InstaGAN簡介 - Instance-aware Image-to-Image Translation
Sangwoo Mo, Minsu Cho, Jinwoo Shin. “Instance-aware Image-to-Image Translation”. In ICLR’19
ICLR 2019 paper
Paper link:https://openreview.net/forum?id=ryxwJhC9YX
Github code(PyTorch):https://github.com/sangwoomo/instagan
前言:此文的 Instance-mask 是由 dataset 提供,並非使用模型預測的。但是可以使用預測的 Segmentation label 做轉換也能得到不錯的效果。


簡介
本文提出 Unsupervised image-to-image translation,
主要是基於 Cycle GAN 作延伸的,
結合了 Instance mask 或是 Object semantic mask 來讓圖像轉換的更好,
以往多物件靠得很近相連時,
會覺得轉換完後怎麼都連在一起了。
而本文提出針對個體(Instance)轉換的改善。
因此本篇的重點是 multi-instance transfiguration.
以往的圖像轉換多為單一物件的轉換,
但是本文提出多物件轉換,
並且提出 Sequential mini-batch inference/training 避免物件過多時,
轉換途中超出記憶體的問題。
提出此框架 Instance-aware GAN(InstaGAN) 整體結果令人驚艷。

主要為 3 個貢獻:
- 結合 Instance mask 的模型架構(Instance-augmented neural architecture)
加入物件 Mask 的 Image-to-Image 模型。
- Context preserving loss
確保 Instance 轉換後背景的一致性。
- Sequential mini-batch inference/training
確保多數量 Instance 轉換時,不會出現 out of memory 的問題。
以往模型的問題
以往 Image-to-Image 模型在處理下列問題時有時會處理得不好:
- 圖片有多個同類別物件的轉換
- 兩張圖片物體間的形狀差異過大
因此此文主要針對上述兩點做優化,
提出可結合 Instance mask 來輔助多物件的轉換。
因此我們與以往的任務不同,
以往的任務都只是圖片的轉換
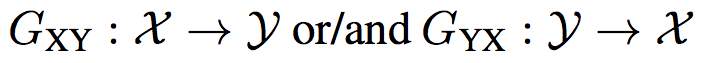
但是我們這任務需要考量到每個 instance 的 attribute (定義為 A, B),
因此稱作 joint-mapping between attribute-augmented spaces。
模型架構
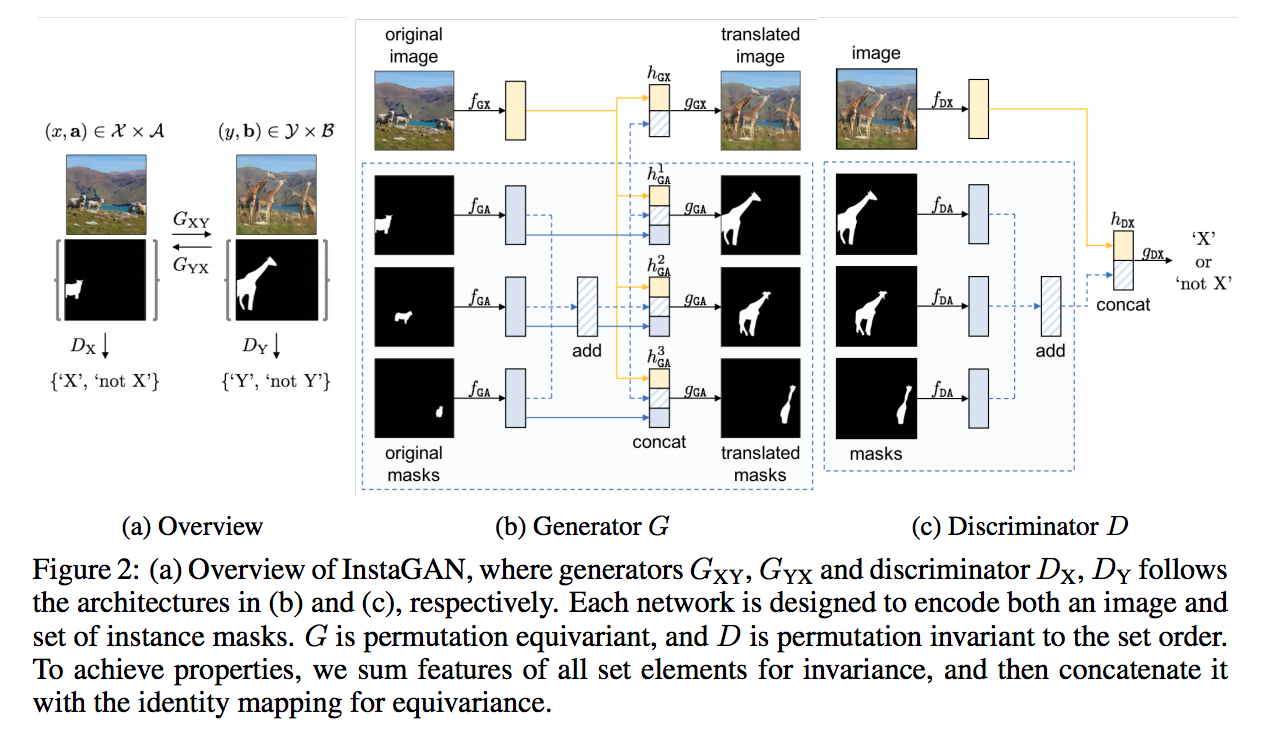
- fGX : 針對圖片的特徵萃取器 - image feature extractor
- fGA : 針對 Mask 的特徵萃取器 - attribute feature extractor
比較值得一提的是 hGX 以及各個 hGA 都有使用到 fGX 的圖片特徵以及所有 fGA 所得出的特徵值加總,
至於加總的原因論文是這樣寫的,確保排列不變性。:
The attribute features individually extracted using fGA are then aggregated into a permutation-invariant set feature。
個人想法
這部分的困難處是我們無法知道每張圖片的物件(Instance)個數(模型內無法事先定義好要有幾個通道之類的)。
那如果我們希望結合所有 Instance 的特徵,只是說除了使用單純的加總之外,是否有更好的方式!?
並且我們的 Discriminator 的輸入為 圖片 以及 最終的 gGA 所產生的 mask,
這邊的想法為可以讓模型學習 圖片 與 物件特徵(Attribute) 之間的關係。
Loss function
與 Cycle GAN 相同的使用 domain loss(LSGAN),
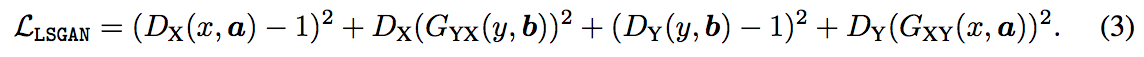
以及常見的 cycle-consistency loss 以及 identity mapping loss.
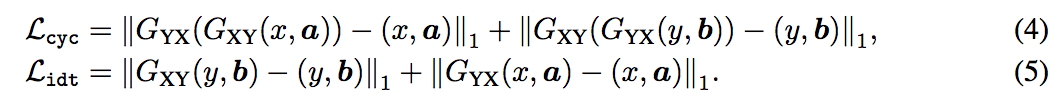
本文提出 context preserving loss - Lctx,
這邊的想法是我們要確保背景的一致性的時候,
會對背景去做 l1 loss,
但是我們在做 Instance 轉換的時候,
Instance 形變後可能覆蓋或著是空出背景,
透過對轉換前後的圖片 Mask 做比對,如果其 pixel 為 mask 的話就不做 context preserving loss,
w: 1 - min(a, b),可理解成如果那個 pixel 為前景 mask 時 w = 0 如果是背景 w = 1。
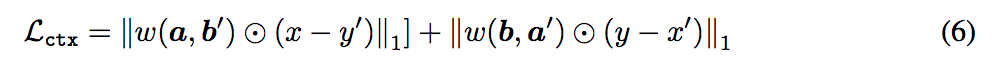
最終整體的 loss 如下:
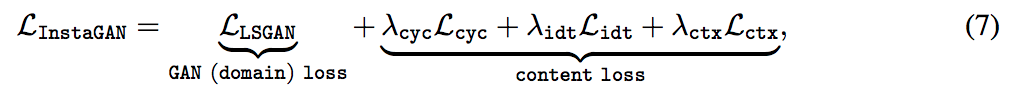
Sequential mini-batch translation
原先提出的架構是希望可以對於 instance 作轉換,
但是當大量的 instance 需要轉換時,
意味著我們需要大量的使用 fGA 的萃取特徵,
並且將所有 fGA 的特徵加總,
還要考量到我們 bp 的時候需要更多的記憶體,
當 instance 數量過多時勢必會面臨到 out of memory 的問題。
因此本文提出此方法來避免這個狀況。
說白了就是一次只轉換少部分的 instance,
因此稱作 mini-batch,
而這樣多做幾次就會把所有 instance 轉完了。
但是做這件事不只可以解決記憶體上的問題還帶來額外的好處,
舉例來說:原本 4 隻綿羊要轉換成 4 隻長頸鹿,
那我先轉換 2 隻綿羊成長頸鹿 => 2隻長頸鹿 + 2隻綿羊,
接下來再轉換 2 隻綿羊成長頸鹿 => 4隻長頸鹿 + 0隻綿羊。
這樣做處理的話其實可看作是一種數據增強(data augmentation),
這樣 Discriminator 可以一直看到不同的生成圖片。

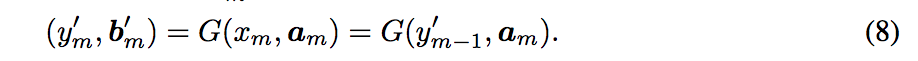

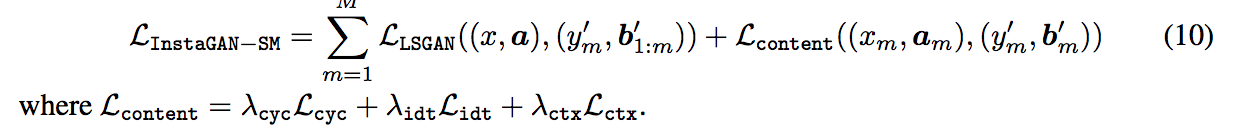
實際上在實作時,
會從尺寸大的 instance mask 先做,
發現透過這方式會比隨機挑選 instance mask 成果來得好,
這邊給出一個想法是小物體如果先作轉換的話,
之後可能會被大物體轉換後所遮擋。
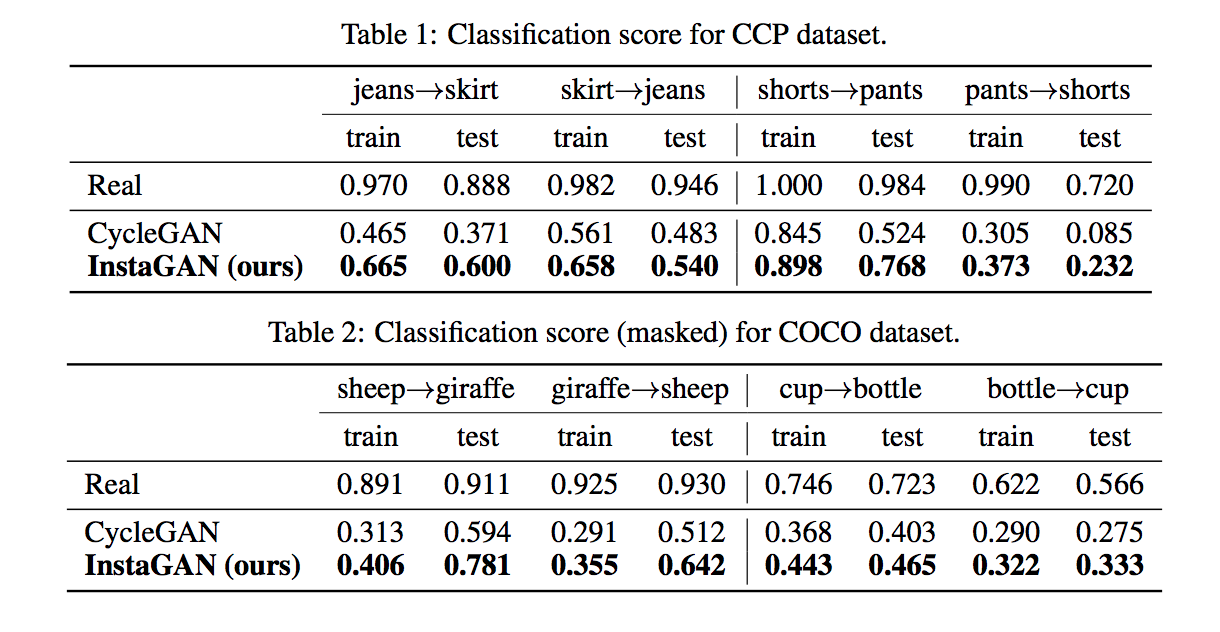
實驗結果
即使使用自己預測的 Segmentation mask 也能得到不錯的效果。
下方的都是使用 Instance mask 作轉換。





透過物件分類模型評分,
觀察轉換出來的圖片是否能讓分類器辨認出那個類別。