produced Guidance for Weakly-supervised Object Localization”, arXiv:1807.08902
ECCV 2018 paper
Github Code(Pytorch):https://github.com/xiaomengyc/SPG
簡介
本篇論文在展示如何透過一張圖像以及物件的 label 就能獲取我們感興趣的部分。
e.g. 給定一張鳥的圖片,能夠知道圖片的哪些pixel是鳥。
主要構想是透過 Attention map(類似熱力圖),
透過它來了解這張圖片的哪個區塊最能夠代表這個物件。

以往若是使用Attention機制來做的話,
會發現它往往只會聚焦在圖像中的最能夠辨別的幾個點。
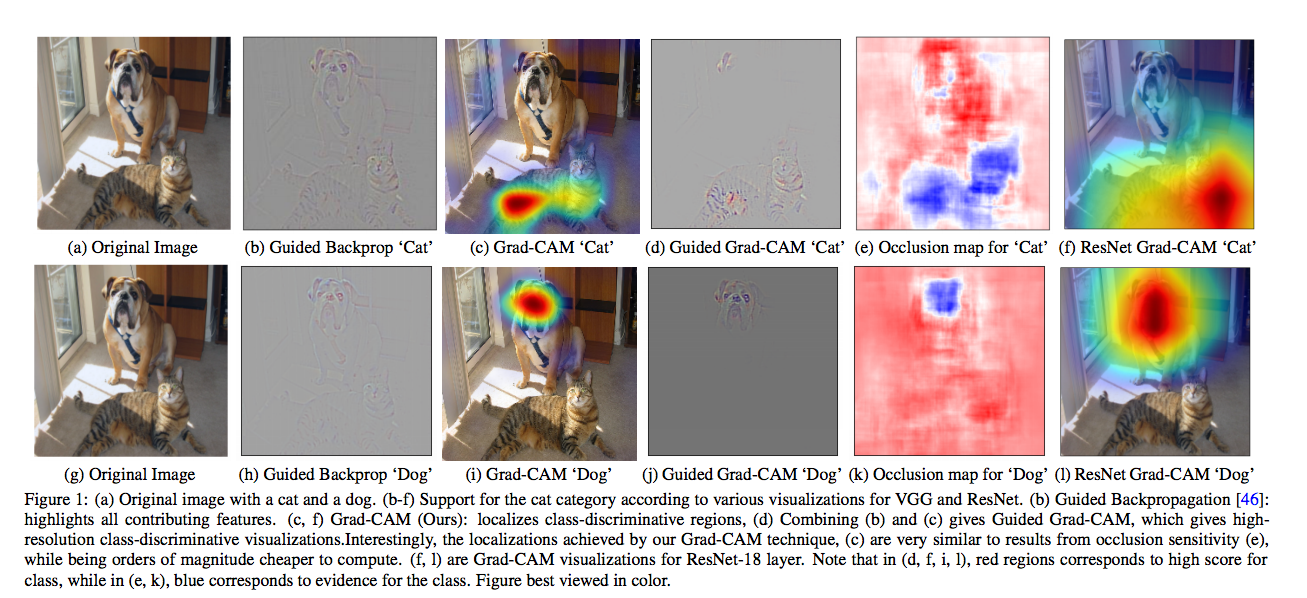
看看以往的 paper 結果:
Ramprasaath R. Selvaraju, Michael Cogswell, Abhishek Das, Ramakrishna Vedantam, Devi Parikh, Dhruv Batra, “Grad-CAM: Visual Explanations from Deep Networks via Gradient-based Localization”arXiv:1610.02391
可以發現以 Grad-CAM 的 Attention 結果還不算太好,因為它還是聚焦在狗或貓的某個部分。
這邊其實還有一個伏筆,
看到最右邊那一欄 - ResNet Grad-CAM 的結果比一般的 Grad-CAM好,
這意味著 Attention 的好壞和分類器的架構有關,在本篇的最後也有這個實驗。
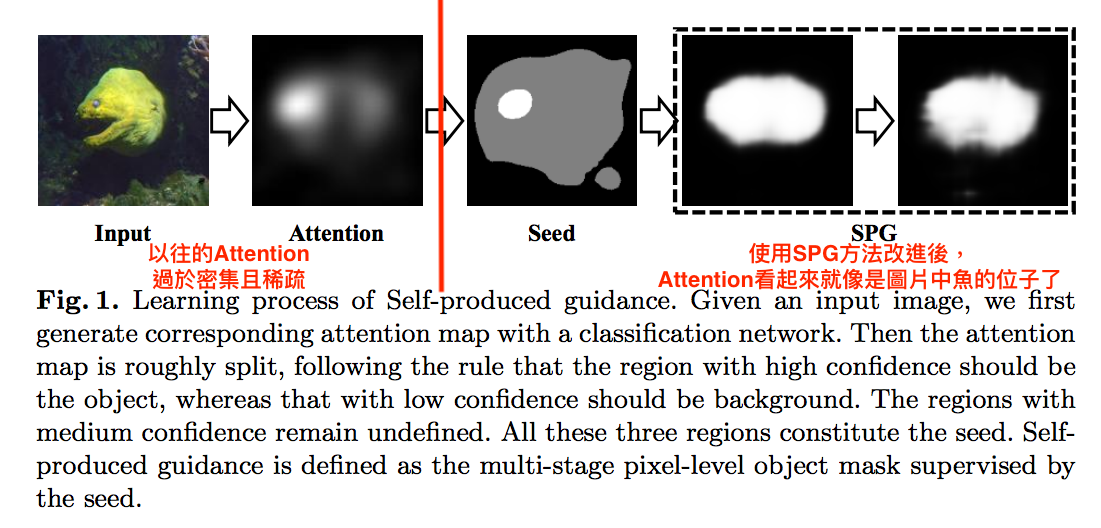
而本文提出 SPG 的方法來讓 Attention 的 Mask 更加的吻合圖像中物體。
為什麼要使用 Weakly Supervised
這邊大家可能有個疑問是那為什麼不用 Ground-Truth(GT) 的 Mask 去做 Supervised Learning,
而是用 Weakly Supervised Learning (WSL)訓練?
如果要使用 Ground-truth 的 Mask 作訓練的話,
需要有大量的 Mask(Pixel-level)當 GT ,
而這件事是需要透過大量的人力去標注的,
其實成本是很高。
如果能透過 Weakly Supervised 的方法就能大致的準確的話,那其實是省下很多力氣。
因此這篇論文主要想解決的問題是 Weakly Supervised Object Localization(WSOL)。
只希望透過一張圖片(Image-level)和物件的label就能夠找到哪邊是物件的位置。
概念
首先要有個概念是 CNN 前面幾層學到的東西是相對於低階(紋理),
而最後幾層學到的是較為高階的資訊。
因此 Attention 都是在最後一層 Conv 輸出。

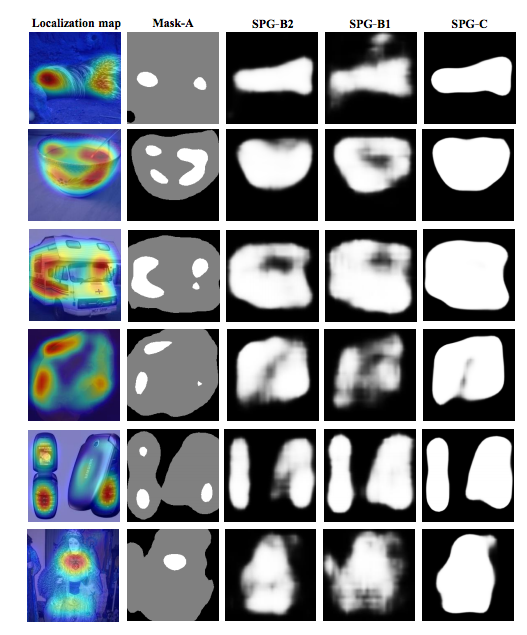
由上圖可以看出白色的部分是前景,而全黑的部分就是背景。
但這個 Attention 作為 mask 來說還不夠好,
Mask 應該要像魚的形狀而且還要很白才對!
那如何能讓這個 Attention 更好呢?
我們知道在物件定位的任務,物件都是在前景的部分。
基於這個想法,我們使用最後輸出的 Attention 輔助前面幾層學習前後景的觀念,
透過這個觀念訓練前面幾層,
就可以有效的過濾出前景的位置,
可能以前是到最後一層才能夠明白前後景的觀念,
但是透過上面這種方式學習,在前面幾層就已經學會了前景的觀念,
那麼後面幾層就可以將前景的特徵學的更為透徹,
藉此提升最終的 Attention mask 的準確率
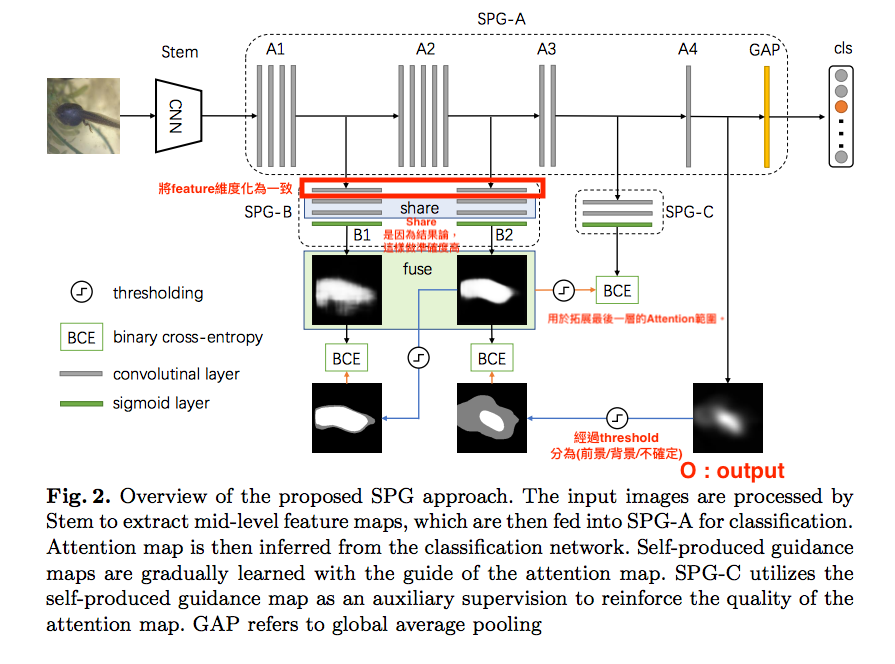
架構
這架構直接看會很混亂,
請搭配下方流程一起看。
流程
先介紹流程,讓大家有個想像,這樣看Model會比較順利。
為了讓大家方便對照流程與上圖架構,符號定義在流程下方
- 圖片(I)經過 Stem 獲得一張圖片的 Feature
- 將 Feature 輸入進 SPG-A 從 A4 的位置處獲得我們的 Attention mask - O(最終我們使用的output)
- 將 Attention mask - O 計算δ (Threshold),辨別是否為 前景/背景/不確定,計算方式請看下方 δ (Threshold)部分
- 獲得一張新的 Mask - M,其 Mask 包含 3 個值 (前景/背景/不確定)
- 將 M 與 A2段(SPG-B2) 所輸出的 Mask 做 BCE-Loss(只對前景和背景部分做,不確定的pixel就不會做BCE)
- 從 A2(SPG-B2) 得出的 Mask 與 A1段(SPG-B1) 所輸出的 Mask 做 BCE-Loss(只對前景和背景部分做,不確定的pixel就不會做BCE)
- 將 A1(SPG-B1) 與 A2(SPG-B2) 的 Mask 取平均(相加/2) 得到 fuse-mask
- 透過 fuse-mask (經過Threshold)與 A3 段所輸出的 Mask 做 BCE-Loss
本文的重點,
透過合成出來較為寬大的 Mask 做 BCE-Loss ,
目的是讓 Model 學習最終輸出的 Mask 不要像原本一樣小且稀疏。
備註:Mask 在傳遞時都會通過 threshold 的計算, 請注意架構圖。
定義一些符號
- I (訓練資料)
I = {(Ii, Yi)}
Ii 為第 i 張圖片, Yi 為第 i 張圖片的label, Y ={1…C} 有 C 的類別。
- Stem
特徵萃取的Model - 這邊設定為 Inception-v3 network
- SPG
接續在 Stem 特徵萃取後的 Model,
也是本文的重點架構。
SPG - A 分成 4 段 A1、A2、A3、A4
- O
SPG 的輸出,也是我們的 Output - Attention mask
- δ (Threshold)
要先定義好背景和前景的 threshold
當輸出的 Attention > δh 時為前景, Attention < δL 時為背景,
如果介於中間的話代表模糊地帶,就直接忽略。
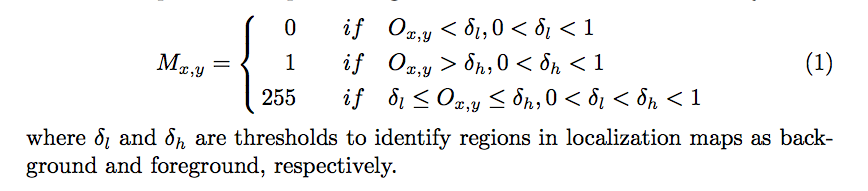 此處設定
此處設定B1 - δh = 0.5 δl = 0.05
B2 - δh = 0.7 δl = 0.1
Ablation study
使用SPG方法,是否有提升準確率
SPG-plain:Stem + SPG-A , 不包含本文的SPG招數,用於讓大家知道採用SPG方法會提升多少準確率。
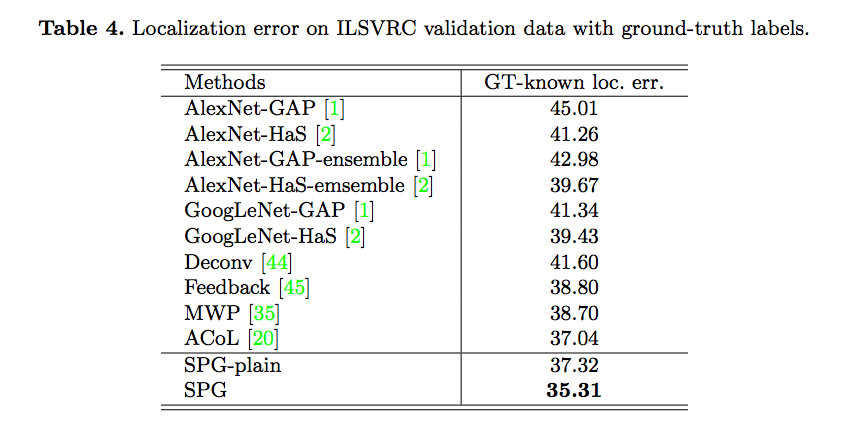
從上圖可知透過 SPG 方法真的有降低錯誤率。
透過循序學習下一級的 Mask 是否真的有帶來提升
這邊指的是流程部分的這幾步:
5.從 A4 得出的 Mask(經過Threshold) 與 A2(SPG-B2) 段所輸出的 Mask 做 BCE-Loss(只對前景和背景部分做,不確定的pixel就不會做BCE)
6.從 A2(SPG-B2) 得出的 Mask(經過Threshold) 與 A1(SPG-B1) 段所輸出的 Mask 做 BCE-Loss(只對前景和背景部分做,不確定的pixel就不會做BCE)
這樣做的錯誤率為35.31%
如果改為 SPG-B2和 SPG-B1 都使用最終的 Mask 做 BCE-loss 的話,
錯誤率反而提高為 35.58%。
其實是只差一點點。。。
此外發現 B1 以及 B2 中間那兩層做 Share weight 的話,會學得比較好,
如果沒有這樣做的話,
錯誤率會從 35.31% 提升至 36.31% 。
SPG-C Fuse mask 是否有效
如果移除 SPG-C 這部分的話,
錯誤率會從 35.31% 提升至 36.06% 。
實驗結果:
在 ILSVRC 以及 CUB-200-2011 Dataset 做測試。
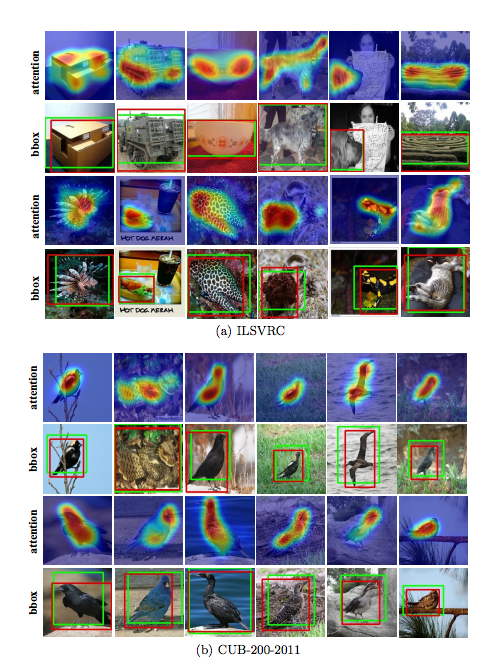
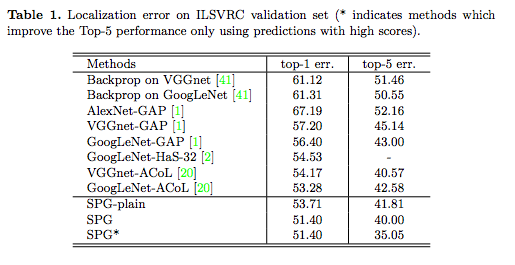
在 ILSVRC Dataset 上的定位成績
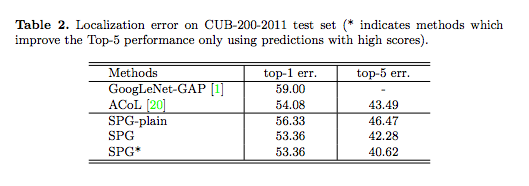
在 CUB-200-2011 Dataset 上的定位成績
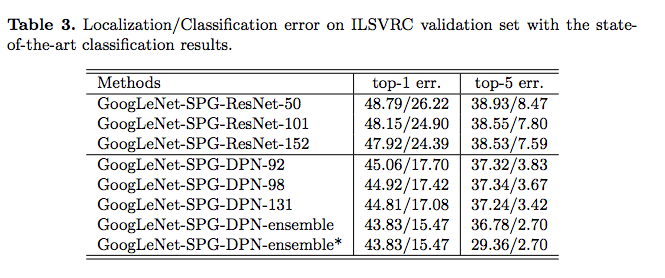
改測試不同的 Classification Model 是否對準確度有影響性。
結論:
提出 Self-produced Guidance (SPG) 方法來學習物件定位,
透過 Attention 方式讓模型可以聚焦到前景,
這樣就可以讓模型學會前景的 pixel 關聯性,
藉此提升物件定位的準確度。
並且只需要一張圖片搭配一個 label 就能達到這種準確率。
參考資料:
Paper:Self-produced Guidance for Weakly-supervised Object Localization