GAN Dissection簡介 - Visualizing and Understanding Generative Adversarial Networks
David Bau, Jun-Yan Zhu, Hendrik Strobelt, Bolei Zhou, Joshua B. Tenenbaum, William T. Freeman, Antonio Torralba. “GAN Dissection: Visualizing and Understanding Generative Adversarial Networks”. arxiv preprint.
此論文於 26 Nov 2018 發佈,尚未被 Conference 接收。
Project 主頁 : https://gandissect.csail.mit.edu/
Demo video (建議觀看) : https://www.youtube.com/embed/yVCgUYe4JTM?rel=0&autoplay=1
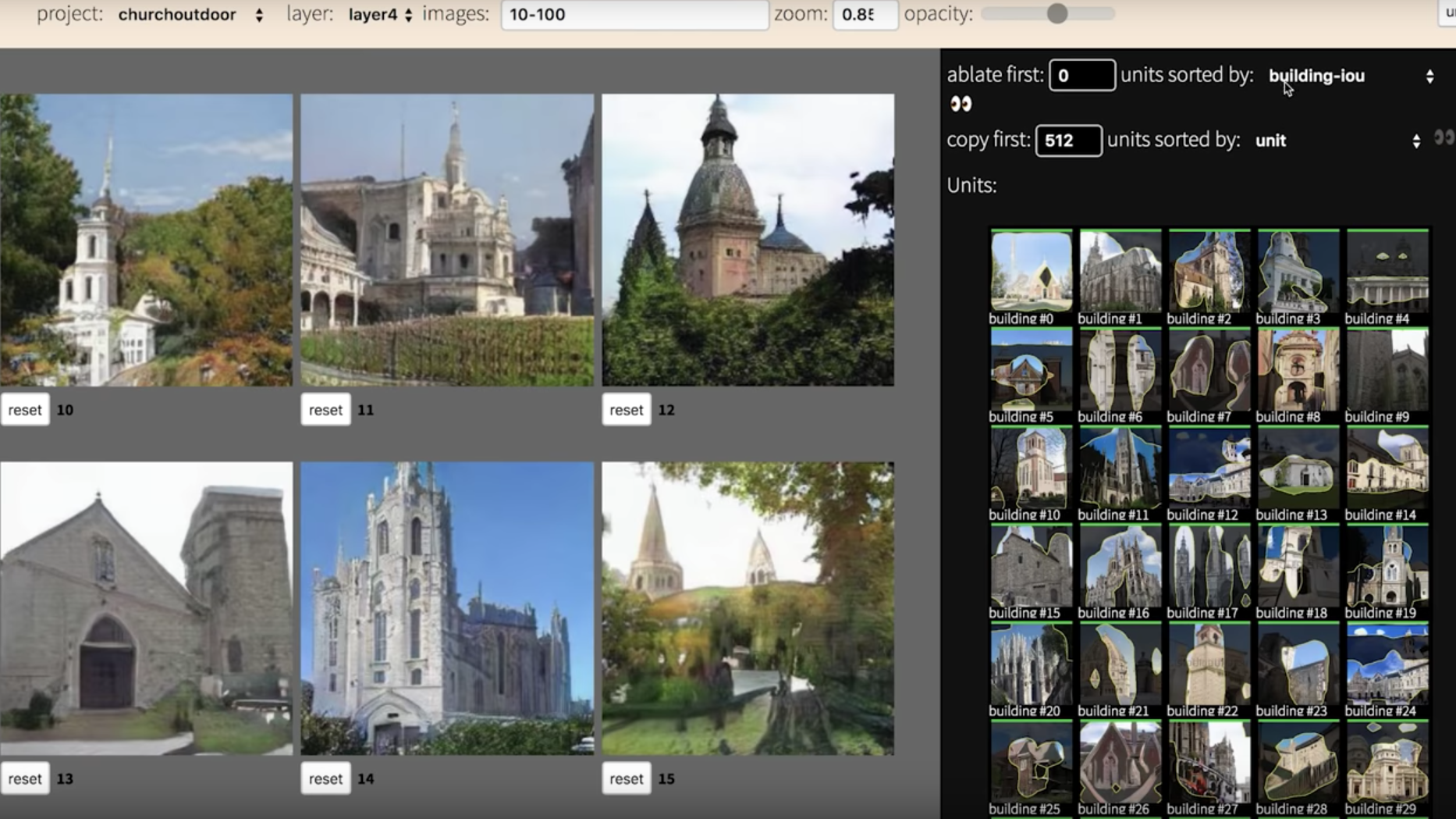
Demo(可操作看成效):http://gandissect.res.ibm.com/ganpaint.html?project=churchoutdoor&layer=layer4
Paper Link : https://arxiv.org/abs/1811.10597
Github code(Pytorch) : https://github.com/CSAILVision/gandissect

簡介
GAN 近年來發展得非常火熱,
但 GAN 伴隨著幾個問題 e.g., 生成的品質不夠好, 訓練不夠穩定。
而上面這兩個問題是許多人的研究方向,
但較少人在探討 GAN 內部的神經元以及每個 layer 都在學些什麼?
因此此論文使用視覺化的方式探討 GAN 神經元。
以圖片生成的任務為例,
我們希望他會生成出特定場景的圖片。

而可視化能帶來什麼好處呢?
- 可以知道 GAN 是在學習什麼樣的東西。

- 尋找哪些神經元導致輸出的結果不好。

- 知道哪些神經元導致輸出結果不好,那我們就讓那些神經元的輸出設為0。
原本生成圖片

將觀察到會導致扭曲的神經元的輸出設為0

並且提出一個可互動的框架來調整神經元,
可達到新增或是移除指定類別的功能。

此論文特點:找出某個類別所對應的 Units。
1 . 每個神經元 (Unit 或者說 Channel / Feature map) 代表什麼。
以下圖為例,此神經元學會了沙發這個類別。

2 . 每個物件 (Object) 對應到哪些神經元。
3 . 對應每個場景(Scene)資料集,其神經元是學習到什麼特徵,並可分析此 GAN 是否存在特定 bias。
概念
我們可以知道 CNN 是有所謂的空間相關性的。
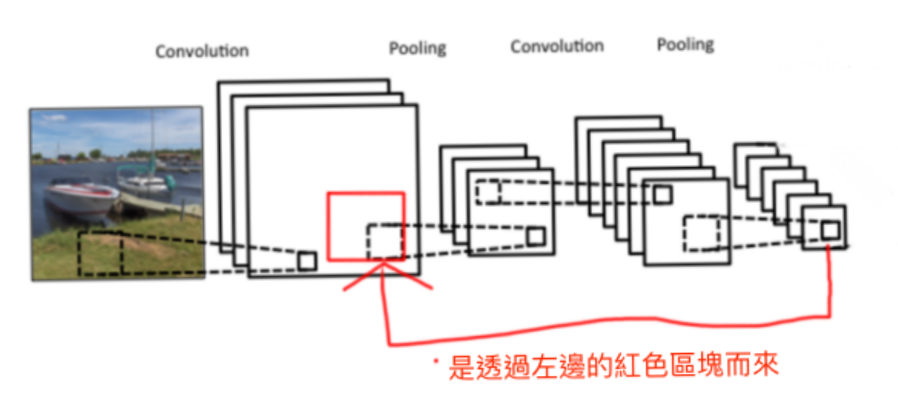
那我們經過上面這個示意圖能夠知道,
每個 pixel(Feature map) 都是對應到前面 Feature map 的某區域。
Dissection 解開
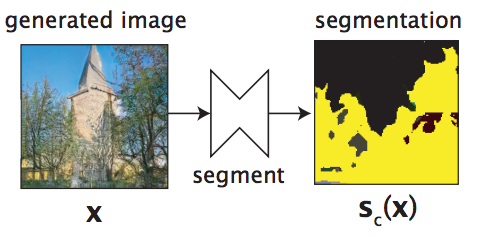
先講結論:如果該 Unit 與某個類別是相關的,那麼其 Feature map(想像成熱力圖)會與語意分割後該類別的 Mask 相似。
透過語意分割模型將特定的類別切割出來,
下圖將樹(Tree)的部分切割出來。
接下來我們再將某個 Unit 的 Feature map 與其分割出的 Mask 做比對,
看看相不相似,
下圖為此論文架構的一部分。
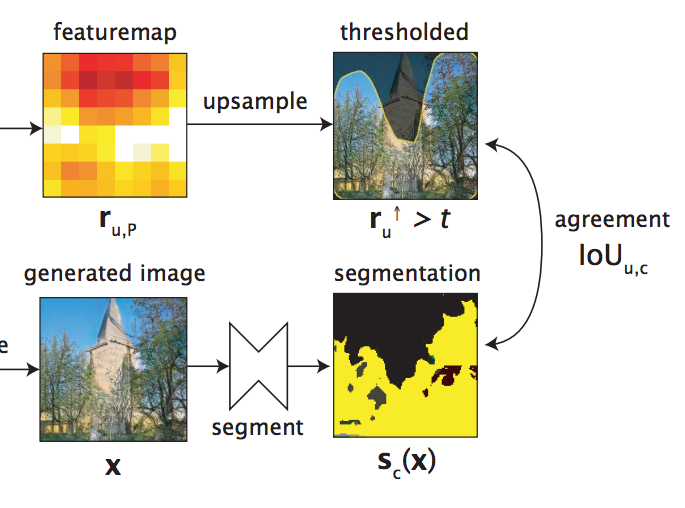
透過這方式一一比對,
當 Feature map 與某個類別的 Mask 長得夠像的時候,
我們可以認定這個 Unit 與某類別之間是有較大關聯性的。
Intervention 介入
透過上面的方式,
我們能夠知道哪些 Unit 與某類別是相關的,
但是我們卻不知道更動這些 Unit 的 Feature map 與最終產生出來的圖片(Output)有什麼關聯。
可能這個 Unit 與該類別雖然有關聯,
但是實際上對產生出來的圖片影響不大,
透過這個方式我們可以將其類別的 Unit 進行排序,
排名(Rank)出對其類別最有影響力的 Unit,
此實驗是對每個類別取 1…n(n=20) Units。
整體想法
我們要先透過 Dissection 得知哪些 Unit 是與該類別相關,
再經由 Intervention 明白改動這個 Unit 到底對最終輸出的該類別有著多大的影響。
因此我認為 Dissection 與 Intervention 的關係可以用 “方向” 與 “能量大小” 的關係作比喻。
方法
此文提出的架構如下,
上半部為 Dissection 解開
下半部為 Intervention 介入
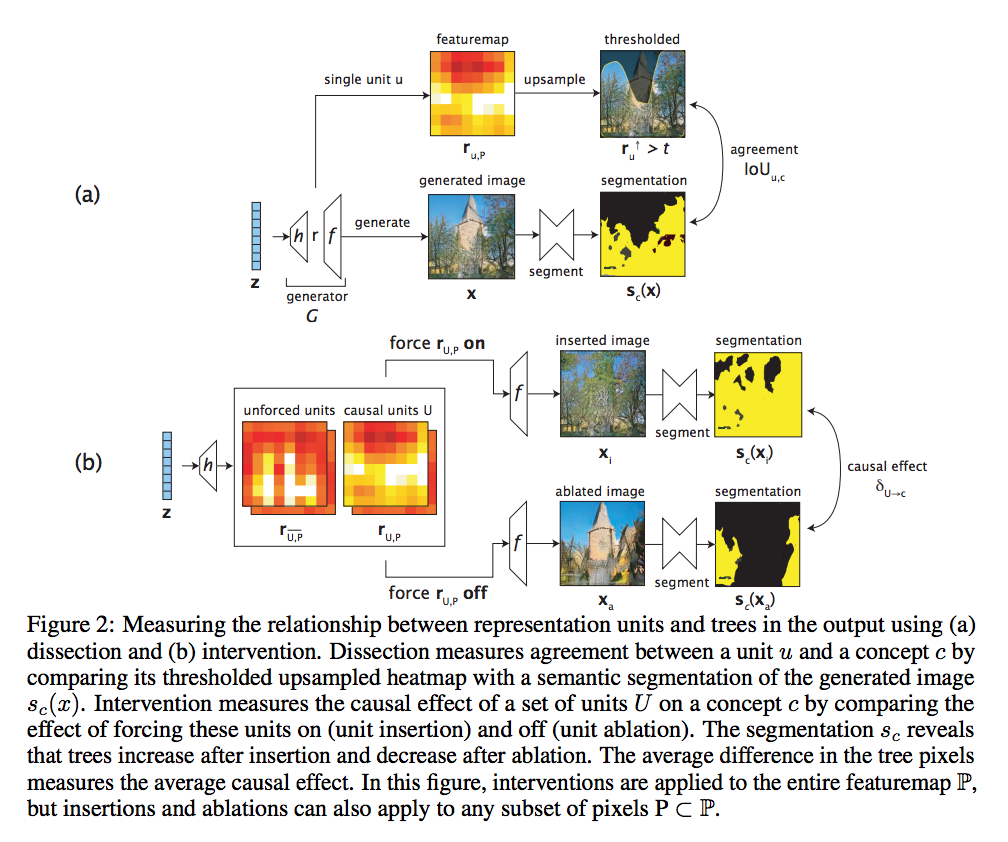
先看 G 的架構,
對於圖像生成的任務,
通常會輸入雜訊 z,
然後生成圖片 x,
而之所以可以生成 x 是因為 z 再經過一層一層的 layer 慢慢的轉變成圖片,
這邊的想法是我們提取出第 r 層,
來探討他每個 Unit 的 Feature map,
而他的 Feature map 會繼續影響著後續的 f(layers) 最終生成圖片。
而我們的最終目的是希望找出哪些 Unit 是對結果有顯著影響的。
這邊我們可以這樣想像,
假設我們要生出辦公室的場景,
那可能有些 Unit 各自負責桌子、椅子、人。
但是剛好這張圖片生成出來後,
只有桌子和椅子,
我們希望找到著重於桌子和椅子的 Unit,
這樣就能對他做移除/修改的動作。
因此我們定義下面這公式

參數定義:
- r : 某層 Layer, 可看架構圖 generator(G) 的部分
- U : 哪些 Unit 是對目前想要操作的類別有影響的,舉例我可能想要修改椅子而已,我們要找出哪些 units 對椅子有影響。
- U- : U 的補數,即為我們不感興趣的 units.
Dissection 解開
此處我們要找到哪些 Unit 對該類別有影響,
找尋哪些 Unit 的 Feature maps 與我們 Semantic segmentation 的模型預測出來的 Mask 相近。
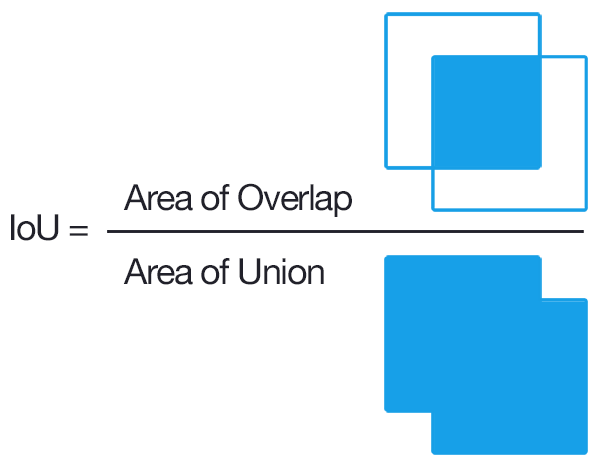
而此處使用 IoU 的方式
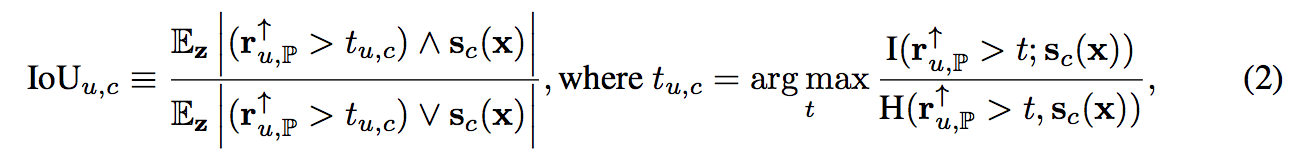
參數定義:
- ↑ : 將 Feature maps Resize 成 x 的大小。
- Sc : 給定 x 後,獲得 c 這個類別的 Mask, 架構圖segmentation黃色處。
- t : threshold,這部分比較複雜,有興趣的人在自己去了解。
想要研究的更深入的話可以去看看,H & I 參考論文。

透過這方式,我們可以知道 r 的哪些 Unit 與某個類別有著高度相關性。
Intervention 介入
透過將 Dissection 可知道哪些 U 是與該某個類別 c 相關的,
但我們不知道每個 U 到底對最終的輸出影響多大,
因此我們會將 U 去做修改,
將其 Feature map 歸0 或是 設定為一個常數 k,
透過這兩個方式來測試這個 Unit 到底影響大不大。
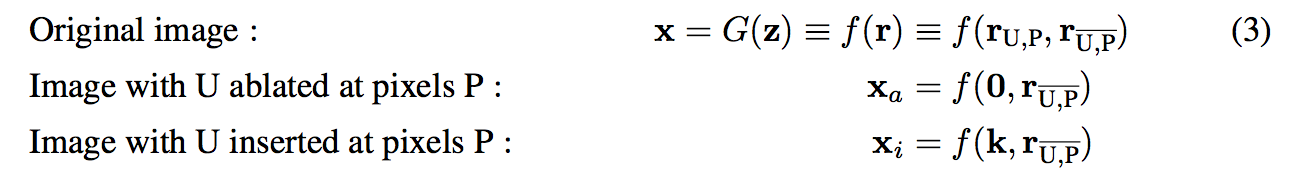
提出 average causal effect (ACE),
透過這方式可知道基於每個 c(類別)這些 Unit 是否能影響輸出。
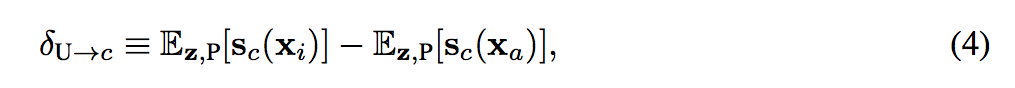
可是要怎麼樣才能有效率地得出 δ 呢?
如果我們每次都對一個 Unit 做 On/Off 的操作來測試它的影響力,
這樣沒效率呢!
因此這邊使用 α ∈ [0, 1],
對每個 Feature map 都給定一個 α,
我們可以想成每個 Feature map 多一個參數,
備註:
這邊有趣的地方是我們給每個 Feature map 1 個參數 α,
並非是 c 個參數 α,
想了一下,我們可以回到 IOU - eq 2的部分,
可以想像每個 Feature map 通常只會對應到某個類別 c,
所以用 1 個參數應該就可以了。
透過 sgd 的方式去求得最佳化。
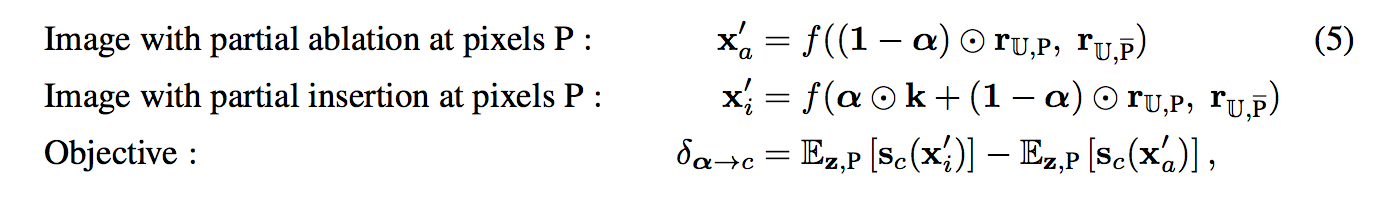
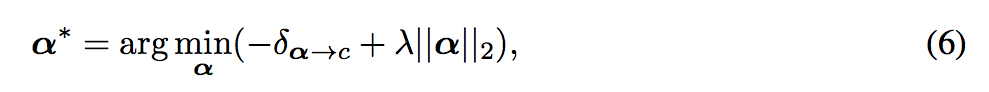
而這邊 α 初始化為
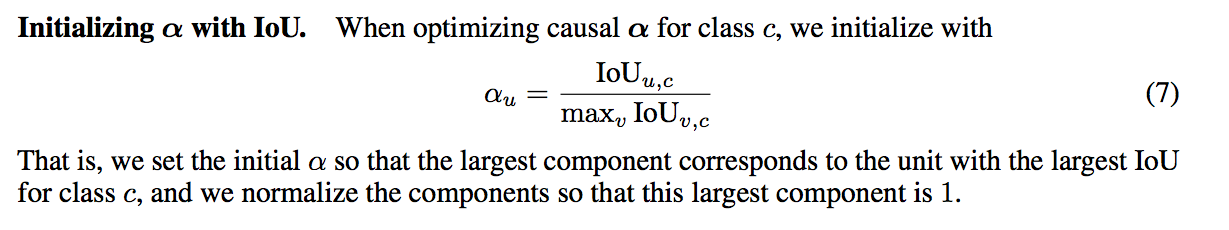
最終我們可以透過 α 的值來知道哪些 Unit 對最終的影響較大,
就可以將該 Unit Off(設定為0),
達到移除的功能。((下方為移除樹木的圖片展示
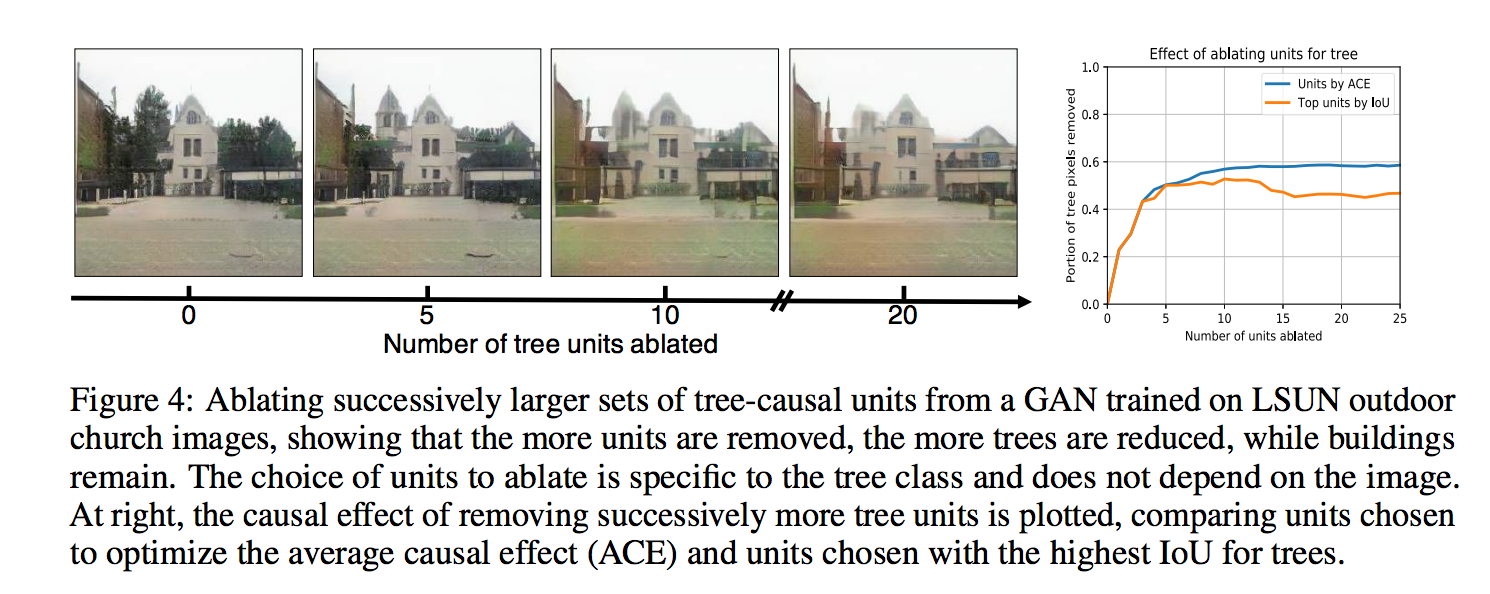
實驗設定
使用 Progressive GANs,
資料集選用 LSUN scene datasets,
使用(Xiao et al., 2018)所提出的 Segmentation model 其訓練在 ADE20K scene dataset,
一些探討
Unit 可以應付同種類但是不同外觀的類別
如上圖可以看到這個 Unit 是專門處理桌子的,
而他可以處理不同材質、不同形狀的桌子,
下面那一列的沙發也是同理。
對於不同場景,Unit學到的東西也不同
建議去開論文看清楚的圖檔,
右邊的 Unit class distribution 可以知道每個類別使用多少個 Unit。
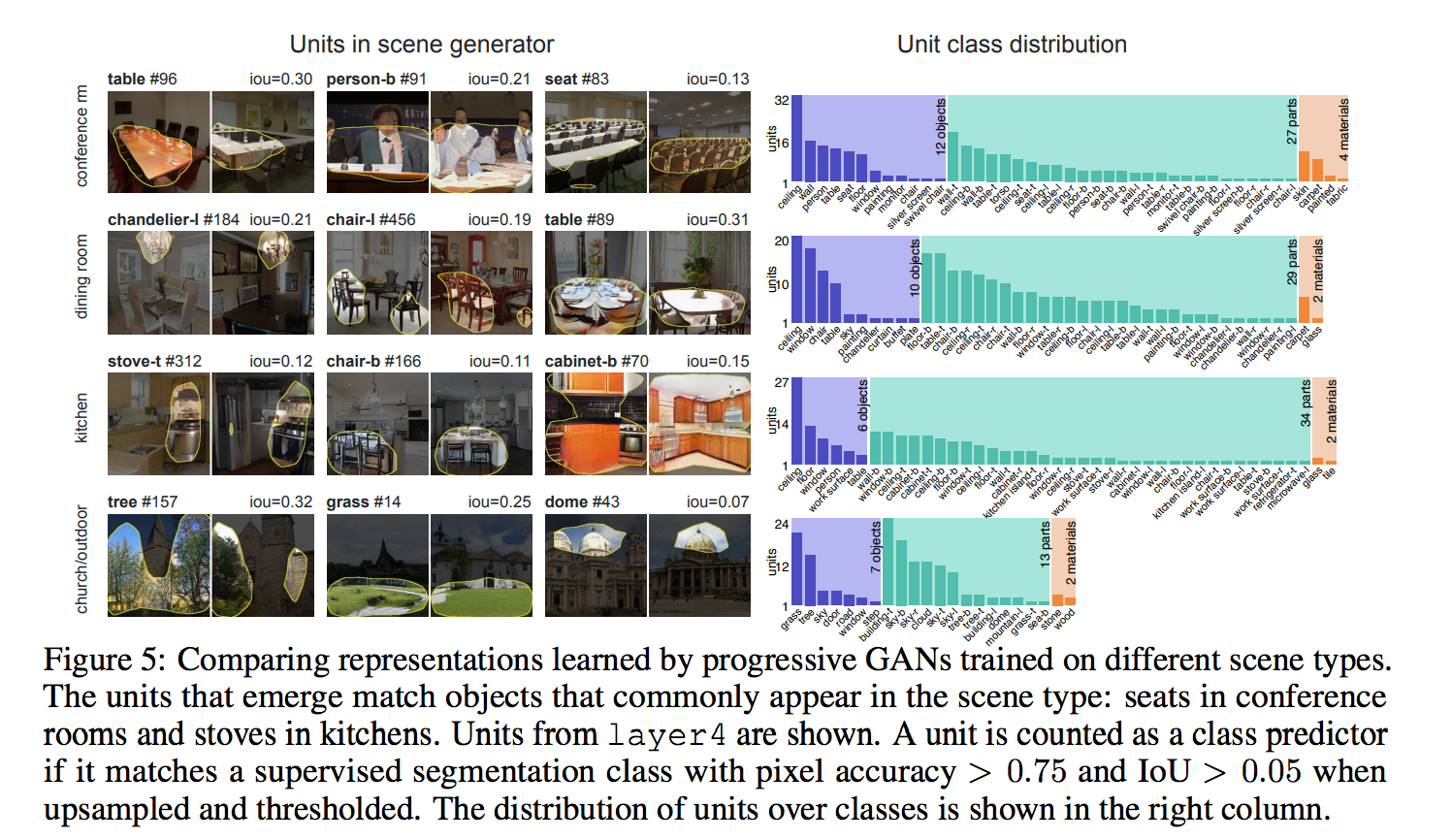
在 LSUN 這個資料集有著不同的場景,
而我們能觀察到當我們訓練廚房(Kitchen)這個資料集時,
我們會發現我們的 Unit 會偏好學習 火爐(Stove)、 櫃子(cabinet)、 櫃子(cabinet)、廚房凳子(kitchen stool),
而這些也是符合廚房會有的特徵,
還有個有趣的現象是,
當訓練會議室(Conference room)的資料集時,
有些 Unit 甚至學會了人的不同部位(頭、身體)。
不同 layer 之間學習到的特徵不同
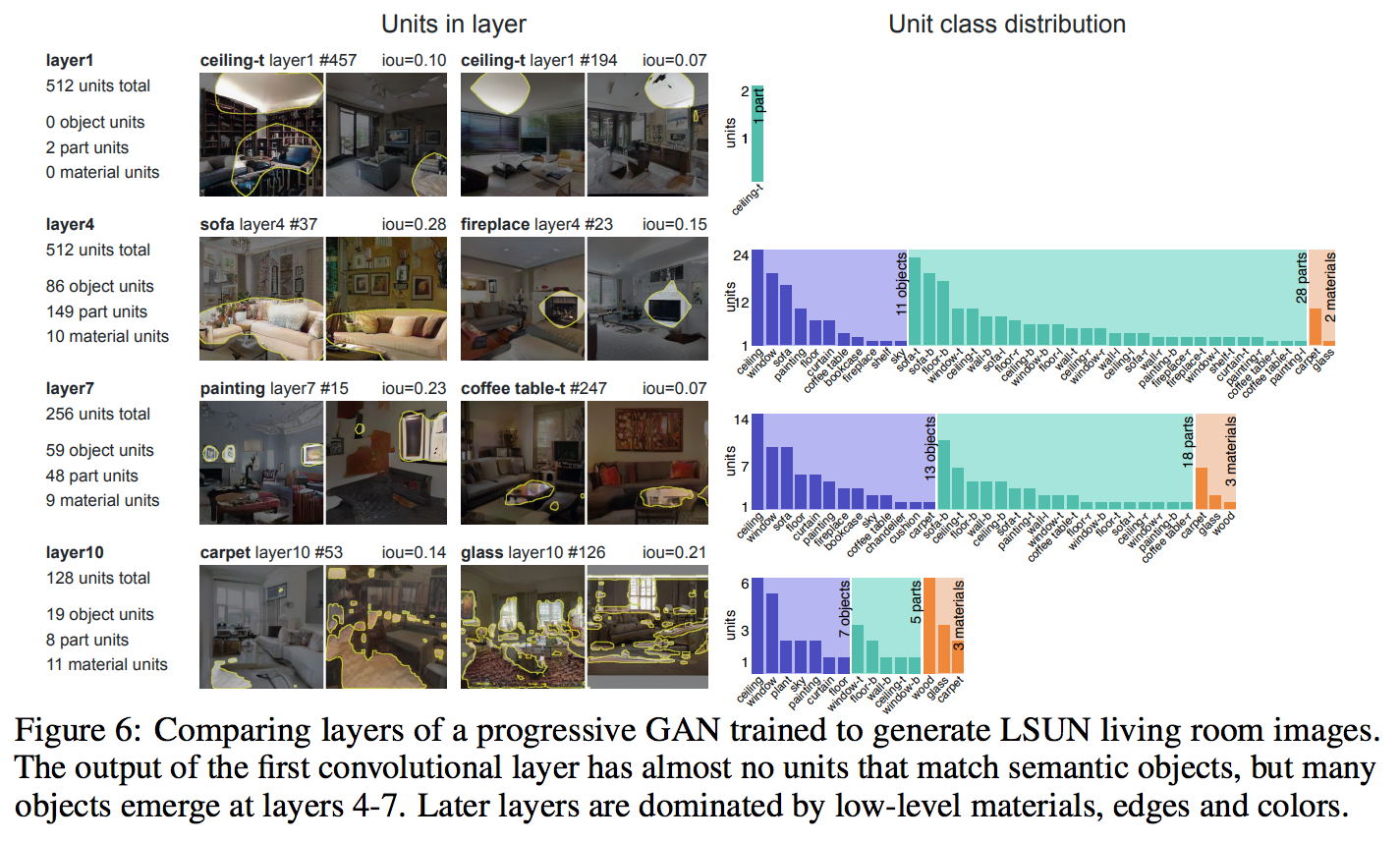
第 1 層我們看到還是會有誤判的情形,
而且除了天花板這類別之外,
其他的類別都沒學到(可看右半部 Unit class distribution)
但是第 4 層學習到最多的類別,
可是到第 10 層過後,
反而開始學到紋理、邊緣一些細節等等,
個人覺得或許是因為這是圖像生成的任務,
導致後面的 Layer 會認真學習優化一些細節。
透過視覺化模型來評估 GAN 是否訓練的好
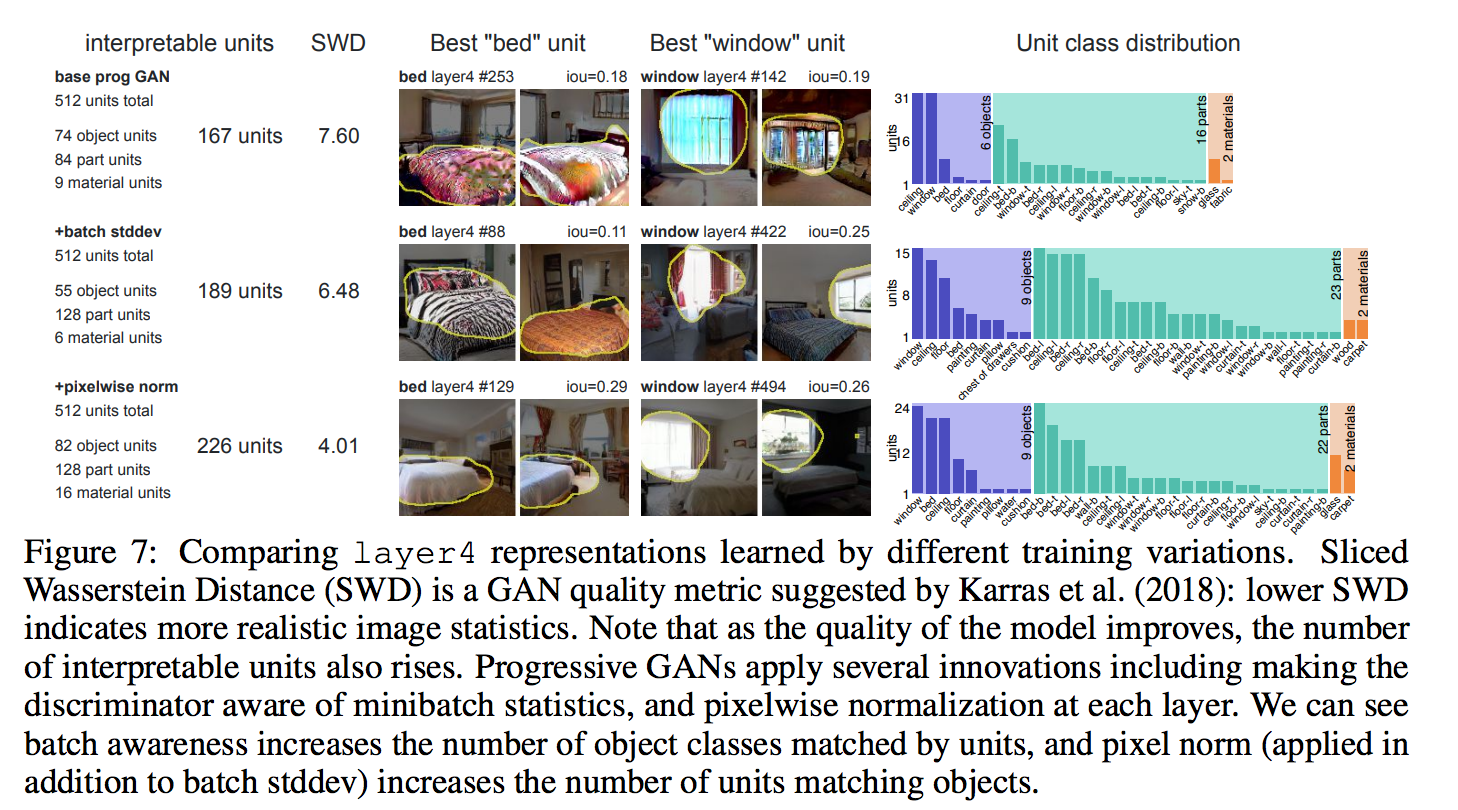
看左半部的 interpretable units 以及右半部的 Unit class distribution,
我們可以發現伴隨著 SWD 的分數越來越高,
可解釋的 units 個數也越來越多。
透過視覺化“手動”改善 GAN 扭曲
這部分是我個人覺得這論文最有意思的地方了,
我們都知道 GAN 雖然這幾年一直進步,
但是 GAN 還是會產生出怪怪的圖片。

那我們可以透過可視化找出扭曲部分所對應的 Unit,
可是怎麼找呢? 他又不能被 Sc 分到一類,
因此這邊提出來的方法是先產生 1000 張圖片,
然後我們可以看每個 Unit 對應到分數最高的前幾張圖片,
透過這種方式我們可以發現有的 Unit 專門產出很奇怪的圖片,
那我們就可以手動將該 Unit 的 Feature map “Off”,
透過這方式就明顯地將詭異的部分改善了,
而作者提出人工將 layer 4 (512個units) 挑出 20 個這種 Unit 將他 Off,
只需要 10 分鐘,
換句話說,只要10分鐘效能立即改善,
你知道訓練一個 GAN 要好幾天嗎。。。((更何況 GAN 還有訓練不穩定的問題
而現在只要 10 分鐘就基於現有的模型進行優化,
真的感動。
移除特定物件

我們可以透過將某類別的 Feature maps Off 來達到移除特定類別的功能,
雖然某些類別可以很乾淨的移除,
但是並不是每個類別都可以移除的這麼乾淨,
如桌子、椅子, 看那圖片根本沒移除掉。
而這件事可能牽涉到訓練的資料集,
舉例來說有些物品在某些場景就是很容易出現,
所以就算你把那個 Unit Off,
後續的 layer 還是強迫你出現,
臥室(bedroom)的窗戶或是會議室(Conference Room)的桌子、椅子。
因此這邊有個推測,
GAN 能夠學到理念的部分,
像是會議室的桌子椅子很重要,
因此不能被移除。
新增特定物件

黃色框框處是希望門(door)可以新增在該位置,((透過 layer 4 unit 的操作
而在這個實驗有發現個有趣的現象,
就是如果我們將門畫在建築物周圍的話,
GAN 可以順利的新增上去,
但是如果是畫在樹木或是天空,
GAN 則無法順利的新增,
因為 GAN 能夠判斷物體間的關係,
也就是後面的 layer 會阻止這種不符合常理的事情發生。
討論
此論文有 Discussion 部分,
提出幾個未來方向:套用至 VAE model, 以及為什麼門不能被新增到天空、GAN在更後面幾層 layer 到底是在學些什麼((請看 layer1 ~ 10 那張圖片。
此論文還有很多細節以及補充說明的地方,
有興趣的自己去翻論文。
個人想法
這篇看起來很不錯,
給出許多圖片來論述,
Demo video 也讓人驚艷,
先決條件是需要 Segmentation model,
並且 Segmentation model(pre-trained weight) 或是 Semantic segmentation dataset 要有對應到你 Task 的 label,
其實這條件艇嚴苛的。
本文透過 Segmentation 搭配 IoU 來檢索哪些 Unit 是相關的,
那除了圖像生成任務,目前我個人沒有想法可以套用在其他任務上。
可是本文有個讓我驚豔的地方,
章節:透過視覺化“手動”改善 GAN 扭曲,
在那個章節透露出了手動調整 GAN,
讓生成圖片的扭曲問題得到改善,
雖然在研究方面通常不能夠透過手動方式調整模型,
因為近年來還是注重在模型架構以及損失函數的設計等等。
但是對業界來說,
透過手動調整的方式能夠快速的優化 Model 也不算作弊,
不然訓練 Model 都是動輒好幾天,
如果能透過 10 分鐘手動優化就能提高成效的話,
是非常值得嘗試的。
只是現在看來只能優化圖像生成的任務,
期待未來有更多的延伸。
參考資料:
GAN Dissection: Visualizing and Understanding Generative Adversarial Networks
Youtube:GAN Dissection: Visualizing and Understanding Generative Adversarial Networks