ST-GAN簡介 - Spatial Transformer Generative Adversarial Networks for Image Compositing
Chen-Hsuan Lin, Ersin Yumer, Oliver Wang, Eli Shechtman, Simon Lucey. “ST-GAN: Spatial Transformer Generative Adversarial Networks for Image Compositing”. CVPR’18
CVPR 2018 paper
Github code(tensorflow):https://github.com/chenhsuanlin/spatial-transformer-GAN
前言:看這篇是因為注意到這篇下面這篇,下面這篇有使用到 ST 的模組當作核心,因此才來看這篇 ST-GAN。
Donghoon Lee, Sifei Liu, Jinwei Gu, Ming-Yu Liu, Ming-Hsuan Yang, Jan Kautz. Context-Aware Synthesis and Placement of Object Instances. In NIPS’18
簡介
此文主要是針對前景物體的幾何校正(Geometric corrections),
這問題是給定一張前景物體的圖片以及一張背景圖片,
我們的生成器要將前景物體插入到背景圖片中適當的位置,
舉例來說給定一個臥室的背景照片,
我們希望插入一張床,
那生成器會找哪邊適合安置床的位置。

本文提出 ST-GAN 的架構來解決這個問題,
並且使用 iteration 的方式來不斷的調整物體的位置,
藉此達到更好的效果
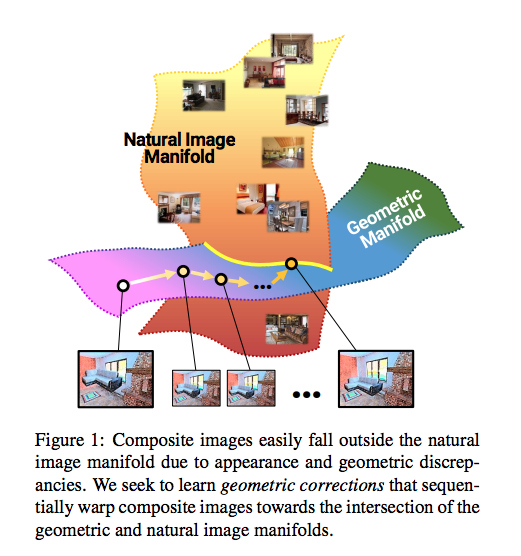
對不同資料集進行實驗,
比較有趣的是應用於配戴眼鏡的任務(透過 Unpair 的訓練,後面會提到。)
基礎概念
在圖像合成(Image compositing)的任務中,
最終目的要將前景圖片(I_FG)插入到背景圖片(I_BG),
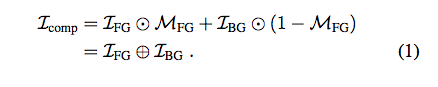
主要有兩個困難點
- 前景圖片與背景圖片的畫風/材質不同
- 幾何形狀的不同,可能是攝影機拍攝的角度導致物體型變或著是位置有誤差,因此需要求得 I_FGu 應該要在哪個位置插入 - Mask(M_FG)。
而本文是針對第 2.幾何形狀的任務去做改善,
我們希望前景物體要與背景圖片的視角(camera viewpoint)相同,
並且插入的位置(position)要合理,
舉例來說一張床浮在空中這就很不合理,
因此我們要找到對應的位置。
而以往的方法是透過模型去學會如何變形圖片,
但是直接變形高維度圖片是相對困難的事情,
而本文提出使用 homography transformation 來讓圖片形變,
推薦可以看一下這個:Slideshare:Spatial Transformation 大概就能知道是如何透過 homography matrices 形變。

因此此文的重點是我們要如何讓生成器學會 homography matrices 的 8 個參數值。
p 即為我們的參數值,
我們將 p 當作 homography matrices,
將前景圖片(I_FG)藉此形變(wrap)之後再插入到背景圖片(I_BG),
這樣就能得出 ST-GAN 所生成的合成圖片(Icomp)。
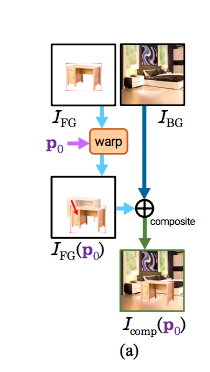
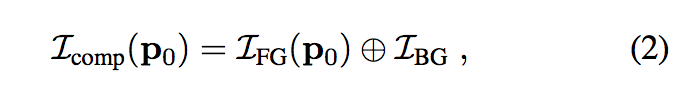
架構
我們的輸入是前景(I_FG)以及背景圖片(I_BG),
輸入背景的原因是因為要讓模型知道這個前景物體應該插入到背景圖片的哪個位置。
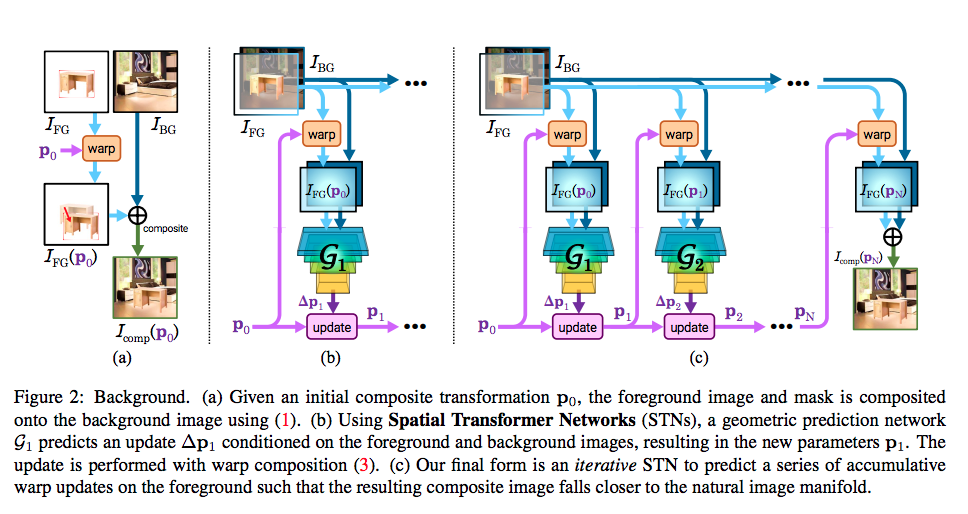
而此模型的重點是使用生成器來學會 p 的參數,
一開始的 p0 是事先給定的經由資料集的分佈得來,
後續的 p1…i 都是經由生成器所學來,
我們最終的結果是 Icomp(pi) - 對前景圖片使用 pi 參數變形,並且插入到背景圖片中。
整體架構有 i 個 G 原因可見下方 Sequential Adversarial Training,以及 1 個 D。
Iterative Geometric Corrections
之所以要循序的求得參數 p1…i 的原因是我們很難透過 wrap parameters 來造成很大的形變,
所以這邊的想法是要循序(iterative)的形變,
iterative 也是近年挺常用的 trick,
這其實可以讓你一開始的結果可以不用很準確,
透過 update 對參數更新
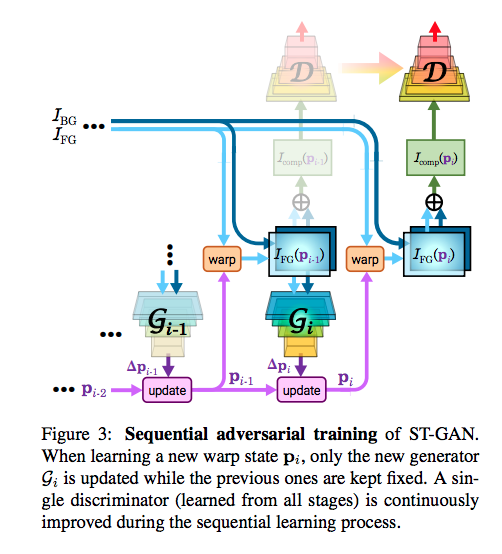
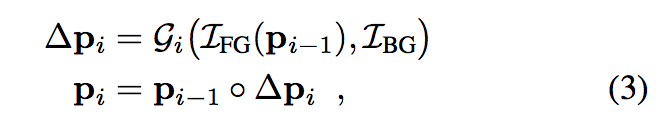
Sequential Adversarial Training
為了要讓插入的物體符合原本的背景圖片,
因此使用 GAN 架構,
而使用 GAN 有兩個目的,
- 前景圖片可能可以插入到背景圖片的好多個地方,如床可以放在房間的不同地方,因此這是個 multi-modal 的問題
- 使用 Supervised 的方式在此方法通常是不可行的,這部分論文沒有給出一個原因,因此這邊不多作猜測。
備註:從 1th G 開始訓練,訓練到第 ith 個 G 的時候, 1…i-1th 的 G 權重會 freezed。
而我們只會使用 1 個 D,
這個 D 主要負責辨認圖片真偽,
會輸入各個 Gi 的輸出 Icomp(pi)

Objective Function
採用 W-GAN
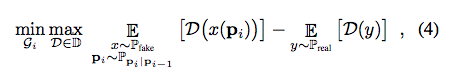
並且結合 WGAN-GP 的 gradient penalty - Lgrad
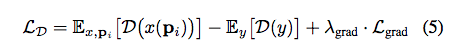
以及避免 G 故意捨棄前景或是將前景的資訊移動到外面之類的,
所以我們使用 L_update 避免 p 過大,
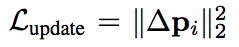
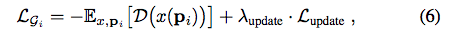
實驗設定及模型架構
我們前景輸入圖片 (RGBA),
背景輸入圖片(RGB),
因此我們輸入至 G 共有 7 個 channel。
C : convolutional layer
L : fully-connected layer
G 的架構為 C(32)-C(64)-C(128)-C(256)-C(512)-L(32)-L(8),
重點就是最後用 Fully-connected 輸出 8 個數值。
D 的架構為 C(32)-C(64)-C(128)-C(256)-C(512)-C(1)。
G 使用 Activation - Relu
D 使用 Activation - LeakyRelu(slope-0.2)。
備註:他沒使用 normalization layer,他表示發現使用後會降低訓練效能,並不清楚實際狀況。
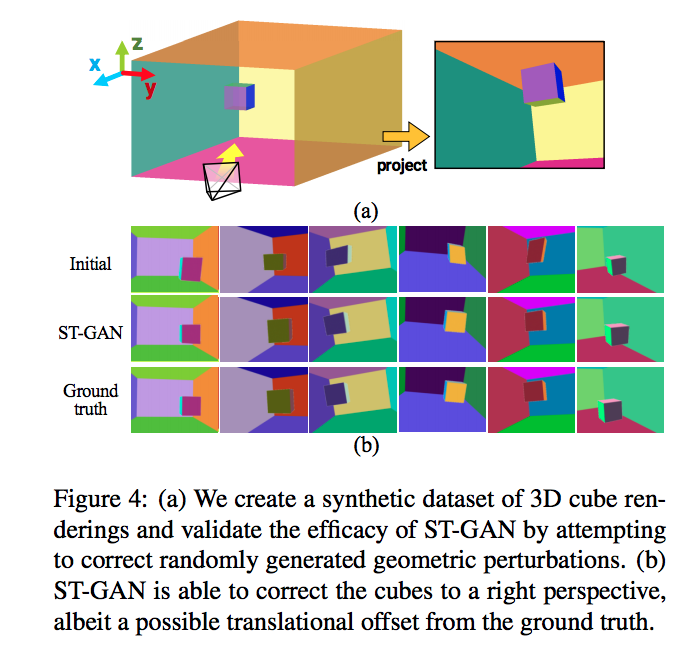
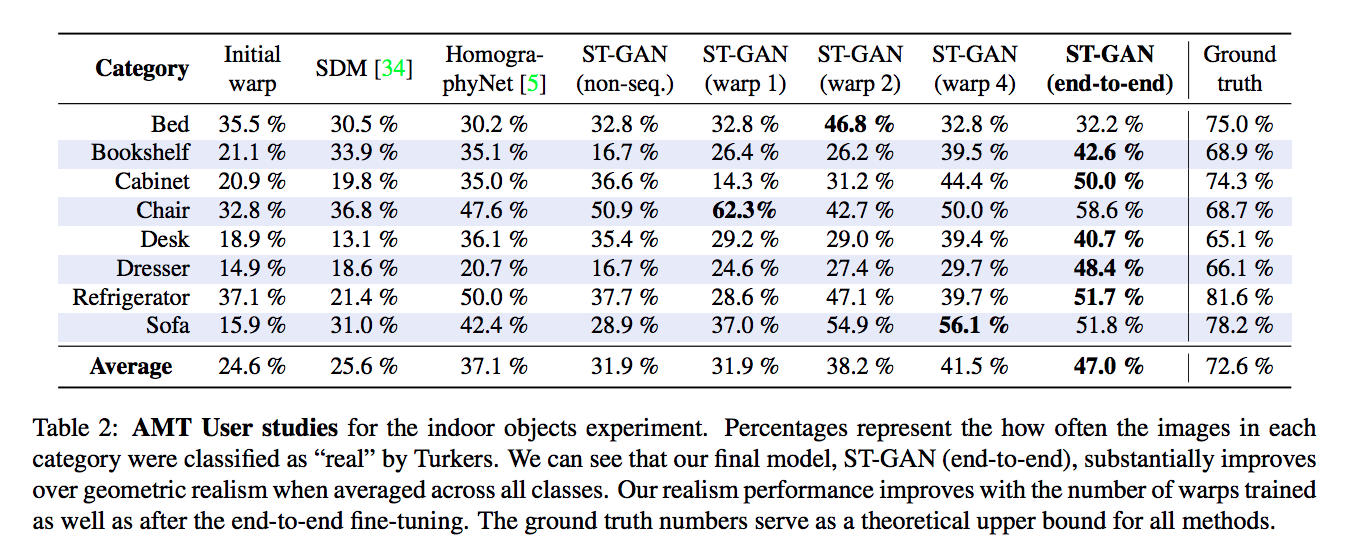
成果
此文中有自己合成資料集,
經由擺動攝影機等方式,
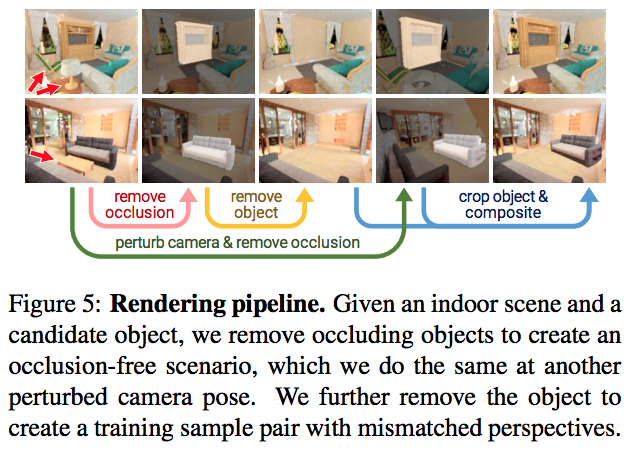
這邊不贅述太多,
直接貼成果以及覺得有趣的部分
比較有趣的是眼鏡的實驗,
以往我們做研究都是給定同一個人戴眼鏡/不戴眼鏡的圖片去訓練,
但是在 CelebA 的資料集中,
“沒有”一個人是有著戴眼鏡與不戴眼鏡的照片,
因此改變策略為將資料集區分為戴眼鏡(Real)與沒戴眼鏡(Fake)的人當作訓練集,
這部分稱作 Unpair !!!
我覺得這招術還挺有趣的~
並且將戴眼鏡的人的眼鏡手動的擷取下來,
擷取出10副眼鏡,如下圖。

最終成果如下

(a)每個 G 的 output。
(b)上面那排是 initial 的 composite Icomp(p0),
下面那排是輸出,
而最後下面那排照片是 failure case。
備註:
在這實驗他有提到在 data augmentation 時若將人臉旋轉至超出圖片的話,這樣訓練會訓練不好。
值得一提的是,
訓練時是使用低解析度訓練,
但是在 test 時可以使用高解析度圖片。




參考資料:
ST-GAN: Spatial Transformer Generative Adversarial Networks for Image Compositing