M2Det簡介 - A Single-Shot Object Detector based on Multi-Level Feature Pyramid Network
QQijie Zhao, Tao Sheng, Yongtao Wang, Zhi Tang, Ying Chen, Ling Cai, Haibin Ling. “M2Det: A Single-Shot Object Detector based on Multi-Level Feature Pyramid Network”. In AAAI 2019.
AAAI 2019 paper
Paper Link : https://arxiv.org/abs/1811.04533
Github code : https://github.com/qijiezhao/M2Det
P.S. 寫稿日 - 2018.11.20 目前只放readme,作者說會釋出程式碼
因沒有程式碼可對照再加上這架構有點複雜,有可能會有理解錯誤的部分,如果有人有注意到的話再麻煩提醒。
簡介
此團隊在 CVPR2018 參加 Workshop of Autonomous Driving (WAD) 「道路物件偵測的任務」提出過一個 CFENet 的架構,
而當時的 CFENet 的論文被 ACCV 2018 接收,
CFENet是針對小物體準確度的優化。
而這次提出的 M2Det 主要的想法是 Multi-Level Feature Pyramid Network(MLFPN),
和當時提的 CFENet 有部分的想法相似,
在兩篇論文都提出了:物件分類的和物件偵測的問題有點矛盾,
基於上述的想法此論文給出了較為全面的解釋,
並且提出應該要使用淺層(Low-level)的特徵來輔助物件偵測任務,
因為深層(High-level)的特徵往往會偏好學習最具辨別力的特徵,
而最具辨別力的特徵不見得能將整個將物件給框選起來。
整個想法是採用 SSD 的架構作延伸,
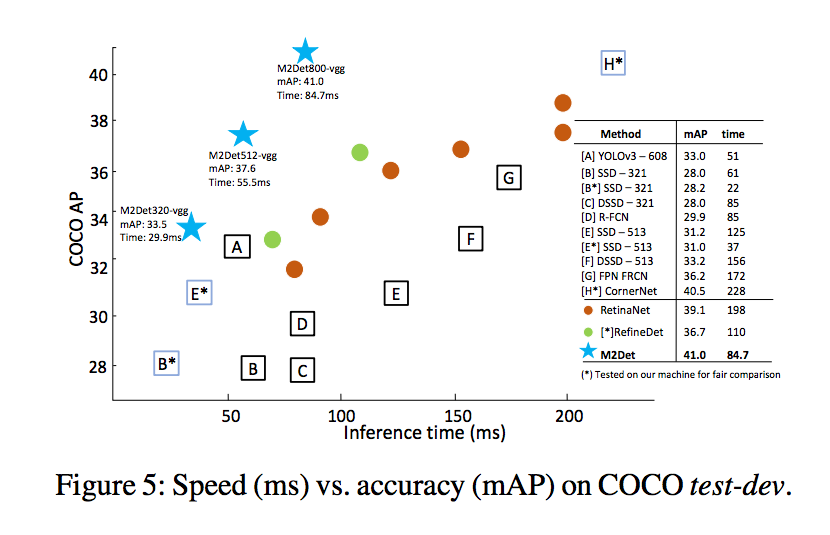
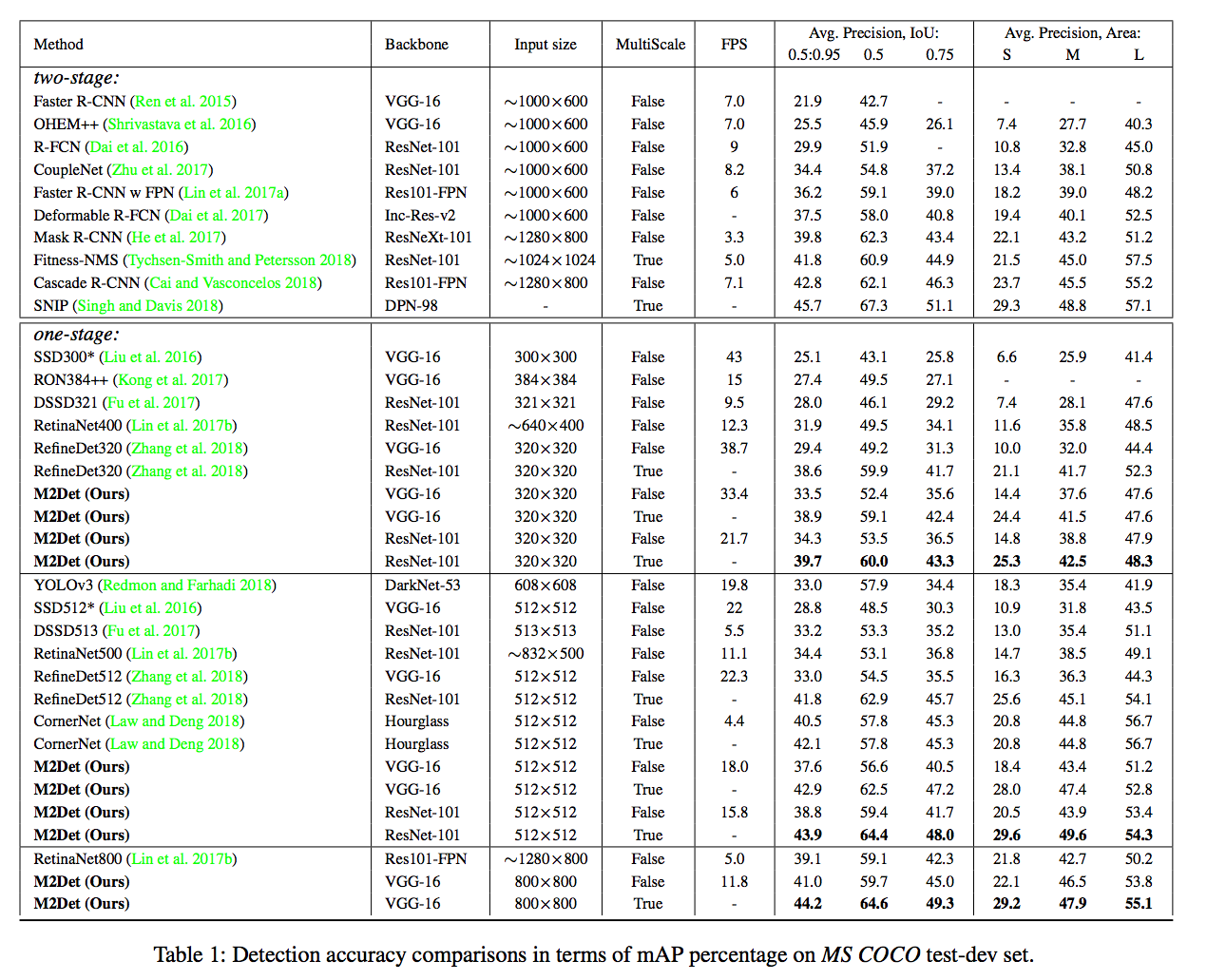
提出的 M2Det 若採用 single-scale inference 可達到 11 FPS, AP 41 的準確度,
採用 multi-scale inference 可達到 AP 44.2 的準確度。
概念
物件分類的和物件偵測的任務是有點矛盾的,
如果我們將物件分類的模型可視化,
我們往往會發現模型會專注於一些可辨認的點,
如辨認鳥的話,他會集中在翅膀的部分
但是我們的物件偵測的目標是希望把目標的位置框出來
因此我們不只需要最能夠辨別物體的那個點,
我們還要想辦法把主體框出來。
可看下圖想像一下:
CVPR2017 - Large Kernel Matters - Improve Semantic Segmentation by Global Convolutional Network
在上圖可看到這是一個多尺度的問題,
當圖片放大時(中間那張圖),那個白色的感知視野(valid receptive field - VRF)無法有效的框出鳥的部分。

我們看一下 SSD 的架構,
典型的 Feature pyramid 金字塔架構,
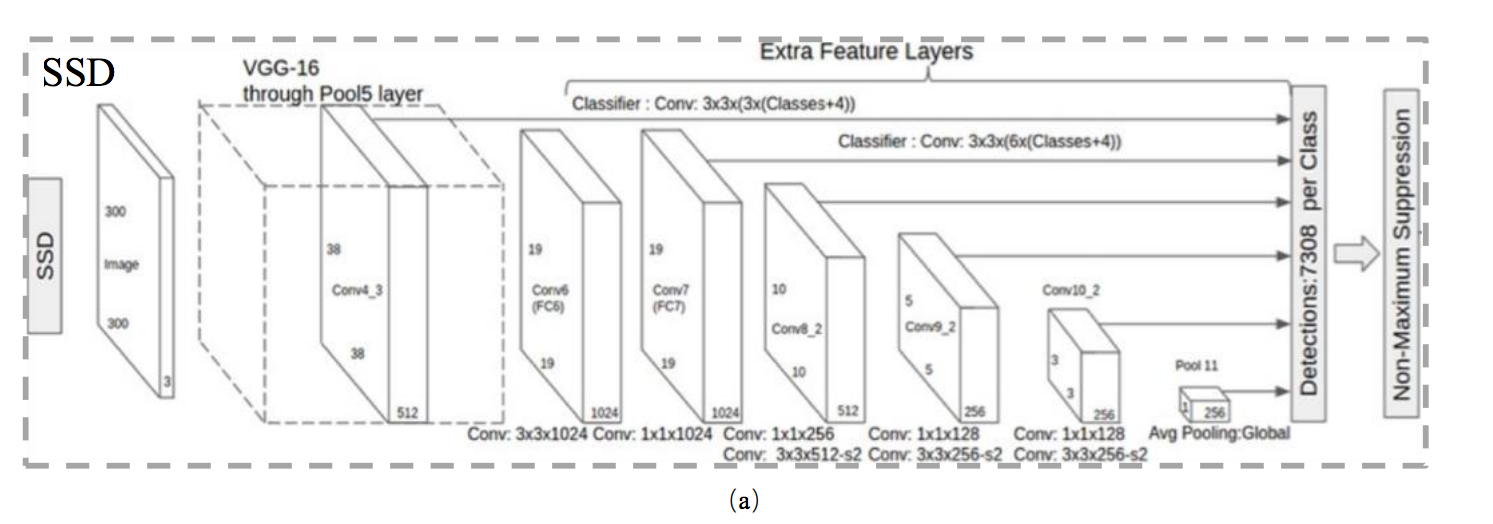
我們可以看到他的架構是基於 VGG 16 的最後一層(Conv4_3)以及幾個額外的 layer(Fc6 … Poll 11)去做預測,
而為什麼只選擇Conv4_3這層而不是前面幾層呢?
通常的考量是深層的網路中會有者較複雜的特徵,
用深層的資料(High-level)會對預測較有幫助,
而淺層的資料(Low-level)往往是簡單的特徵 ((如簡單的紋路、顏色、形狀,
所以通常是使用深層的資料做預測((在 VGG 以及 ResNet 的模型中是這樣的。
P.S.
時代在變,我說的通常你都可以隨便看看不用太認真,每年電腦視覺(CV)領域都在進步。。。
寫到這裡莫名的心虛一下。。。
此論文的論點是高階的特徵(High-level)是有助於我們分類的問題,
但是對於物件識別的部分(將物體框出來)使用低階的特徵(Low-level)是會有幫助的。
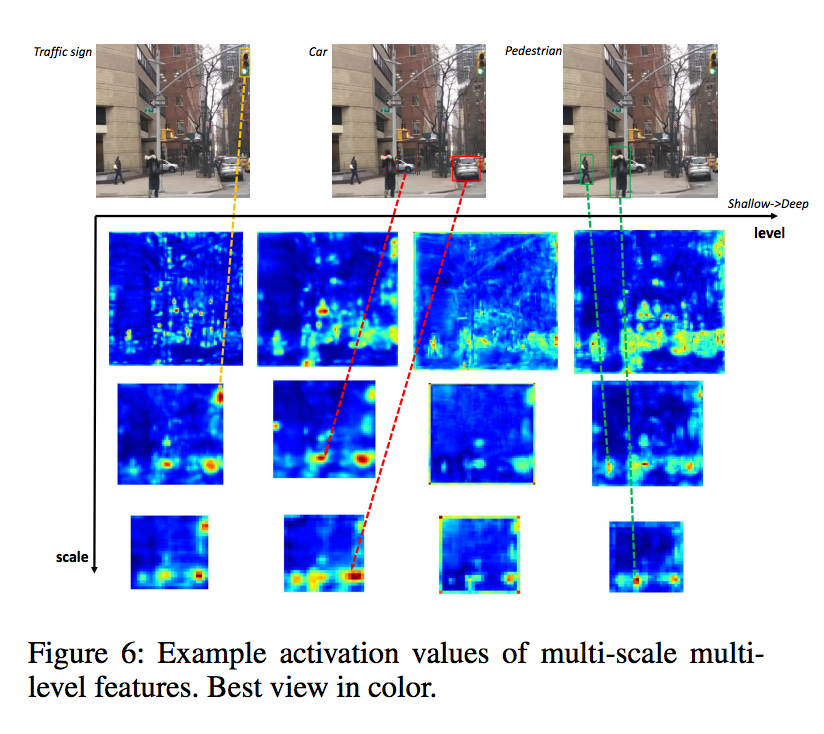
舉例來說一張圖片有人和紅綠燈,
因為這兩個物件的紋理、形狀或是大小(紅綠燈在一整張圖片中可能都是只占據很小一塊)其實都差很多,
若是只使用 High-level 的特徵可能只能夠框出最能夠辨別的點,
可能沒辦法包覆著整個物體,
但如果採用 Low-level 的特徵反而容易將那整個物體給框出來。
方法
此文提出的架構如下,
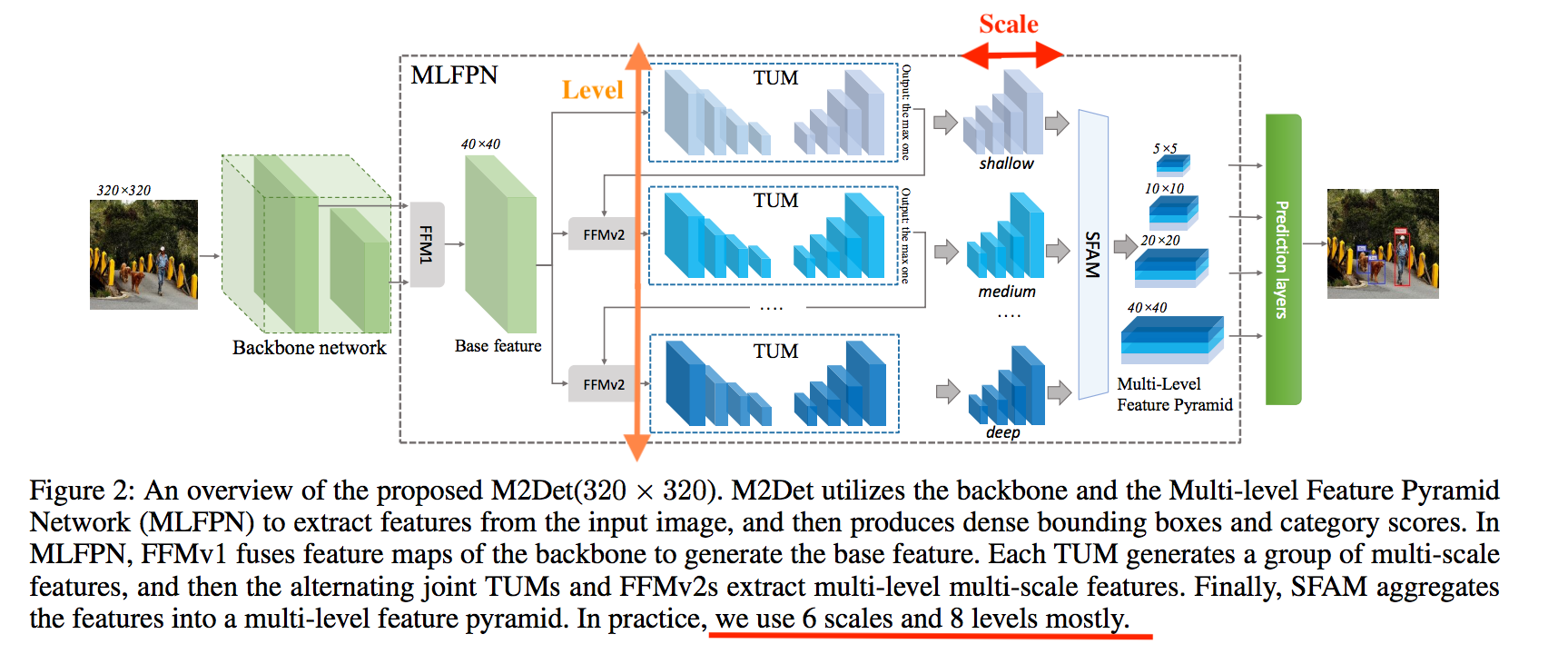
這邊要知道的是
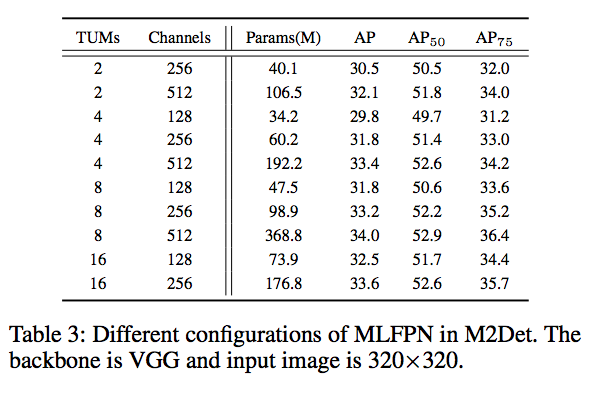
- Level: TUM 個數,實驗設定為8個
- Scale: TUM 的輸出層個數,實驗設定為6個
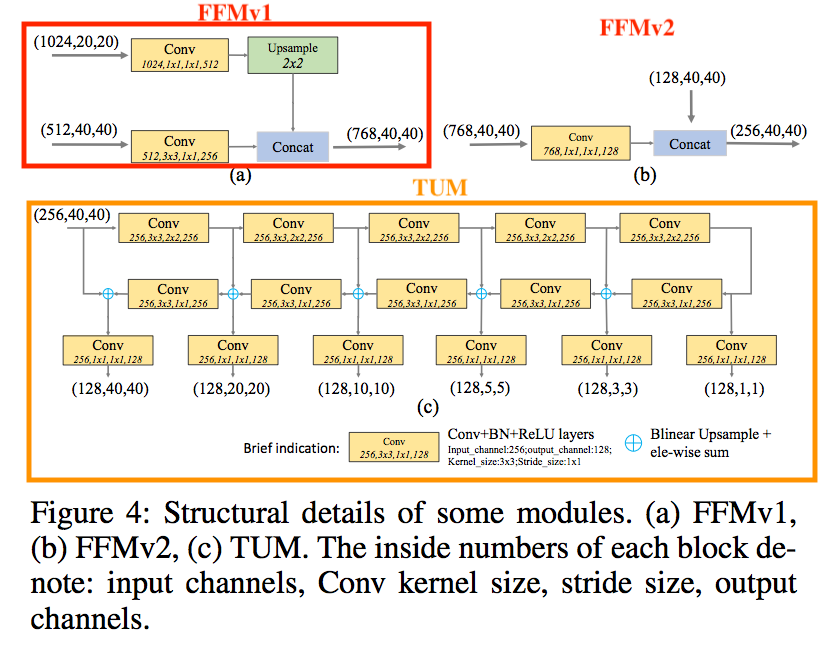
如何利用淺層資料 - Base feature
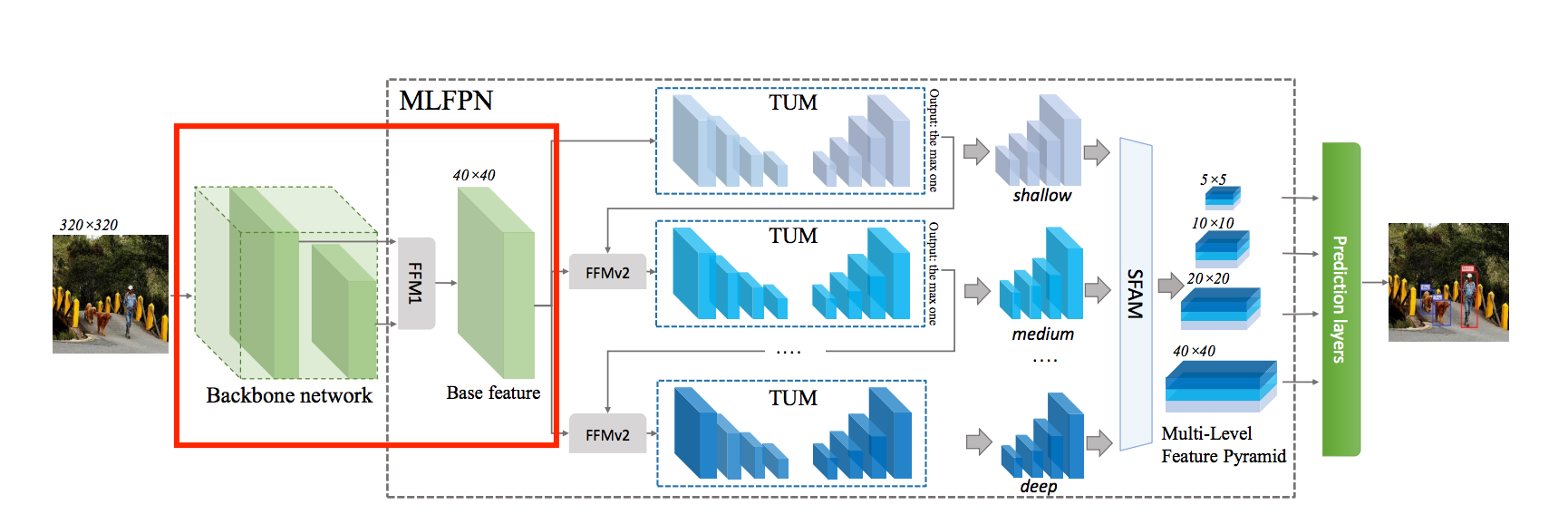
請看模型架構圖的 FFMv1,
它的作法很簡單就將前面的 Feature maps 結合起來,
在 VGG 當作 Backbone 時是使用 conv4_3 和 conv5_3,
這樣我們的 Base feature 就會有深層和淺層的特徵。
實作的部分只要注意兩個 H x W 相同就好,
所以如果維度不一樣要加入 UpSample,
其實也挺常見的拉,
所以不多作解釋。
FFM(Feature Fusion Module)
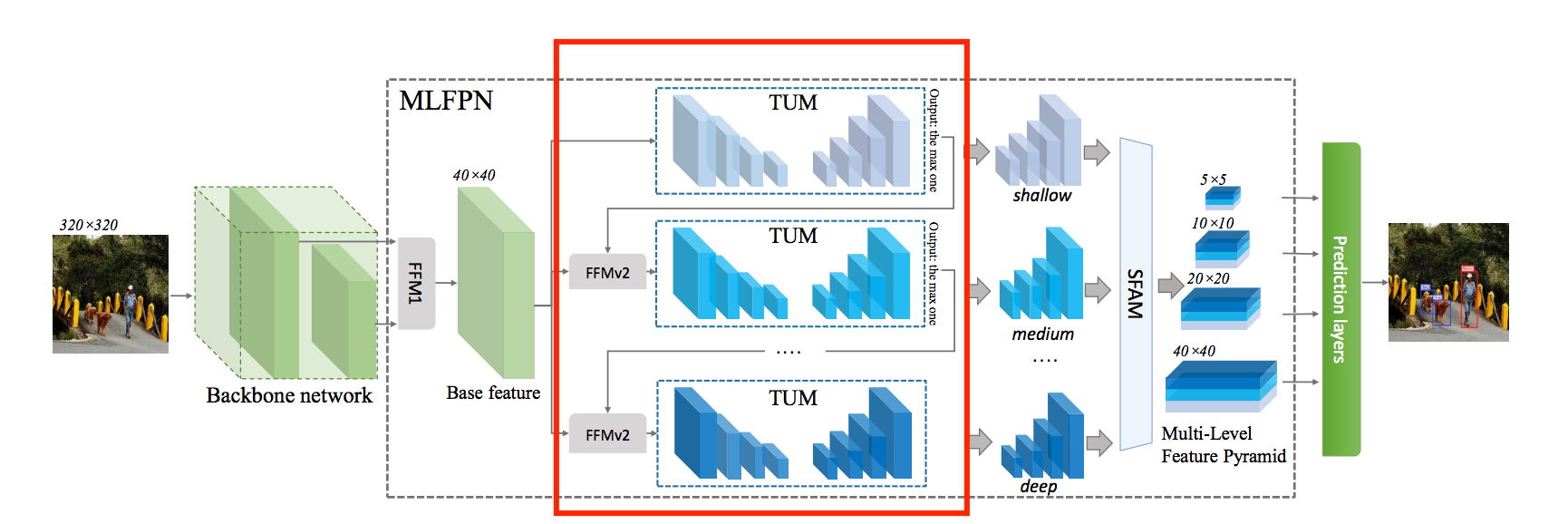
模型細節請看模型架構圖的 FFMv2
這部分就是將兩個不同層的 feature maps 合併起來,
和上面想法差不多,
只是我們接入 Base-Feature 結合上一個 TUM 最後一層輸出,
這邊值得注意的地方應該是我們重複使用了 Base-Feature,
這意味著我們每次輸入進 TUM 的模組時,
都有看到 Backbone 的 low-level 和 high-level 的特徵。
數學式如下:
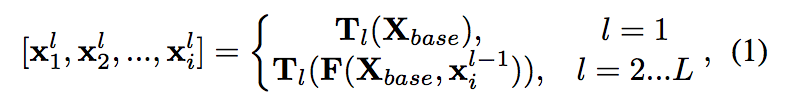
TUM(Thinned U-shape Module)
就是縮減版的 U-net,
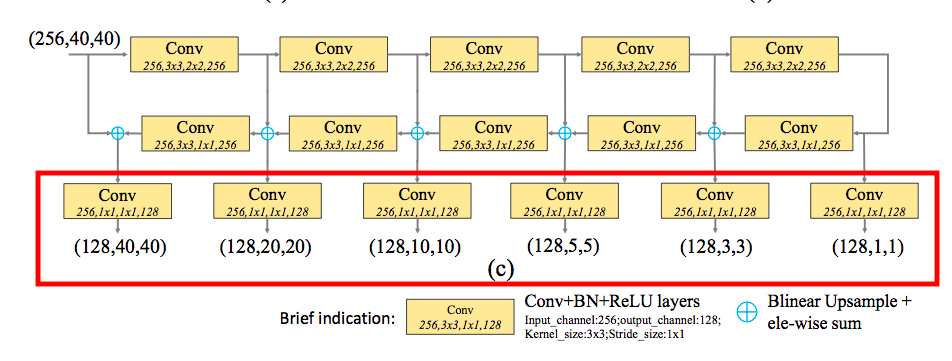
而他縮減版的部分應該是指他每層channel數只有256,
給出的理由是這樣比較容易於 GPU 訓練,
我的想法是單純是 GPU 記憶體大小的限制,
因為我們架構有8個 TUM ,
當每個 U-net 都用這麼大的維度的話,
可能會有記憶體上的問題。
比較特別的是他的每層都有 Decoder,
為上面架構圖紅框處,
他這有6個輸出 => Scale = 6,
而這6個輸出分別代表著不同維度的特徵,
可以注意一下他們每層的 H X W,
從 1X1 … 40X40。
在論文的 Discussion 的部分有提到,
透過 TUM 產生的這些輸出因為是使用相對更深的網路,
因此能學到更複雜的特徵,
而透過 TUM 有不同尺度的輸出,
我們可以處理好多尺度的問題,
那再將 TUM 的輸出接到下一個 TUM 的輸入,
那下一個 TUM 就可以基於上一個複雜的特徵再往下去做學習。
透過這種方式可能第1個 TUM 的 40x40 的特徵可能只能應付簡單的部分,
但直到接到第8個 TUM ,
即便是 40x40 的特徵也能夠處理相對複雜的部分了。
SFAM(Scale-wise Feature Aggregation Module)
看到這邊我們要先理解本文的 Multi-Level Feature Pyramid Network(MLFPN),
- Multi-level : 多個 TUM,定義為 L 個。
- Multi-scale : 多個 U-net 的輸出層,對每個不同尺度(1x1…40x40)的輸出定義為 i。
所以我們每個尺度的輸出 Xi 其實有從 L 個,
因為每個 TUM 都可以產出相同尺度的 i(1x1…40x40)。
那這邊的 SFAM 就是為了處理 L 個 不同尺度的 i - Feature maps,
然後再將處理完的 i 輸出至 prediction layer。
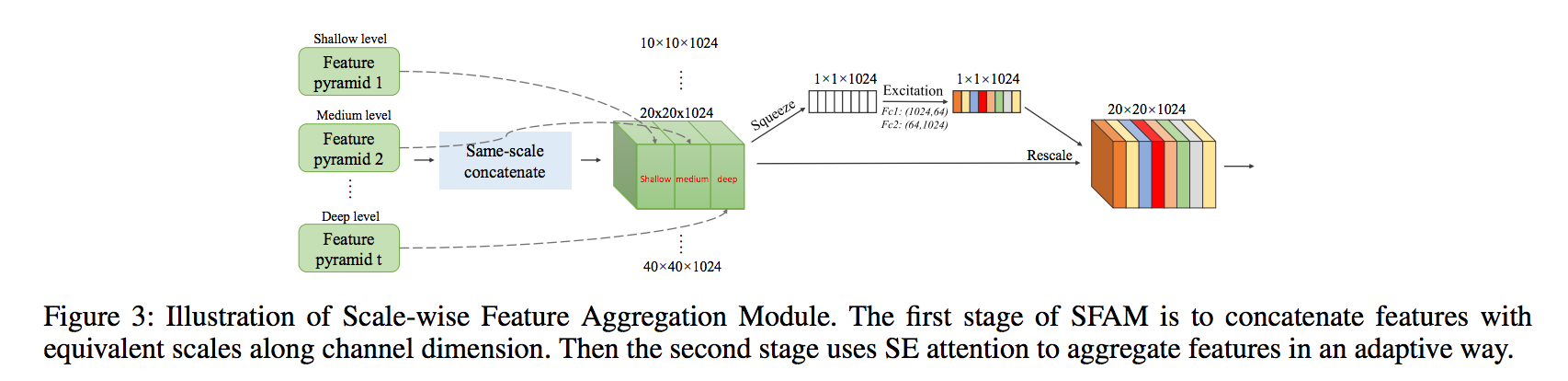
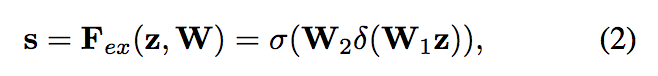
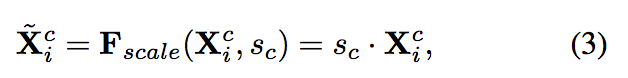
此處架構是採用 CVPR 2018 的 Squeeze-and-Excitation Networks-(SENet),
簡單來說是透過 Fully-connected layer 來學習每個 feature 應該要給多少權重,
這部分細節可以去看 SENet 那篇論文。
最終 prediction layer 會接受的是 i 個不同尺度的 Feature maps,
而每個 Feature maps 有多少的權重是經由此 SFAM 所給定,
我目前的理解是 SFAM 其實就是有 i 個 SENet。
這時候大概就能夠理解這模組為什麼叫SFAM(Scale-wise Feature Aggregation Module)了吧!?
備註(下方為個人理解,沒程式碼沒辦法肯定):
雖然圖片上是寫 10 X 10 X 1024 ~ 40 X 40 X 1024,
不過我覺得可能只是示意圖,
實際上實驗設定應該是 6 個 scale,
從 1x1 … 40x40 可見 TUM 的架構圖。
而最大張的架構圖它上面雖然畫 5x5 … 40x40 但應該也是從 1x1 … 40x40才對吧!?
實驗部分+成果
在 MSCOCO 的資料集上做實驗,
backbones pre-trained on ImageNet.
訓練 320x320 以及 512x512 的圖片時,使用4張 Titan X 訓練,
訓練 800x800 的圖片時,使用NVIDIA Tesla V100訓練,
此論文的實驗做的挺多的,
並且有一些細節部分,
所以呢 Ablation study 就不提了,
有興趣的自己去看那部份的細節。
參考資料:
M2Det: A Single-Shot Object Detector based on Multi-Level Feature Pyramid Network
CFENet: An Accurate and Efficient Single-Shot Object Detector for Autonomous Driving
Large Kernel Matters - Improve Semantic Segmentation by Global Convolutional Network