CFENet簡介 - An Accurate and Efficient Single-Shot Object Detector for Autonomous Driving
Qijie Zhao, Tao Sheng, Yongtao Wang, Feng Ni, Ling Cai. “CFENet: An Accurate and Efficient Single-Shot Object Detector for Autonomous Driving”. In ACCV 2018.
ACCV 2018 paper, CVPR2018 - Workshop of Autonomous Driving (WAD)
Paper Link : https://arxiv.org/abs/1806.09790
Github code(Pytorch) : https://github.com/qijiezhao/CFENet/tree/working
P.S. 他的程式碼並不放在master,而是放在working的分支
前言:其實我是看到 AAAI’19 他們團隊提出的 M2Det 才先看來這篇的。
簡介
此團隊參加 CVPR2018, Workshop of Autonomous Driving (WAD) => Berkeley DeepDrive(BDD) Road Object Detection challenge 獲得第2名的佳績,
下圖轉載自 Berkeley Deep Drive
此論文提出如何有效率的偵測出小型的物體,
在道路物件偵測任務中,
我們可以從下圖右方的統計圖表可得知:交通號誌和紅綠燈通常在圖片中只會有很小的一部分。
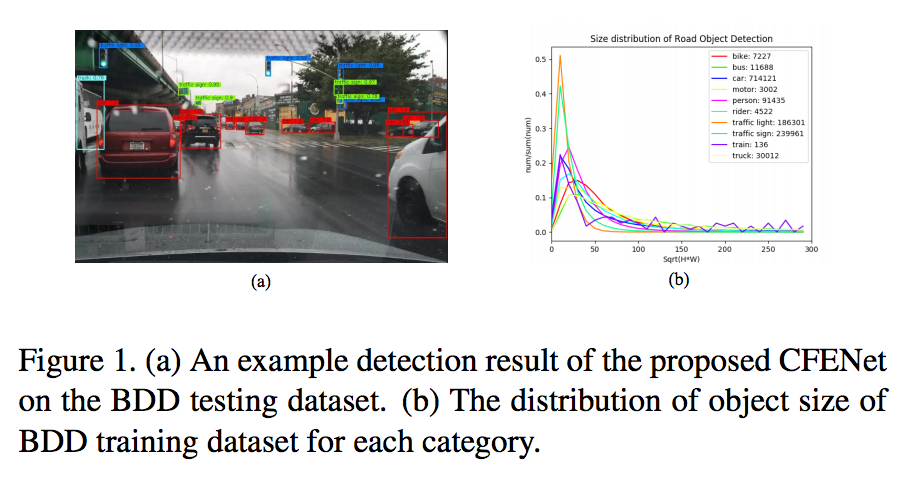
但是交通號誌/紅綠燈卻也是很重要的,
因為在無人車的行進之間交通號誌是會影響到決策的,
越早知道當然越好,
因此提出在道路資料集中處理小物件的偵測是相當重要的。
此文提出 CFENet (Comprehensive Feature Enhancement module) 的物件偵測模型,
可達到 21 fps的效能。
前導概念
此文主要有著著兩個原則
- 偵測小物件:如果我們能夠看到遠方的物體的話,可以讓無人車提早反應並且避免危險。
- 運算要快:畢竟是要用於自駕車。
此文是將 SSD 的物件偵測方法做改進。
備註:
因 SSD 網路是 One-stage 因此運行速度較快,使用 Titan XP 可達到 20 FPS。
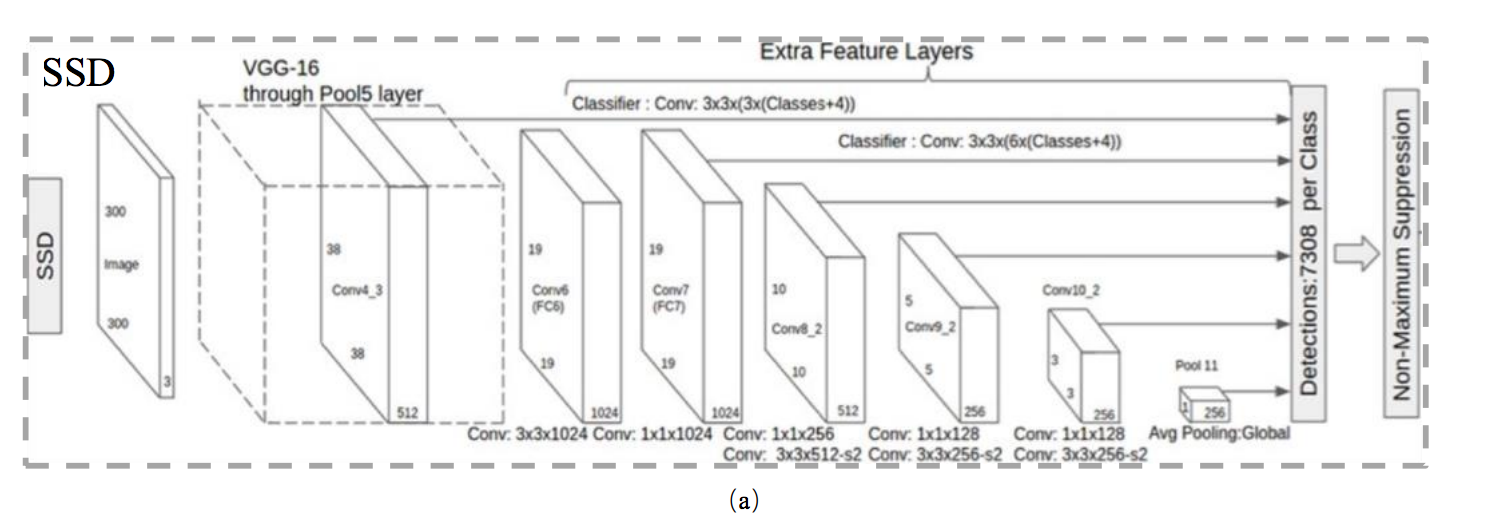
此文認為 SSD 之所以無法處理好小型的物體,
其無法處理好的原因是 backbone(假設為VGG16) 的 Conv4_3 部分,
其解析出來的特徵還不足以讓模型可以準確的預測,
簡單來說就是 Conv4_3 之後接預測層(predict layer) 效果之所以不好,
是因為其網路太淺,
因此得到的特徵還太粗糙,
不利於預測。
備註:
網路越深通常是監測更大的物體,因為通常每過一層就會有 stride 或是 pooling,
因此如果要檢測最小的物體就是憑藉著前面的 feature maps。
那這問題怎麼解決呢?
最簡單的想法可能是把 backbone vgg16 換成其他比較深層的網路 resnet-101之類的,
但是這意味著我們的運算時間會增加,
會影響fps,
而導致無法應用在無人車這種需要即時運算的應用上。
方法
此文提出的架構如下,
紅框為此模型基於 SSD 後所新增的部分。
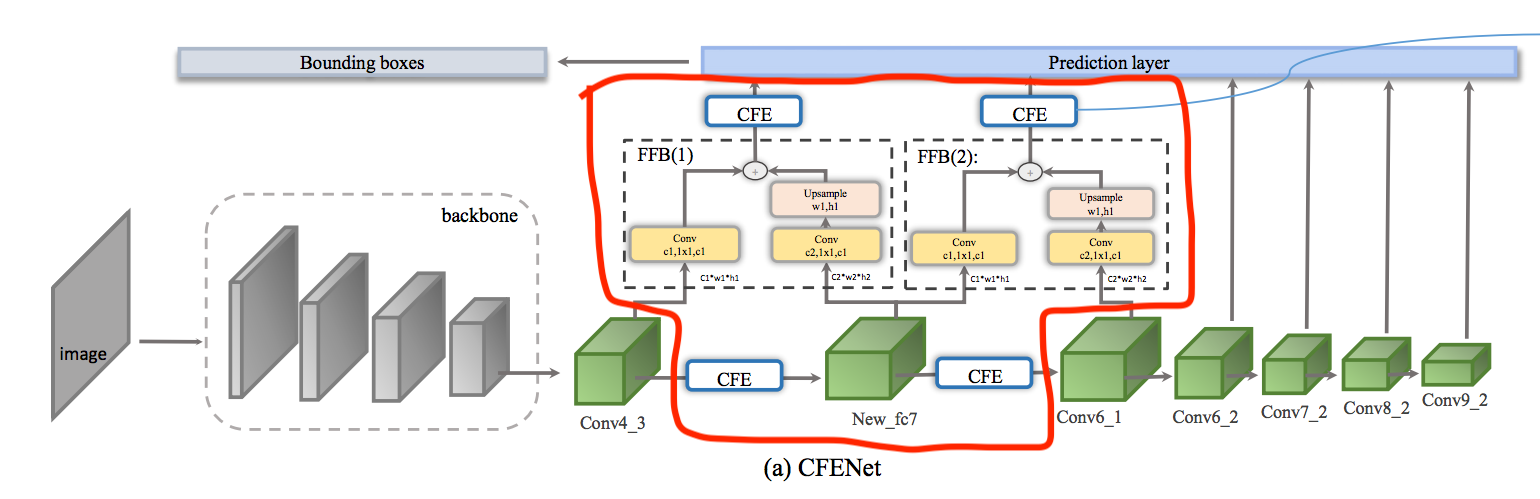
- 1 個 fully convolutional layer (New_fc7)
- 4 個 Comprehensive Feature Enhancement(CFE) module
- 2 個 Fusion Blocks(FFB) module
CFE(Comprehensive Feature Enhancement module)
先前得出的問題點:Conv4_3太淺,特徵不足以用來辨認小物體。
最簡單的想法來解決小物體偵測就是網路變深((在沒有使用 Stride/pooling的前提下加深,
這方法可以讓模型學會更細節的特徵 feature,
因為他又多了一些非線性(non-linear)的函數,
所以輸出的 Features 會更複雜,
能幫助模型預測,
因此提出下方架構:
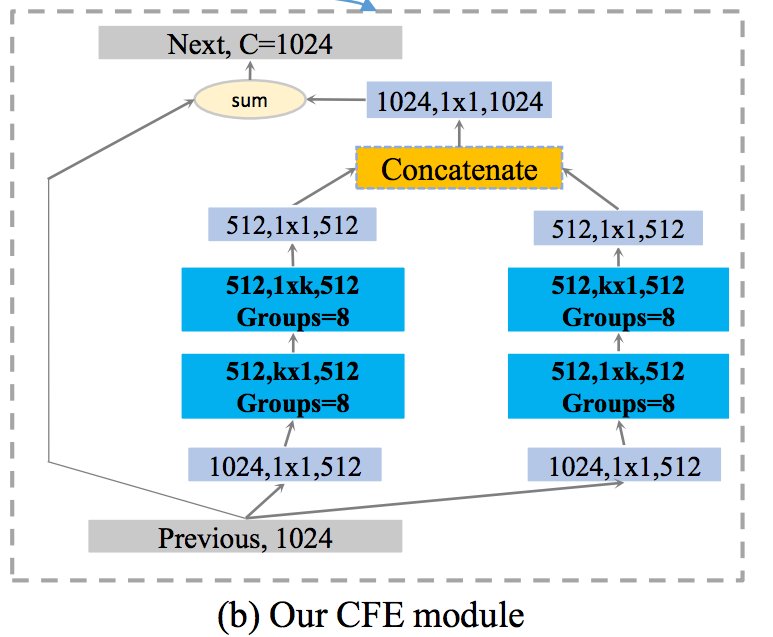
這邊的想法是希望透過 k X K 的 Conv 讓 feature 能夠有更大的感知視野(receptive field),
備註:
這邊的 k 設定為 7。
但是如果我們使用 k X k 的 kernel-size 又會增加龐大的運算量,
因此這邊使用對稱架構(淺藍色部分)的運算,
透過對稱的(1xk + kx1)可組成類似 k X k Conv 的效果,
他的優點是比起運算 k x k 的大小,
用這種替代方法能夠讓運算速度變快。
此方法的出處:
CVPR2017 - Large Kernel Matters - Improve Semantic Segmentation by Global Convolutional Network
在其論文中使用 Global Convolutional Network(GCN) 來介紹此模組。
除了淺藍色的 1 x k, k x 1 之外,
此模型還有提到另一個技巧 Groups 可增加準確率,
此方法的出處:
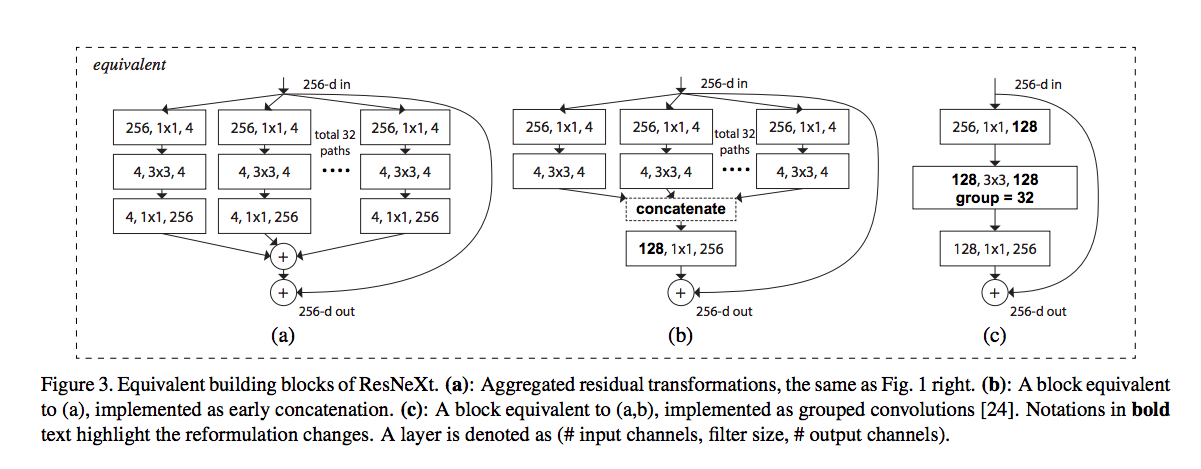
CVPR2017 - ResNeXt Aggregated Residual Transformations for Deep Neural Networks
下圖出自ResNext,可看下圖大概能明白其概念吧!? 下面三個架構是相等的,在該論文有詳細的比較,有興趣能去看看。
FFB(Fusion Blocks)
這部分就是將兩個不同層的 feature maps 合併起來,
這樣可以提供更多的資訊用以幫助 prediction layer。
此處的想法來源
FCN,其最後的多維度的串接。
U-Net,維度的拼接。
主要注意兩個 feature maps 的 H X W 要相同就好了,
所以才會有 Upsample 的那個步驟。
架構總覽
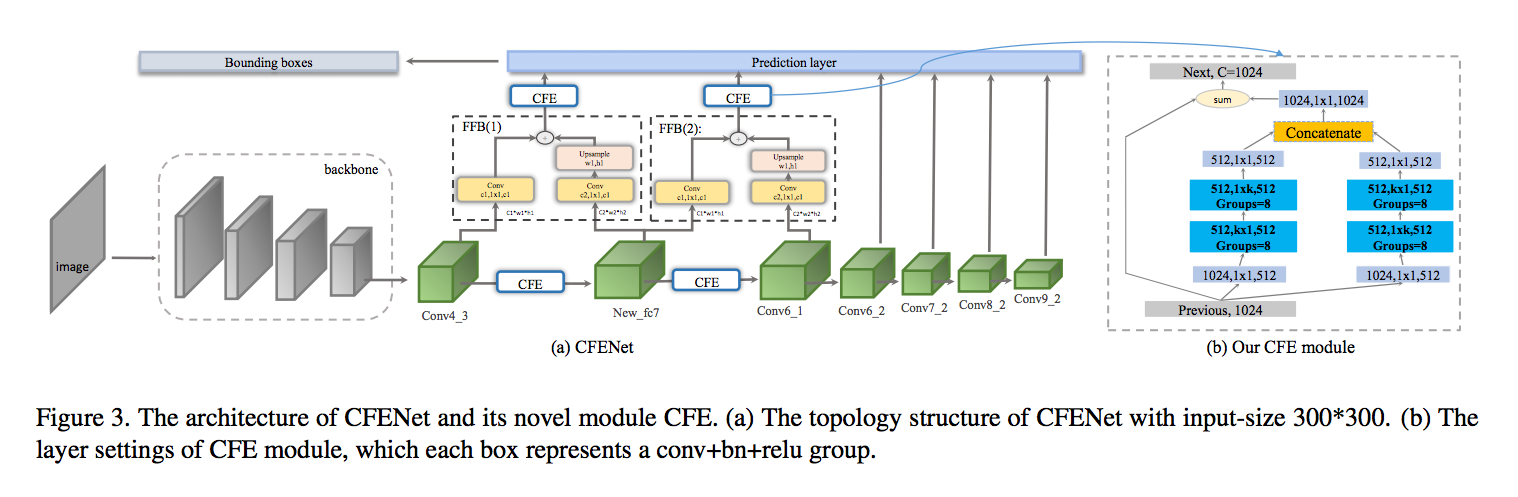
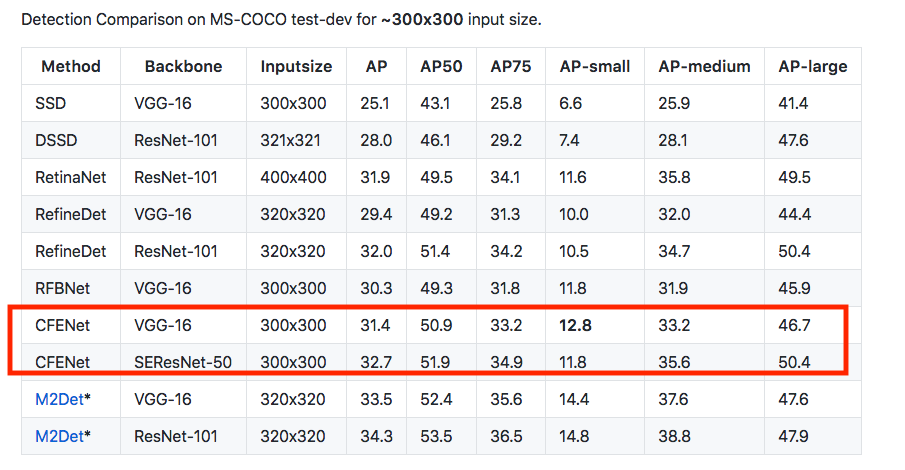
實驗部分
在 MSCOCO 以及 Berkeley DeepDrive(BDD) 的資料集上做實驗,
在各個尺度(S / M / L)的準確度都不錯。
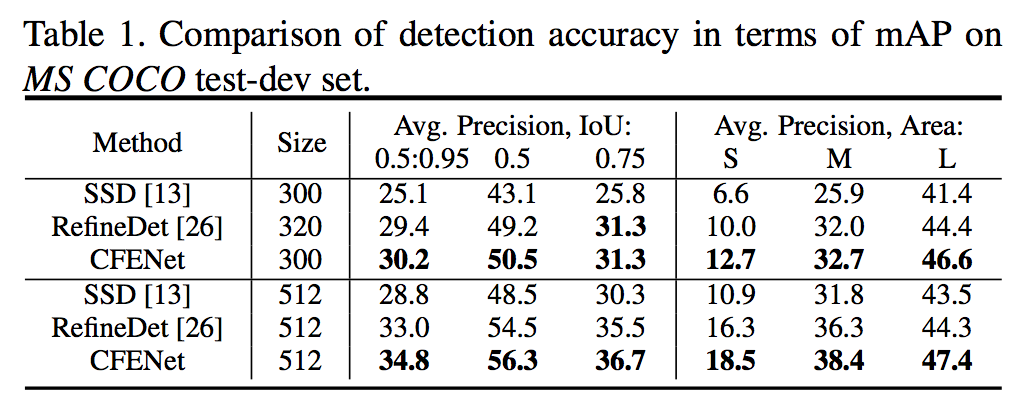
Ablation study
下圖參數定義
T: 上方(淺藍色那個部分)
B: 下方 (Conv4_3 -> New_fc7 -> Conv6_1)
Incep(T) : 使用 Inception v3 的架構
CFE(T) : 上半部使用2個 CFE 的架構
CFE(B) : 下半部半部使用2個 CFE 的架構
FFB : CFE(T)之前接的 FFB 架構

準確度贏 RefineDet,但是速度小輸 RefineDet。
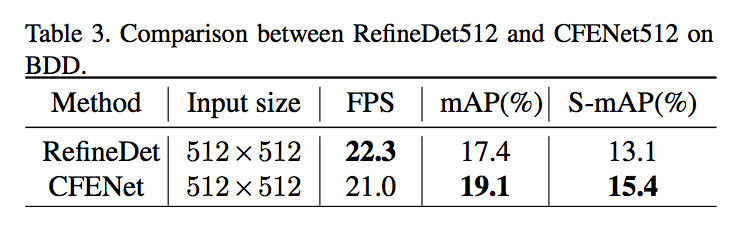
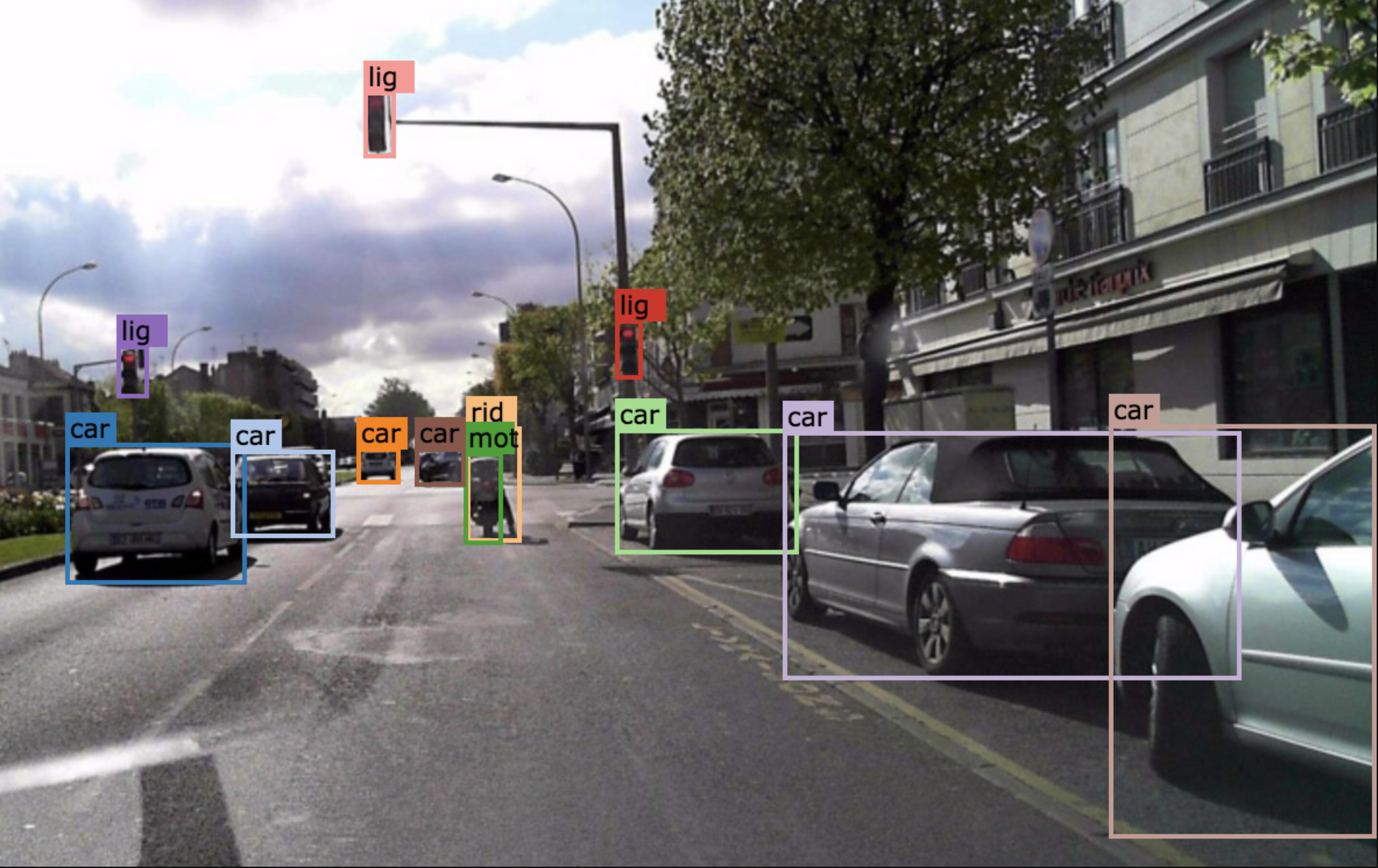
成果圖

參考資料:
CFENet: An Accurate and Efficient Single-Shot Object Detector for Autonomous Driving
Large Kernel Matters - Improve Semantic Segmentation by Global Convolutional Network
Aggregated Residual Transformations for Deep Neural Networks