Gated Convolution 圖像修復任務 Deepfillv2 - Free-Form Image Inpainting with Gated Convolution
Jiahui Yu, Zhe Lin, Jimei Yang, Xiaohui Shen, Xin Lu, Thomas S. Huang; “Free-Form Image Inpainting with Gated Convolution”
10 Jun 2018 發佈, 目前尚未被 Conference 接收。
Project 主頁 : http://jiahuiyu.com/deepfill2
Demo video : https://youtu.be/uZkEi9Y2dj4
Github code非官方實作(不確定成效) : https://github.com/avalonstrel/GatedConvolution
官方版本有考慮要出,但不確定什麼時候,可以 Follow 這一個 issue : https://github.com/JiahuiYu/generative_inpainting/issues/62

簡介
提出基於深度學習進行圖像修復的任務,
並且可以自行輸入不規則的 mask 讓它修補,
而此模型僅需使用圖片就可訓練,
不需要額外的label做輔助。
此論文的主軸為 Gated convolution,
其特點為可以學習出每層 Channel 相對應的空間資訊,
舉例來說對於圖像的修復我們都會給定一個 Mask 指定哪個部分是需要修復的,
透過瞭解空間資訊(Mask),可以讓 CNN 進行更精確的修補,並且不影響到原本就是好的 pixel。
此外提出新的 GAN loss function,稱作 SN-PatchGAN。
此篇貢獻
- 提出 Gated convolutions 去學習每個 channel 的空間資訊,特點是每層的每個 channel 都有其空間資訊做搭配。
- 提出新的 loss function, SN-PatchGAN
- 可供使用者互動,可看Demo video。
- 視覺化顯示出 Gated convolutions 在每層中的情況。
- 應用於 Places2 natural scenes 以及 CelebA-HQ 的資料集,其效果達到目前領域前沿。

前置知識
強烈建議先閱讀下面這篇,
Partial Convolution 圖像修復任務PConv簡介 - Image Inpainting for Irregular Holes Using Partial Convolutions
因為此任務是上方的 PConv 的改進,
並且在上方這篇有介紹到 Conv 與 PConv 的差別。
可看到 Partial convolution 完就好, 後面的網路架構開始可略過。
概念
我們下方會對 Gated Convolution 與 Partial Convolutions 有何不同來做探討。
PConv
PConv 主要公式如下。
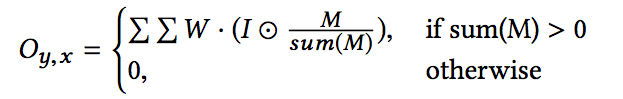
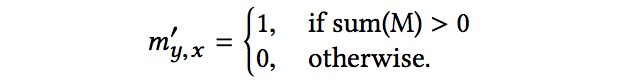
而在此篇論文有提出對於上方公式有幾個疑慮,
- Mask 傳遞機制
My,x處 : 他不論該 kernel 內的 mask 內有幾個未知有幾個是有效的pixel,
只要有一個是有效的pixel傳遞下去都為1,
可以思考幾個情況,舉例 kernel 為 5 X 5,
當 5 X 5 的 mask 全為 1的時候, 該位置傳遞到下一層也為 1
當 5 X 5 的 mask 只有最左上方的 pixel 為1的時候,其他都為0,此時該位置傳遞到下一層也為 1
而這樣的設計似乎有些不完善的地方。
- 此系統不相容使用者輸入
假設我們使用者希望達到下方的功能的時候,

那我們的 Mask 要如何設計呢? 要設為1還是0?
- Mask 逐步消失
在 PConv 的論文中,它的原意是希望透過 PConv 的模型,
逐漸地將圖像需要修補的地方補起來
到最後整張圖修補完成,即為 Mask all 1(空洞為0)
而這個特性也可以解釋成:當到了深層的layer時,空間資訊逐漸被稀釋掉。
- 共用同一個空間資訊
整個網路其實是基於一開始輸入的那個空間資訊,逐步的傳遞,
但這樣子的話似乎有些不彈性。
備註:我個人是對這個點感到有點抽象拉。
Gated conv
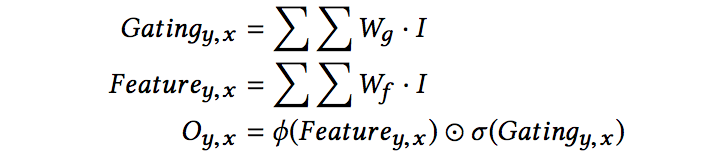
ϕ : Activation function, 如 Relu, leakyRelu。
σ : sigmoid function 主要是要限制 mask 為 0~1 的區間
⊙ : element-wise 乘法
整體說穿了就是下面這樣,
假設原本 X 輸入進一層為 64 個 Channel 的 Layer,
現在會變成 X 輸入進一層為 64 X 2 個 Channel 的 Layer,
其中 64 個 Channel 負責原本 CNN 的事情(學習原本圖像資訊),
而另外的 64 個 Channel 也是經過 CNN ,
但是用意是希望可以學會其相對應 Channel 的 Mask(學習空間資訊)。
最後將兩個 Channel element-wise 的相乘,
達到 Gated conv 所希望傳達的概念。
原作者給出的概念代碼如下

還有個厲害的地方是:原本 PConv 的 Mask 部分是要額外指定給特定的 PConv,
現在的 Gated conv 直接輸入 x 即可,(x = concat(Image, mask), channel-wise concat)
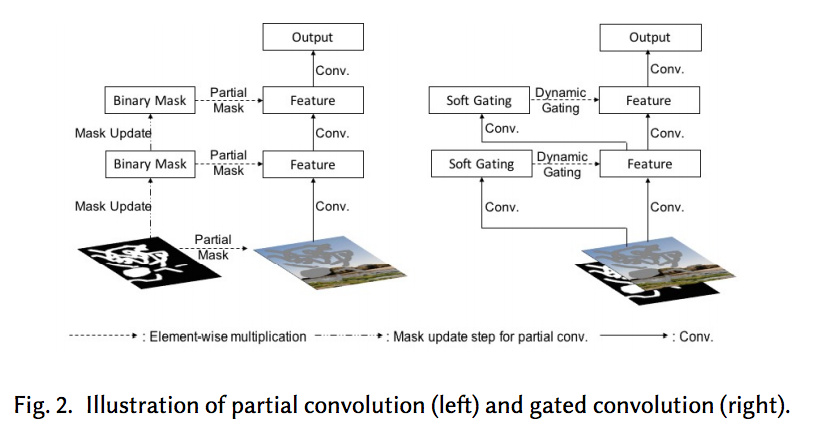
雖然沒放出完整代碼,
但是大家在此連結Deepfillv2 issue討論的很熱烈,
原作者也回應得很快,
對整體可以有大概的想法了。
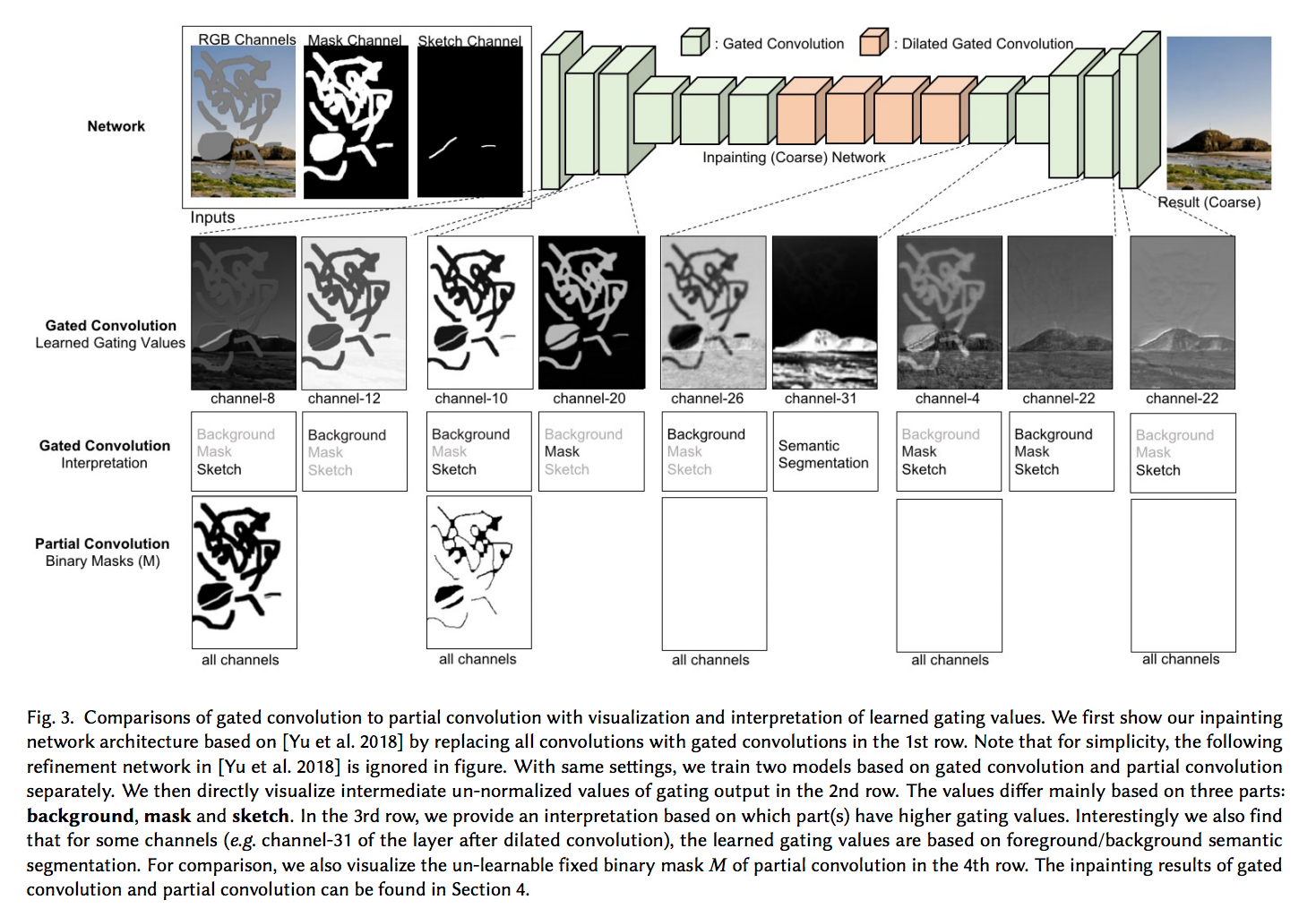
下圖視覺化所要表達的是,
即使在深層我們還是可以發現有塗鴉的資訊存留在該 layer 的某個 Channel,
比較最下方的 PConv, 其塗鴉資訊會逐漸消失。
Spectral-Normalized Markovian Discriminator (SN-PatchGAN)

概念是從 SN-GAN 而來,即為 ICLR 2018 的論文:
- Spectral normalization for generative adversarial networks.
- cGANs with projection discriminator
使用了 spectral normalized 來讓 GAN 更加穩定,
特點是輸出為 3D 的 feature maps,
透過 3D 的 feature maps 做 Hinge loss。
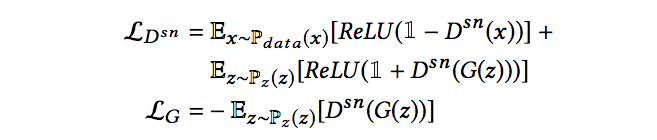
Dsn : 代表 spectral-normalized discriminator
z : 代表不完整的圖片
而此 loss function 有別於 PConv 提出的那麼複雜(有6個參數可調)的 loss function,
此 loss function 還有結合 l1 的 reconstruction loss,整體來看還算簡單。
剛好我以前寫過這篇論文簡介cGANs with projection簡介,不過那篇的概念部分,我後來看,都覺得我到底在寫什麼。。。
總之呢,能夠參考Github:cGANs with projection discriminator的代碼。
網路架構
架構主要是基於 arXiv:Generative Image Inpainting with Contextual Attention,
其實就是此論文的發表團隊於 CVPR 2018 所提出的圖像修補框架,
基於此框架再將 Conv 都換成 Gated-Conv 作延伸,
此處因我沒有看過上述文章,因此對架構不多做探討。
Free-Form Masks Generation
與 PConv 提出的使用影片連續畫格來提取 Mask 方法不同,
此團隊提出用另一種方法來獲得更像普通使用者會畫出的不規則的 Mask,
演算法如下, 這部分我不多做介紹。

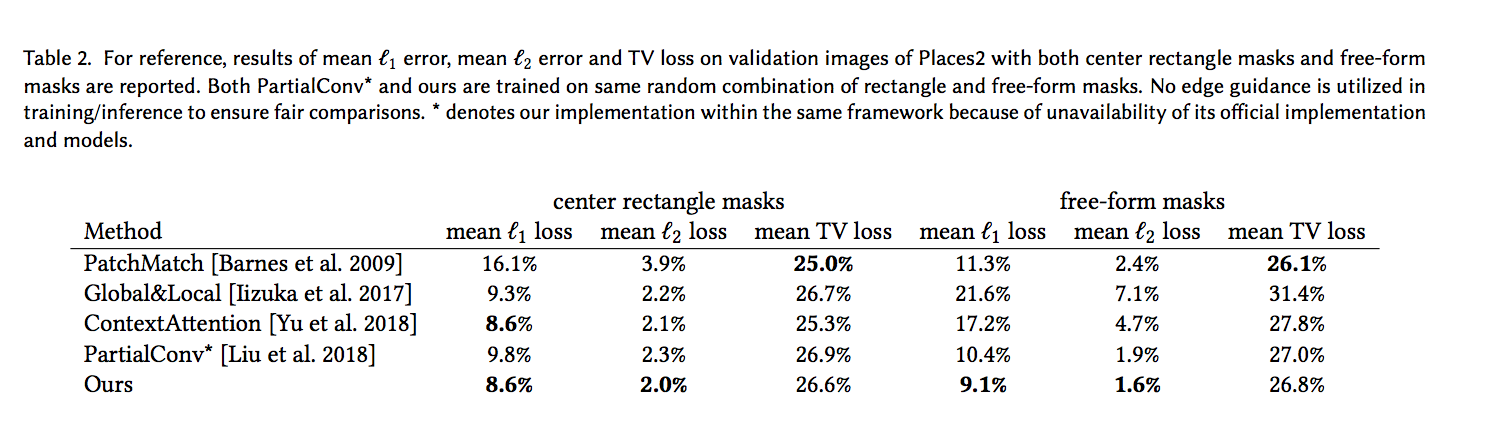
結果






參考資料:
arXiv:Free-Form Image Inpainting with Gated Convolution
arXiv:Generative Image Inpainting with Contextual Attention
arXiv:Image Inpainting for Irregular Holes Using Partial Convolutions
Partial Convolution 圖像修復任務PConv簡介 - Image Inpainting for Irregular Holes Using Partial Convolutions