淘寶網的人物提取論文簡介 - Semantic Human Matting
Quan Chen, Tiezheng Ge, Yanyu Xu, Zhiqiang Zhang, Xinxin Yang, Kun Gai, “Semantic Human Matting”, arXiv:1809.01354
ACM 2018 paper - 阿里巴巴(Alibaba)團隊提出
Github Code(Pytorch):沒找到,在Github:Alibaba上也沒看到。
Dataset:沒找到。
如果有人有找的話可以在下方留言,我會再更新此帖。
簡介
本篇論文在展示如何從一張圖片中提取出該圖片上的人物,
以往此技術需要透過使用者輔助才能夠提取出高品質的人物圖像,
但是此篇僅需輸入一張圖片,即可將人物中從圖片提取,不需使用者輔助。
而此技術是非常實用的,
以淘寶網(Taobao)來說,
他們會希望藉由此技術可以快速的將人物提取出並合成到不同的背景上,
以達成對每個使用者的精準行銷, 可見下圖。
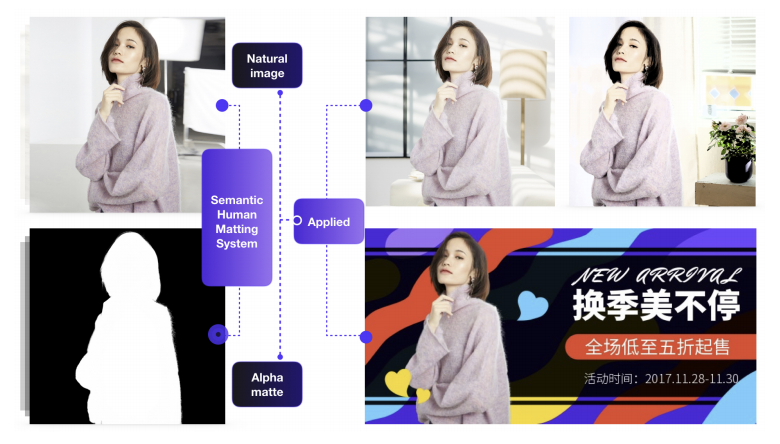
可以想見的是當我們要賣一件衣服時,
我們可以將穿著該衣服的模特兒透過這技術快速的套用至不同圖片(如全場最低價、今日限定五折等等,
藉此就可以減輕設計師的負擔,並且透過這手段可以進行更多的行銷手法。
而此篇就是提出 Semantic Human Matting (SHM) 的技術來達成這件事,
核心想法是我們很難訓練好一個模型可以處理好語意分割(將人物提取)的部分又可以精確的將細節處理好,
既然一個模型難以達成,那就試試看透過兩個模型合作,各自負責不同的事情。
先透過一個 Semantic segmentation model 將前後景以及不確定的部分提取出來,
再透過另一個 Encoder-decoder Model 將不確定的部分做細節的調整,
最終就可得出高品質的人物圖像。
此篇的貢獻
提出 Semantic Human Matting (SHM) 的模型,並且達到目前最新的準確率。
提出一個有效協調兩個模型的方式,透過此方式可將Semantic segmentation model 和 Encoder-decoder Model 做協調, 讓兩個 Model 可一起訓練得出更高品質的圖片。
提出大型的 Human Matting (這邊我不確定怎麼翻譯,我就姑且稱之為人物提取)資料集。
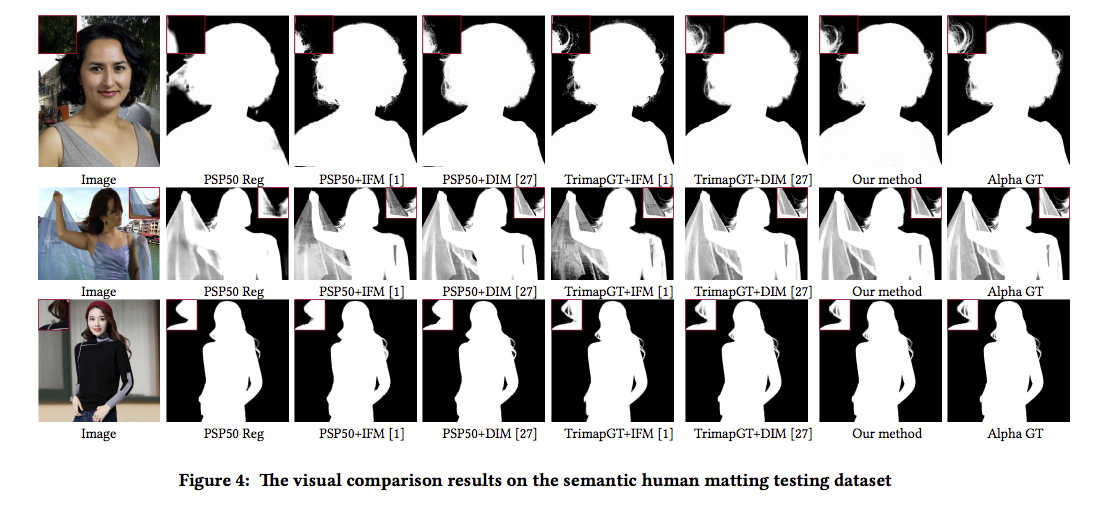
先看一下這任務困難的點在哪,
這任務困難得地方在於有的pixel是無法明確定義他是前景或是背景,
稱之為 alpha matte,在頭髮或是第三欄的芭蕾舞裙的裙擺,都能看出有這個跡象。
而我們的模型不僅要能夠處理 alpha matte 的部分,
也要能夠精確的提取出整個人物,包含使用的配件如:手機、包包等等。

Human matting - 人物提取資料庫
先來看看以往的人臉提取資料庫以及此文提出的比較
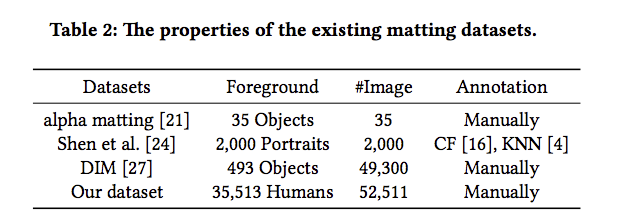
- alpha matting 的資料庫樣本過少,對於深度學習來說首要條件就是資料樣本要多
- Shen et al. 此資料庫是透過 CF 以及 KNN 的方式所製造的, 因此有可能該資料庫有bias,不採用。(這部分可搜尋幾個關鍵字: deep learning dataset bias)。
- DIM 的資料庫雖然有 493 個物件, 但是物件中包含人物的只有 202 個。
- Our dataset 從電子商務網站中搜集圖片,將35,513個人物透過人工標注他的Annotation,此資料集有遵循DIM的方法收集。
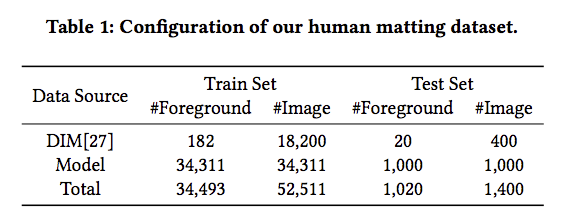
- Our dataset 是將 DIM的資料集與剛剛提到的 35,513 個圖片彙整成一個資料集,由上述提取的人物與收集的背景合成為一張圖。
備註:背景部分是由 MS COCO 資料集以及網路中提取,這也確保了此資料集有著更廣泛的多樣性。
方法
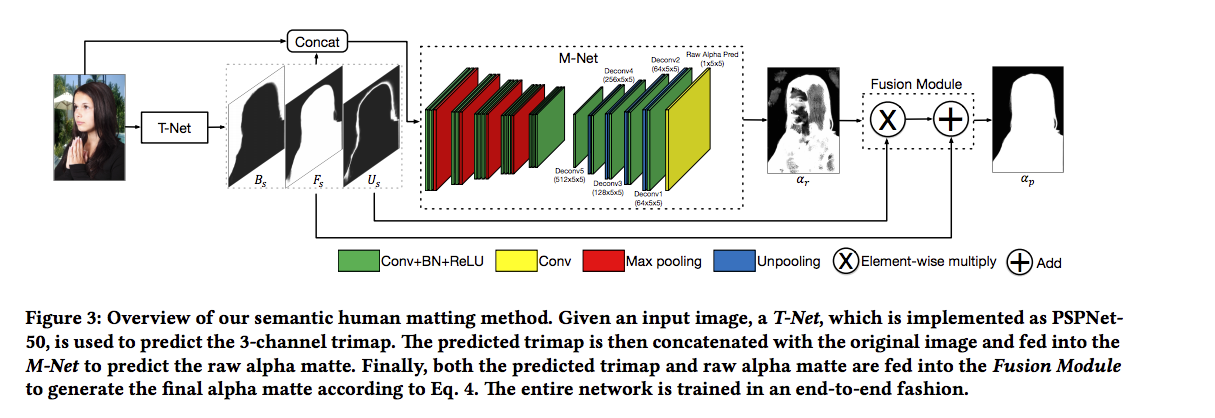
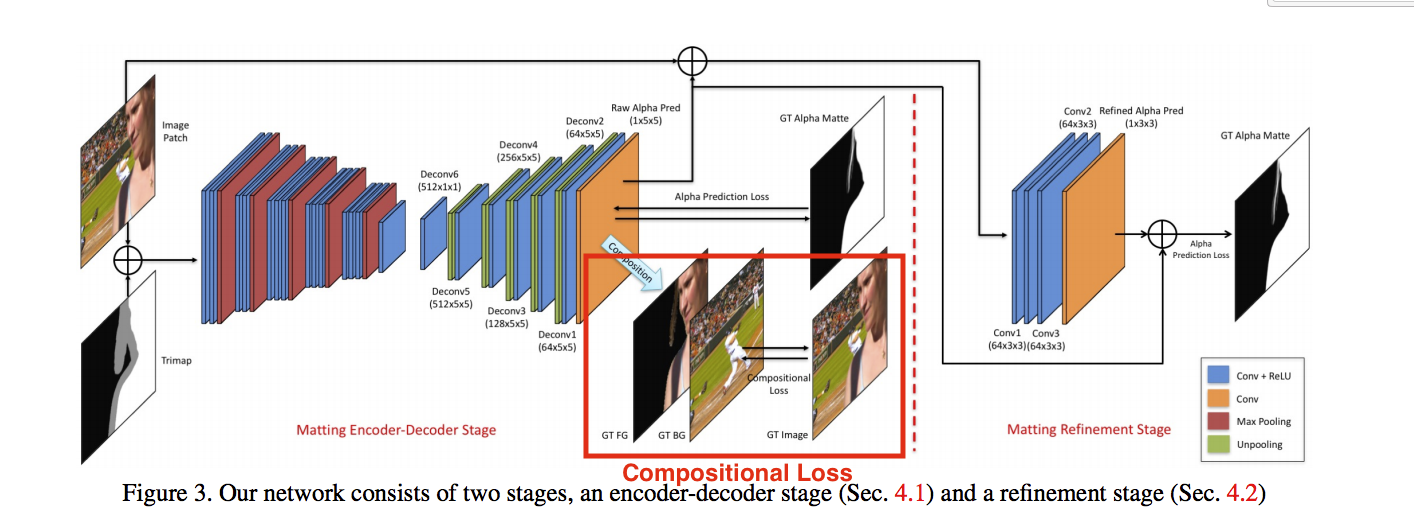
此部分的概念為:
我們會先透過 T-Net 得出前景(Fs)、背景(Bs)、不確定的部分(Us),
再將圖片(3 channel)與我們剛剛得出的 3個(前景、背景、不確定的部分)共計6個 channel 一起輸入進 M-Net,
做一個較為精確的調整,
此處的用意是將不確定的部分可以處理的更完善,
可以看到 Fusion Module 的 X 法部分,
將 Us(不確定的部分,多為人物邊緣處) X M-Net 的 Output 可以獲得更加精準的人物邊緣
最終再與 T-Net 所預測出的前景圖片結合,即為最終的結果。

T-Net
此處的概念是使用 Segmentation model 可以先將圖片區分為前景、背景、不確定的部分,
透過此 T-Net 我們能夠知道圖片的哪些部分是人物,
剩餘未知的部分,因為圖片區塊比較少,我們可以透過下一個 M-Net 來做精準的預測。
這邊採用的是 PSPNet-50 的 Segmentation model, 但是理論上來說換成其他的也沒關係。
M-Net
此處使用 Deep convolutional encoder-decoder network,
用於細節處的偵測,如頭髮。
此處是輸入6個 Channel(原始圖片RGB + T-Net的輸出),
而作者也有嘗試使用4個Channel作為輸入,
將T-Net的輸出從3個改為1個(value 0=背景 0.5=未知 1=前景),
其實不管是4個或是6個Channel的準確度都差不多,
這邊作者還是採用6個Channel。
而此部分的架構主要為VGG16,
比較不同的地方是輸入的部分從3個 Channel 改為 6個 Channel,
以及加入 BN 在每個 Conv layer之後加速收斂,
其他還有一些細節就不贅述,有興趣的翻論文。
Fusion Module
將 T-Net 的輸出做 Probability map, 公式如下。
Fs(前景) + Bs(背景) + Us(未知) = 1
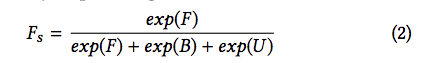
整個模型的公式可以寫成
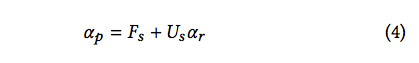
Loss Function
對整個模型做 alpha prediction loss 以及 compositional loss。
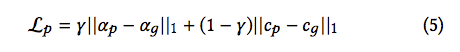
備註:此處γ = 0.5
alpha prediction loss: 對我們最終輸出 αp(即為人物的Mask)做 loss。
compositional loss: 我對這部分的理解較為模糊,覺得應該是對於最終的合成圖(提取出的人物結合背景)對背景做loss function(( 此部分有錯請指正
參考了一下 引用論文的 compositional loss 的定義,
Deep Image Matting - CVPR 2017
arxiv link: https://arxiv.org/pdf/1703.03872.pdf
他這邊是指對 Foreground 做 RGB 的 loss
原文:which is the absolute difference between the ground truth RGB colors and the predicted RGB colors composited by the ground truth foreground, the ground truth background and the predicted alpha mattes
引用論文的架構圖
以及為了讓 T-Net 的分類可以更加準確, 有對 T-Net 的前景背景分類添加 cross entropy loss。
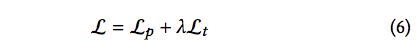
備註:此處λ = 0.01
實驗
使用Pytorch的框架實作(不過論文當中沒給出源碼的網址)
實際上在訓練的時候,先獨自訓練 T-Net 再獨自訓練 M-Net,
等兩個模型都穩定後,最終再結合起來一起訓練。
此部分有做data augument的動作與一些 Pretrained 的細節,
詳情請看論文。
下表述說的是以往的方法都需要使用者協助標注出大致的位置,才能夠精準的將人物從圖片中提取,
而現在是採用 T-Net(PSP50) 提供出大致的位置,然後使用各個方法評估分數。
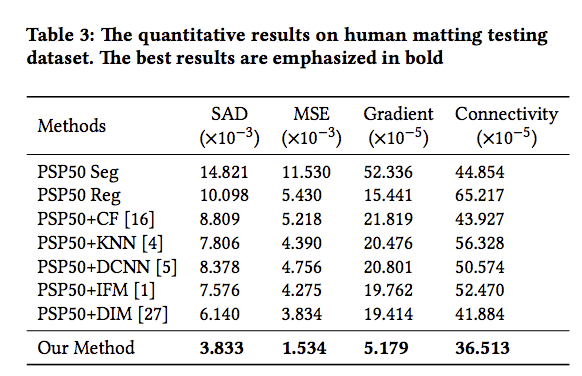
而使用 PSP50 或許不能夠提供模型最精準的位置,
所以下表示述說使用 GT 去提供位置給各個方法,
然後再與此論文方法比較( 備註:此論文是採用全自動化,不需使用這標註,因此Our method的部分是(PSP50 + M-Net 並非 TrimapGT + M-Net)
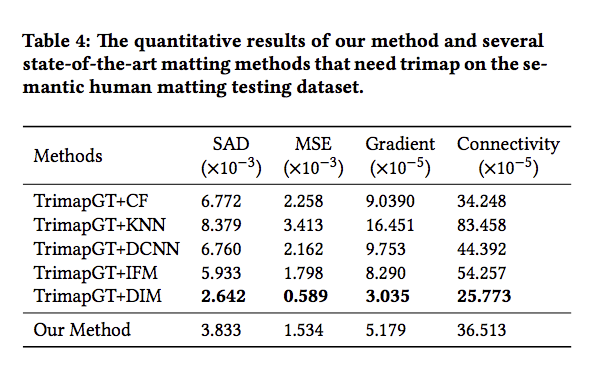
儘管此方法輸 TrimapGT+DIM,但是此方法是採用全自動的分割,並不像 TrimapGT+DIM 需要使用者協助提供位置。
下表展示每個方法的 ablation study
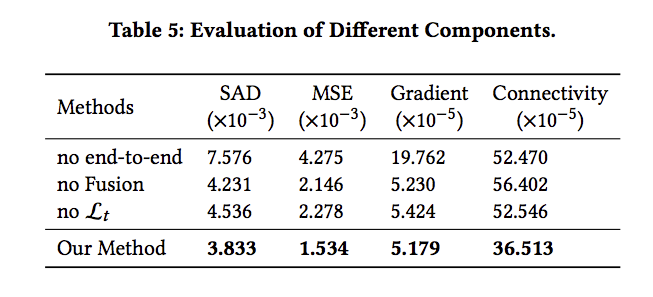
結果