CoordConv簡介 - An Intriguing Failing of Convolutional Neural Networks and the CoordConv Solution
Rosanne Liu, Joel Lehman, Piero Molino, Felipe Petroski Such, Eric Frank, Alex Sergeev, Jason Yosinski. “An Intriguing Failing of Convolutional Neural Networks and the CoordConv Solution”. In NIPS’18
NIPS 2018 paper
Paper link:https://arxiv.org/abs/1807.03247
Github code:論文有給連結,但是連結失效。
可關注 Uber Repo:https://github.com/uber-research
Demo Video(部分展示,可忽略不看): https://www.youtube.com/watch?v=YefMbLqS7Jg
其實這是篇透過大量實驗來驗證 CoordConv(此論文提出的方法)是否有效,
所以寫完發現好像也沒什麼東西。。。
有興趣的可以看論文得知實驗的細節。
簡介
以往的我們對於像素或者空間資訊關聯的任務通常會採用 CNN 處理,
在此篇透過一些簡單的座標轉換(coordinate transform problem)任務來探討 CNN 是否能夠有效的處理,
結論是 CNN 其實無法有效地處理空間上的關係。
因此提出 CoordConv 的方法來處理座標間的關係,
他的想法很簡單,
就是多加入 2 個 Channel 各自代表 x 與 y 座標的 Channel,
就可以有效的學習座標間的資訊。
透過一系列任務的探討,
展示出 CoordConv 可以有效地幫助模型學習空間的關係,
簡單提一下使用 CoordConv 帶來了哪些好處,
若在 GAN 以及 VAE 中使用緩解了 mode collapse 的問題,
並且在大型的 GAN 架構中有觀察到使用了 CoordConv 提供了幾何轉換(geometric transformation)的概念,
而幾何轉換是單純使用 CNN 架構的 GAN 所沒有觀察到的現象。
若是將 CoordConv 加入 Faster R-CNN 的架構在 MNIST 的資料集做數字偵測可提升 24% 的 IOU。
甚至在 Reinforcement Learning (RL) 的任務也有提升效能(這部分這邊不提)。
方法
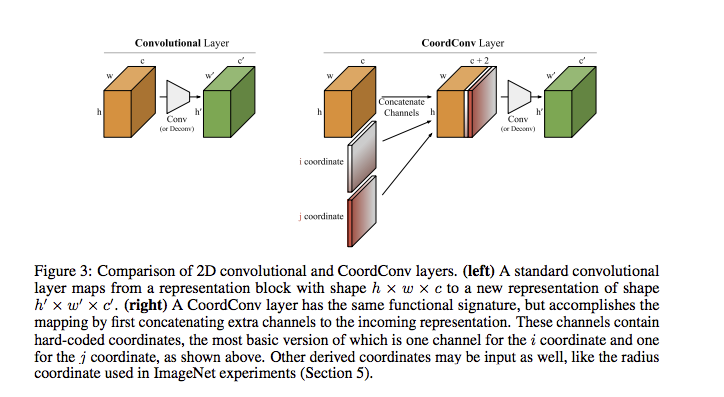
簡單來說就是多加入空間資訊,
說白了就是一個 Channel 加入的是 x 軸的座標,
另一個 Channel 加入的是 y 軸的座標,
加入這 2 個 Channel 就能讓輸入有更明確的空間資訊,
下圖以 2x3 的矩陣做示範。

不過實際在運作的時候有做 normalize 的動作,
設定在 [-1, 1] 之間,
有一些實驗還有添加 r coordinate(添加第 3 個 Channel),
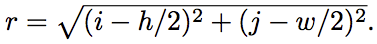
總之呢,透過添加 2 個 Channel 的資訊來增加空間位置的資訊,
相較於使用 One-hot encoding 的空間資訊,
使用 CoordConv 是非常節省空間以及運算資源的。
實驗
使用下方的任務來驗證 CNN 與 CoordConv 的效能差異
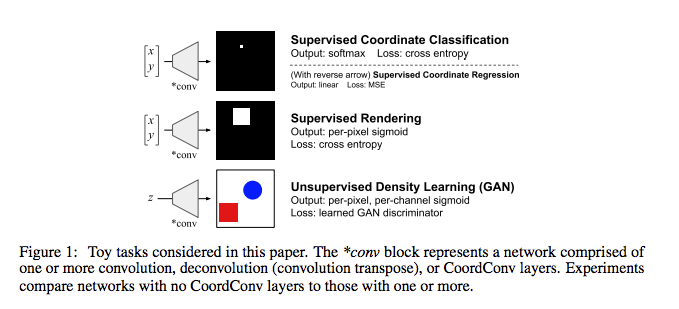

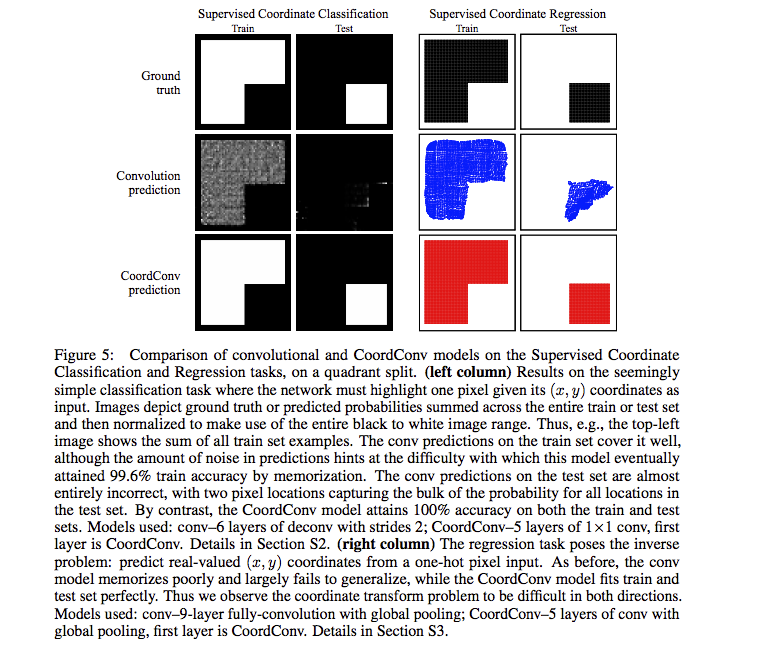
- Supervised Coordinate Classification task:輸入 x, y,輸出一張圖片只有 x, y 為白色1,其餘位置都為黑色0。
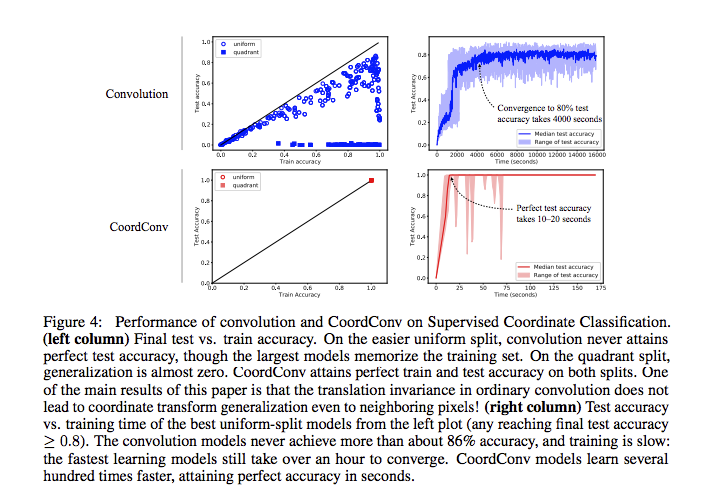
我們發現使用 Convolution 的方法僅能夠達到 80% 的準確度,
當添加 CoordConv 的時候就可以達到趨近於 100% 的準確度。
- Supervised Rendering task:輸入 x, y,輸出一張圖片以 x, y 為中心,畫出一個白色正方形,其餘位置都為黑色。
Object Detection: 在偵測 MNIST 的資料集中,相較於沒有使用 CoordConv,加入 CoordConv 後讓 IoU 提升了 24%
Generative Model: 這邊是假設 mode collapse 的問題是因爲 latent space 無法學習好空間的相關性所導致的,而這時候使用 CoordConv 或許會有幫助,感覺是結果論。
VAE model 也是同理。


結論
此論文展現 CNN 對於座標轉換的任務無法處理得很好,
並且提出 CoordConv layer 來改善這個問題,
在此論文透過大量的實驗來證明這方法可以改進以往框架並且得到更好的結果,
未來可能會朝向幾個方向去研究 Relational reasoning, language tasks, video prediction, spatial transformer network 以及 cutting-edge generative model。
程式碼實做(論文上有給) - tensorflow


參考資料:
An Intriguing Failing of Convolutional Neural Networks and the CoordConv Solution