CBST簡介 - Unsupervised Domain Adaptation for Semantic Segmentation via Class-Balanced Self-Training
Yang Zou, Zhiding Yu, B.V.K. Vijaya Kumar, Jinsong Wangl; “Unsupervised Domain Adaptation for Semantic Segmentation via Class-Balanced Self-Training”; The European Conference on Computer Vision (ECCV), 2018, pp. 289-305
ECCV 2018 paper
Github code:https://github.com/yzou2/cbst
簡介
此文主要是解決語意分割(Semantic segmentation) 中的 Domain adaptation(DA) 問題,
往往只使用資料集訓練出的模型應用到真實世界時準確度都會下降,
而 DA 就是為了處理這個問題,是近年來很火紅的領域。
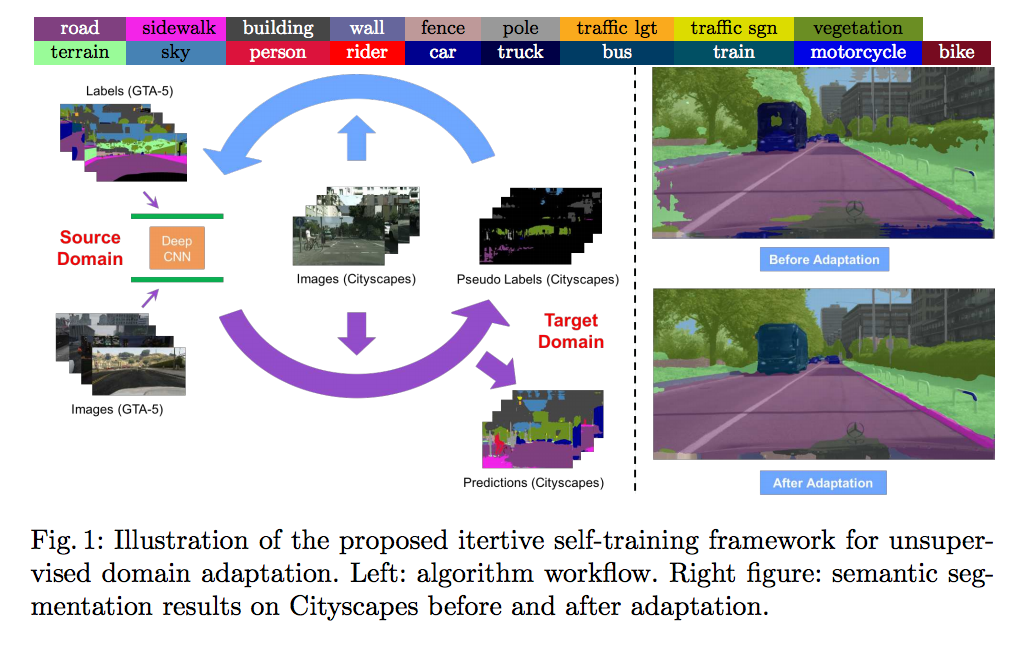
此論文提出了自我訓練(Self-Training)的方法來提升準確度,
因為真實世界的圖片往往沒有標註(Ground-Truth labels),
而它的概念是透過正在訓練的模型預測出一個解答(Pseudo labels),
儘管他不會是百分之百正確的,
但是我們可以只提取信心程度高的部分做訓練,
透做這種方式逐步的訓練就能夠獲得一個較好的模型,
上述的方法稱之為逐步自我訓練(iterative self-training (ST))。
但是只使用上面方式是不夠的。
近年對城市場景(Cityscenes)的資料集進行 Semantic segmentation Domain adaptation 的實驗時,
會發現道路、天空的準確度是相對高的,
那其他的準確度都偏低,

若是只採用信心程度高的話,
那麼常常都只訓練到道路和天空而已,
為了解決這問題我們必須考量到有些類別(如:巴士、火車、腳踏車等等。。。
較為冷門的類別也要受到訓練,
因此基於上述的 ST 方法再添加平衡類別(class-balanced)的方法,
而此方法稱作 class-balanced self-training (CBST),
此篇主要是在闡述此兩種方法,
並且在CBST的方法中,
提出增加空間上的資訊(Spatial priors)達到更高的準確度。
此篇的貢獻
提出 self-training (ST) with self-paced 的 DA 架構
解決類別不平衡的問題 class imbalance problem, 稱作 class-balanced self-training (CBST)
基於 CBST 架構,搭配空間資訊(Spatial priors)提高準確度, 稱作class-balanced self-training with spatial priors (CBST-SP)
在城市道路資料集 SYNTHIA/GTA 適應至真實世界(Real world) - Cityscapes 的圖片,有著目前此領域前沿的準確率,除此之外 Cityscapes 的資料集適應至 NTHU 的資料集也有著很好的準確率。
基礎概念
本文是要處理 DA 的問題,
因此我們需要考慮 2 個不同資料集,
通常是分為 Source / Target Domain。
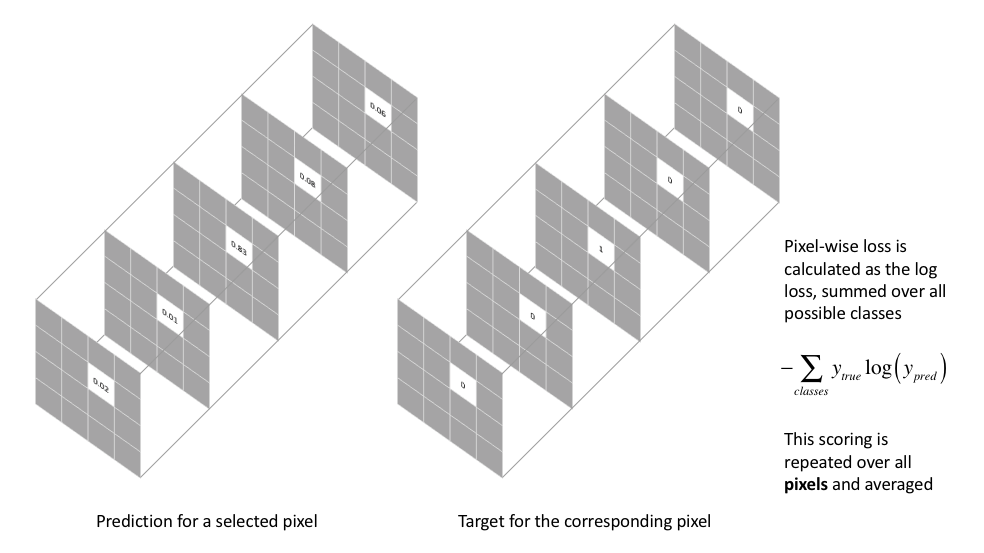
基礎的 Semantic Segmentation 損失函數(loss function)如下
下圖轉載自 - Jeremy Jordan:An overview of semantic image segmentation.,
但當我們要考慮兩個不同的場域(Domain => Source/Target)時,
我們的損失函數定義如下
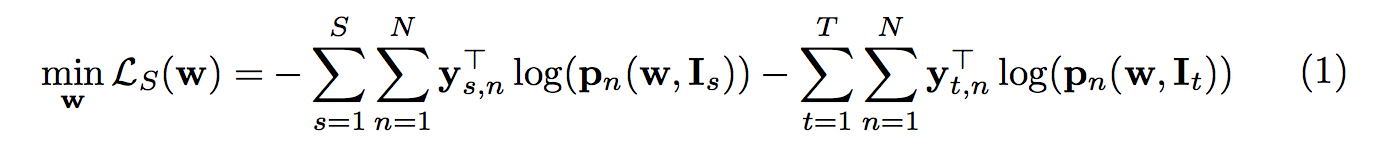
參數定義:
S:source domain
T:target domain
N:一張圖片的pixel數量(H X W), n-th(第1,2,…,N個位置的pixel)
pn(w, I):輸入一張圖片,預測出的output - 有經過softmax,即為包含每個類別的機率,假設預測19個類別的話,輸出為(N, 19)。
w:網路的權重
可是對於 DA 的問題來說,
我們是沒有 target domain 的 ground truth(GT) 的 labels,
但是我們可以用現有的模型(p)預測出 target domain 的 semantic segmentation 結果,
稱之為 Pseudo-labels(yˆ )
因此我們的損失函數定義為下面這樣,
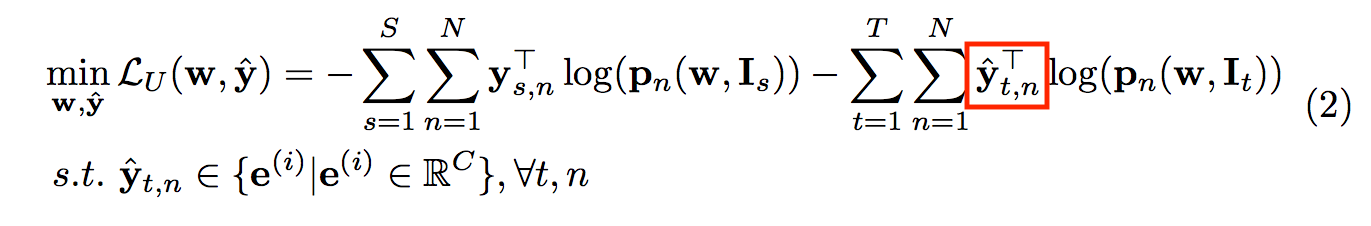
參數定義:
yˆ : Pseudo-labels 經由p模型預測出的label
C: 類別數目(類別可能有:馬路、人行道、人、車子等等。。。)
e: One-hot vector
方法
Self-training (ST) with self-paced learning
主要是基於上方的想法,
我們會利用 pseudo-labels(yˆ ) 來輔助學習,
但是畢竟是使用模型預測出的 pseudo-labels(yˆ ) 並不能保證完全正確,
因此提出從簡單到難(easy-to-hard)的學習策略,
實際做法是選擇預測分數高的 pixels 做訓練,
若是預測模型輸出後還不能肯定的 pixels 就先不使用 cross entropy loss 訓練。
舉例來說:我們道路往往能學得不錯,所以預測出的分數也高,所以我們一開始先學道路,
那巴士、火車這種較為困難的任務,就等它的類別預測出的分數夠高我們再開始學習。
下圖轉載自Jeremy Jordan:An overview of semantic image segmentation.,
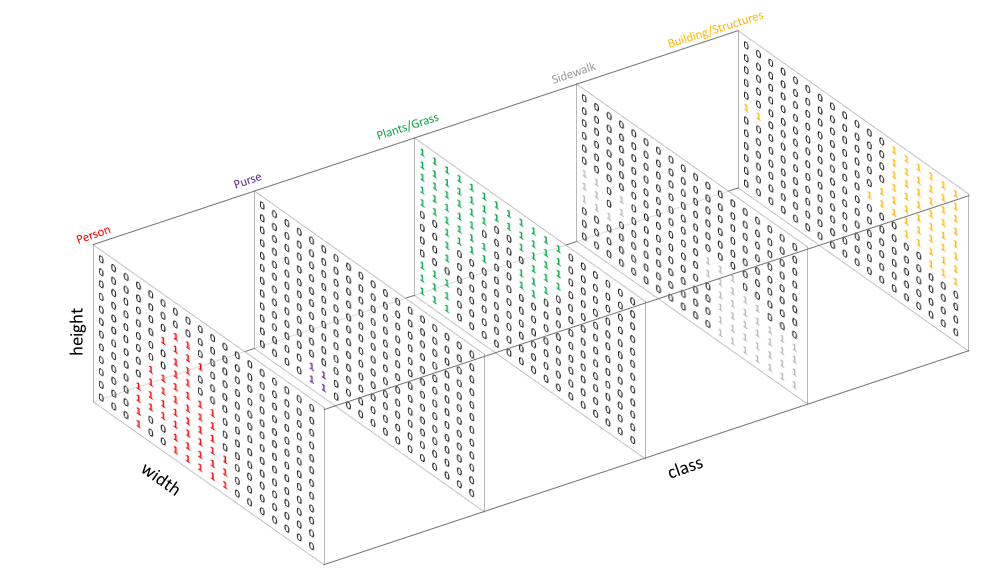
原本 segmentation 的 one-hot encoding 至少會有一個維度為 1,
那我們會定義好當每個類別的分數都沒有過一個信心門檻(k)的時候,就算是困難測資,
這種時候該 pixel 的 one-hot encoding 的類別都被我們設定為 0,
在進行 loss function 時就會忽略該 pixel 不進行學習。
式子如下:
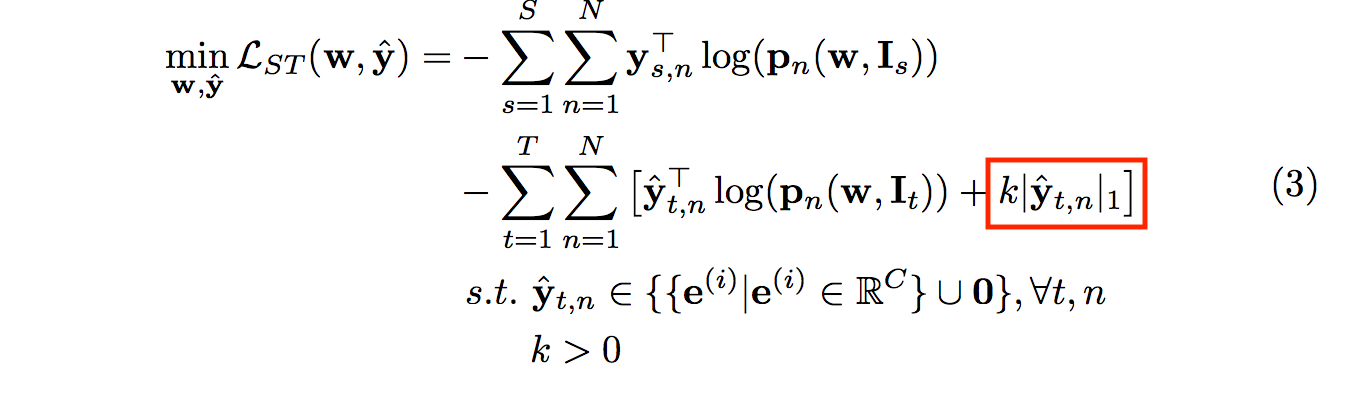
而紅框的部分是要讓模型去學習困難的測資,
假如使用原本 eq2 的公式當作loss function的話,
此時如果 pseudo-labels(yˆ ) 都為0,
那式子會變成這樣:
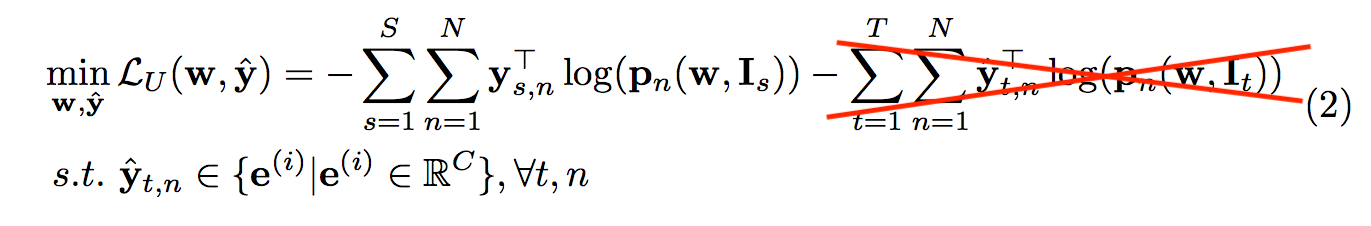
為了避免出現上面的狀況,
才會使用紅框的部分來讓懲罰當有pixel輸出類別為0的狀態,
透過這種想法,該模型就會盡量去學習,而不是在那邊偷懶都輸出為0。
使用這方法訓練流程為
- a) 基於目前 p 模型的 w 權重,讓 yˆ 可調整來 minimize loss eq(3)
下方公式的概念為當有一個類別的輸出機率超過我們的信心門檻 k 的時候,
代表為 easy 的 case,我們可以肯定他就是那個類別, 將他帶入loss function學習。
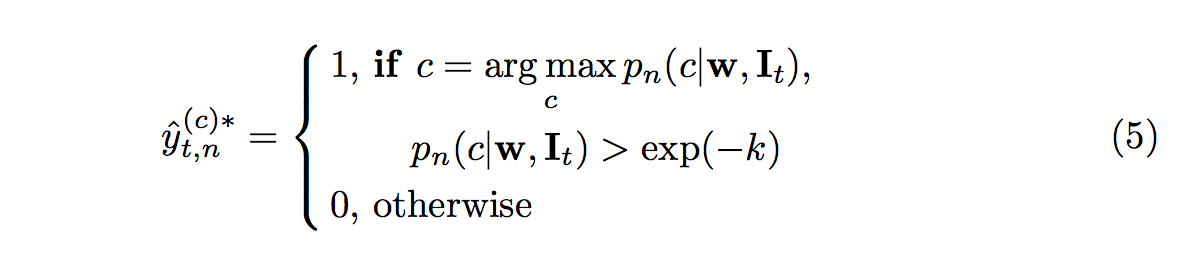
此時下方公式的 yt 可能是 one-hot vectors 或者是全為 0 的 vectors,
而透過下方這公式我們希望可以 minimize yˆ
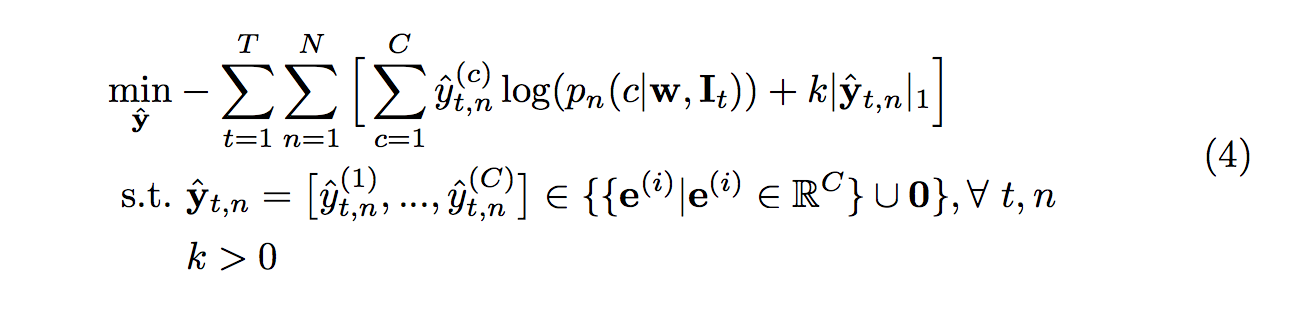
- b) 固定yˆ 調整 w 權重來 minimize loss eq(3)
上面 a, b 兩個步驟稱作一輪(round),
而實際上一次訓練會重複好幾輪,
重複好幾輪就是 self-training 的 easy to hard 概念,
每一輪會透過調整信心指數 k 的門檻,
讓整個模型可以從信心指數高的地方開始學習,
備註:k => 會在後方 Self-paced learning policy design 做詳細的介紹。
Class-balanced self-training (CBST)
如果僅僅靠著上方的 Self-training 的方式,
其實在實務面來說還是有點問題的,
舉例:常出現的類別:如道路,
它的輸出的信心能達到很高如 70~80 %,
但是火車、巴士這種可能只能到 10~20%,
因為本身就很難學習(火車 巴士 貨車 轎車等等。。。)都會被互相混淆。
因此單純定義一個信心指數會造成少數類別可能永遠沒辦法學習到,
為了解決這個問題才提出 CBST 的方法,
而想法很簡單,就是對每個class的信心指數應該要個別處理。
將原本信心指數 k -> kc(基於每個類別的 k )
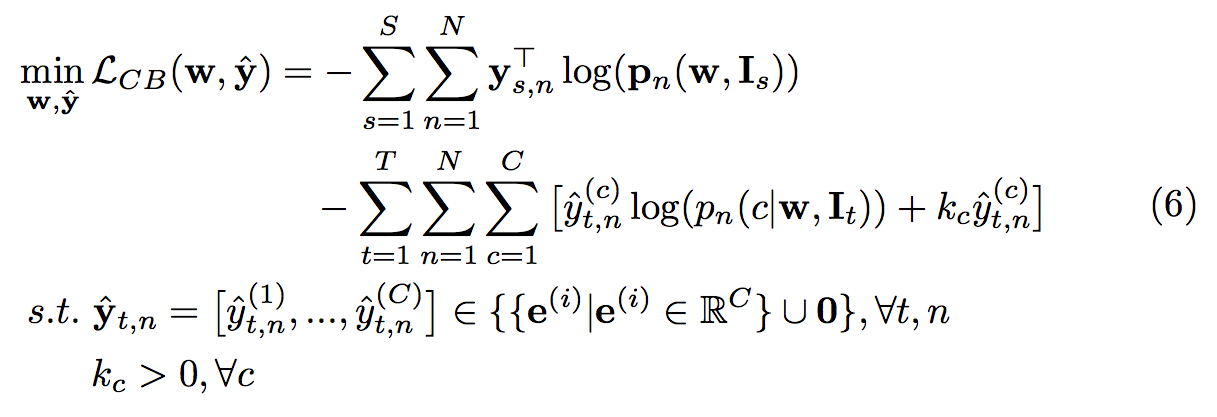
透過下方這公式我們希望可以 minimize yˆ
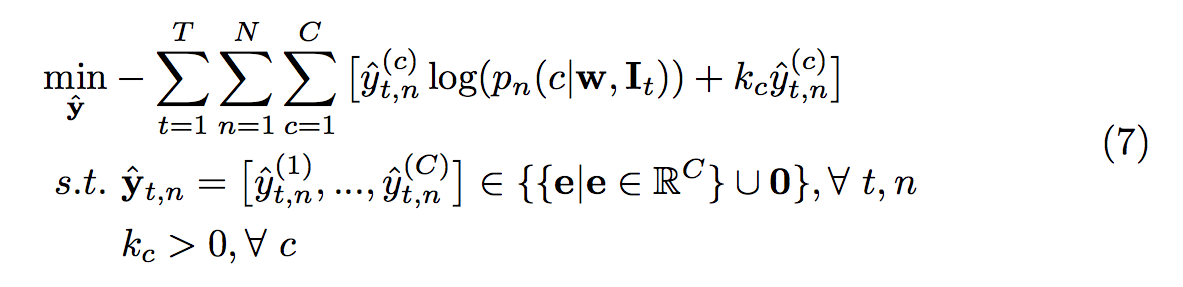
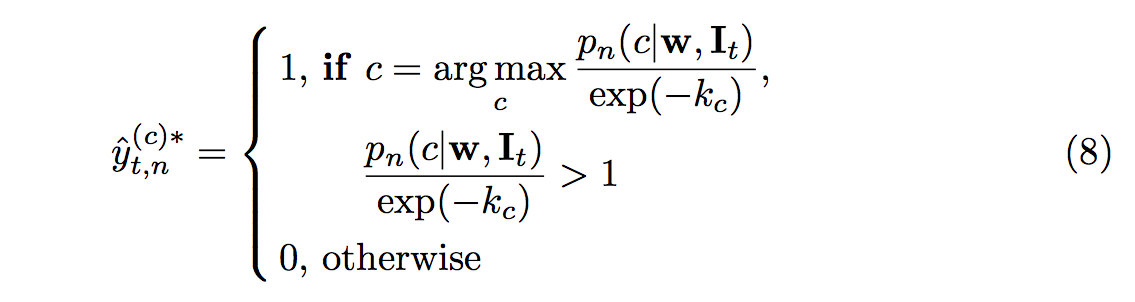
透過上式即可讓每個類別的權重獲得較平均的分配,
即為少出現的類別即使信心機率相對低的時候,
也有可能當作 yˆ 進行訓練。
Self-paced learning policy design
此處是希望能夠有個較好的方式可以去定義信心門檻 k,
先來介紹在 ST 的方法如何定義 k,
首先我們會給定 Target domain 的圖片(line 1),
使用模型 P 預測出每個 pixel 屬於每個類別的機率(line 2),
提取出每個 pixel 最有可能的類別之“機率” (可能該pixel 道路類別:0.9, 人行道:0.1 此時我們會提取 0.9 )(line 3)
將整張圖所有 pixels(共有 N 個值, N = H X W) 各自的最高機率收集到一個陣列 (line 4),
將所有機率排序,由高到低(line 6),
我們希望提取出前 p% 的人作為標準(line 7),(舉例來說 班上100人,我希望挑選前20%的人, 因此我們會以第20名的分數作為標竿)
將第 p% 的人的分數作為標準, 把它當作信心水準k (line 8)

備註: p 在實驗中的設定是 20%開始 ~ 50% , 每經過一輪 + 5%
而 CBST 定義 k 的方式也差不多, 但是他是對每個類別的機率個字排序
要知道目前預測出最有可能的類別為何, 假設為車 (line 3),
因為我們預測為車,代表車的預測分數最高,所以採用 max 得出來的機率是從車子類別出來的 (line 3),
如果預測出的是車子類別,那就將該機率丟入車子類別的機率陣列(line 5~8)
提取出各自類別的信心門檻 kc (line 10~14)

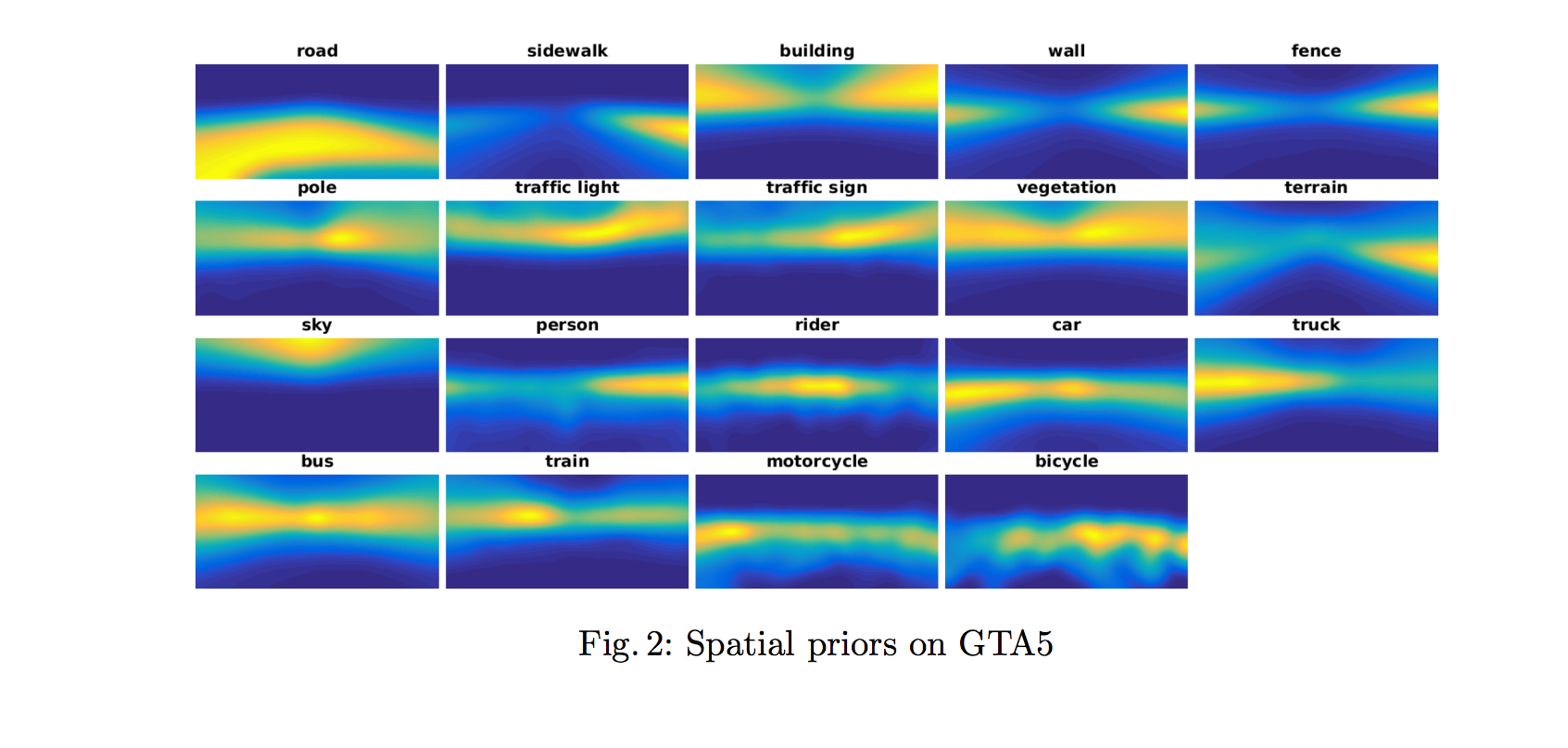
結合空間資訊 - Incorporating spatial priors
當兩個資料集相似時,如都為街景的資料集,
那麼他們的圖片可能有相同的架構,
如車子跟道路會在中間以及下半部,
天空都會在上半部。
透過這種觀念來輔助模型可以明白每個類別比較有可能在哪些位置出現。
黃色為出現機率高的pixel,藍色為出現機率低的pixel,
而這個統計是從 source domain 的 GT 統計而來。
而搭配空間資訊的公式如下,多了 qn 的參數
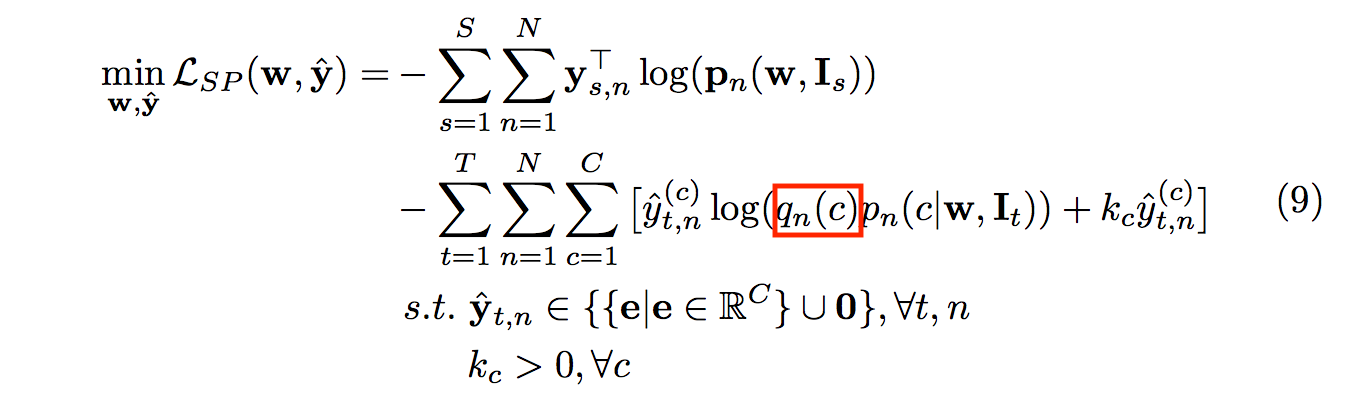
備註:之所以 road 的右下角為藍色的是因為 GTA5 的資料集右下角都為車子(GT 標為 255 即為忽視這個部分,因此 car 類別的右下角也沒有東西)。
下圖轉載自 Playing for Data: Ground Truth from Computer Games

實驗設定
使用 FCN8s-VGG16 當作 base network,
之後發現採用 ResNet-38 的 Semantic segmentation[39] 架構較佳。
[39] - Wu, Z., Shen, C., Hengel, A.v.d.: Wider or deeper: Revisiting the resnet model for visual recognition. arXiv preprint arXiv:1611.10080 (2016)
而實驗設定有一段,我對這部分有點不清楚他的意思,
原文:we use a hard sample mining strategy which mines the least prediction classes according to target prediction portions. The mining classes are the worst 5 classes and top priority are given to classes whose portions are smaller than 0.1%.
但我對上述意思的猜想是:希望針對 Target domain 最少出現的 5 個類別去多做學習,可能該類別在資料集中出現的較少導致訓練不好,透過這種方法多看少樣本的類別。(大概的猜想,有錯請指正)
結果
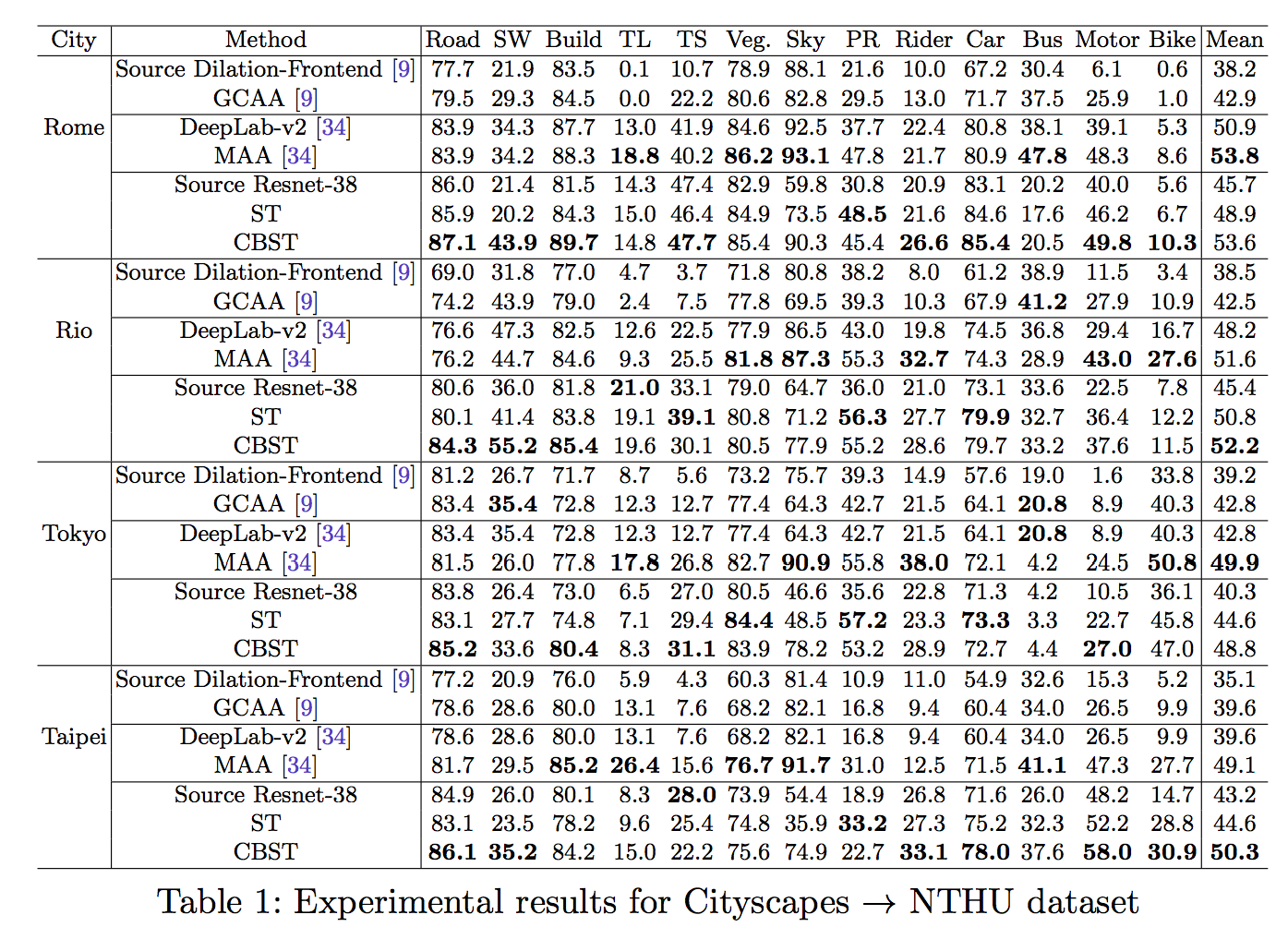
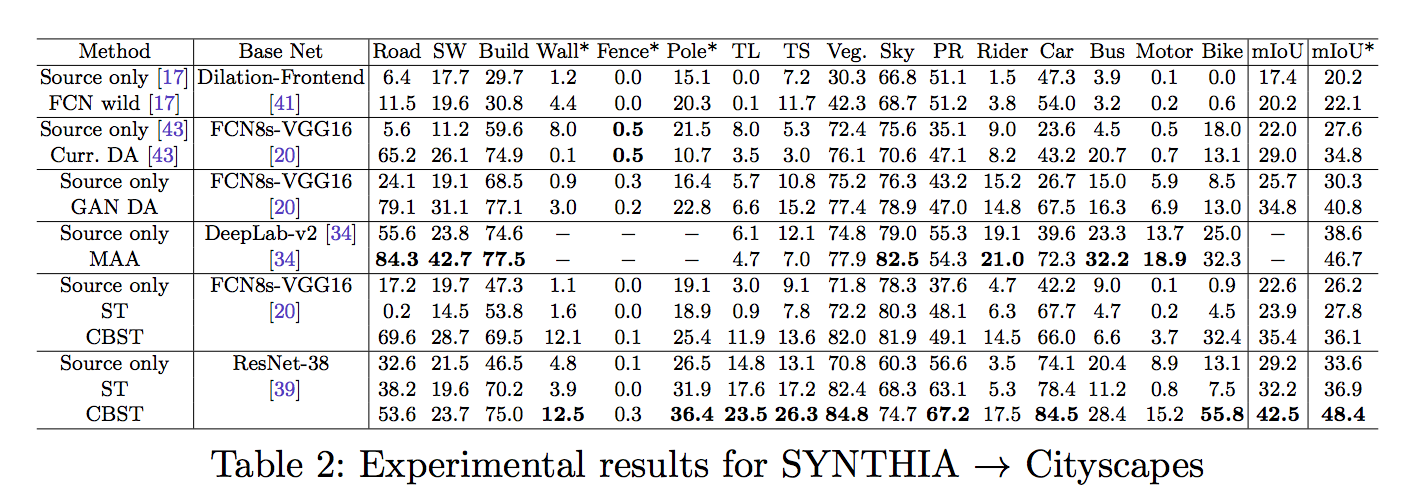
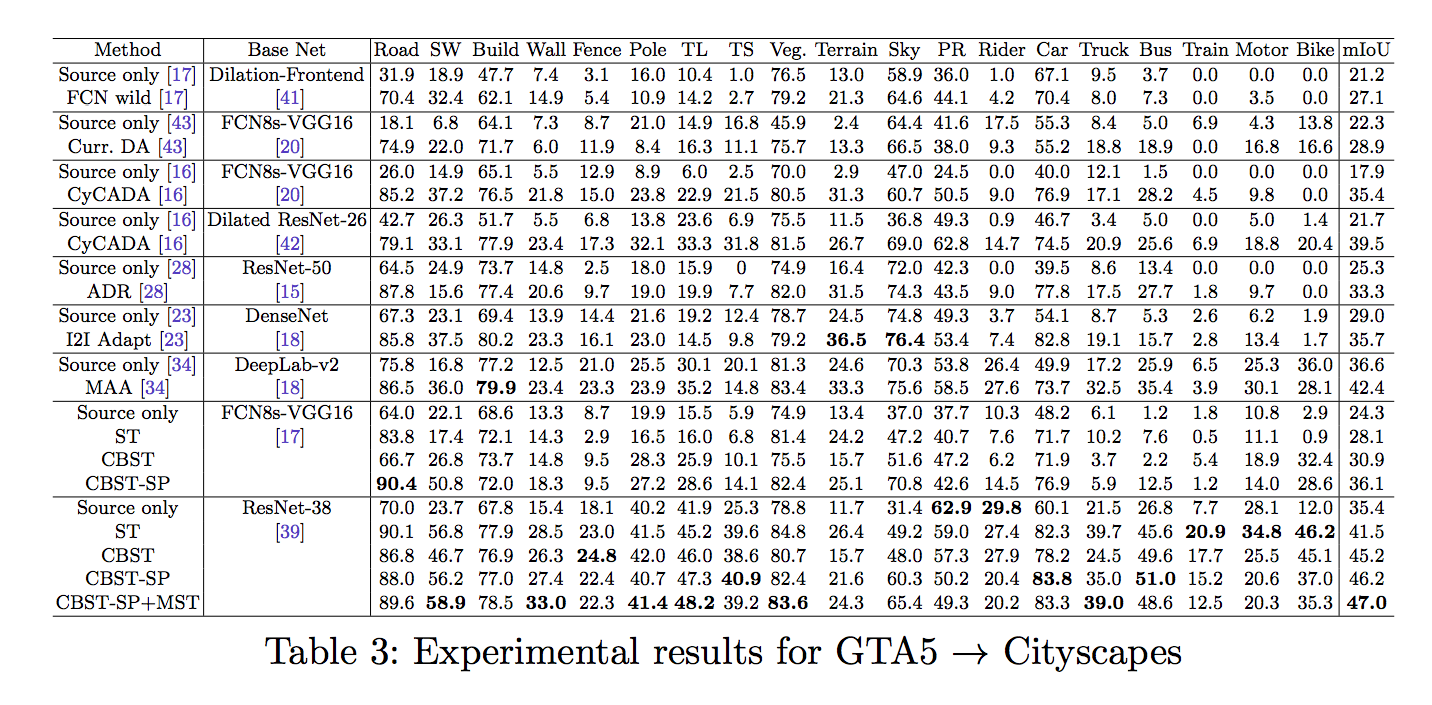
備註:
Table 3 的 MAA[34] 方式, 之前有寫過簡介, 有興趣的可以去看看AdaptSegNet簡介
[34] - Tsai, Y.H., Hung, W.C., Schulter, S., Sohn, K., Yang, M.H., Chandraker, M.: Learning to adapt structured output space for semantic segmentation. arXiv preprint arXiv:1802.10349 (2018)

參考資料:
[34] - Tsai, Y.H., Hung, W.C., Schulter, S., Sohn, K., Yang, M.H., Chandraker, M.: Learning to adapt structured output space for semantic segmentation. arXiv preprint arXiv:1802.10349 (2018)
[39] - Wu, Z., Shen, C., Hengel, A.v.d.: Wider or deeper: Revisiting the resnet model for visual recognition. arXiv preprint arXiv:1611.10080 (2016)
Unsupervised Domain Adaptation for Semantic Segmentation via Class-Balanced Self-Training