OCNet語意分割模型簡介 - Object Context Network for Scene Parsing
Yuhui Yuan, Jingdong Wang. “OCNet: Object Context Network for Scene Parsing”. In ArXiv preprint.
此論文於 4 Sep 2018 提交至 Arxiv,目前尚未被 Conference 接收。
Paper link : https://arxiv.org/abs/1809.00916
Github code(PyTorch) : https://github.com/PkuRainBow/OCNet.pytorch
其他的補充資料 : 知乎:Fast-OCNet(原作者專案的延伸)
小建議:
建議先看 v1 版本的: https://arxiv.org/abs/1809.00916v1
再閱讀後續的改動版本,
因為 v1 版本參數定義的較為清楚,直接看v3版本的話,對於v3的 eq1 應該會有點疑惑。
簡介
本文提出名為 OCNet 的語意分割模型,
靈感是來自取自 NLP 領域近期相當有名的 Self-Attention 的架構,
提出 Object Context Pooling (OCP)的架構,
他主要的想法是希望將同類別的像素都看作一體(Context aggregation strategy),
我們可以看到下圖,
當我們選定(紅色十字)某像素時(下圖左),
OCP 的架構可以將與該像素相似的像素都提取出來(下圖右)。

Q : 為什麼這會帶來好處?
可以去看知乎:Fast-OCNet(原作者專案的延伸)這篇對於 Context 的說明,
他的想法是將 Context 定義在物件上,
相同類別的物件,其像素視為一體(上圖右),
與以往的不同之處在於,
以往是將 Context 定義在場景上,
現在改在物件上試試。
以及以往的語意分割模型都是使用空間上的鄰近資訊來優化,
如 PSPNet 的 Pyramid Pooling Module 或是 Deeplab 的 ASPP 來增加感知視野提升準確度,
那上述兩種方式都會帶來一個問題,
空間上的鄰近資訊並不見得代表同一個類別,
舉例來說車子在道路上跑,
那在兩者的邊界處時,使用上述得方法,
所得出的結果是會混合著兩種類別的資訊,
該結果可能會降低模型的準確度。
但此文使用 Self-attention 的方式,
讓模型可以擺脫空間上的鄰近資訊,
變為更長範圍(long-range)。
我認為這篇文章應該要搭配 Self-Attention Generative Adversarial Networks 一起看,
才會對 Self-attention 在電腦視覺上的應用有更好的理解。
下圖取自 Self-Attention Generative Adversarial Networks
使用 Self-Attention 的特點為長範圍(long-range),
並且可以擺脫以往 CNN 只能空間上鄰近的限制。

整篇文章也有人用 CNN + Nonlocal 總結,
而 nonlocal 的部分指的就是 Self-Attention 所能達成的的超越鄰近空間。
架構
此處我會混合著論文的 v1 以及 v3 搭配著講,
這樣可能會比較好理解。
整體的流程如下
下圖出自 v3 版本
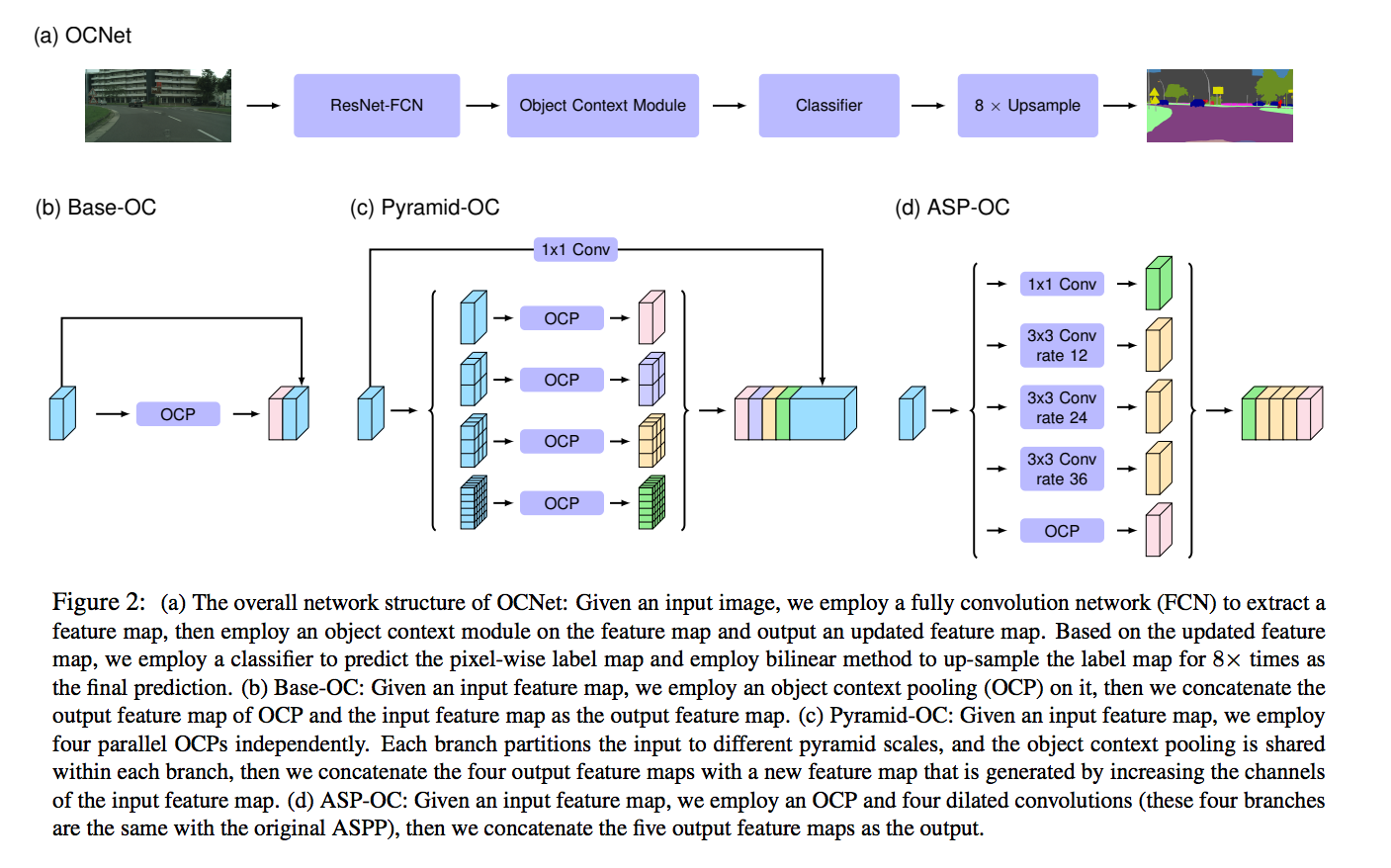
從上半部可知,
我們先經過 ResNet-FCN 萃取出特徵 X,
接著我們會將 X 輸入進 Object Context Module(OCM) 得到一個新的特徵,我稱作 C 好了
最後輸入進 Classifier 的特徵為 X 與 C 的拼接(concat),
因此 Feature map 的維度為 (X的dim + C的dim)。
接下來說明本文最重要的 Object Context Module(OCM) - Base-OC 的部分。
至於 Pyramid-OC 和 ASP-OC 算是延伸,
此處不講。
Object Context Module(OCM)
主要是透過 Self-Attention 的概念做延伸,
先說明什麼叫 Self-Attention,
即為輸入只有一個,自己對自己做 Attention。
其實這邊我們看 SA-GAN 的架構圖會比較好理解
下圖架構圖出自 Self-Attention Generative Adversarial Networks
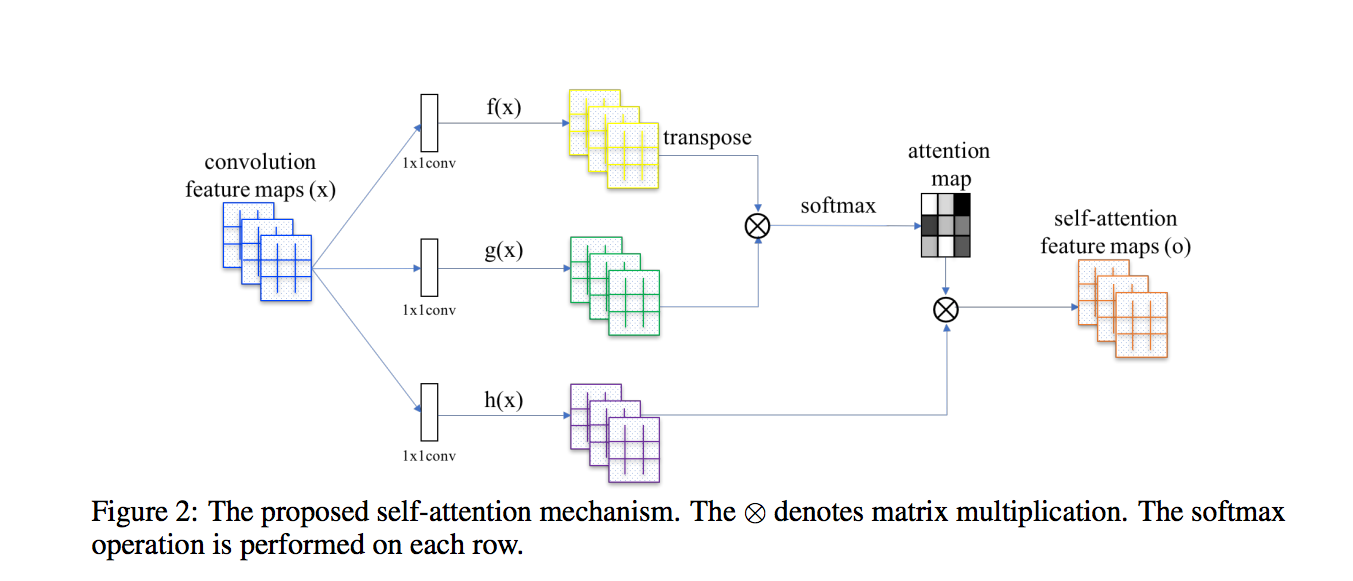
看懂上面圖之後,
我們來看一下本文的 v1 所給出的架構圖,
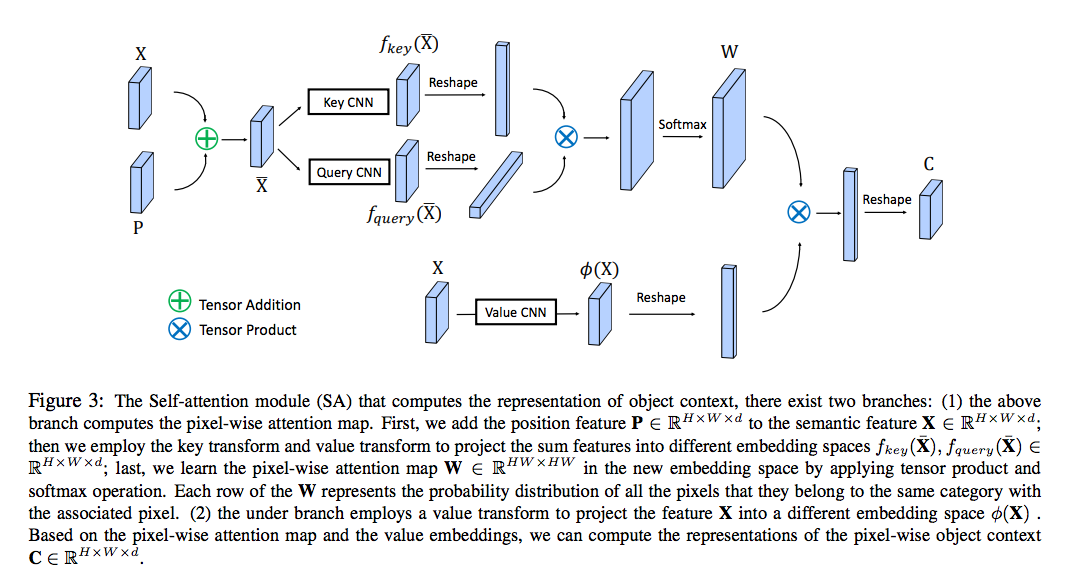
其實跟前面 SA-GAN 很像對不對~
其實概念也差不多,
我們可以看一下上半部的 Key and Query CNN,
Key and Query 這兩個在做的是將相同類別的物件視為一體,
模型學習相像的關鍵是基於 Feature 之間相不相像,
為什麼不是使用 Label 可以看 v1 的論文,有點瑣碎又不是很重要就不提了。
因此使用 Key and Query 學習在 Feature maps 中的相像程度,
最終得出的相像程度就為 W,
這邊的 W(熱力圖) 其實是有意義的,
可以想成這個是代表著每個像素之間的相似性,
Wi,j = 第 i 個 pixel 與第 j 個 pixel 的相似性。(如果兩個是同類別的話,分數會高。
寫成數學式會長這樣(v1版本的),
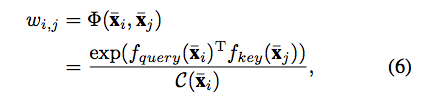
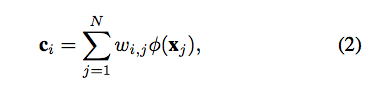
而在 v3 版本中,
為了要強調 Feature 屬於相同類別這件事,
因此這邊定義 p 是某個類別的像素集合,然後符號改一下公式如下。
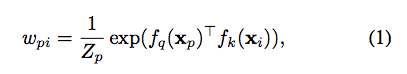
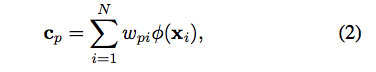
備註:
v1 版本的 OC Module 有 P(空間資訊輔助),可是在後續版本就把 P 移除了,因為 P 的幫助不大。
詳情參考此 OCNet:Issue30
實驗結果
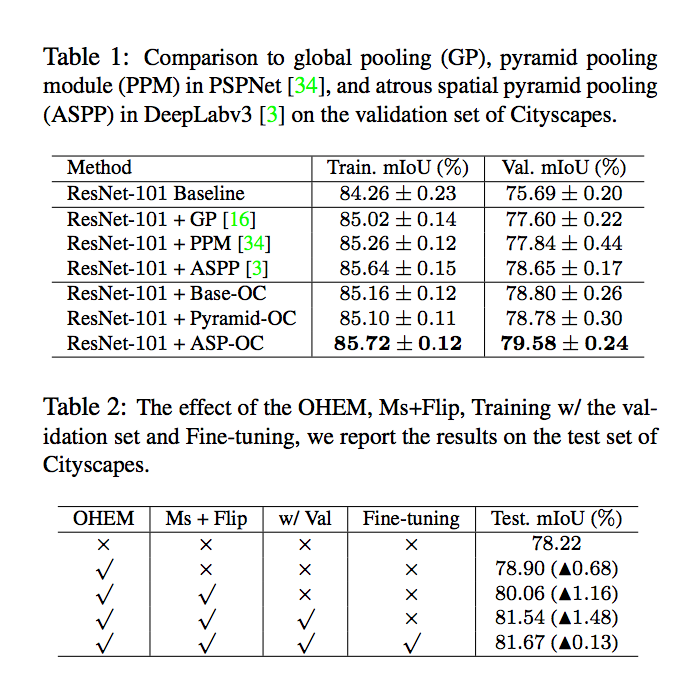
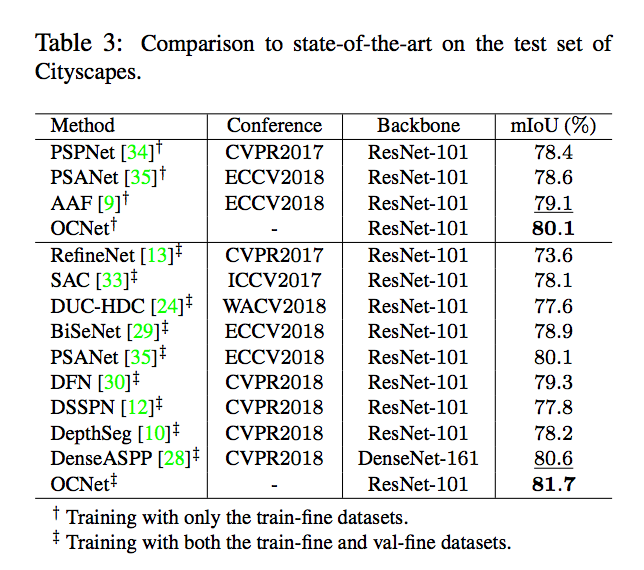
對此實驗感到疑惑的部分
關於這張圖片的視覺化部分,
我目前不清楚他到底怎麼實做出來的,
如何基於某個 Pixel 並經由 Self-attention module 能畫出這麼漂亮的圖。
btw,
OCNet 以及 SA-GAN 都是使用 Self-attention 的架構,
並且都有基於某個選定的 Pixel 去畫出視覺化圖片呈現,
但都沒有放出相關的程式碼,
有興趣的可以和我關注下方兩個 Issue~
都發布已久但是作者都沒放出程式碼,真巧。
後續:
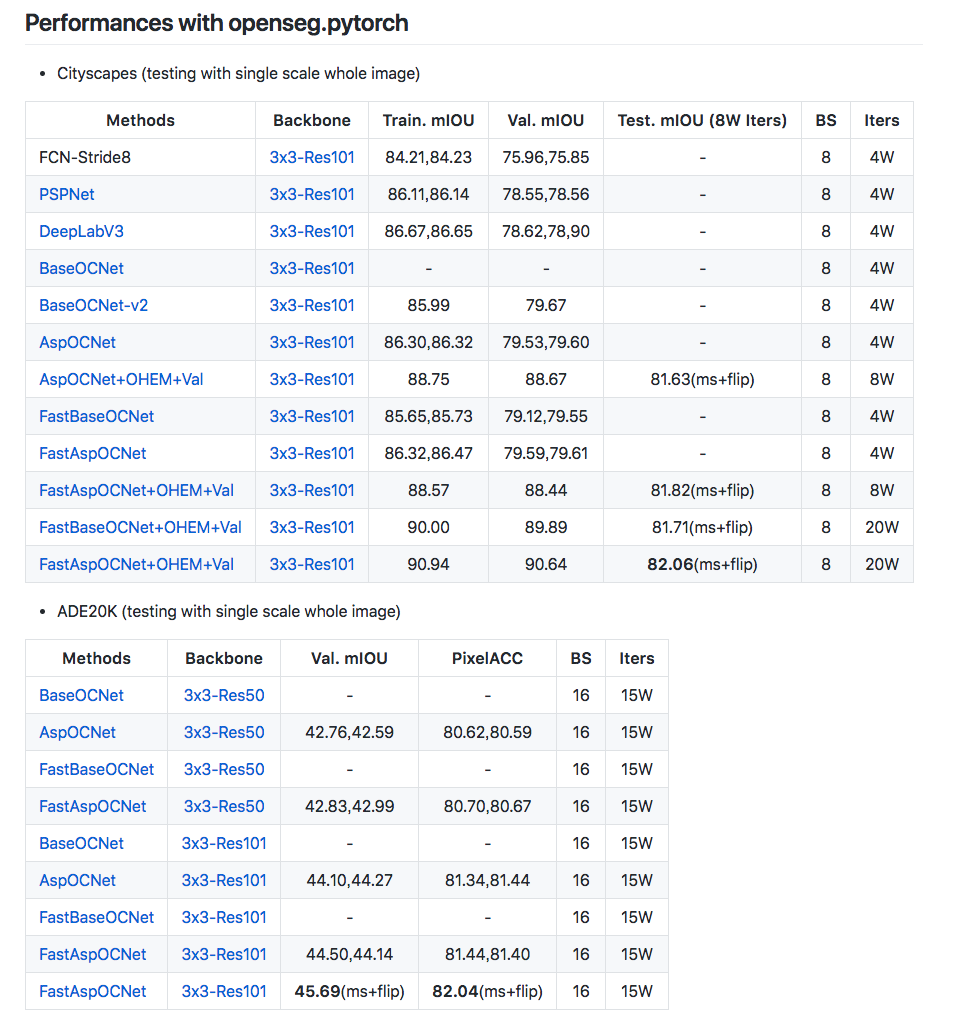
近期該團隊透露了 Github:Fast-OCNet 的語意分割模型,
提出不使用 Self-attention 架構,
但也能達到同等甚至更好的性能,
如果認真看 Self-attention 架構會發現它的架構非常的佔用內存,
顯卡的內存很寶貴的。。。
目前只放出結果,沒有程式碼,
有興趣的人請持續關注此專案 Openseg!
https://github.com/openseg-group/openseg.pytorch
參考資料:
OCNet: Object Context Network for Scene Parsing