Look into Person簡介 - Look into Person Self-supervised Structure-sensitive Learning and A New Benchmark for Human Parsing
Ke Gong, Xiaodan Liang, Dongyu Zhang, Xiaohui Shen, Liang Lin, “Look into Person: Self-supervised Structure-sensitive Learning and A New Benchmark for Human Parsing”, arXiv:1703.05446
CVPR 2017 paper
Github Code(Caffe):https://github.com/Engineering-Course/LIP_SSL
LIP dataset : http://www.sysu-hcp.net/lip

簡介
提出一個大型的人體架構(Human parsing)資料集 - Look into Person (LIP) 以及提出人體架構分割的模型。
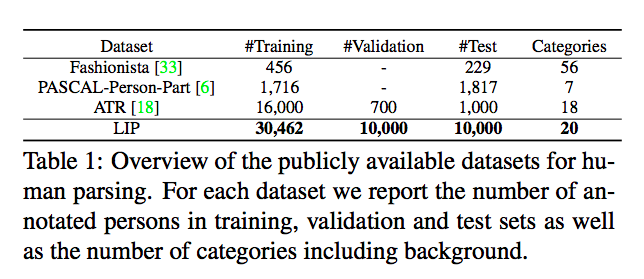
資料集包含 50,462 張圖片,
共有 20 個 Label (19個 + 1個背景),
和當時既有的人體資料集相比,
此資料集的圖片數量是相當驚人的。
而第二個貢獻人體架構分割,
它主要的想法是要解決架構上的誤判,
如左手接到右手臂等等的問題,
下圖的(b)有著右手掌接到左手臂的問題,
而此論文提出的模型(c)則可以解決此種問題。

而解決這個問題所提出的 Model 稱之為 Self-supervised Structure-sensitive Loss(SSL),
透過 SSL 的方法希望對於人體的架構有著更好的理解,
避免出現上面那種不合邏輯的預測。
資料庫細節
此 Dataset 是從 Microsoft COCO 的資料集中提取人物的部分組成的,
並且將那些圖片定義20個Label(包含背景), 為他們標註每個 pixel 是屬於哪個 label。
也因為是從 Microsoft COCO 資料集中提取的,
因此是包含不同背景以及有著許多不同姿勢的資料集。
並且對圖片有做統計,
備註:Occlusion 有人將它稱作遮擋,這部分有錯的話請指正。
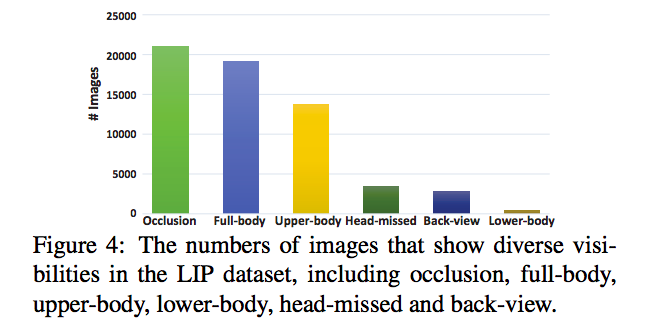
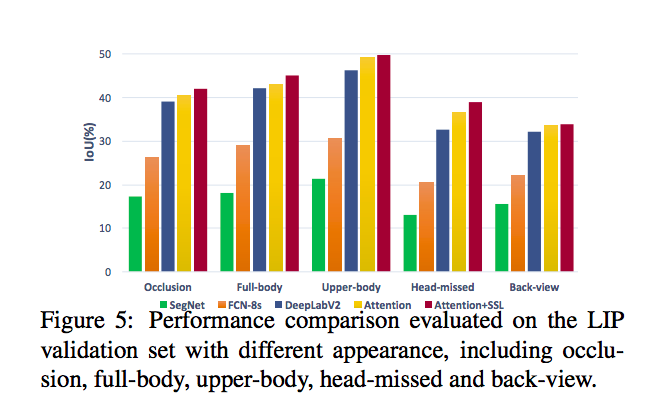
在研究中有發現使用以往的模型在只有人物背面(Back-View)或是人物的頭部消失(Head-missed)的這兩種情況下,
準確度會有明顯下降的問題,
可看下圖,展示在什麼情況下準確度會偏低。
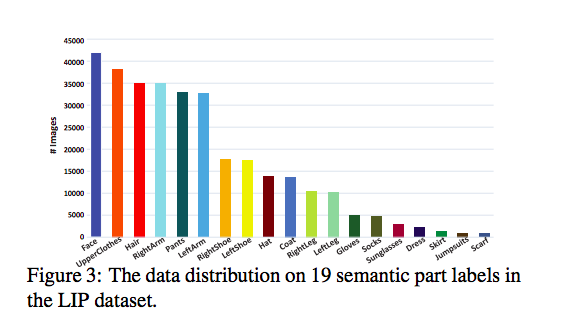
除此之外因為此資料集還有將衣服、鞋子等等的物品當做一個類別,
因此在處理這些小尺寸的類別時,要能夠準確預測這些物品也是相對困難的。
下圖有做類別數量的統計。
除了上述資料集的敘述之外,
他們發現現存的人體架構資料集並沒有提供一個伺服器讓人上傳 secret testing dataset 的結果,
因此此資料集有開設一個網站,讓人提交結果至網站上,
此 secret testing dataset 的 Ground truth 是不公開的,
因此大家能夠透過這個平台來公平的測量自己的模型準確度如何,
以及可以知道自己的模型是否有過擬合(over-fitting)的問題。
方法 - Self-supervised Structure-sensitive Loss(SSL)
此模型是基於既有的 Semantic segmentation model 做改進,
主要是基於 DeepLabv2 以及 Attention 的 model 增加 Self-supervised Structure-sensitive Loss(SSL)。
以往的模型只透過預測出來的結果, 對 GT 做 Segmentation loss。

但此篇論文提出,應該要對人體架構去做探討,
避免不會有一開始的右手掌接到左手臂上面去的問題,
因此架構圖如下,
主要想法就是透過各個部位的關節點去添加一個 Loss function -> Joint structure loss。
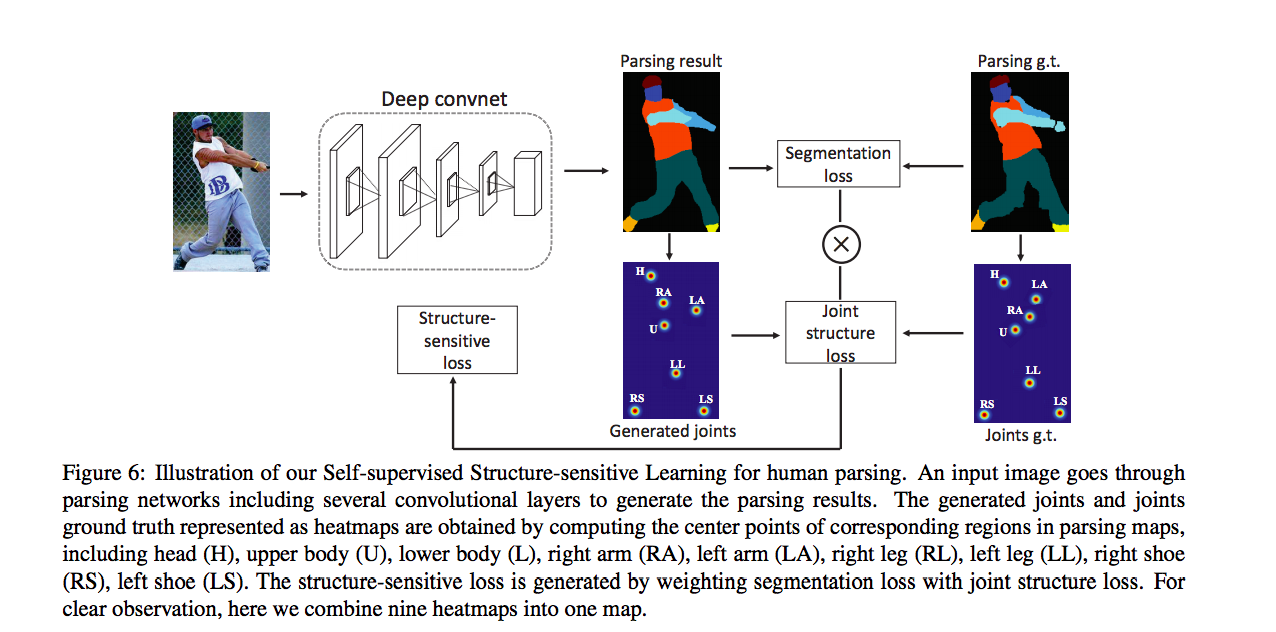
定義 9 個關節點為頭、上身、下身、左手、右手等等。。。
而實際上得到關節點的方法是透過各個類別的組成,
舉例來說頭的關節點位置是由帽子、頭髮、太陽眼鏡、臉組成後的中心點(C),
因此會有 9 個中心點 (C1…C9),
備註:
實際上使用是採用 Attention map 的形式,
這部分從論文上看,我個人是認為寫的不夠詳細。
並沒有詳細說明 C 的求法, 上面的 Generated joints 的圖片與我的想像不太一樣,
因為如果是密集的點的話, 那為什麼要用 Attention map, 而不用單一個 point 座標去做計算。
論文上還有提到當關節點不存在於一張圖像時, 其關節點的 Attention map 全部會補0,
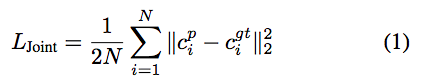
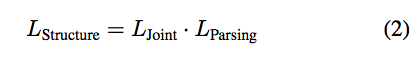
LParsing 指的是預測出來的 Segmentation 對 GT 做 pixel-wise softmax loss,
這邊和以往 Segmentation model 做的 loss function 一樣, 因此不贅述。
而上面幾個公式很直覺的理解就是,當架構(L-joint)與 GT 相差很多的時候 loss function 就會變大,
透過這種方式來達成對人體的架構做學習的想法 => Structure-sensitive Model。

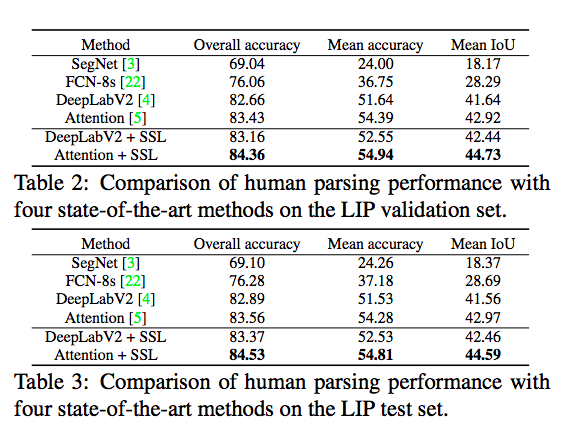
成果圖

