Partial Convolution 圖像修復任務PConv簡介 - Image Inpainting for Irregular Holes Using Partial Convolutions
Guilin Liu, Fitsum A. Reda, Kevin J. Shih, Ting-Chun Wang, Andrew Tao, Bryan Catanzaro; “Image Inpainting for Irregular Holes Using Partial Convolutions”; The European Conference on Computer Vision (ECCV), 2018.
ECCV 2018 paper, Nvidia團隊提出
Github code(Pytorch)非官方實作 : https://github.com/naoto0804/pytorch-inpainting-with-partial-conv
Demo video : https://www.youtube.com/watch?v=gg0F5JjKmhA

簡介
以往使用深度學習進行圖像修復的任務,通常會採用 Convolution network,
但以往使用 Convolution network 的方式修補圖片後,看起來都有點不自然(顏色差異 or 模糊),

因為這種方式會將正常的 pixels 與空洞的 pixels 都視為同樣的方式去處理,
而此文提出 Partial convolutions,
它的作用就是讓 CNN 在傳遞時有個 Mask (區分空洞與否)作輔助,
如果我們能夠讓 CNN 有 Mask 作為輔助,
知道此 pixel 是正常或不正常的話,
就能進行更為精準的修改,
此篇貢獻
- 提出 Partial convolutions(PConv) 以及一個自動傳導 mask 的機制,透過此機制讓 PConv 可以讓下一層知道哪邊還需要進行修復,並透過此方法達成目前技術前沿。
- 使用 U-Net 進行圖像修復,將 Conv 改為 PConv 可達到更好的準確度
- 以往的圖像修復往往都是處理長方形的缺口,而此篇是第一個展示修復不規則缺口的圖像修復任務。
- 提出一個不規則 mask 的資料集,並且公開出來讓大家可以評估圖像修復任務。
Standard convolution
這邊只是複習一下,簡單帶過。
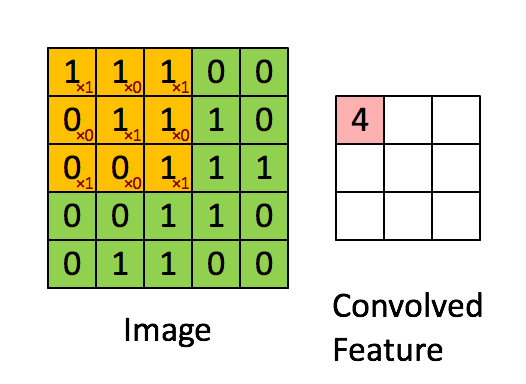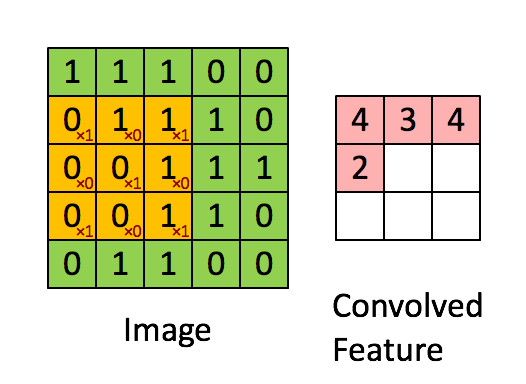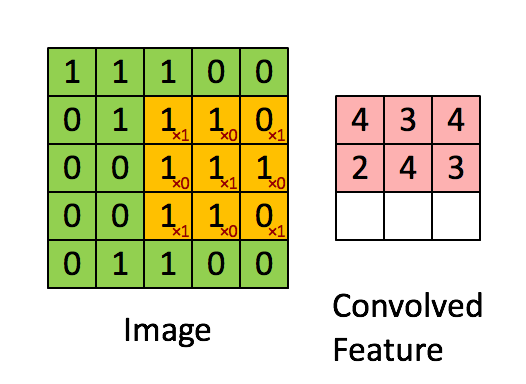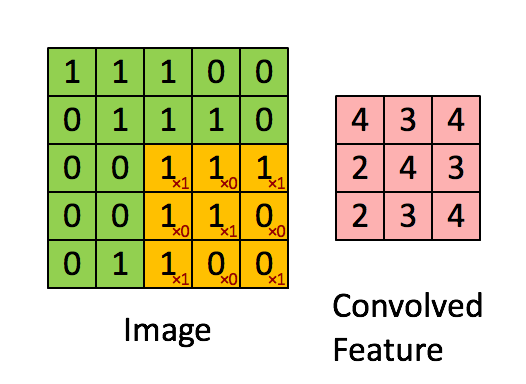
黃色的部份我們稱做 Kernel ,
此處的 Kernel(黃色)為 3X3 的大小。
那應用到圖像修補的任務,可以想像幾個場景,當目前 kernel 掃到的位置上,其3X3所看到的
- 都是需要填補的pixel。
- 都是不需填補的pixel。
- 有需要填補以及不需填補的pixel。
Partial convolution
Partial convolution 的概念其實是一般的 CNN 搭配上 Mask 的概念,
Mask 代表著一張圖哪邊是需要修補的空洞(1為不需要修補,0為空洞)
可使用 3X3 的 kernel 想像下方公式,會更有畫面,
再更下方有舉例。
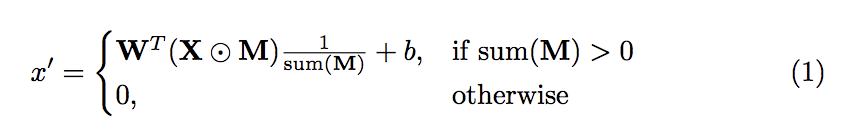
m’ 為下一層 layer 的 mask
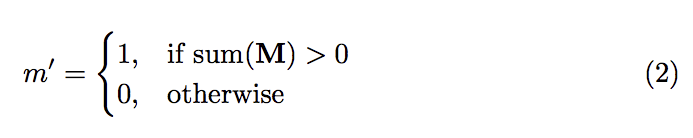
參數定義
W : convolution filter weights
X : 當前 pixel/feature 的值
⊙ : element-wise 乘法
M : binary mask (0 或 1)
b : bias
當我們搭配下方這個 Mask 時, PConv的概念如下
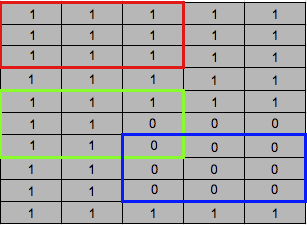
- 紅框
此時 Kernal 內的 Mask value 都為 1(都為正確的pixel不需填補),
那他會執行 eq1 的 if sum(M) > 0 的式子。
概念為 : 此處並非空洞,可使用一般的 Convolution 正常處理。
- 綠框
雖然 Kernal 右下角的 Mask value 右下角為 0(代表空洞),
但是我們可以透過附近的 1 即爲正常的 pixel 學到點東西,
可能是顏色、紋理。
- 藍框
此時 Kernal 內的 Mask value 全為 0(都為空缺需填補的pixel),
那我們就先不處理,
等傳遞到後面的 Layer 有較多的資訊時再做修補。
而透過 PConv 的架構,只要有 Valid 搭配 Hole 的時候(上圖綠框),
傳遞到下一層時Mask會逐漸從 0 填補為 1(因eq2上半部的式子 if sum(M) > 0),
透過這種方式到最後能夠得到全為 1 的 Mask,
而 Mask 全為1所代表的意思為整張圖片已修補完成,沒有0(空洞)了。
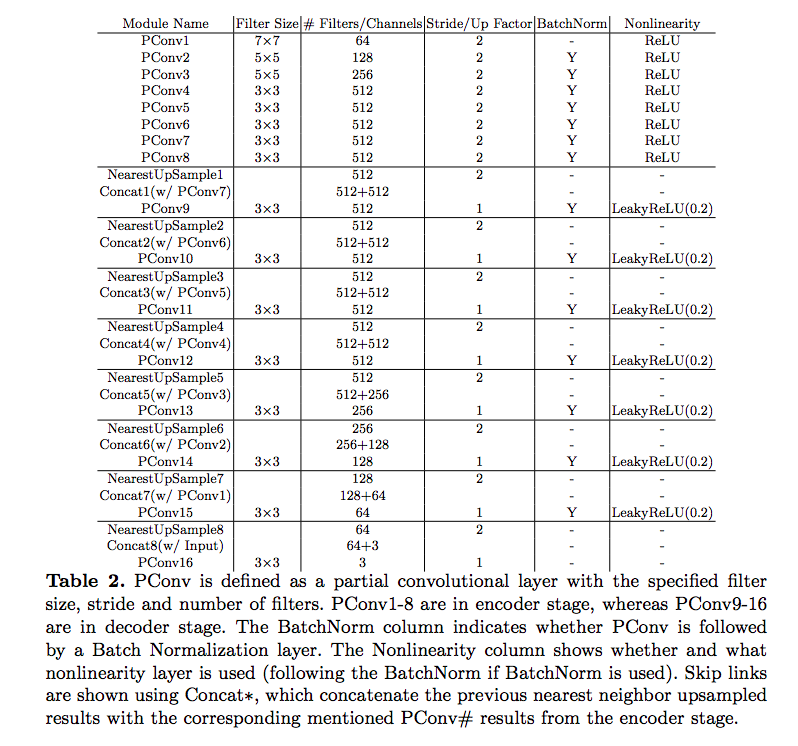
網路架構
透過 Pytorch 實作,
將 512 X 512 的圖片運行在 NVIDIA V100 GPU 上僅需 0.23秒,
輸入應該為 RGB(3 dims) 加上 Mask(3 dims),可參考下面連結
http://masc.cs.gmu.edu/wiki/partialconv
他在上帖有提到 Note: M has same channel, height and width with feature/image. M is multi-channel, not single-channel.
架構如下圖:
Loss function
Pixel loss
M (0 為空洞 / 1 為正常)
Iout - 模型輸出的結果
Igt - Ground Truth
Perceptual loss
使用 VGG16 得到一張圖片的特徵向量,
Icomp - 空洞內為Iout的輸出,其他地方給原始圖片的影像。
Icomp概念:來確認空洞中的影像與正解的影像做結合後,是否會有看起來有不一致的感覺。
nth: 此設定為3,表示pool1, pool2 以及 pool3 的輸出。
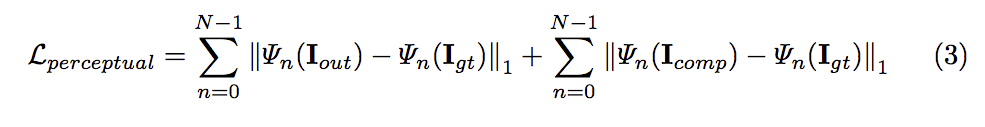
Style Reconstruction loss
Kn : 此部分的定義可自行看論文,並且比對下方 Reference {1} 的Style Reconstruction loss。
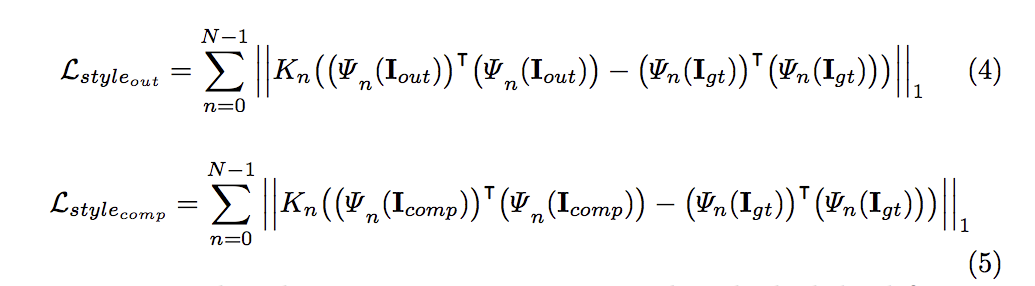
可參考下方幾篇論文去研讀這部分的 loss
{1} Johnson, J., Alahi, A., Fei-Fei, L.: Perceptual losses for real-time style transfer and super-resolution. In: European Conference on Computer Vision, Springer (2016) 694–711
Gatys, L.A., Ecker, A.S., Bethge, M.: Texture synthesis using convolutional neural networks. In: Advances in Neural Information Processing Systems 28. (May 2015)
Gatys, L.A., Ecker, A.S., Bethge, M.: A neural algorithm of artistic style. arXiv preprint arXiv:1508.06576 (2015)
Total variation loss
用來確保周遭pixel是否平滑化
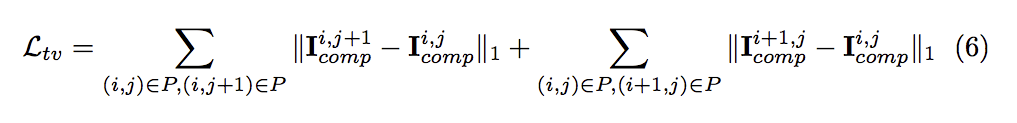
最終的 loss function 如下 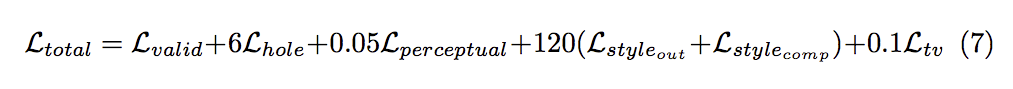
探討幾個 Loss function - Removing Checkerboard Artifacts and Fish Scale
TV loss :
VGG loss 會產生一個棋盤效應(Checkerboard Artifacts),而 {1} 這篇論文透過採用 TV loss 去降低這個影響,
不過這篇論文的方法,並沒有明顯發現這問題。
Style loss:

實驗設定
Irregular Mask Dataset
採用下方 Reference {2} 的方式來創建 Mask,
簡而言之是透個影片 2 個連續的 Frame 提取 mask,
此部分我沒細讀。
最終創建 55,116 個 Training mask / 24,866 個 Testing mask
所有圖片以及mask的大小都為 512 X 512,
並且將 Mask 再細分圖像的缺口比例,並且分成有邊界以及沒邊界的資料集。
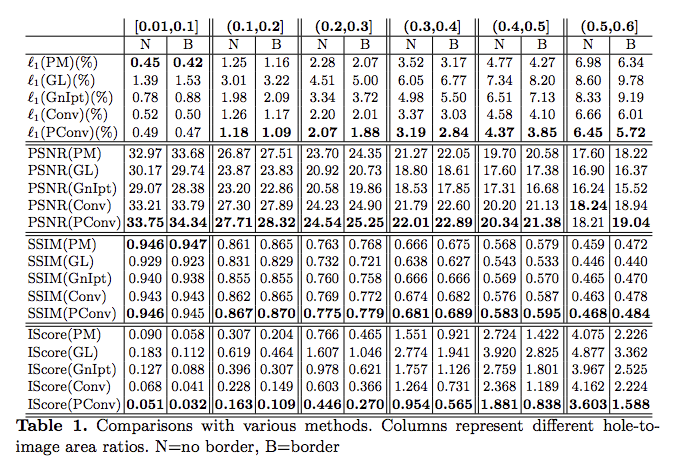
{2} Sundaram, N., Brox, T., Keutzer, K.: Dense point trajectories by gpu-accelerated large displacement optical flow. In: European conference on computer vision, Springer (2010) 438–451
結果





此團隊最後延伸做一下 SR
這結果真的是厲害,
明明論文主體不是SR,但竟然有如此成效。




延伸閱讀
下方論文有作者的問與答,
有興趣可以看看。
http://masc.cs.gmu.edu/wiki/partialconv
TODO:
下文提出了 PConv 的延伸,並進行圖像修復,效果也是很好,過幾天把心得補完再補上連結。
Free-Form Image Inpainting with Gated Convolution : https://arxiv.org/abs/1806.03589
Gated Convolution 圖像修復任務 Deepfillv2 - Free-Form Image Inpainting with Gated Convolution - 09/18更新
參考資料:
arXiv:Image Inpainting for Irregular Holes Using Partial Convolutions
http://masc.cs.gmu.edu/wiki/partialconv
{1} Johnson, J., Alahi, A., Fei-Fei, L.: Perceptual losses for real-time style transfer and super-resolution. In: European Conference on Computer Vision, Springer (2016) 694–711
{2} Sundaram, N., Brox, T., Keutzer, K.: Dense point trajectories by gpu-accelerated large displacement optical flow. In: European conference on computer vision, Springer (2010) 438–451
Gatys, L.A., Ecker, A.S., Bethge, M.: Texture synthesis using convolutional neural networks. In: Advances in Neural Information Processing Systems 28. (May 2015)
Gatys, L.A., Ecker, A.S., Bethge, M.: A neural algorithm of artistic style. arXiv preprint arXiv:1508.06576 (2015)