vid2vid簡介 - Video-to-Video Synthesis
Ting-Chun Wang, Ming-Yu Liu, Jun-Yan Zhu, Guilin Liu, Andrew Tao, Jan Kautz, Bryan Catanzaro. “Video-to-Video Synthesis”. In NIPS 2018.
NIPS 2018 paper
Project 主頁 : https://tcwang0509.github.io/vid2vid/
Paper Link : https://arxiv.org/abs/1808.06601
Video Link(推薦觀看) : https://www.youtube.com/watch?v=GrP_aOSXt5U&feature=youtu.be
Github code(Pytorch)) : https://github.com/NVIDIA/vid2vid

此篇我認為是 pix2pixHD 的延伸,
如果沒看過此篇的話建議去看一下,
或是看我之前寫過的pix2pixHD簡介。
Ting-Chun Wang, Ming-Yu Liu, Jun-Yan Zhu, Andrew Tao, Jan Kautz, Bryan Catanzaro, High-Resolution Image Synthesis and Semantic Manipulation with Conditional GANs. In CVPR 2018.
應用到了許多觀念
Coarse-to-fine generator
Multi-scale discriminators
Feature matching
Instance-level Feature Embedding
簡介
video-to-video 是將label(e.g. semantic segmentation)的影片轉成真實世界的影片,
可達到畫面連貫、2048 X 1024的高解析度、可調整每個物件的外觀,
對於特定的任務(街景)還可生成出30秒連續的影片,
超越了以往 video-to-video 的成果。
與其相似的問題為 Image-to-image,
但 video 更要注重的是每個 frame 之間的連貫性,
如果我們單純用image-to-image的方法來製作圖片會變成下面這樣(右上方的 pix2pixHD)
下圖擷取自 vid2vid official video

而此模型提出的解決辦法為基於 GAN 架構,
透過不同功能的 Discriminator((e.g., 確保畫面解析度,畫面是否連貫,
才能達成上方動圖(gif的右下角Ours)的成效。
基本方法
下方我們都以街道資料集(GTA5/Cityscapes)做說明。
先定義參數
T:各個時間點的圖片(per-frame) 1…T 。
S:Input labels (街道圖就是Semantic segmentation) 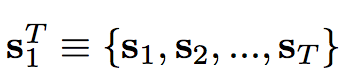
X:Ground Truth - S對應的圖片 ( X 經由 Semantic segmentation model 生成 S) 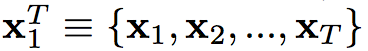
\(\widetilde{x}\) :經由vid2vid模型所生成之圖片 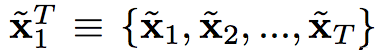

基於 s 生成 \(\widetilde{x}\),寫成數學式會像下面這樣,

而本文提出透過 GAN 讓他們的機率分佈相近,
提出 conditional GAN ((D 會加入原本 G 的 input
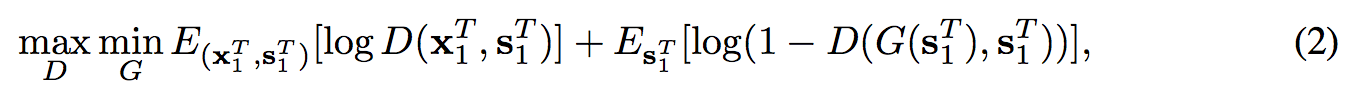
可是上方公式並沒有考慮到 frame 之間的連續關係,
所以提出 Markov assumption 透過下方的公式來定義與前 L 個frame 之間有序列關係
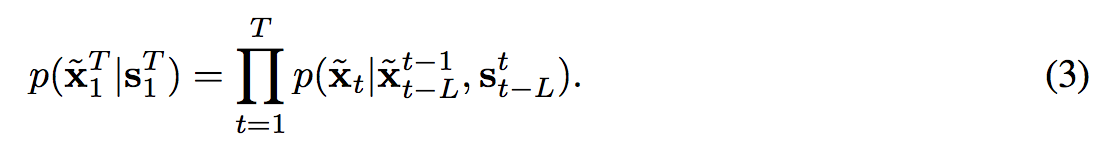
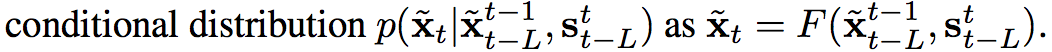
function F in a recursive manner
我們在生成圖片時會往回看 L 張圖片,
當 L = 1 只往回看一張,訓練模型時比較不穩定
本文設定 L = 2,
並且說明 L 越大訓練越久並且需要更多的 GPU memory,
但是只會改善一點點成效。
如同上面所述說的,影片在幾個 Frame 中有著極大的相關性,
我們甚至能從上一張 Frame 提取出大量相同的部分,
因此這邊提出要使用光流法來取代至下一張 Frame,
而光流法是什麼呢?
簡單來說是可以知道圖片中的每個pixel朝向哪個地方位移,
下圖轉載自FlowNet 2.0: Evolution of Optical Flow Estimation with Deep Networks
下圖的顏色代表著不同方向以及位移量。
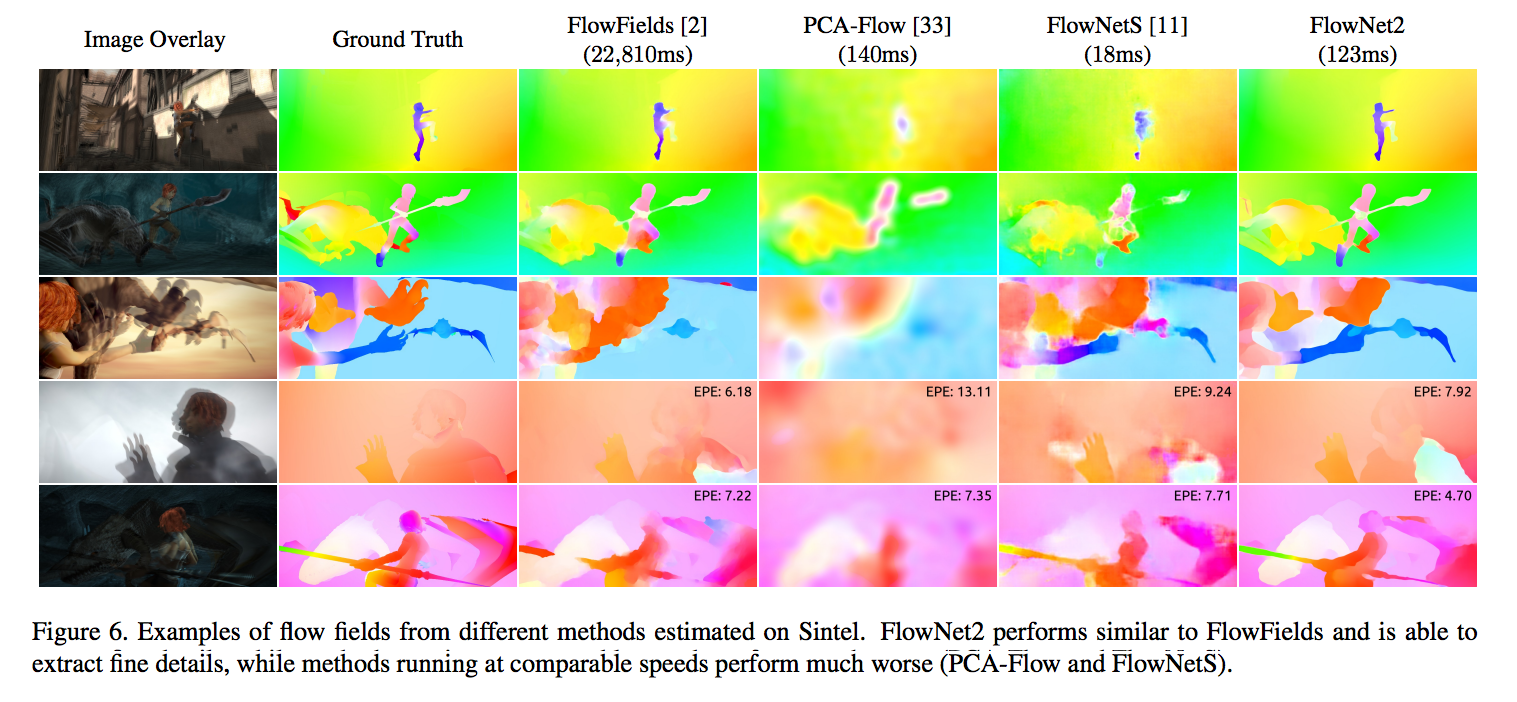

而透過這方式所得出的結果通常會正確。
因此我們的模型可以注重在空洞的地方,即為光流法對應過去後仍然為空洞的部分。
因此將剛剛的想法寫成公式會變成這樣。
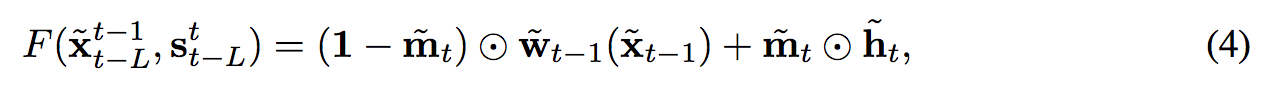
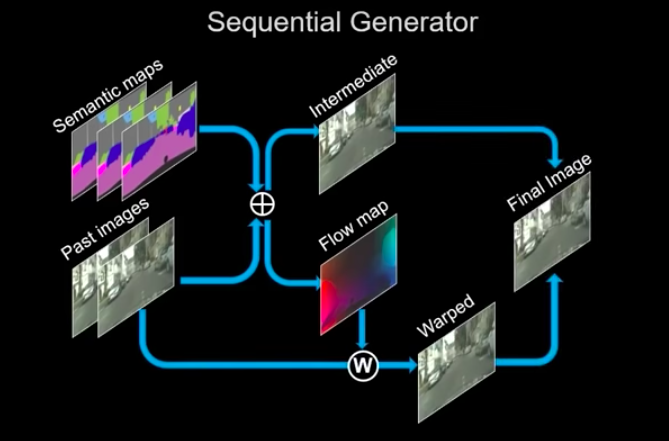
簡單介紹參數:
m: 0 ~ 1 當0的時候代表是光流法可處理的部分,反之則為須藉由我們模型輸出的圖片填補。
\(\widetilde{w}_{t-1}(\widetilde{x}_{t-1})\):給定上一張圖片再經過光流法後,產出一張新圖片,我稱作 Xb(background)
ht:模型生成的圖片,我稱作 Xf(foreground)
簡單公式說明
m 會決定每個pixel佔有多少 Xb 與 Xf,
如果 m 覺得這個pixel,經由光流法所產生的 Xb 能夠處理好的,那我們就相信他直接取代,
如果 m 覺得這個pixel,經由光流法所產生的 Xb 沒辦法處理好,我們再用我們所生成的圖片Xf填補。
原文定義:

下方為個人理解,如果有錯的話再麻煩指正:
w, m, h 都是經由 G 所產生的,
本文最後方有附上部分程式碼方便理解。
\(\widetilde{w}_{t-1}(\widetilde{x}_{t-1})\) 預測出的光流法結果
這邊挺有意思的,以往的光流法我們都是使用目前圖片 xt 與前一張圖片 xt-1 得來,
但是我們任務比較不一樣,我們的模型輸入是label(Semantic segmentation),
我們希望模型可以明白先前產生的圖片與label之間的光流法關係。
因此我們的模型是要基於 L 筆資料的 st…st-L 和 xt-1…Xt-L 來預測出光流法的結果,
至於訓練方法就是預測出來的結果與 FlowNet2.0(xt, xt-1)所輸出的光流法結果做 l1 loss。
loss function
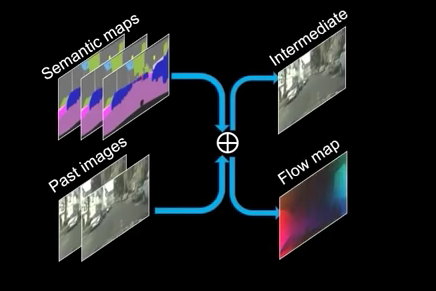
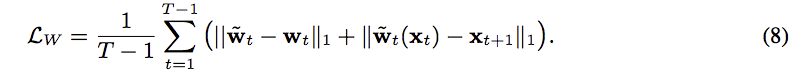
\(\widetilde{h}_{t}\) 模型所生成之結果
即為上圖 Intermediate 的部分
\(\widetilde{m}_{t}\) - mask,決定每個 pixel 要給 w 和 h 多少權重
這邊的 m: 0~1,意味著pixel有可能是由光流法和生成的圖片合成而來,
而這邊給出的說明為,當物體走遠或走近時,
其實物體是會有視覺殘影(motion blur)之類的,
為了應付這問題,才讓 mask 為 0~1 之間。
BTW,
我當初看到這個 m 的時候,
就在想說其實從 w 轉換過後的結果就能夠拿到 m 了,
為什麼還要特地訓練出一個 m,
後來再看論文和code才理解到要達到 motion blur 的效果。
Discriminator
Conditional image discriminator - DI
讓 Discriminator 可以辨別是自己生成的還是Ground truth,
conditional gan 因此 D 也會輸入原本 G 的輸入(label)
輸入 label 以及 圖片(Ground / 自己生成的)

輸入 (xt, st) 輸出 1
輸入 (\(\widetilde{x}t\), st) 輸出 0
loss function \(L_{i}\):
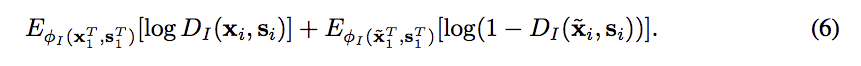
Conditional video discriminator - DV
DV 注意的是生成的 Frame 之間是否有連貫,
透過給定生成的圖片以及光流法 w 的輸出。
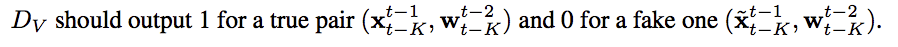
直接看圖片最能理解,
trick 是可以挑不連續的圖片,會學得更好。

因為影片通常 1 秒鐘 30 frames,
所以間隔多一點也是合理的。
loss function \(L_{v}\):
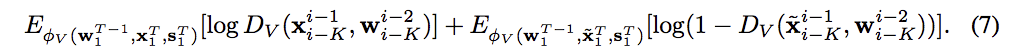
objective function
最基本的如下:
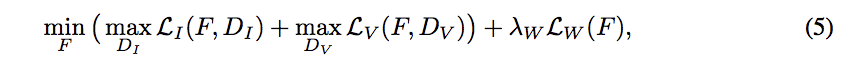
參數:λw 設定為10, Lw可往上看到光流法那部分。
後續還會介紹幾個loss,所以objective function還會更複雜
- discriminator feature matching loss
- VGG feature matching loss
更多的trick
Foreground-background prior
因為我們是輸入label,如街景的資料集有著馬路、建築物、人物、車輛等等。
而對於人物、車輛這種在圖片中相對小,並且移動幅度較大的物體我們應該要分開處理,
因為對於這種物體用光流法其實無法準確測量,
因此提出前景與後景需要分開做,

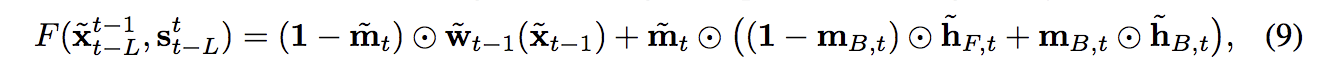
\(m_{B,t}\)是從輸入的 S 直接提取背景的 mask
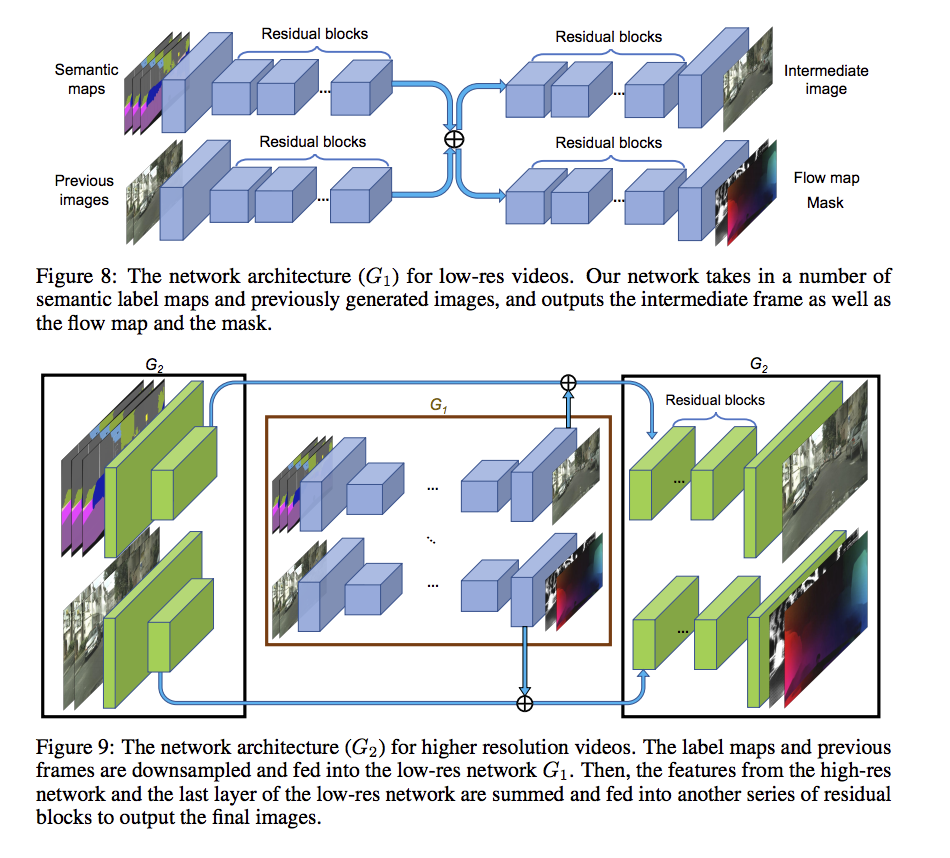
Coarse-to-fine generator(Multi-scale discriminator)
pix2pixHD coarse to fine 的概念,
細節可去看pix2pixHD
會訓練多個 discriminator
分別處理 512X256 、 1024X512 、 2048X1024

Multimodal synthesis
可以讓調整生成影片的物件
請去看pix2pixHD

Feature matching loss
請去看pix2pixHD
實驗細節
訓練40個epochs,
ADAM optimizer with lr = 0.0002 and (β1, β2) =(0.5, 0.999)
LSGAN loss
使用DGX1 (8 V100 GPUs, each with 16GB memory)
4個GPU訓練G,4個GPU訓練D。
訓練10天才將2K解析度的vid2vid訓練完。
資料集(簡單帶過)
此模型雖然厲害,但是要訓練也不是這麼的方便,因為我們要有一個輸入labels的輸入影片,
下圖轉載自GTA5 dataset

因此此 Model 訓練方式會依照不同的任務做調整,
Cityscapes:
使用Deeplabv3 取得 Semantic segmentation label,
並且使用 FlowNet2 做光流法的訓練,
使用Mask R-CNN訓練instance segmentation。
Apolloscape:相似Cityscapes
Face video dataset:
使用 Dlib 切出人臉的landmark
Dance video dataset:
pose 分割會使用 DensePose / Openpose
實驗結果


Trace code - 對於光流法部分 W, M
為了方便各位 trace code 我貼出幾段我看到比較關鍵的部分,
請注意註解處有行號 L,只貼出一些我覺得重要的,
如果還是不懂的可以去看原始的程式碼,挺複雜的呢。
https://github.com/NVIDIA/vid2vid/blob/master/train.py
real_B_prev, real_B = real_Bp[:, :-1], real_Bp[:, 1:] # L:108 the collection of previous and current real frames
# 用下方這個去當 L1 loss 去訓練 G 的 w 部分
flow_ref, conf_ref = flowNet(real_B, real_B_prev) # L:112 reference flows and confidences
https://github.com/NVIDIA/vid2vid/blob/master/models/flownet.py
# resample 看作將原有圖片經過光流法轉換後的新圖片
def compute_flow_and_conf(self, im1, im2): #L:38
flow1 = self.flowNet(data1) #L:50
conf = (self.norm(im1 - self.resample(im2, flow1)) < 0.02).float() #L:51
def norm(self, t): #L:57
return torch.sum(t*t, dim=1, keepdim=True) #L:58
def forward(self, scale_T, tensors_list): #L:144
real_B, fake_B, fake_B_raw, real_A, real_B_prev, fake_B_prev, flow, weight, flow_ref, conf_ref = tensors_list
################### Flow loss #################
if flow is not None:
# similar to flownet flow
loss_F_Flow = self.criterionFlow(flow, flow_ref, conf_ref) * lambda_F / (2 ** (scale_S-1))
# warped prev image should be close to current image
real_B_warp = self.resample(real_B_prev, flow)
loss_F_Warp = self.criterionFlow(real_B_warp, real_B, conf_ref) * lambda_T
################## weight loss ##################
loss_W = torch.zeros_like(weight)
if self.opt.no_first_img:
dummy0 = torch.zeros_like(weight)
loss_W = self.criterionFlow(weight, dummy0, conf_ref)
else:
loss_F_Flow = loss_F_Warp = loss_W = torch.zeros_like(conf_ref)
### Warp loss
fake_B_warp_ref = self.resample(fake_B_prev, flow_ref)
loss_G_Warp = self.criterionWarp(fake_B, fake_B_warp_ref.detach(), conf_ref) * lambda_T
參考資料:
FlowNet 2.0: Evolution of Optical Flow Estimation with Deep Networks