GAM簡介 - Domain transfer through deep activation matching
Haoshuo Huang, Qixing Huang, Philipp Krahenbuhl;“Domain transfer through deep activation matching”; The European Conference on Computer Vision (ECCV), 2018, pp. 590-605
ECCV 2018 paper
project 主頁:https://rsents.github.io/dam.html
Github code : 沒找到
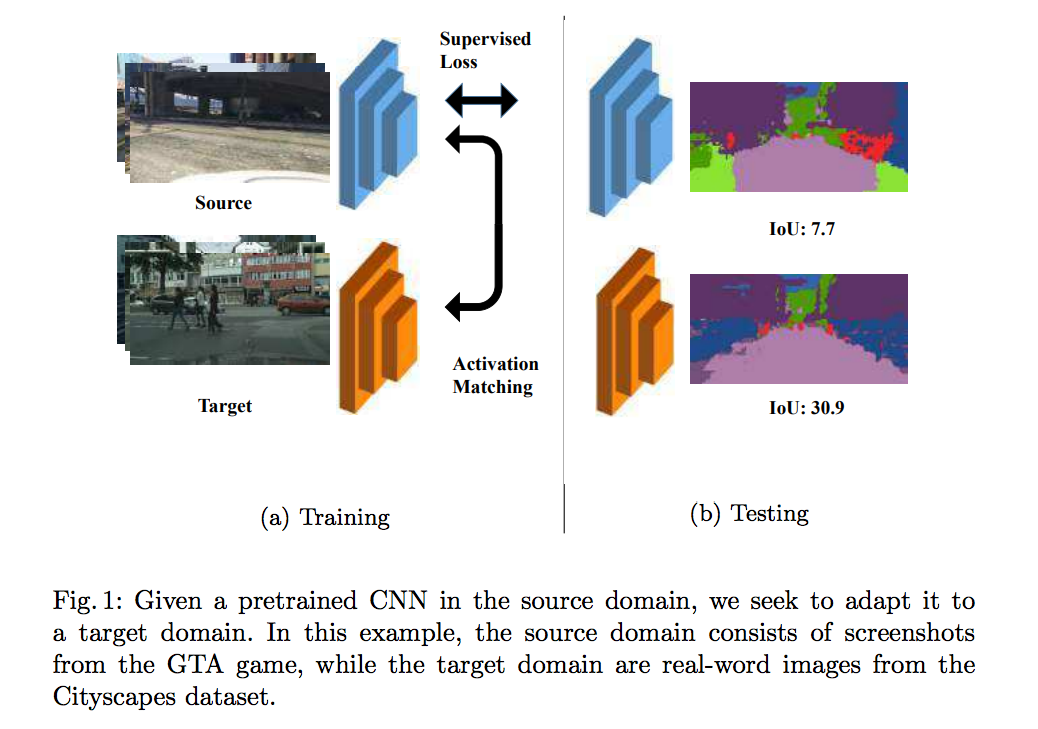
簡介
本文提出 General activation matching(GAM) 方法,
其方法是解決 Unsupervised domain adaptation(UDA)的問題,
特色為讓每層(layer-wise)輸出的分布相似,
並非只讓 Output layer 的輸出分布相似。
說破就是透過使用 GAN 的方式來讓內部 layer 的分布也要相似,
此方法適用於 Semantic segmentation 以及 Classification 的任務。
以往的 Domain adaptation(DA) 方法主要是針對 Output layer 的分布去做調整,
而此篇提出不只是要對 Output layer 還要對內部的 Activation layers 的分布做調整。
主要提出兩個論點
- 針對內部的 Layers 去做調整分布的動作,對 DA 的任務來說可以更加的穩健。
- 對內部 Layers 調整分布,可緩解 Covariate shift 的問題。(因為在中間的 Layer 中也有 Covariate shift 的問題)
對 Covariate shift 不了解的可以看下方兩個文章
並且在幾個 DA 常用的資料集都顯現出此方法能夠提高準確度:
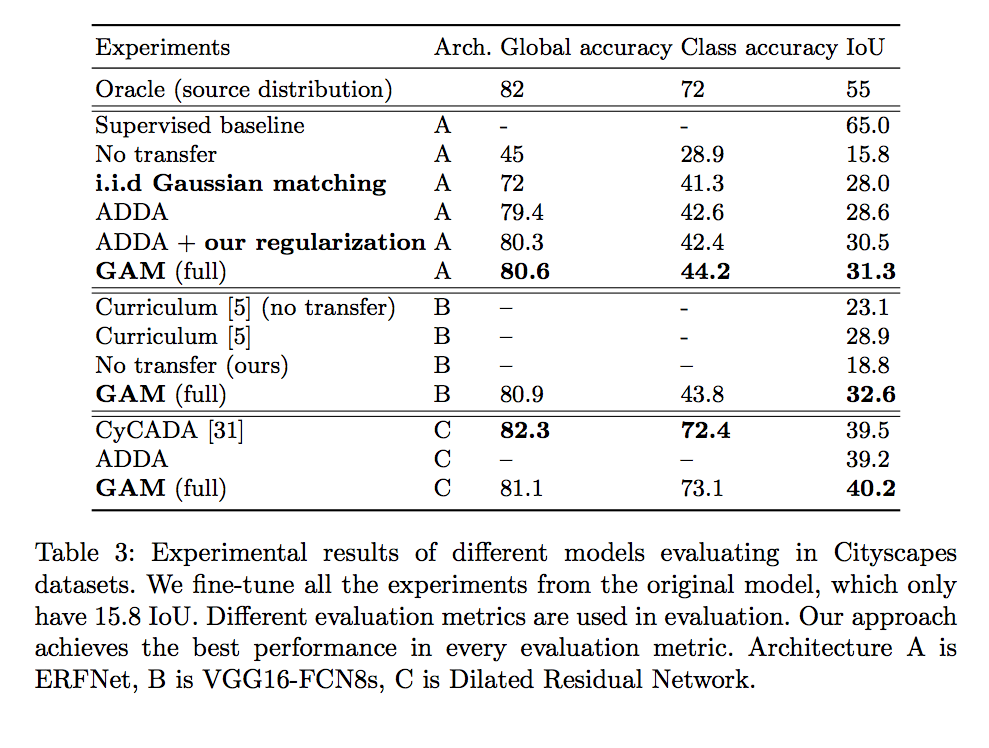
- GTA to CityScapes (semantic segmentation)
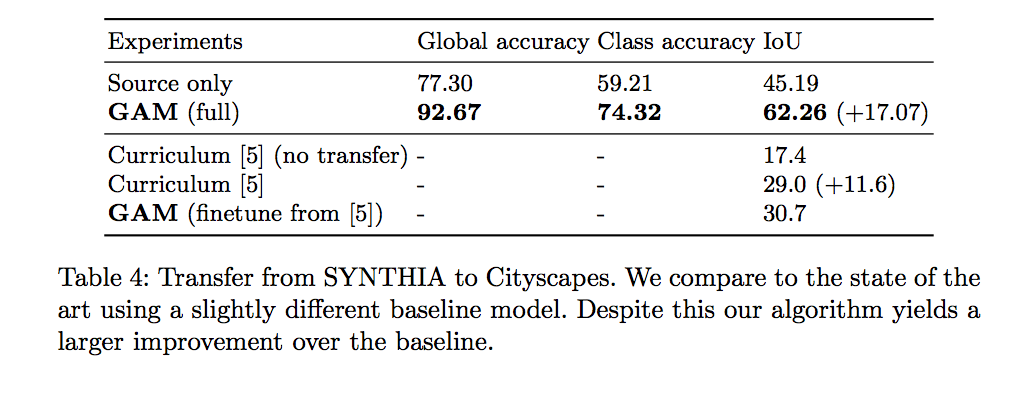
- SYNTHIA to CityScapes (semantic segmentation)
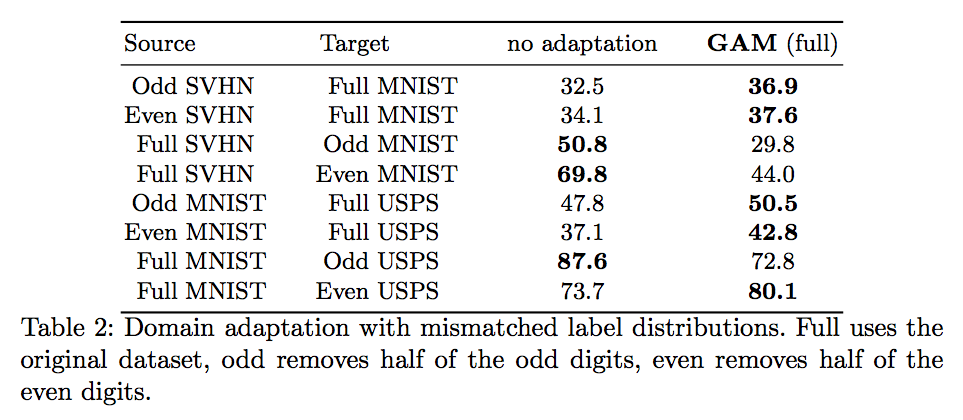
- USPS and MNIST (image classification)
此篇都是基於 independent and identically distributed(i.i.d. Gaussian) 的原理去思考的,
建議去看 知乎:詳解深度學習中的Normalization,BN/LN/WN ,
此篇的方法與 BN 相似。
概念
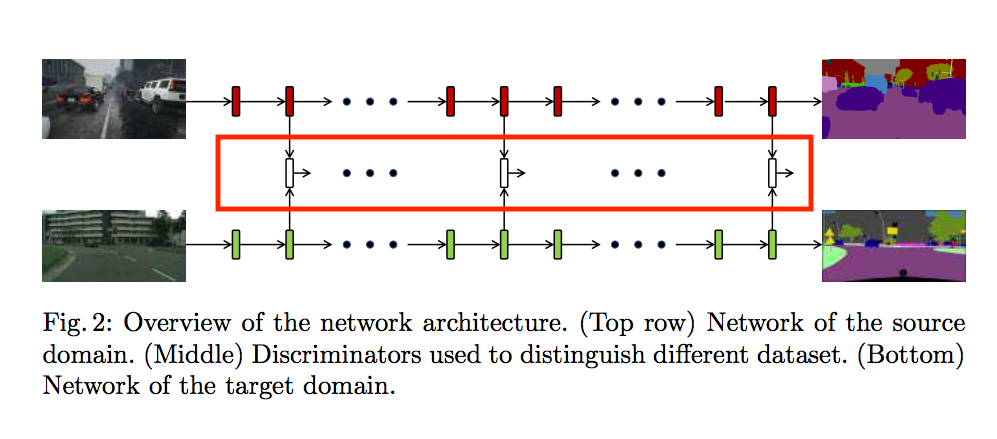
此篇的想法是當我們要 transfer model 時,
會有 Source model 以及 Target Model。
我們希望透過中間紅框的 Discriminator 讓內部 layer 的分布是相似的。
Label distributions
以 Semantic segmentation 的任務為例,
以往我們都是在 Output layer 所輸出的是各個像素的各個類別的機率,
舉例 f(x=0, y=0) = 天空0.8 車子0.1, 道路0.05, 人行道0.05
我們以往在 Output layer 後加入 Discriminator 的話,
他做的事情其實是讓 Target domain 的輸出分布與 Source Domain 的輸出分布盡量相似,
但是對於 UDA 的問題,
我們在訓練時是不會給 Target domain 的 label,
所以在沒有 Target domain label 的情況下,
若是只憑藉 Target domain 的輸出分布要相似於 Source domain,
這能學習到的其實是有限的。
Activation distributions(此篇的突破)
Domain shift 的問題不僅僅是發生在 output layer,
在內部的網路其實都有這個問題的發生,
因此我們需要有個方法來緩解這種狀況的發生。
因此提出在內部激活層後的輸出分布要相似。
看看使用同一個模型,但是輸入不同 Domain 的圖片會是怎樣。

此部分有一段話,目前沒有很好的理解,
原文:While activation matching provides considerably more constraints on supervised domain adaption than merely aligning the label distributions, it is not yet sufficient — one can still design a target network so that it matches activation distributions but outputs different pixel-wise labels.
目前理解是雖然內部層的輸出分布相似,但是輸出的 label 還是會依照 target domain 做 output。
Weight drift
DA 可以看作是從 Source domain 所學習到的資訊慢慢調整至 Target domain,
因此我們只需要微調,
透過加入 Regularizer 確保 Source domain 與 Target domain 不會相差太多。
方法
P: 輸出分布 empirical distributions of X
Ai: 在模型 F 中的第 i 個激活函數後的輸出 activation at the i-th layer of F
其想法為透過 Regularizer 讓 Source domain model 與 Target domain model 的參數相似,
還要讓輸出分布相似。
式子如下:
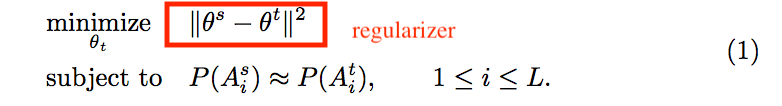
Gaussian i.i.d. matching
這邊的想法是想說 Target domain 是很相似 Source domain model,
既然相似的話,只要 Target domain 的分布相似,
再經過平移與縮放找出對應於 Target domain 的最佳參數,
照理來說會得出不錯的結果。
整體想法相似於 BN 以及 AdaBN(在後方有附演算法,可參考)
此方法的基礎是建設在 weight initialize 是使用 Gaussian i.i.d.。
定義
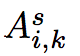
是在第 i 個 layer 中的第 k 個 channel
並且假設 A 遵循 Gaussian 分布,
因此我們就會有 mean µ and standard deviation σ,
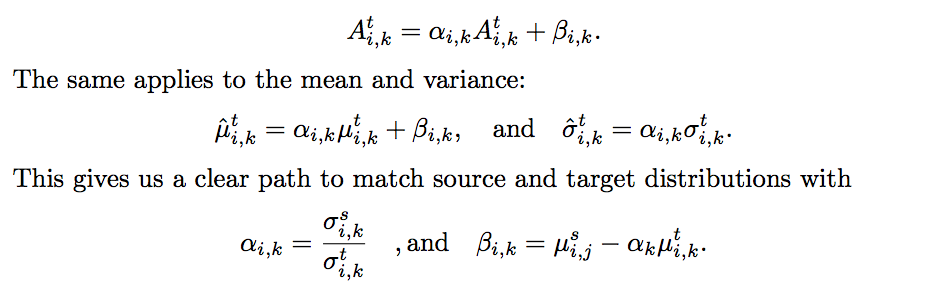
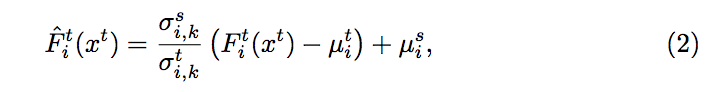
文中也有提到上述的方法可用 AdaBN 的方法替代。
同場加映
BN - Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift
AdaBN - REVISITING BATCH NORMALIZATION FOR PRACTICAL DOMAIN ADAPTATION


General matching
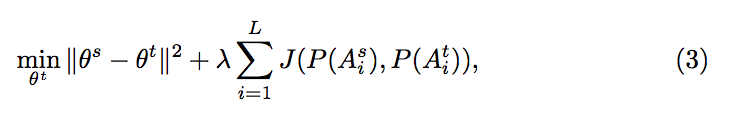 備註:此實驗 λ = 0.1
備註:此實驗 λ = 0.1
這邊我們希望可以讓每個 layer 的參數輸出分布相同,
我們會透過 Jensen-Shannon divergence (JSD) 來達到這件事,
使用 JSD 有個好處是他只有當分布完全符合時才為 0,
其他時候都為 > 0 的值。
那如何才能在類神經網路這眾多的參數中找到找尋 JSD 呢?
有個方法是使用 Discriminator 去達到這件事,
這邊理論不懂的話,可以看台大李宏毅教授 - GAN Lecture 4 (2018): Basic Theory。
備註:
此方法使用 Discriminator 前,
該層的激活函數需先經過 Gaussian i.i.d. matching 後,
再輸入進 Discriminator 才能有效地訓練。
這樣一整套稱作 GAM(Gaussian i.i.d. matching and General Activation Matching )
在數字分類任務上是使用基本的 GAN (因只是數字分類的任務,不難),
在 Semantic segmentation 的任務上是使用 Least Square GAN(LS-GAN)
實驗設定
有分為 Classification 與 Semantic segmentation(SS)任務,
實驗有點瑣碎,我只挑我覺得重要的介紹。
在 SS 任務中採用ERFNet,
並且在(4th/17, 8th/17, 12th/17, 17th/17)在這4層加入 Discriminator,
作者表示只用4個就夠好了。
而在 Classification 任務中,因為比較簡單,
因此只要在最後2層加入 Discriminator 即可。
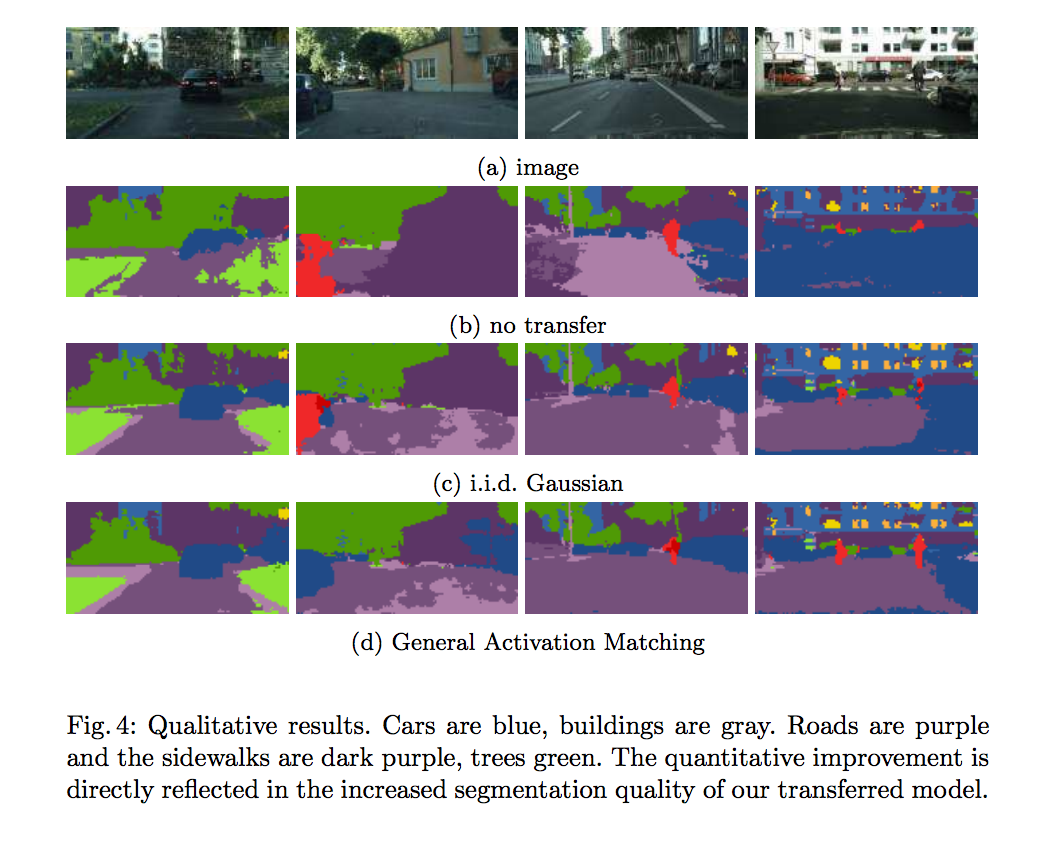
實驗結果
參考資料:
Domain transfer through deep activation matching
REVISITING BATCH NORMALIZATION FOR PRACTICAL DOMAIN ADAPTATION
Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift