pix2pixHD簡介 - High-Resolution Image Synthesis and Semantic Manipulation with Conditional GANs
Ting-Chun Wang, Ming-Yu Liu, Jun-Yan Zhu, Andrew Tao, Jan Kautz, Bryan Catanzaro, “High-Resolution Image Synthesis and Semantic Manipulation with Conditional GANs”, arXiv:1711.11585
CVPR 2018 paper - Nvidia 團隊提出
Github Code(Pytorch):https://github.com/NVIDIA/pix2pixHD
主要model - https://github.com/NVIDIA/pix2pixHD/blob/master/models/pix2pixHD_model.py config1(base + generator) - https://github.com/NVIDIA/pix2pixHD/blob/master/options/base_options.py config2(training + discriminator) - https://github.com/NVIDIA/pix2pixHD/blob/master/options/train_options.py 上面三個連結搭配著看,應該就能夠理解整體架構了,整體模型較為複雜。
Demo video (建議觀看) : https://www.youtube.com/watch?v=3AIpPlzM_qs&feature=youtu.be
簡介
本篇論文在展示如何透過 Semantic segmentation 的 label 合成出高解析度的影像。


以往的方法使用 Semantic segmentation label 合成出的圖片有著解析度不高以及不夠真實的問題。
而本文除了解決上述的問題之外,還有幾個功能:
- 可將場景中的物品置換(如下圖,將樹木轉為建築物)
- 更換各個物件的外觀

pix2pix baseline
輸入一張圖片合成影像的任務,
最經典的就是 Github:pix2pix,
本文會和此方法做比較。
pix2pix 是輸出 256 X 256 的合成影像,
若使用 pix2pix 輸出高解析度(2048 X 1024)的影像時,
會發現輸出圖像的品質不好,並且在訓練時也不夠穩定。

改善解析度與圖片真實性
逐步的修正產生高解析度影像 - Coarse-to-fine generator
若直接訓練高解析度的方法的結果不好,
那我們就分為兩個步驟訓練
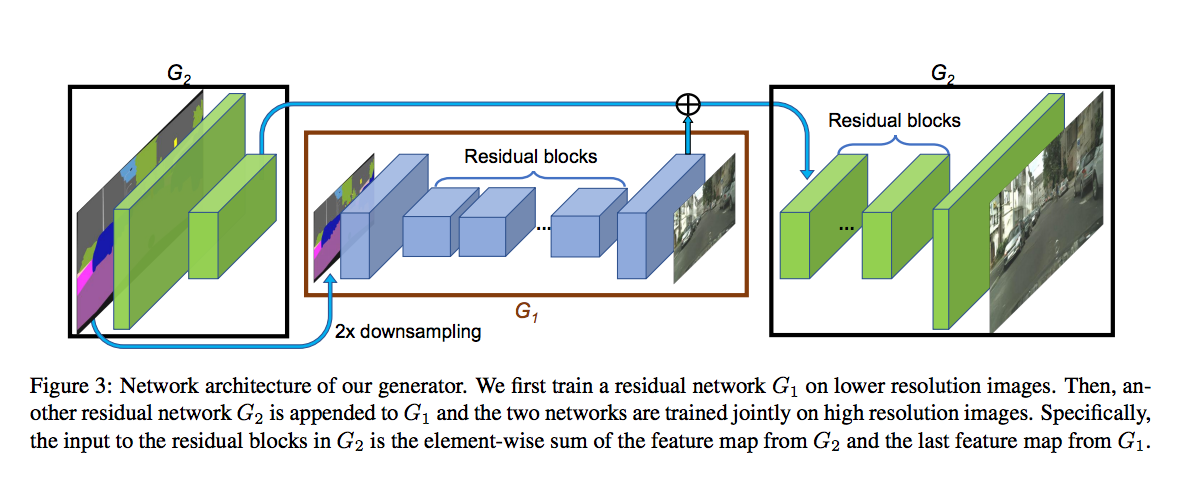
- G1 - 輸入 1024 X 512 的圖像做訓練 - global generator
- G2 - 輸入 2048 X 1024 的圖像做訓練 - local generator
實際上的架構圖如下
備註:
1.若要產生4096 X 2048 的話就再多接一個 local generator 就好了。
2.實際上在訓練會先訓練 global model, 之後再訓練 local model, 等兩個 model 都有一定的水準的時候再結合起來一起訓練。
Discriminator辨別高解析度影像的方法 - Multi-scale discriminators
當我們 Generator 產生出的影像為高解析度(2048 X 1024)時,
如果希望 Discriminator 能夠學得好的話,
需要很深的網路或是很大的 Conv kernal 才能夠處理這麼大張的影像,
而不管是哪個選項都需要相當龐大的記憶體。
因此這邊提出使用3個 Discriminator 來處理這個問題,
而這3個分別負責不同大小的影像做辨別。
- D1 辨別 2048 X 1024 的影像。
- D2 辨別 1024 X 512 的影像(由原影像做 downsample 而來)。
- D3 辨別 512 X 256 的影像(由原影像做 downsample 而來)。
雖然這3個 Discriminator 都擁有著相同的架構,
但作者的想法是 D1 可以看到整張影像, 雖然它能學到的較為粗淺, 但希望它能夠學習圖片整體的一致性。
而 D2, D3 因為影像尺寸有被縮小過了, 因此希望這兩個 Discriminator 可以用來確保細節的處理。
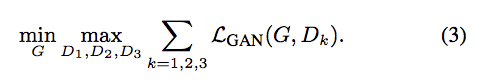
改進 adv loss - Feature matching
這邊提出對 Discriminator 中的每一層 layer 做 L1 loss,
為了確保 Discriminator 能對真實的圖片與合成的圖片學到相似的特徵分佈。
透過這方法,可以讓 Generator 在訓練的過程中更加穩定,
這個 loss 相似於 perceptual loss。
有用到類似技巧的 Paper :
C. Ledig, L. Theis, F. Huszar, J. Caballero, A. Cun- ´ ningham, A. Acosta, A. Aitken, A. Tejani, J. Totz, Z. Wang, et al. Photo-realistic single image superresolution using a generative adversarial network. In IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2017.
J. Johnson, A. Alahi, and L. Fei-Fei. Perceptual losses for real-time style transfer and super-resolution. In European Conference on Computer Vision (ECCV), 2016.
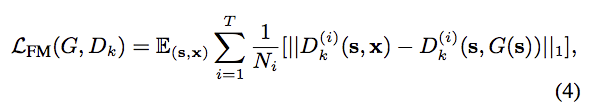
參數定義:
Dk => D1…D3 看有幾個 Discriminator
s => 輸入的 Semantic segmentation label
x => 輸入圖片(GT), 原本s對應之原圖
T => D 共有幾層 Layer
i => 第 i 個 Layer
N => 那層 Layer 有幾個特徵
因此最終的 Discriminator loss 為:
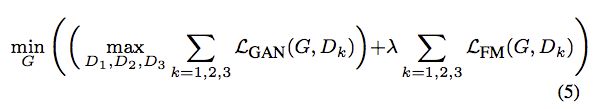
此處的 λ 在實驗中設定為 10
備註:
論文原文:This loss stabilizes the training as the generator has to produce natural statistics at multiple scales.
或許這是因為上面使用了3個不同的 Discriminator 才需要這招來穩定 Generator。
當 Discriminator 只使用一個時不確定效用如何。
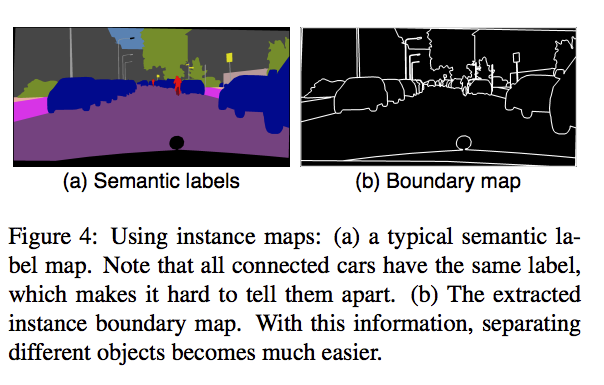
Instance Maps 作輔助(Cityscapes資料集有提供)
以往的影像合成方法都只透過 Semantic segmentation label 就生成影像,
可是單靠 Semantic segmentation label 能獲得的資訊有限,
因為我們無法知道每個物件的邊界處,
e.g. 如果一張影像有兩個人沒有什麼間隔站在一起,
這時候你從 Semantic segmentation label 中無法得知這件事,
看下圖會比較清楚。
下圖轉載自:https://engineering.matterport.com/splash-of-color-instance-segmentation-with-mask-r-cnn-and-tensorflow-7c761e238b46

而此處我們會透過上方圖片的 Instance Segmentation 作輔助,合成一張圖片。
當我們加入 Instance map 就能夠獲得物件的邊界,
藉此明白每個物件的位置。
而這在街景圖是相當的實用的,
因爲街景車與車或人與人之間的相連是非常常見的,
而在 Semantic segmentation label 又無法得知這個資訊。

因此有使用 Instance map 的輸入如下,
原有的 Channel 數 + 1(Boundary map) 做 concat 一起輸入
對每個物件做操作 - Learning an Instance-level Feature Embedding
在上面一段介紹到了使用 Instance map 當作 boundary 一起輸入,
但是這樣還是無法對每個生成的物件做改變。
而以往圖像合成常用 latent-code 來改變輸出,
但是 latent-code 的概念不適合應用在這個任務,
因為 latent-code 學到的是對整張圖片的顏色或是紋理做改變,
並不是基於每個物件去做改變。
因此為了達到對每個物件(Instance-level)做改變,
作者提出自行加入低維度的Features當作輸入來改變。
而實際做法是訓練一個 Encoder layer 來獲得 Feature maps,
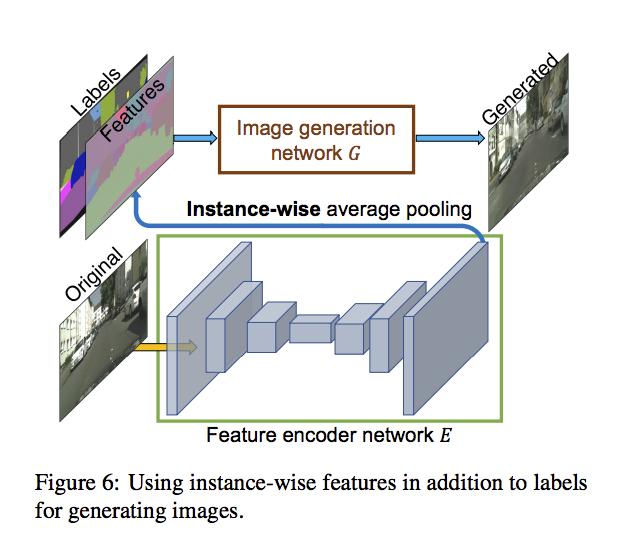
並且對每個物件的 pixel 位置做 average pooling 並且填回去原本的位置,
即為 Instance-wise average pooling,
做法看下圖:
- 藍色底是車子A所在的 pixel
- 綠色底是車子B所在的 pixel
- 粉色底是馬路所在的 pixel

透過這種方式我們就多了 Feature map 可以來控制每個物件的外觀等等。
而實際上使用是先訓練好這個 Feature encoder 之後,
然後將訓練的測資跑一次,
記錄下該類別的物件會出現什麼樣子的特徵值,
之後對該類別所有的特徵值做 K-means,
實驗設定 K : 10,
舉例:我們記錄所有車子出現的特徵值,分為 K 類,
此時 K 類中的每一類都代表著一個特別的 Style, 可能是 跑車/吉普車/計程車 等等的,
未來在輸出的時候, 就是依據各物件的類別 sample 出一個中心點的值當作特徵, 填補進 Feature map 中該物件的pixel位置。
最後再將 Feature map concat 進輸入,
因此最終的輸入為:
原有的 Channel 數 + 1(Boundary map)+ 3(Features : 實驗設定為3層) 一起輸入
透過上述的想法,我們就能對各個物件去做單獨的更改了(如替換顏色、材質等等,
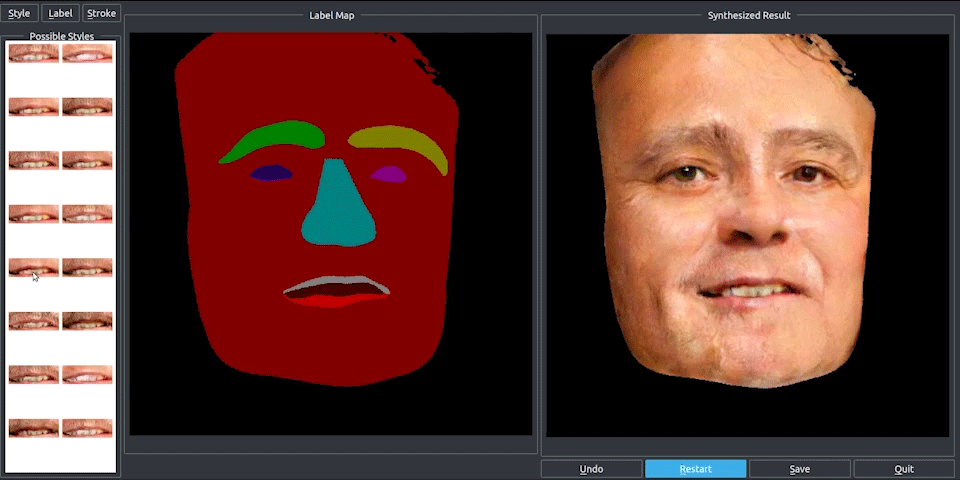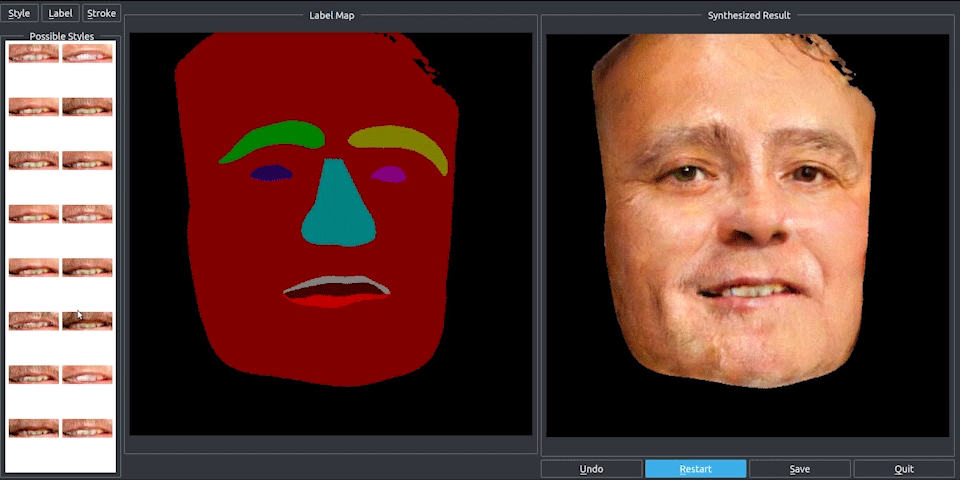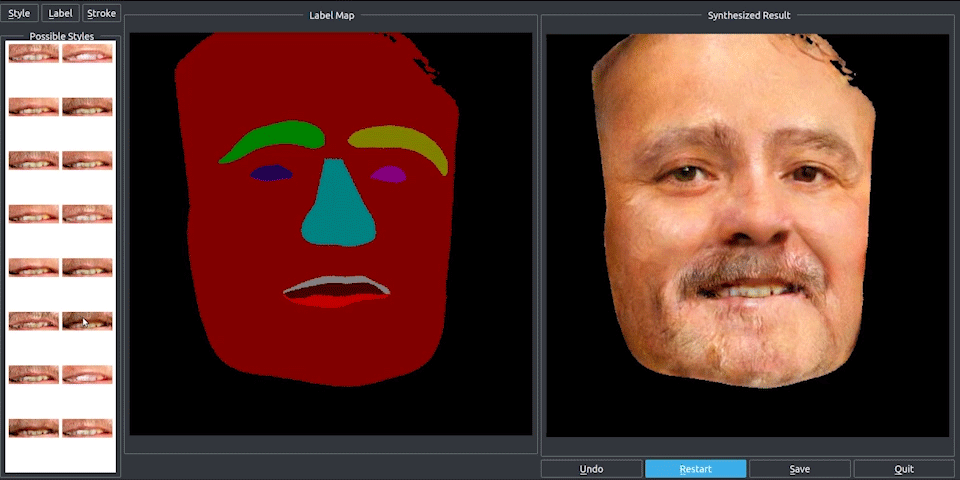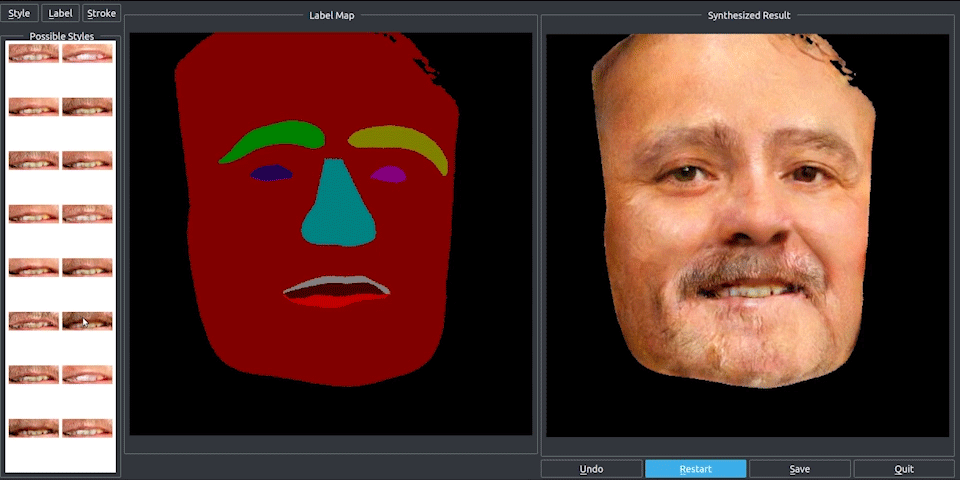
補充
實作是使用 LSGANs,
並且有嘗試使用 perceptual loss (輸入進 VGG-16 取得特徵值),
實際上有沒有用 perceptual loss 的結果沒什麼差別,
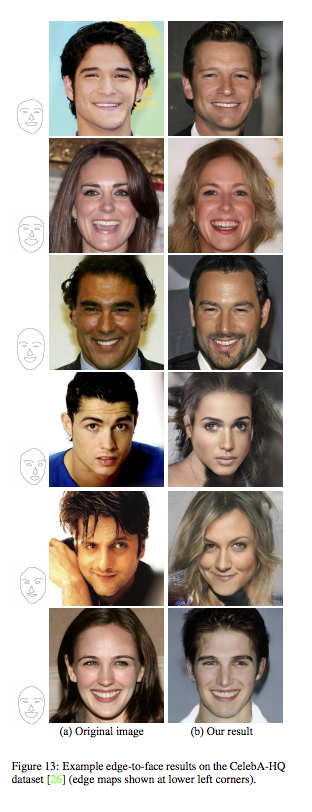
結果
這部分不詳細介紹,
有興趣的自己去看論文,
論文中有許多 User study 的結果。




參考資料:
arXiv:High-Resolution Image Synthesis and Semantic Manipulation with Conditional GANs