TADA簡介 - Transferable Attention for Domain Adaptation
Ximei Wang, Liang Li, Weirui Ye, Mingsheng Long, and Jianmin Wang. “Transferable Attention for Domain Adaptation”. In AAAI’19.
AAAI 2019 paper.
Paper Link(不是在arXiv) : http://ise.thss.tsinghua.edu.cn/~mlong/doc/transferable-attention-aaai19.pdf
Github code : 尚未發布
可能會發布請關注:https://github.com/thuml
因為沒有 Code 參考,加上架構複雜,可能會有寫錯的地方,歡迎指正^^
簡介
此論文是在解決 Domain adaptation(DA) 的問題,
主要是結合了 Attention 的機制。
他的想法是並非每張圖片的所有區塊都適合做 Domain adaptation,
舉例來說我們可能只要 Transfer(遷移) 椅子這個類別,
我們可以透過 Attention 機制專注於椅子這個物體,
除了椅子之外的背景資訊就不是這麼的重要了,
還有另一種情況是當 Target domain 的圖與我們的 Source domain的圖片相差太大時,
使用 Discriminator 學習的話可能會破壞模型既有準確度。
基於上述的情況提出兩種 Attention 機制
- Global Attention - 與原本 DA 常見的 Domain Discriminator 相似。
- Local Attention - 此文重點,透過在 Layer 中加入 Attention 機制找尋其 Feature map 的哪個部分較適合 Transfer。
基本概念
整個框架是基於 Domain Adversarial Neural Network(DANN) 作延伸,
簡單描述 DANN 的方法,
在 DA 的任務中通常 Target domain 是沒有 label 資料的,Source Domain 才有。
因此會先使用 Source domain dataset 的圖片輸入至 Gf 萃取特徵然後經由 Gy 做分類訓練模型,
然後再將 Source/Target domain dataset輸入進 Gd 透過 GAN 的方式來讓 Gf 能對於不同資料集(source/target)所輸出的特徵相似。
- Gf: Feature Extractor
- Gy: Classifier
- Gd: Domain Discriminator
- Ly: Classification loss
- Ld: Discriminator loss
- n: Source dataset (Ns) + Target dataset (Nt)
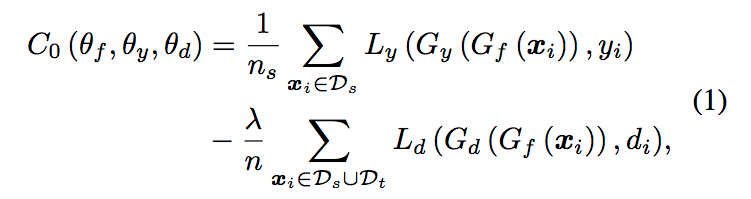
對於 GAN-based 的 DA 方法點出了一個問題,
就是往往他們都是對整個 Feature space 或是 Label space 輸入進 Discriminator 去訓練 Generator,
但是這樣並沒有 fine-graind 的結構,
說白話點就是他的 Attention 概念,
如果有些區塊我們已經覺得訓練的不錯的話那我們就微調就好,
不要把整個 Feature/Label space 都用相同的權重做訓練。
方法
而此文的架構圖如下,
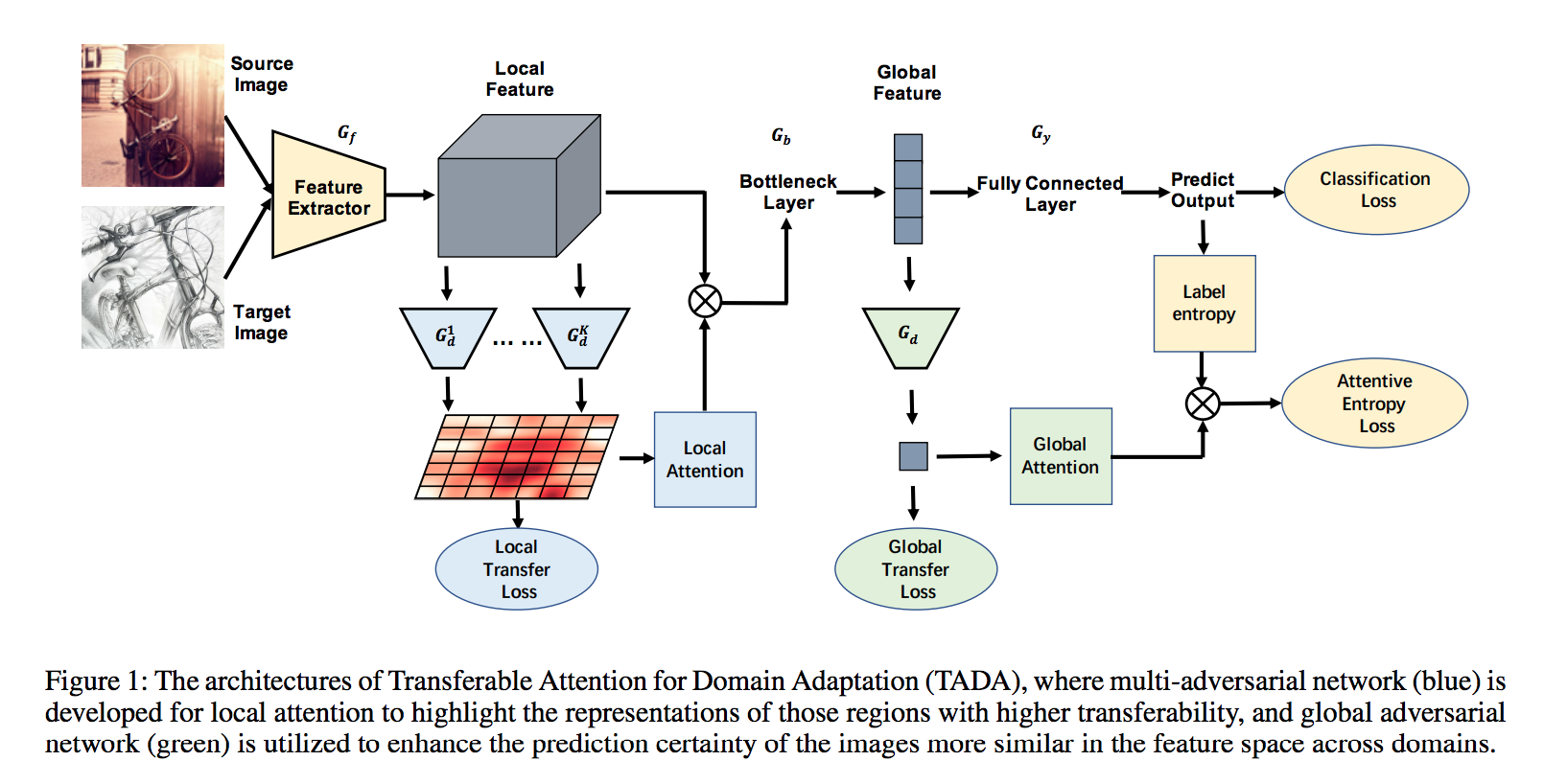
淺藍色是 Local attention 的部分,
而且綠色是 Global attention,
整體架構有點複雜下面慢慢介紹
備註:
下方的開始有些公式定義可能有錯,論文中定義太多符號,有些我覺得沒有寫得很清楚,可能是我的問題拉。
Local attention
此文的論點是並非圖片中的每個區塊都適合 Transfer,
我們透過一個 Gd(Domain Discriminator) 學習該圖片的哪個部分是適合學習的,
他的輸出為熱力圖(大小為該層 Feature map 的 H x W)
我們可以從上圖淺藍色 Local attention 部分的白紅色熱力圖可知,
紅色的部分是 Gd 認為適合遷移的部分,
那我們會發現紅色多半集中在中間,
因為通常中間才是物體的位置,
其他白白可能是背景或是Gd(Domain Discriminator) 認為不適合遷移的部分。
那這篇特別的是在模型中的第 1…K layer 都配置一個 Gd 作輸出,
這邊作者的想法是取自於人的視覺模式,
我們通常看圖片會集中於一個點,
舉例來說我們看一張照片第一眼可能先找找看這張照片有沒有人,
找到人之後,我們會想看細節的部分,
於是我們可能會集中在人臉的部分。
那這觀念在 CNN 如何實踐呢?
在 CNN 中每個 layer 可能負責不同尺度,
舉例來說較為淺層的因為較少 Stride/Pooling 所以可以處理較小的物體,
而到了深層經過大量的 Stride/Pooling 之後,
我們所輸出的 Feature map 逐漸變小,
那他是負責偵測較大尺度的物體。
以本文的 ResNet 50 為例,
最後一層的輸出維度為 7 x 7 x 2048。
而 H x W 就是 7 x 7,
主要是負責較大的物體。
總之呢我們要考量到 Attention 機制可能會想要集中在物體中的某個點,
所以我們要對各種不同大小的 Feature map 都加入 Gd 讓他可以應付多尺度的變化。
Loss-Local
Gd(Domain discriminator) 的用意是辨認圖片是來自 Source / Target domain,
那我們會希望 Gd 可以使生成器(Gf)所產生出很相似的分布,
而 Gf 的目標是希望 Gd 分不清他是來自 Source / Target domain。
簡單來說 Attention 機制就是參考 Gd 所輸出的 d - Feature map(熱力圖),
d: 1 代表 Source domain, 0 代表 Target domain,
如果是紅色代表值較大,也代表著相似於 Source domain 的部分。
那當我們輸入 Target domain 的圖片時,
但是 Gd 的輸出卻是紅紅的部分就代表它認為這部分是相像 Source domain 的部分,
那我們就會覺得這個部分是不是 Gd 分不清,
也意味著較適合遷移的部分,
透過這個想法來達到 Attention 的功能。
Loss function 會寫成這樣,
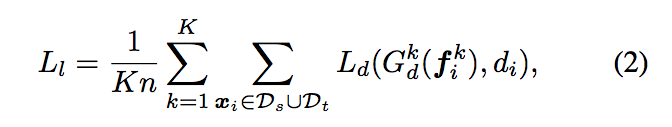
Ld: cross-entropy loss
K: 對不同 layer 都放 Gd,共有 1…K 個 Gd。
di:domain label of point xi
那我們經過 Gd 會得到這個輸出 di,
- i : ith of source image dataset.
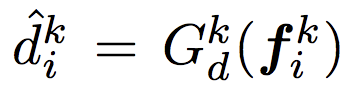
我們會將 d 再經由 entropy(H) 的方式後才會當作我們的 Attention 中每個 pixel 的權重 w。
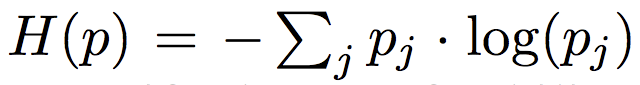
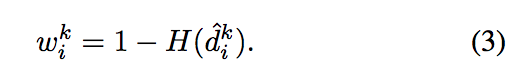
Trick:為了避免我們的 Local Attention 的結果很糟,
怕因為這樣情況會突然降低我們的準確度,
因此提出使用 Residual connection 的方式,
可以讓整個模型更穩定,
不會因為突然的誤判就大大的傷害到準確度,
因此最終 Attention 所採用的輸出為下面公式的 h。
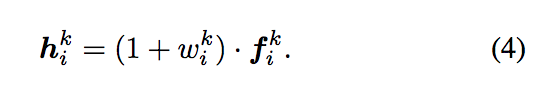
下圖為最後一個 Conv layer 的輸出,

最左邊為輸入圖片,中間為 Attention,右邊為 Attention蓋在原本的圖片上方便觀看。
Global attention
如果我們單純仰賴 Local attention 的話會有個問題,
就是 Local attention 往往會集中在最能夠識別的點,
因為我們的模型有接 Ly - classification loss,
等同整個模型有分類器的功能,
而分類器的特色是不管圖片平移、縮放、旋轉等等,
都應該要分的出來,
而這個特色歸功於他會學習圖片中最具鑑別度的地方。
舉例來說如果我們分類器有鳥的類別,
那他可能會學會有翅膀的就是鳥,
而忽略了鳥的整體訊息。
因此 Global attention 就是為了解決上述的問題,
將整張圖片做做 transfer,
而做法就跟一般 DA 的 Domain discriminator 差不多,
透過 Discriminator 分辨出是來自 source/target domain。
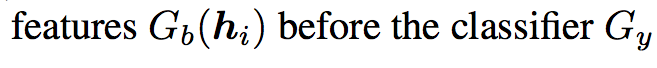
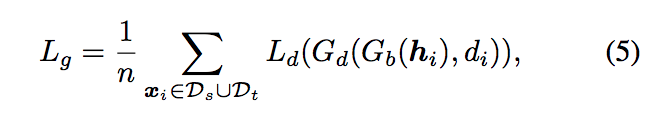
- Gb:指的是 bottleneck layer
- di:domain label of point xi
Weakly supervised 優化
其實 Global attention 和 Local attention 的想法是差不多的,
都是經由 Discriminator 來告知圖片中的哪個區塊有多大的可能性是來自 Source/Target domain,
因此也可以透過 Global attention 來得知整張圖片與 Source domain 相不相像,
評估相像程度給定權重(m),再經由分類器去對整個模型做訓練。
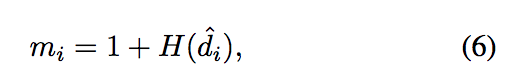
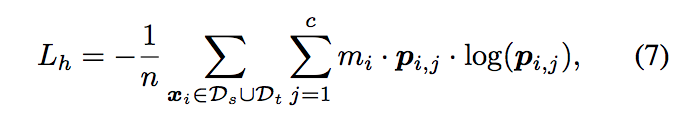
- xi,j : xi to class j
最終公式
與一般的 DA 任務相同,
我們會對 Source domain dataset 去做 classification 來訓練模型。 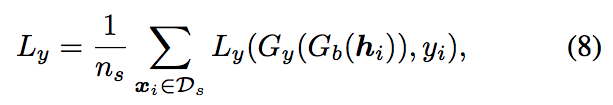
最終公式第 2 行開始為展開,
所以我從 2 ~ 5 這4個式子依序說明,
首先會對 Source domain dataset 去做 classification 來訓練模型,
再來會透過 Global attention 看他相不相似 Source domain ,再將這個權重(m)搭配著 classification 的分類結果去做訓練 ((類似 Weakly-supervised learning
再來就是 Global attention 當作 Domain Discriminator 使用,讓模型對於輸出的特徵能相似。
最後才是 Local attention。 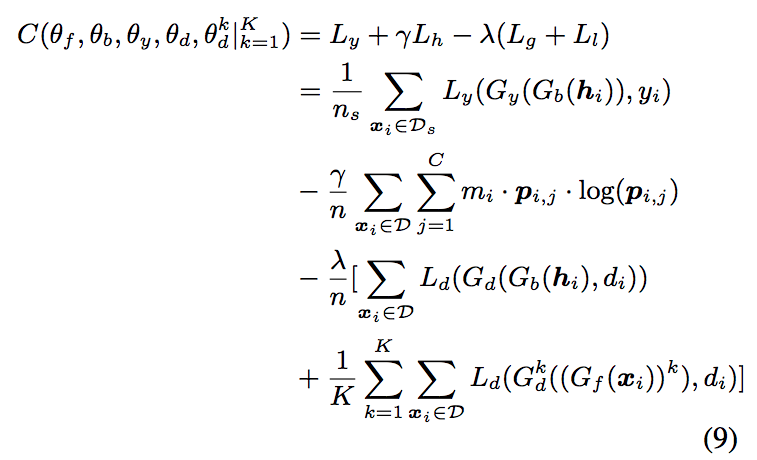
實驗
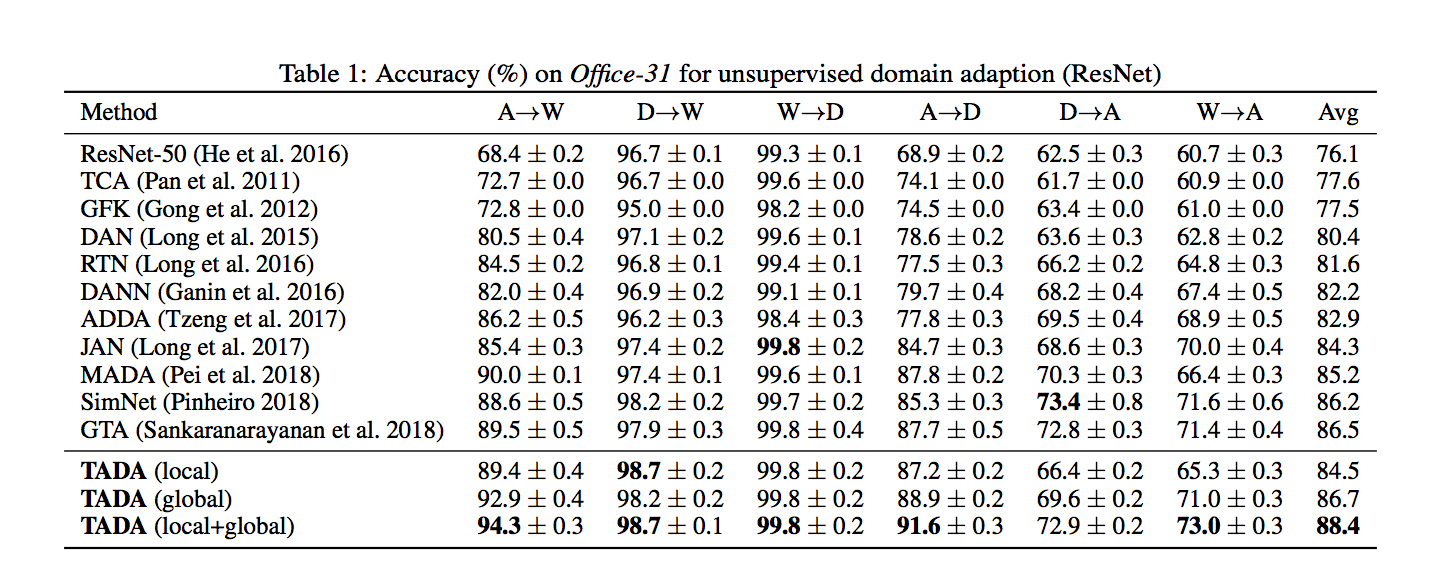
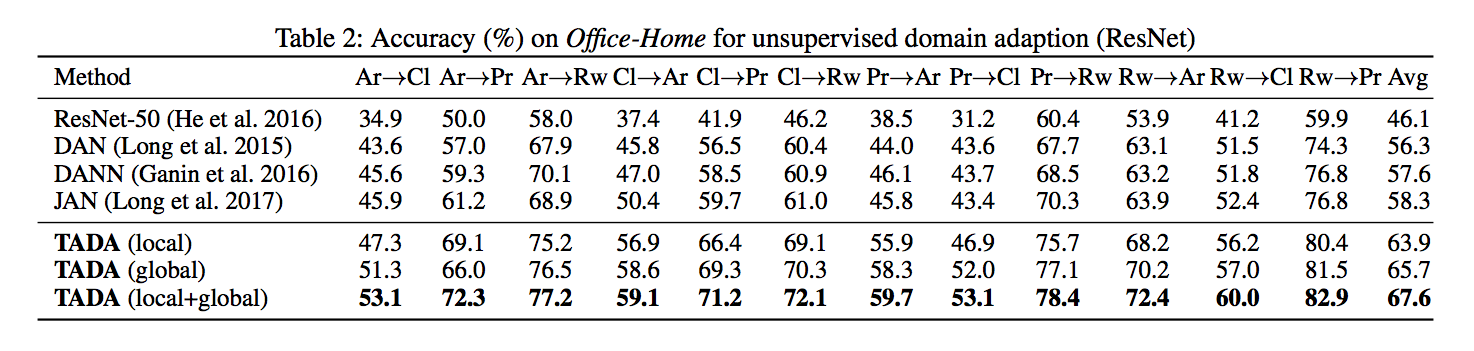
使用 Office-31、Office-Home、ImageNet-Caltech 等資料集測試,
使方法使用 ResNet-50 改進,
實驗細節有興趣的自己去看論文。
用 t-SNE 看特徵分布。
