BigGAN簡介 - Large Scale GAN Training for High Fidelity Natural Image Synthesis
Andrew Brock, Jeff Donahue, Karen Simonyan. “Large Scale GAN Training for High Fidelity Natural Image Synthesis”.
Submit to ICLR 2019
OpenReview : https://openreview.net/forum?id=B1xsqj09Fm
Paper Link : https://arxiv.org/abs/1809.11096
此篇主要是基於下面兩篇論文:
- Takeru Miyato, Toshiki Kataoka, Masanori Koyama, Yuichi Yoshida. Spectral Normalization for Generative Adversarial Networks. ICLR2018.
- Han Zhang, Ian Goodfellow, Dimitris Metaxas, and Augustus Odena. Self-attention generative adversarial networks. In arXiv preprint arXiv:1805.08318, 2018.
備註:
這Paper 29頁,附錄有很多 G 和 D 的分析,下面只有轉載一小部分,對實驗細節有更多興趣的話請去看論文。

簡介
GAN 常見的問題就是訓練時會不穩定,
即便今年 ICLR 2018 針對 GAN 提出了一個新的 weight normalization 的方式 - spectral normalization,
但在大型的 GAN 仍有訓練不穩定的問題存在,
此文就是針對大型的 GAN 做探討,
並提出一些能讓大型 GAN 穩定訓練的方法。
提出 BigGAN 展示圖像生成(Image Synthesis)的任務,
因是多類別的圖像生成任務,
所以是對 class-conditional GAN(可生成特定類別的 GAN) 做探討,
在 ILSVRC2012, JFT300M 等大型的資料集上訓練,
都顯示出很好的成果。
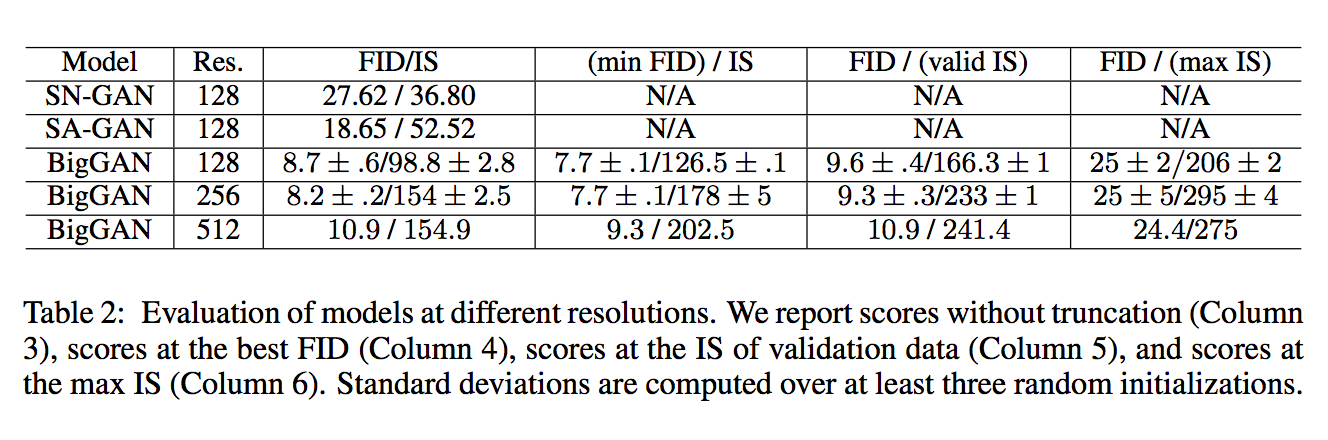
此論文能穩定訓練 128 X 128 / 256 X 256 / 512X512 解析度的圖像生成模型。
這樣看下來可能覺得沒什麼,
但是 ICLR2018 的 SN-GAN 能基於 ImageNet 的 1000 個類別去生成 128 X 128 的圖片就已經是很大的突破了,
才過不到一年就突破到 512 X 512 真的厲害,
而且只用一組 GAN , 並非使用多個 Discriminator 來加強解析度的招數。
整篇論文朝著三個方向
- 加大 2 ~ 4倍的參數量 / 加大 8 倍 Batch size , 透過更改架構以及提出 Regularization 的方法來增進效能。
- 提出 trunctation trick, 使用這方法能讓模型在多變化(variety)和精細度(fidelity)做取捨,可想成控制模型的能力 e.g. 看是要生成10種不同的狗狗但都很粗糙,或是生成3種不同的狗狗但都很真實。
- 探討大型的 GAN 為什麼會不穩定,並且分析本文所介紹的方法。
BTW,
此文是 Google 使用 TPU v3 Pod 訓練,
透過加大 batch size / channel / layers 來探討大型的 GAN,
這實驗可能不是每個人都做得起的。。。
而此篇模型基於 SA-GAN 再加上此論文的訓練技巧就將 SA-GAN 的 FID/IS 分數甩開一截,
SA-GAN - 2018.05月才發布,
此篇2018.09月發佈,僅僅4個月就突破這麼多,
這領域進步的真快。。。
架構說明
主要架構是基於 SA-GAN (Self-attention GAN),
同樣採用 Hinge loss,((可見 Geometric GAN / SN-GAN
G 的部分加入 class-conditional Batchnorm,((可見 A learned representation for artistic style
D 的部分使用 projection,((可見 cgans with projection discriminator
改動原先 SA-GAN 的 learning rate 及改為訓練2次 D 才訓練1次 G。((可見 Self-attention GAN 的 TTUR 部分。
依照不同資料集以及解析度大小有給定不同的模型, 有興趣的去翻論文看。

模型會在 Google TPU v3上做訓練,
每個模型耗費 128 ~ 512個核心做訓練,
而比較不同的地方是他的 BatchNormalize 是基於所有 TPU 的裝置做 BN,
並非對單獨一台做 BN。
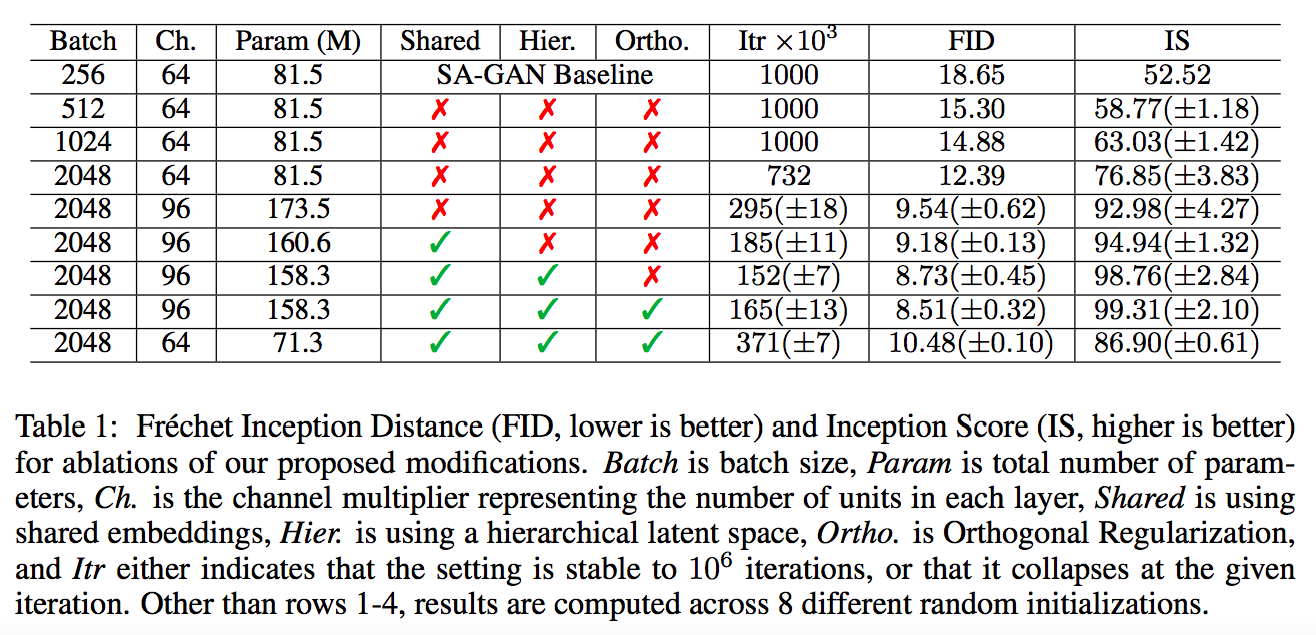
參數會在下方做更詳細的介紹
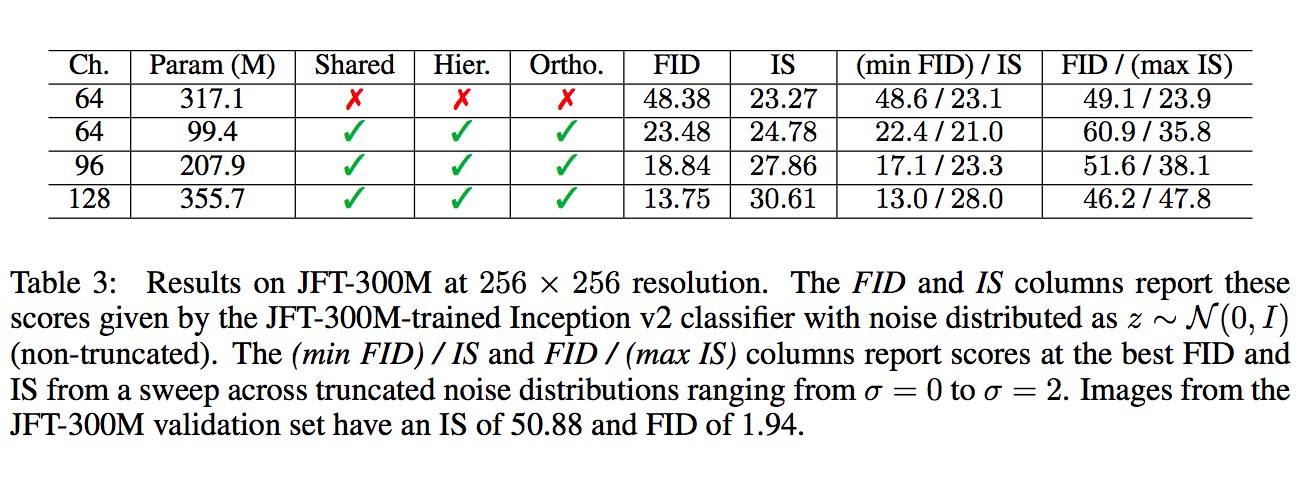
- Shared: shared embeddings
- Hier: hierarchical latent space
- Ortho: Orthogonal Regularization
- Itr: iterations。值得注意的是當模型越大,可以在較少的步數得到最好的結果,但副作用是在訓練時可能會壞掉。((上方不足 1000 的皆是訓練到該步數就壞掉。
我們先看上面這張表的前 4 列,
將 Model 的 Batch Size、Channel size 加大, 都能夠提升最終的效能。
但本文還有提到模型變深並沒有比較好,因此沒有出現在上面這張表上。
Shared - shared embeddings
若在 G 的不同層各自使用該類別的 embedding 會增加很多參數,
並且訓練起來會比較慢,
因此提出 Shared embedding 共用同一組,來節省記憶體以及增加訓練速度。
概念以及下圖出自
Ethan Perez, Florian Strub, Harm de Vries, Vincent Dumoulin, and Aaron Courville. FiLM: Visual reasoning with a general conditioning layer. In AAAI, 2018.
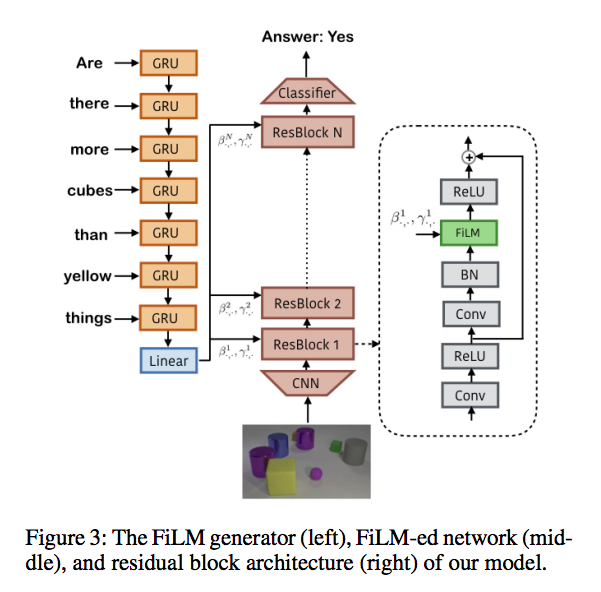
Hier: hierarchical latent space
以往的 GAN 的 noise-z 往往僅於一開始的地方輸入(下圖左半部),
而此篇將 Noise-z 分散輸入,
假設原本的雜訊是 123456(舉例而已不用在意值域),並且有3層,
那它那3層會各自輸入 12(輸入層), 34+c, 45+c,
如下圖右半部的概念。

Ortho.: Orthogonal Regularization
在下方這篇有提到 ORTHOGONAL REGULARIZATION,
Andrew Brock, Theodore Lim, J.M. Ritchie, and Nick Weston. Neural photo editing with introspective adversarial networks. In ICLR, 2017
原本的用意是因為矩陣相乘在深層網路的傳遞中可能會有訊號消失或是訊號爆炸的問題,
因此提出希望 W 與輸入的 Matrix 盡量可以 Orthogonal。

但在下方這篇論文(SN-GAN),提出不一樣的看法
Takeru Miyato, Toshiki Kataoka, Masanori Koyama, Yuichi Yoshida. Spectral Normalization for Generative Adversarial Networks. ICLR2018.
下方與上方兩個式子是等價的,可以看 Wiki:Matrix norm

Spectral Normalization 是要讓最大的 Singular value 去限縮為 1,
但 Brock 的 Orthogonal Regularization 是要讓所有的 Singular value 都趨近於 1,
兩者本質上是有衝突的。
因此本文提出變形的 Orthogonal Regularization,
我們只要不要更動到對角線的 Singular value 就好拉,
這邊給出的解釋是希望透過下面這式子去最小化 Cosine similarity 並且透過下面這式子也不會更改到原本的 norm
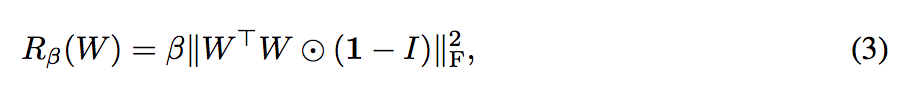
1: 整個矩陣的元素都為
β: 設定為 10-4
如果採用此方法可讓下方的 Truncation trick 在 60% 的模型上可用,若不採用此方法僅有 16% 的模型可用。
Truncation trick
簡單來說,
Noise z ∼ N (0, I),
這篇使用到的技巧是當我們的 Noise > threshold,
就將他重新取樣 Noise 直到 Noise <= threshold,

這邊可以看到 a 圖有 4 個部分,
分別定義 threshold 為 2, 1.5, 1, 0.5, 0.04 ((上面只有4組圖片,他怎麼給5個數字,不過就先這樣把假設左到右是由大至小
當 threshold 變得小時,我們可以發現輸出的圖片都差不多只是某些部分微調,
而我們希望透過這件事情去 fine-grained model,
簡單地想就是當生成出類似的圖片時,
Discriminator 就能針對這類的測資去 fine-grained,
限縮了圖片的多樣性,但是能針對這類型重複出現的圖片做訓練,因此能產生出較高品質的圖片。
而 b 部分是說,並不是每個大型的 GAN 都能夠使用這種技巧,
可能會發生 b 部分的狀況。
而為了要避免 b的狀況,因此就想到了上方的 Ortho.: Orthogonal Regularization,
希望透過上方的特性能讓 G 的訓練可以平滑,讓整個模型可以穩定一點。
分析大型GAN
儘管上方介紹了這麼多招,
不可否認的是模型還是有可能會訓練到一半就壞掉,
Early stopping 是必要的,
從 table 1 也可得知越大的模型訓練得越快,
但是副作用也是有可能會訓練到一半壞掉。
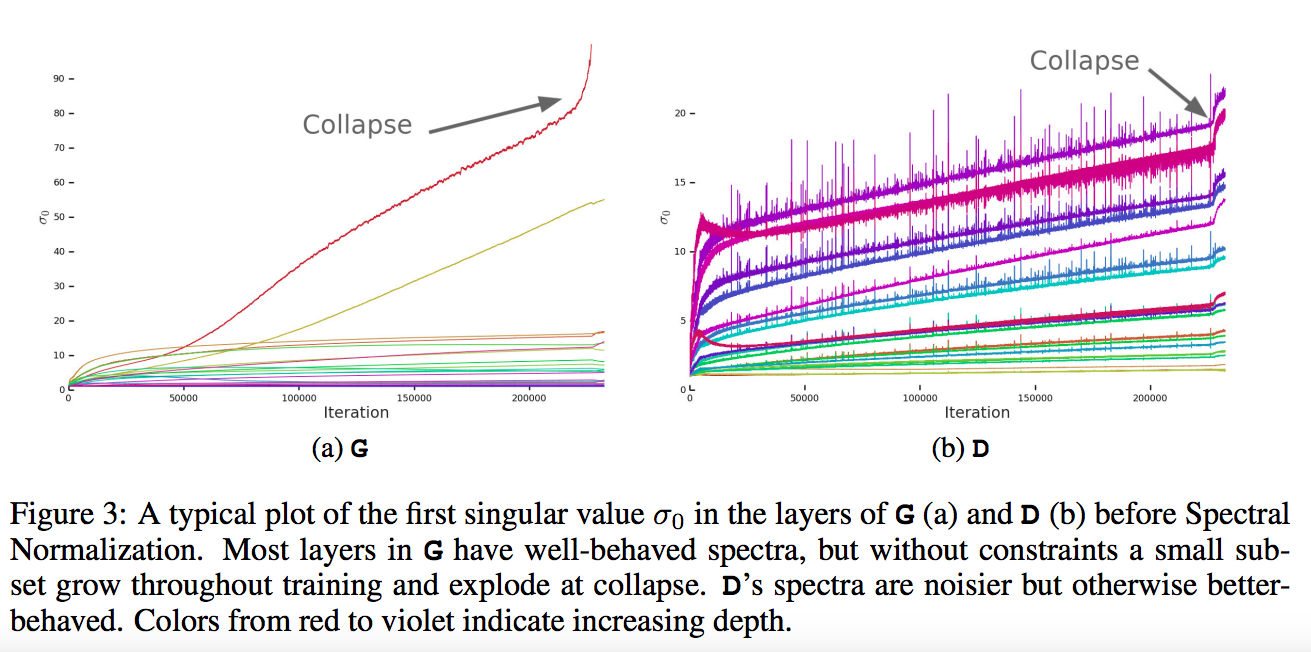
這張圖就看作是儘管前面都很穩定,但是還是有機會訓練到一半爆炸。
顏色由紅到紫代表 layer 深度,
這張圖的 Singular vale 不清楚是哪個 channel 所以我假設是該層的所有 channel 的平均,
btw,
在 SN-GAN 的圖是有 1…n 個channel 的 singular value
分析大型GAN - Generator
以往對 GAN 的深入研究都是偏向小型的 Model 或是僅僅用來解決簡單的問題 ((和這個相比的話都算小吧。。。
僅憑調整參數可以在小型的模型中穩定訓練,
不代表在大型的模型中也可以穩定的訓練,
因此此論文監控了訓練時的權重(weight)/ 梯度(gradient)/ 損失(loss)。
來看看是哪些因素會造成 training collapse,
發現了在每個 weight matrix (channel) 的前三個 singular value 最有影響力 σ0, σ1, σ2,
這意思就是說在 G 套用 spectral norm 是可行的,
備註:原本的 spectral norm 只著重於 σ0
但是在第一層的還是有問題,
因為第一層是輸入層,
接收到的是雜訊,還要訓練。。。
更直覺地想,你沒辦法期望輸入一個 noise 卻只靠一層 CNN 就能產出什麼有用的資訊吧。
為了避免 spectral explosion, 所以要對於最大的 Singular value - σ0 做 Regularize,
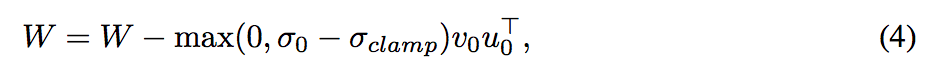
這邊對 σclamp 提出兩種方式
- 定值: 希望它限縮在某個範圍
- 倍數關係:不能超過 σ1 的某個倍率
倍數關係用以防止下圖爆炸。
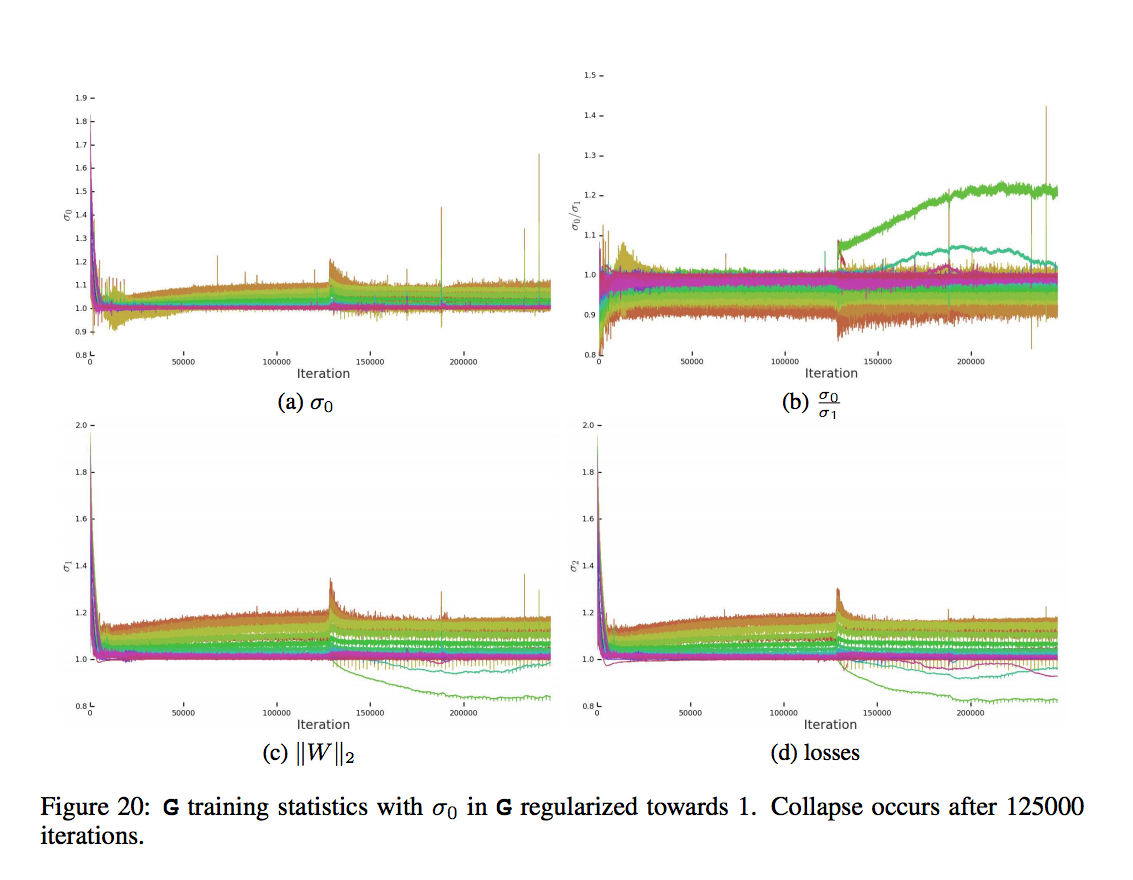
而透過這種方式可以防止爆炸,增加穩定度,
但是 GAN 的穩定並非只靠 G,
因此下方會探討 D。
分析大型GAN - Discriminator
D 從上方的表格看起來沒有什麼大問題,
但是訓練的過程中雜訊真多,
那個曲線跳來跳去的,
D 會遇到的問題是 G 會固定給他一些讓她困惑的輸入,
有時候會造成 D 的不穩定,讓他覺得自己之前是不是沒學好,
這樣gradient就會突然變很大,
而直覺上的解決這件事就是採用 gradient penalty,
避免他突然爆炸,
這招雖然能讓D變穩定, 但也會影響最終的模型分數,會降低分數。
Lars Mescheder, Andreas Geiger, and Sebastian Nowozin. Which training methods for GANs do actually converge? In ICML, 2018.
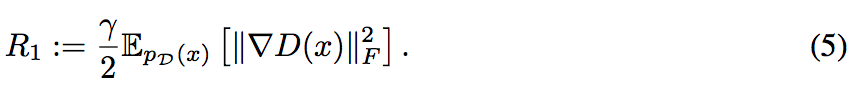
γ: 設定 10
套用後的 D
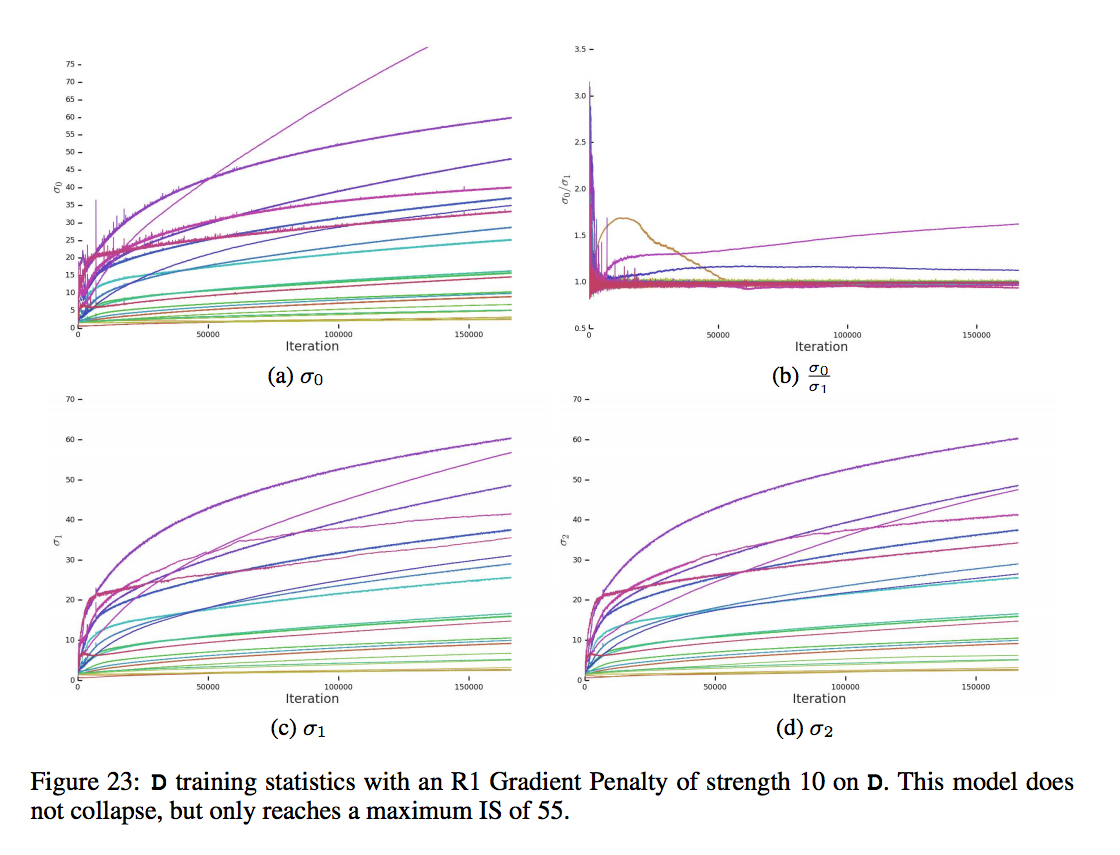
除此之外還發現有時候訓練到後來會發現 D 的 loss 將為0,
但是持續一段時間之後突然就爆炸了,
這邊給出的猜測是 D 可能是記住了 Training example 即為 overfitting,
提出將 D 拿去 ImageNet 的 training / validation data 測測看,
而這邊測試有發生 training example 準確度 98% 但是 validation set 卻只有 50 ~ 55%,
跟亂猜的沒兩樣,
這邊其實也沒給出後續的解決方法,可能不見得每次訓練都會發生這種問題吧
總結
GAN 的穩定不能僅僅依靠 G 或 D, 需要兩個相互訓練,
此文有給出讓 D 可以穩定訓練的方法,
但是它是雙面刃,可能會降低最後的分數,
儘管這篇提出了許多方法,
但是僅是降低訓練時爆炸的機率,
到後期的訓練還是有爆炸的風險,
在大型的 GAN 會在較少的步數就會有較好的結果,
可能在爆炸之前的結果或許就能夠達成很好的結果了,
如果要完全的穩定不知道那個 cost 會多大,
期待未來的發展了。
實驗結果


簡單的類別就是圖片的紋理/材質有較多共同的部分,
反之人臉就相對複雜,所以訓練的不是這麼的好。


參考資料:
OpenReview:Large Scale GAN Training for High Fidelity Natural Image Synthesis
OpenReview:Spectral Normalization for Generative Adversarial Networks