PADA簡介 - Partial Adversarial Domain Adaptation
Zhangjie Cao, Lijia Ma, Mingsheng Long, Jianmin Wang. “Partial Adversarial Domain Adaptation”. In ECCV’18.
ECCV 2018 paper.
Paper Link : https://arxiv.org/abs/1808.04205
Github code(Pytorch) : https://github.com/thuml/PADA
前言:看這篇是因為其實驗室在 AAAI’19 有發布 Transferable Attention for Domain Adaptation,都是 DA 的題目並且都使用相同資料集測試,於是先來看看這篇。
簡介
此論文是在解決 Domain adaptation(DA) 的問題,
但是以往的 DA 任務都是建立在兩個資料集的 label 數量相同並且一致,
但這任務比較不同的是可以接受 Target Dataset 的類別是 Source Dataset 的 Subset,
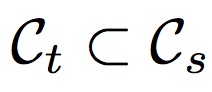
以下圖為例,
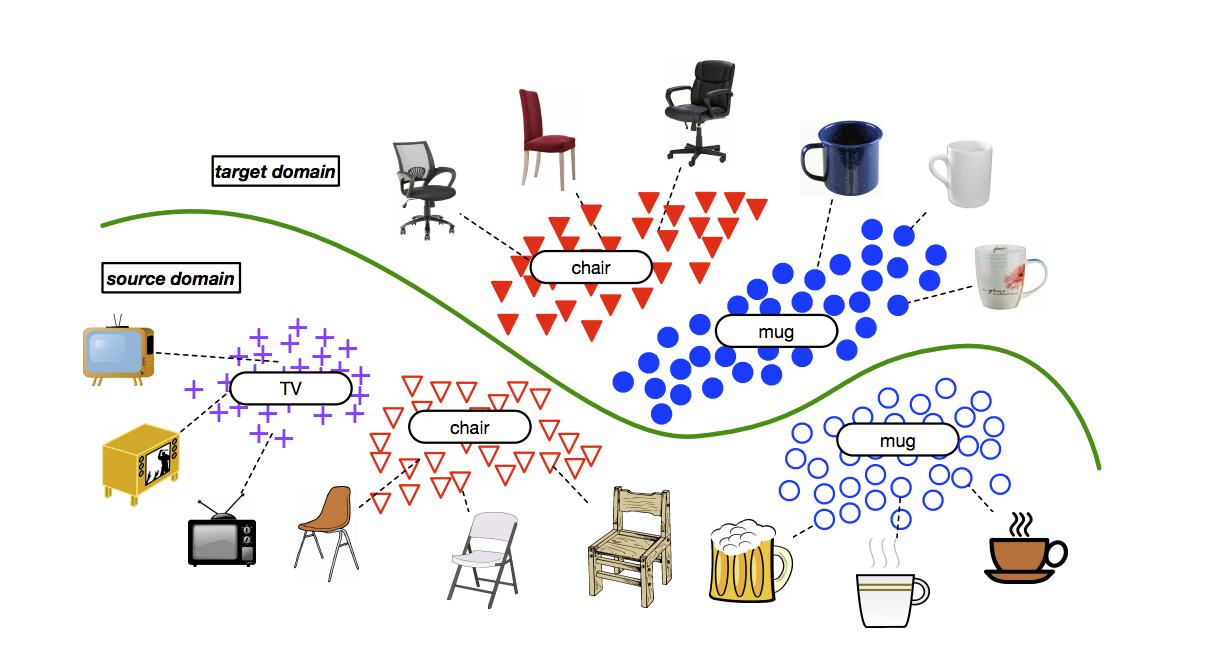
上半部是我們的目標資料集,
而下半部的資料集有著比目標資料集更多的類別(如 TV。
而此論文的動機為現在這個巨量資料的時代,
有著很多類別的資料集並不少見(如 ImageNet-1000,
但是當我們想要應用於特定任務時,
往往不需要這麼多類別,
我們可能只會專注於辨識某幾個類別/讓某些類別有更好的相容性,
如上圖為適應 chair 以及 mug 等圖像的紋理、畫風。
但是直接將多類別(Cs)的資料集遷移至少類別(Ct)的資料集時準確度往往不佳,
這是因為我們的 Discriminator 往往會對(Cs/Ct 定義請看下方註1.)的類別過度的干涉,
為了避免這件事情,
此文提出對(Cs/Ct)的類別的權重調低(此文稱作 down-weighting),
避免讓非遷移的類別(Cs/Ct)過度的影響到整個模型。
註1.:
Cs/Ct 指的是 Cs 的眾多類別中,不屬於 Ct 的類別,我們會寫作 Cs/Ct, 並且稱作 Outlier label space.
備註.:
通常 DA 的任務, target domain dataset(Ct)的圖片是沒有 label 的。
概念
我們要將 Cs/Ct -> outlier 的類別降低權重,
主要的想法是避免給整個模型過多的多餘資訊,
因為我們的任務是 Domain adaptation(DA),
主要是希望我們的模型可以針對目標的類別(Ct)有效地處理兩個資料集(source/target)中同類別的資料,
那如果我們將 Cs/Ct 與 Ct 都設定為相同權重去訓練的話,
| 會讓模型偏好 Cs/Ct 的資料集而無法有效的對 Ct 進行遷移((這邊給的前提是 | Ct | « | Cs/Ct | 。 |
我們定義下面的名稱,雖然後面不會用到但在論文中常出現。
- negative transfer - 訓練 Cs/Ct - outlier 的類別,可能會降低我們的準確度
- positive transfer - 針對 Ct 的類別,讓模型對於兩個資料集的分佈相近。
方法
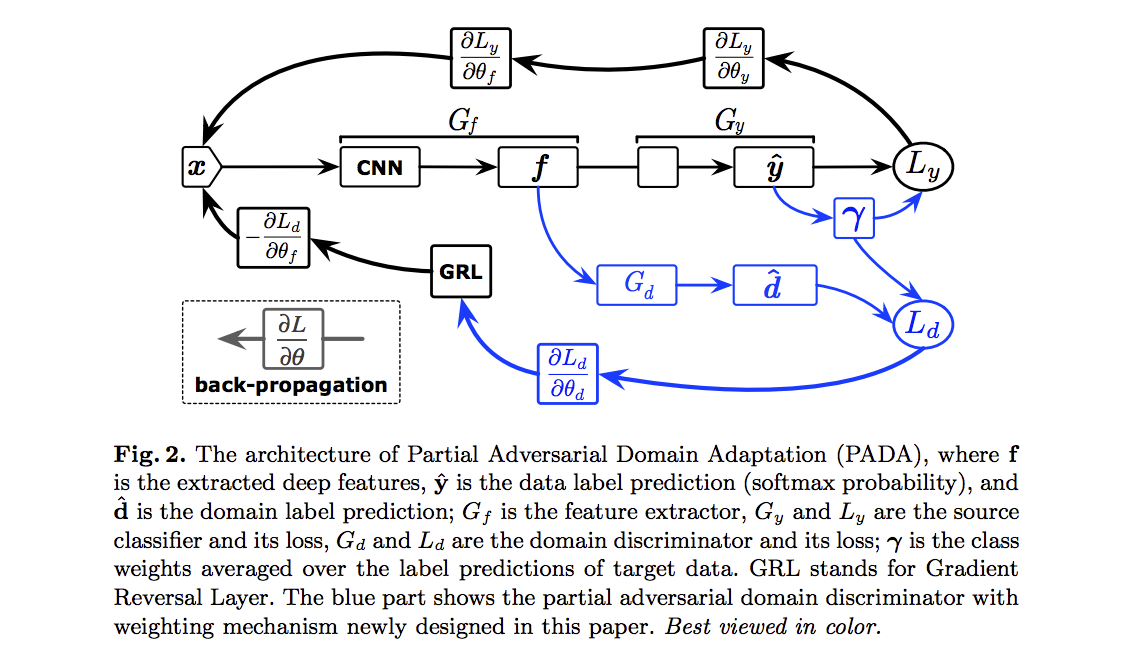
整個框架是基於 Domain Adversarial Neural Network(DANN) 作延伸,
但不同的是此方法針對目標資料集的類別(Ct)做權重上的處理。
簡單描述 DANN 的方法,
會先使用 Gf 萃取特徵然後輸入至 Gy 做分類,
然後再輸入進 Gd 透過 GAN 的方式來讓 Gf 能對於不同資料集(source/target)所輸出的特徵相似。
- Gf: Feature Extractor
- Gy: Classifier
- Gd: Domain Discriminator
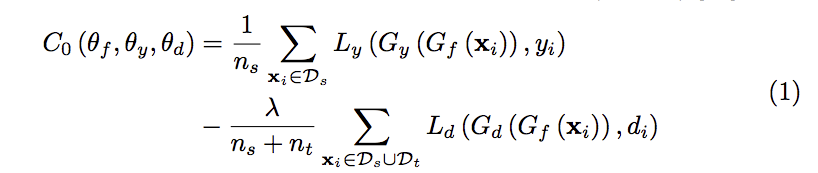
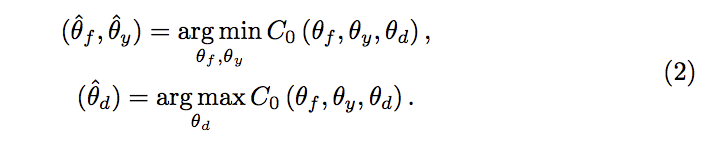
而本文改進的點是在下方可看架構圖,
藍色為有使用本文所提出的(weighting 機制),黑色為原本 DANN 原有的架構。
本文的核心調整權重,
而他的想法是透過分類器給出的機率來決定,
原文這樣描述:
Fortunately, we observe that the output of the source classifier yˆi = Gy(xi) to each data point xi gives a probability distribution over the source label space Cs.
我是覺得描述的有點少拉。。。
總之呢透過分類器調整權重,
如果是屬於 Ct 的類別,
我們權重就給高一點,
那如果是屬於 Cs/Ct 的類別,
我們權重就給低一點。
但是要考量到可能會有誤判的情況,
於是給出下面的式子,

輸入整個 target domain(Ct) dataset,
對預測出的類別機率取平均,
這樣子可以降低誤判所帶來的影響,
因為把整個資料集都預測完,
只要分類器有點水準,
都不會差太多。
備註:
這邊給出的假設是 Cs\Ct 的類別所得到的分數是非常低的,因為我們輸入的是 Target dataset,因此輸入的都是屬於 Ct 類別的圖像。
那最終我們就可以透過 γ 這個權重來控制 Ct 與 Cs\Ct 各自的類別,
以達到不同類別對應不同權重。
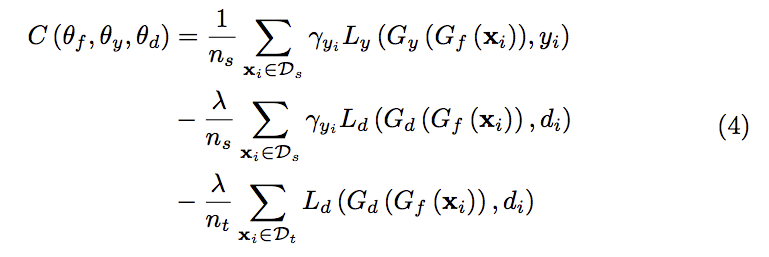
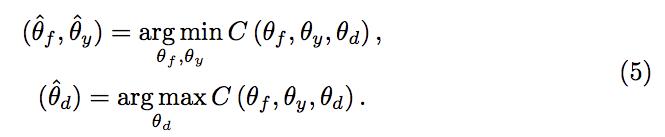
程式碼部分
簡單貼一下我看到覺得可以參考的部分
控制權重的方式透過輸入 weight,
pyTorch 真方便。
class_weight = torch.mean(target_fc8_out, 0)
class_weight = (class_weight / torch.mean(class_weight)).cuda().view(-1)
class_criterion = nn.CrossEntropyLoss(weight = class_weight)
# PADA adversarial loss
nn.BCELoss(weight=weight_ad.view(-1))
不過 GRL 那部分我沒認真看,
可能要去看 DANN 才會明白。
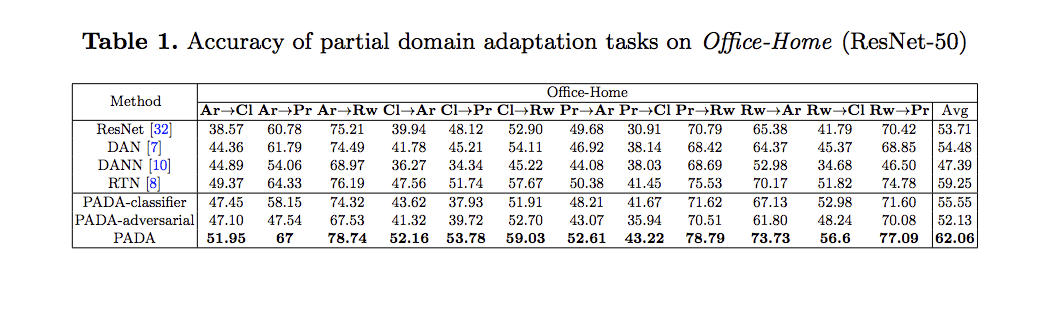
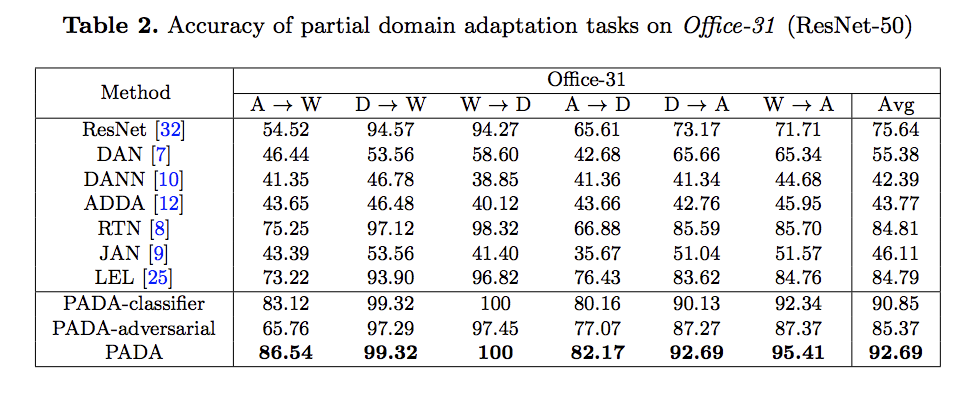
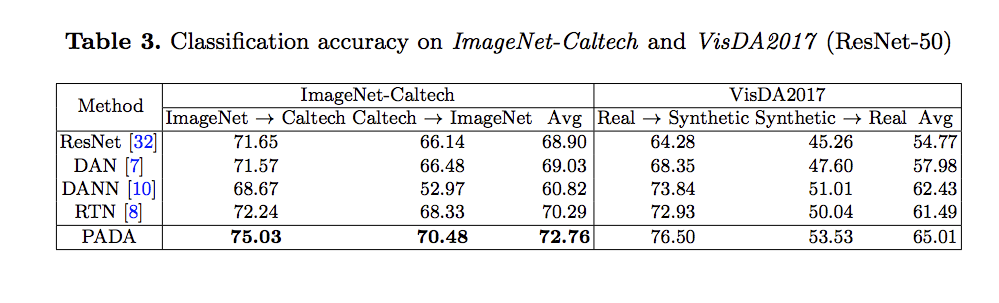
實驗
使用 Office-31、Office-Home、ImageNet-Caltech 等資料集測試,
實驗細節有興趣的自己去看論文。
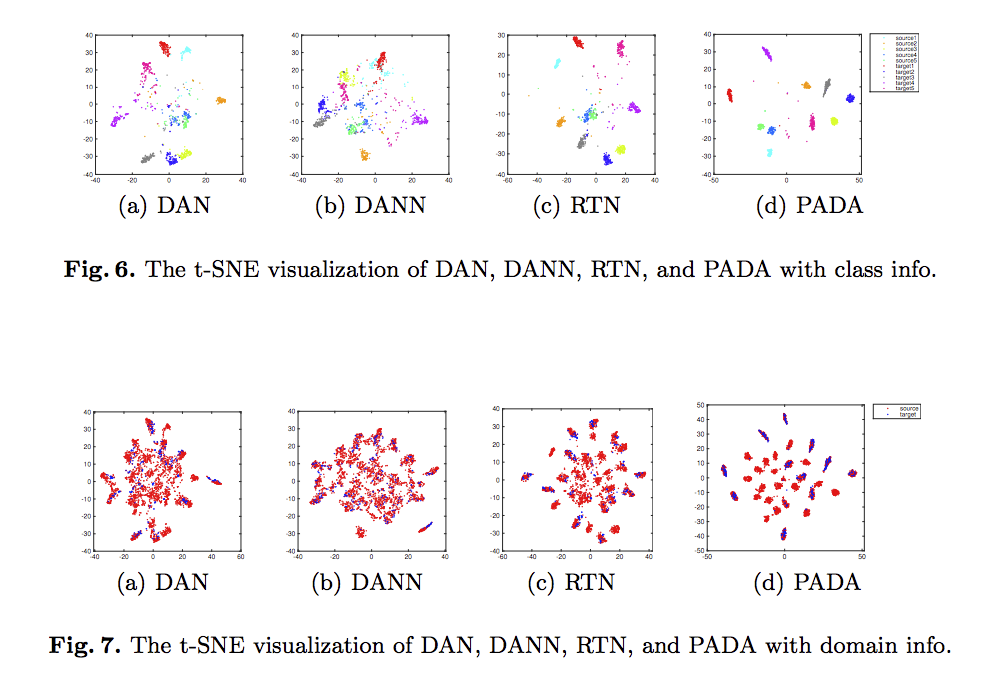
用 t-SNE 看特徵分布。