Deep image prior 簡介 - 不需資料集即可使用深度學習進行圖像修復/去雜訊等任務
Dmitry Ulyanov, Andrea Vedaldi, Victor Lempitsky; “Deep Image Prior.” In The IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2018.
CVPR 2018 paper
Project 主頁 : https://dmitryulyanov.github.io/deep_image_prior
Paper Link : https://arxiv.org/abs/1711.10925
Paper Supmat Link(模型架構/實驗細節) : https://box.skoltech.ru/index.php/s/ib52BOoV58ztuPM#pdfviewer
Github code(Pytorch) : https://github.com/DmitryUlyanov/deep-image-prior

簡介
近年深度學習進行圖像生成/還原的任務非常火紅,
但其成功的原因是因為背後有著大量的資料集供 Model 訓練,
才能夠訓練出效能如此卓越的 Model,
而此篇提出一個不同的方向,
僅透過一張圖片去訓練 Model,
並應用至 Denoise / Super Resolution / Inpainting 等任務,
都獲得不錯的成效。

備註:
雖然上圖是寫 Not trained,
但是他的意思為並非使用大量資料集訓練,
此方法還是有訓練,不過僅使用輸入圖片(單張)訓練。
概念
對於一些圖像處理的任務(denoising, super-resolution, inpainting),可寫作下面這個等式,
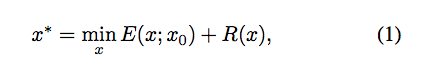
參數定義:
E(x:x0):依照任務給定。後面介紹各個應用(denoising, super-resolution, inpainting)會一一帶入。
x0:輸入的影像,如去雜訊任務就是給一張有雜訊的影像。SR任務就是給低解析度的影像,維度為(3, H, W)
x:我們模型所產出影像
R:regularizer 用於判斷圖片是否自然,這邊也稱作prior(中譯先驗:可從資料集中學會 or 使用人工定義的數學如:Total Variation(TV))
z:隨機給定一個張量,維度為(32, H, W)
而我們的 R(x) 定義如下
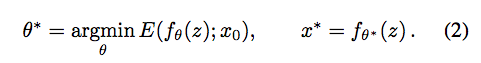
我們希望 Model 所產出的圖片可以相似於輸入的圖片,
當相似的時候我們希望 R(x) 的輸出為 0, 不相似時輸出為 +∞
流程:在一開始會先隨機產生一個 z ,
之後就使用這個 z 去做訓練,
我們會基於這個 z 去訓練一個神經網路讓他能夠產生相似 x0 的圖片。
可能會有人好奇為什麼 R(x) 要用上面式子替代,
以去雜訊任務(denoising)為例:
去雜訊的任務可寫作下面兩式:
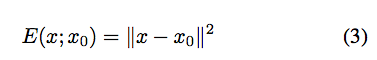
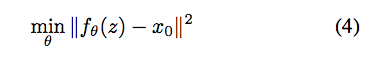
理想上我們其實可以透過 Model 去輸出一個極度相似 x0(有雜訊) 的圖片,
只要訓練得夠久,我們產生的圖片甚至能夠將雜訊的部分也輸出出來。
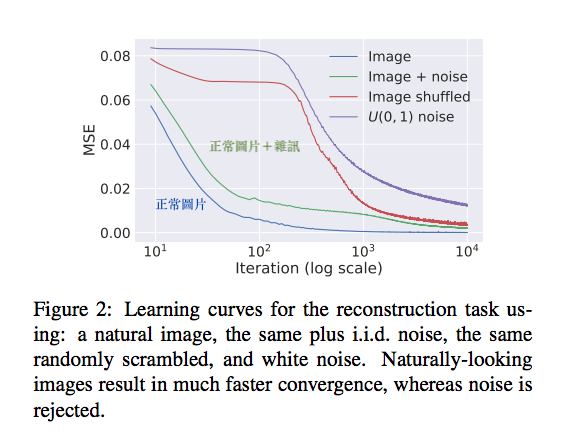
可是看到上圖可以發現 Model 在學習沒雜訊的圖片時會訓練得快一點。
實際上在訓練模型時,會發現模型學習一般的圖片(natural-look)會比較快,
而圖片+雜訊就會學得比較慢,因為雜訊較不規則,Model會學的比較辛苦。
可以得知 Model 在處理雜訊時有較多的阻抗,而處理正常的訊號時有著較低的阻抗。
P.S.
而這邊也有人解釋成一張自然的圖片會有較多的低頻資訊,因此模型只要先學好低頻資訊,分數自然就降的快。
但有雜訊的圖片卻有著相對多的高頻資訊,所以 Model 除了要學好低頻資訊外還要多學一點高頻資訊,因此有雜訊的圖片不會像自然圖片那樣,降的那麼快。
因此整體概念為我們限制學習的次數(Iteration),
在模型還沒有學會擬合雜訊的訊號時我們就停下來,
而這時候就會很神奇的發現模型所產生出來的是去雜訊的圖片了!
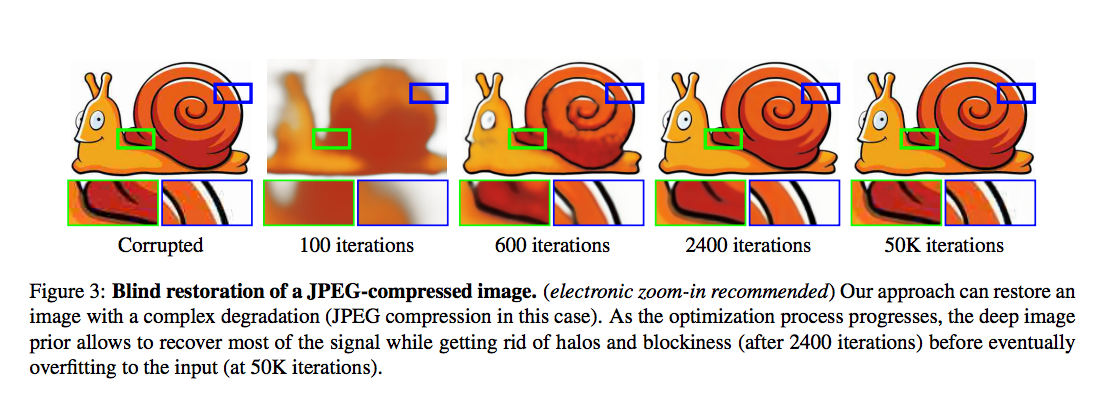
下圖 2400 步時 Model 所生成之圖片即為去雜訊的圖片,
而下圖 5000 步時 Model 所生成之圖片就學會擬和雜訊,因此又有雜訊出現了。
其實最終說穿了,只要我們的 model 訓練得好, 其實 R(x) 項是可以無視掉的,
因此最終式子理想上可以變成下方:
![]()
上方詳情可看Deep image prior Homepage
訓練示意圖(2018.10.15更新)
訓練至100步
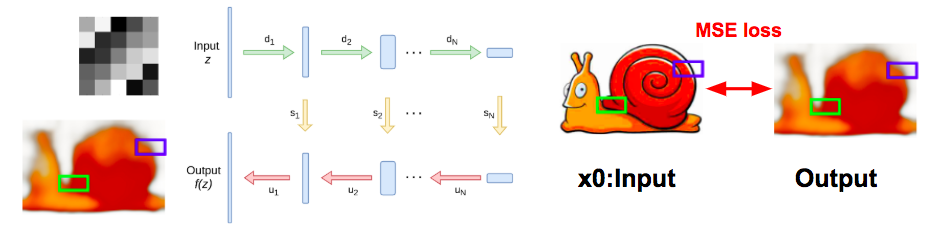
訓練至600步
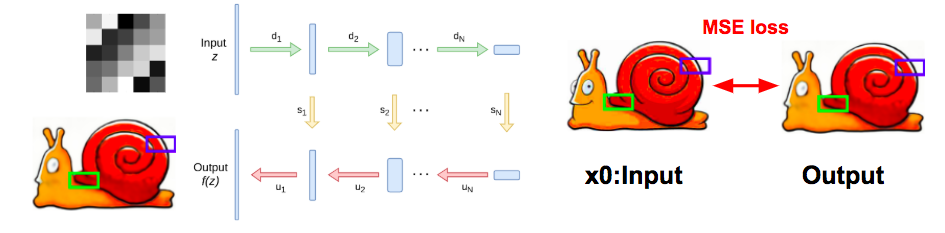
訓練至2400步
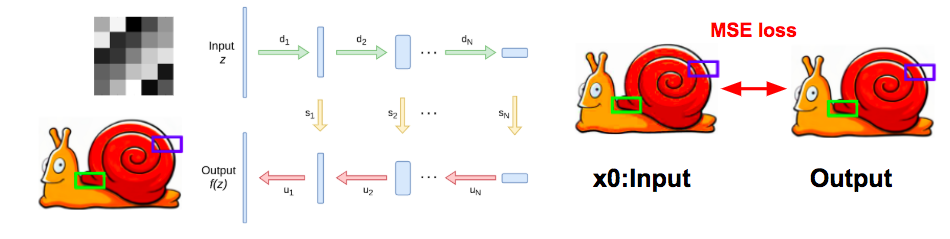
應用
下方會介紹此模型可達成的應用:
- 去雜訊(Denoising)
- 超解析度(Super-resolution)
- 圖像修補(Inpainting)
- Natural pre-image
- Flash-no flash reconstruction.
上面這些應用的架構採用 UNet (encoder-decoder架構)
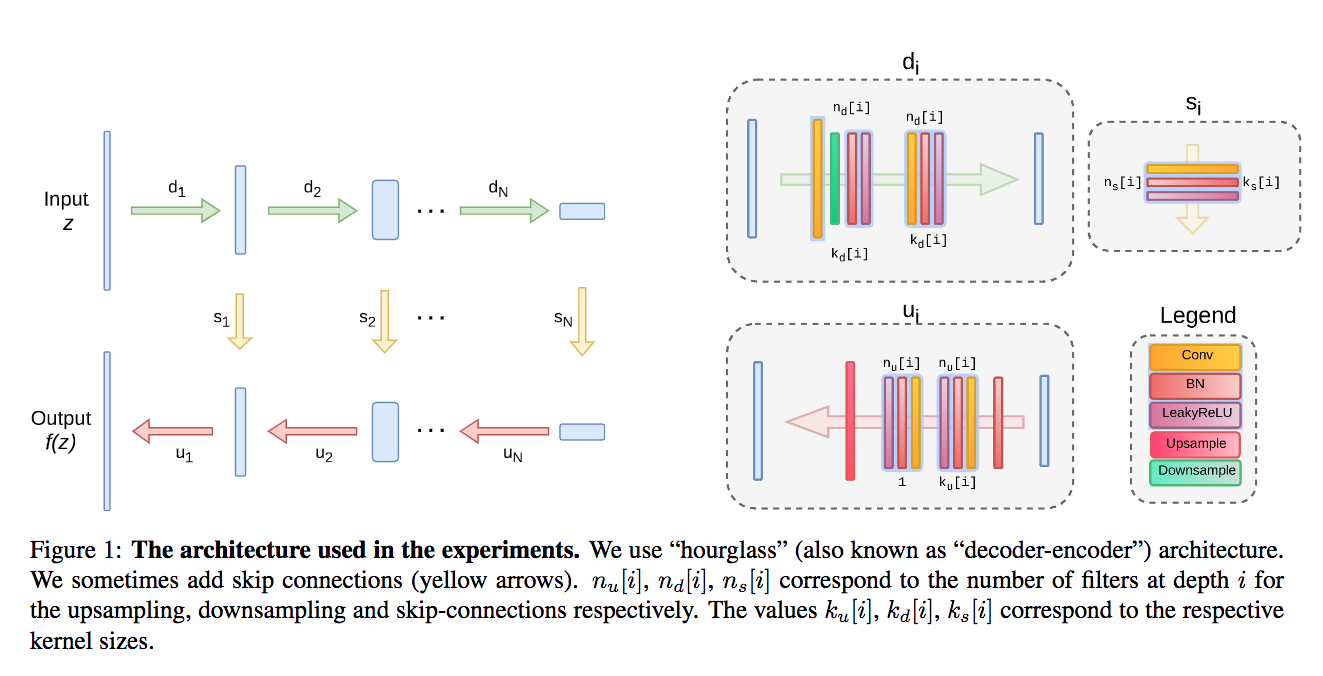

而設定會依照不同的任務微調,有興趣的可以去看補充文件Deep image prior - Supmat
Trick:
- skip connection 不宜過多。
Denoising and generic reconstruction code
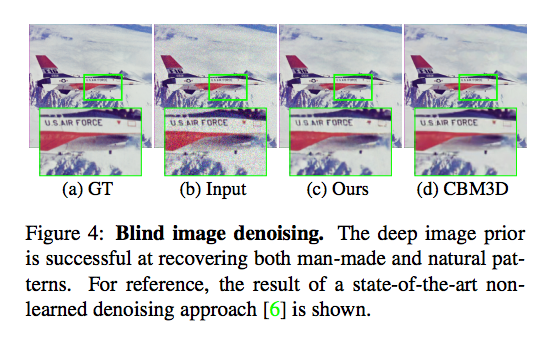
比較其他可直接使用(不需訓練)的方法相比:
此方法 PSNR : 31.00
CMB3D PSNR : 31.42
Non-local means PSNR : 30.26
備註:PSNR 越高越好
Trick:
- 當初說固定 z 做訓練,但是在 denoising 任務中在訓練過程中小小的擾動 z 會得到更好的結果。
- 最後幾個 Iteration 所輸出的圖片做平均會得到更好的結果。(29.22 -> 30.43)
- 使用兩個優化器(Adam / LBFGS)去跑實驗(30.43 -> 31),雖然code沒有寫到這部分,不過原理應該跟上方差不多。
Super-resolution code
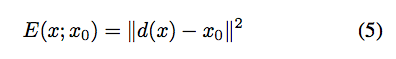
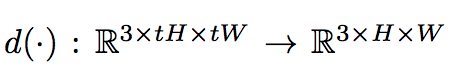
SR 是個相對困難的問題,
因為可能會有 N 張不同的高解析度的圖片經過 downsample 縮小後 ,
得出的是同一張 low resolution 的圖片。
因此就很需要 R(x) 去做 Model 參數的優化,
讓 Model 可從多張高解析度的圖片找出最適當的一張(儘管 d(.) 過後都是同一張 LR 的圖片)。
Trick:
- 使用 Lanczos 當作 downsample 因為他可微分,就可做 gradient descent。
在 Set 5 以及 Set14 的表現:
此方法 PSNR - 29.90 / 27.00
Bicubic PSNR - 28.43 / 26.05
SRResNet(需要訓練) PSNR - 32.10 / 28.53

Inpainting code
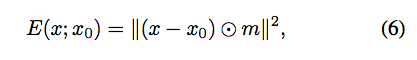
mask = {0, 1}
0 為空洞 1 為正常圖片
我們會透過正常部分的圖片讓 Model 去做學習,
除此之外此公式還能夠讓不需修補的部分要盡量保持原樣,
即為 M = 1 的正常圖片不要去動到。
出乎意料的是在有大範圍空洞的圖像修補任務中,也處理得不錯。



Natural pre-image code
可看出一個模型是否真的學到想要的東西,
這部分有興趣的可去看下方論文
A. Mahendran and A. Vedaldi. Understanding deep image representations by inverting them. In Proc. CVPR, 2015.

Flash-no flash reconstruction code
先前的任務都是輸入一張圖片,
而此部分將它延伸到多張圖片。
這部分有興趣的再自行去看code。
