GeoGAN簡介 - Instance-level Facial Attributes Transfer with Geometry-Aware Flow
Weidong Yin, Ziwei Liu, Chen Change Loy. “Instance-level Facial Attributes Transfer with Geometry-Aware Flow”. In AAAI’19.
AAAI 2019 paper
Paper link : https://arxiv.org/abs/1811.12670
Github code(PyTorch) : https://github.com/wdyin/GeoGAN

簡介
本文提出名為 GeoGAN 的人臉特徵轉換模型,
並且不需使用成對的資料集即可訓練,
舉例來說當我們想要訓練模型學習鬍子的特徵時,
我們不需要同一人有鬍子的照片以及沒有鬍子的照片,
這樣大幅降低了資料集的收集難度,
透過此框架可將目標圖片的特徵融合至原圖,
並可生成出高解析度的圖片。
主要概念是透過基於人臉特徵(68個 landmarks)訓練的光流法進行人臉轉換,
透過光流法我們可以針對 2 個不同的臉部進行變形,
達到 Geometry-Aware 功能,
再透過其他網路來提升圖片轉換的仿真度。
特點
- 特徵轉換後該特徵合成至原圖時看起來無違和
- 可將兩張高解析度的圖片互相轉換
- 突破以往 Semantic-level 的轉換
以往某些人臉轉換的方法需要 Semantic label 不易使用。
示意圖,圖片出自 pix2pixHD

架構 - Instance-level Attribute Transfer Network
整體架構如下,會慢慢拆解。
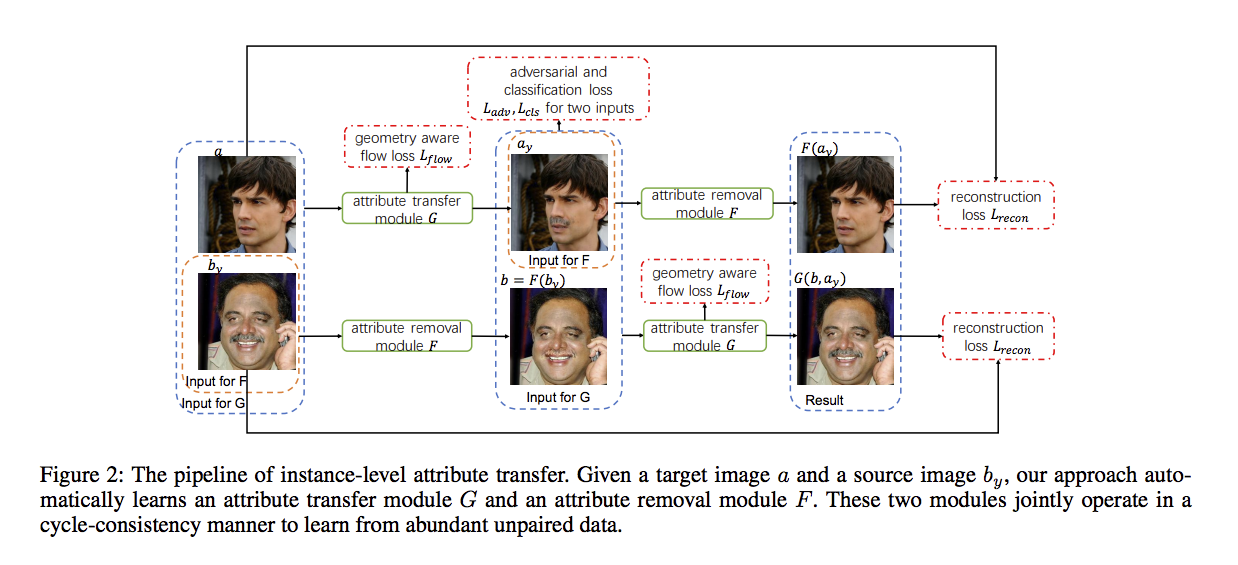
我們會有兩個 Dataset(資料夾)
- A - 人臉圖片 - a
- B - 人臉圖片 - b 有著某個我們希望有的特徵(y) - by 最終我們希望 a 能夠有著 b 的特徵。
備註:
A、B 的人不重複,
舉例來說我們希望有的特徵 y 是鬍子,
不需要有同一個人在同一張場景有著有鬍子的照片以及沒有鬍子的照片,
因此是 Unpair Training。
Attribute Transfer Module
目標在於希望可以將特徵 a 能夠忠實呈現 by 的特徵 y,
原本的難題是臉部表情的不同,
而 b 的特徵 y 也要能夠配合 a 的人臉表情做變形。
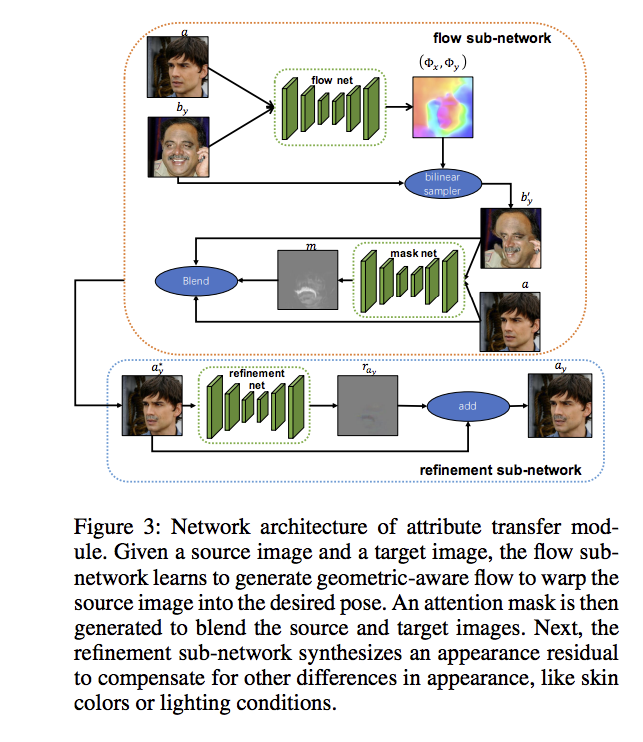
Flow Sub-Network
透過光流法將 Target - b 的圖片中的人臉位置變形成 Source - a 圖片的人臉位置。
下方公式 eq1 視為 bilinear sampler 的部分
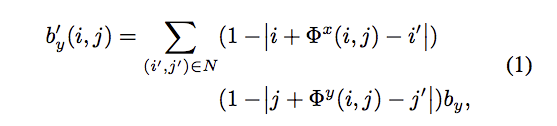
可微分雙線性取樣,
簡單來說就是光流法後的圖為 It, 原圖為 Is,
而 It (i, j) 是經由 Is (x, y)的 4 個鄰近像素所組成。
原理 In NIPS’15 Spatial Transformer Networks
另一種解釋可參考 In ECCV’16 View Synthesis by Appearance Flow
經過轉換後,可以看到 b 已經變形 - b’y,
而此時我們希望萃取的特徵(鬍子)也同樣跟著人臉變形,
透過 Mask net 提取出鬍子的區域 - m,
下方公式為 Blend 部分,將鬍子混合至 Source 圖片 - a。
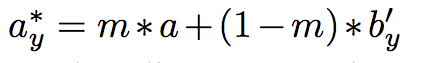
並貼上至 a 圖片, 此時稱作 a* ,

Refinement Sub-Network
給定轉換後的圖片 ay* 當作輸入,
我們希望可以針對細節做處裡, 如皮膚顏色、光線等等,
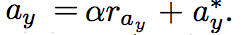 備註:
備註:
α is a hyper parameter

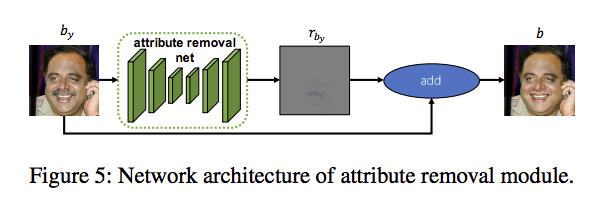
Attribute Removal Module
我們會訓練 Attribute removal module - F 來學習我們是否能夠移除特定特徵,
他的想法是如果能夠移除,
代表他學會這個特徵(instance-level),
學會移除特徵後,
就可以搭配使用 Reconstruction loss 來讓模型可以訓練得更穩定。
做法和 Refinement Sub-Network 差不多,
Objective function
Adversarial Objective
採用 LS-GAN, 希望 G 能產生出讓 D 分不出的圖片。 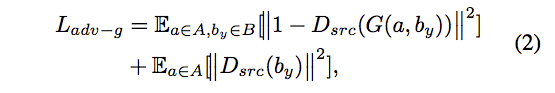
並且鼓勵 Attribute removal module - F 去學習 Instance-level 的特徵 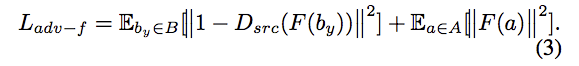
Domain Classification Objective
訓練 Discriminator 學習分辨出有無 y 特徵。
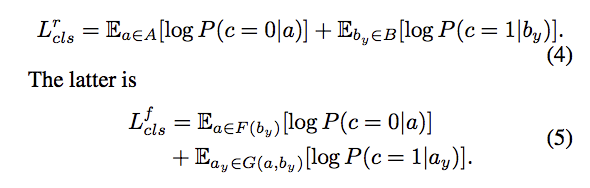
Reconstruction Objective
為了確保我們在進行特徵轉換時,
其他部分的特徵都還是保留住的。
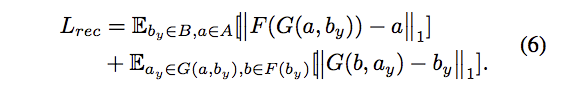
Geometry-Aware Flow Objective
本文重點:主要使用 landmark loss 來訓練 Flow Sub-Network 的部分,
透過 Flow Sub-Network 來達到 Geometry-Aware 的概念。
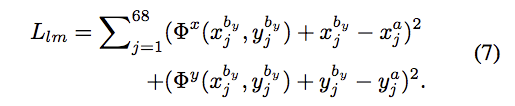
再結合 TV regularization 讓模型訓練起來更平滑。
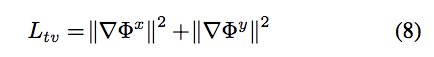
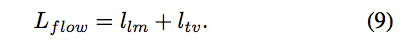
Overall Objective
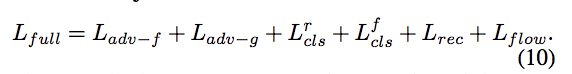
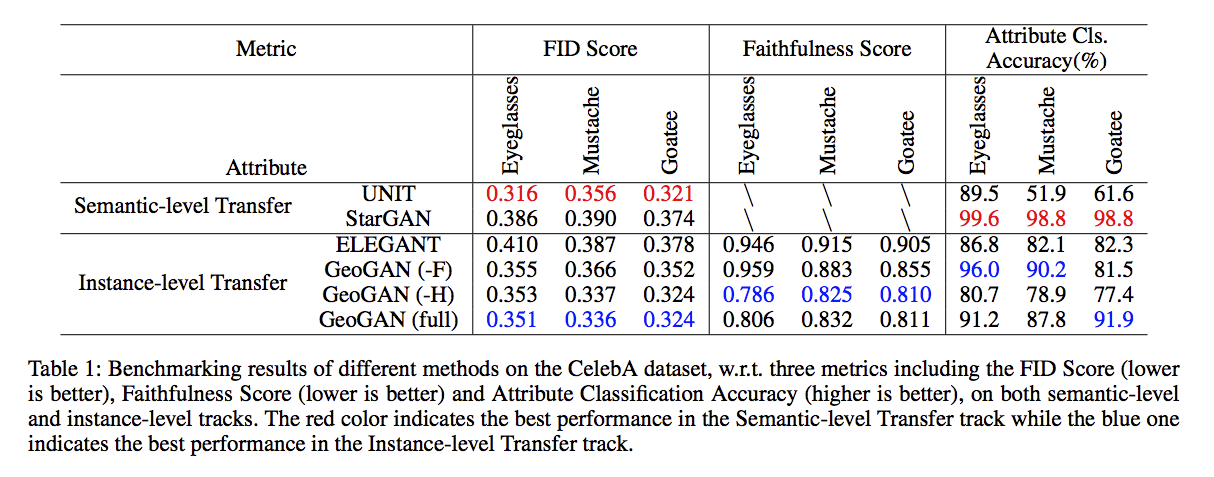
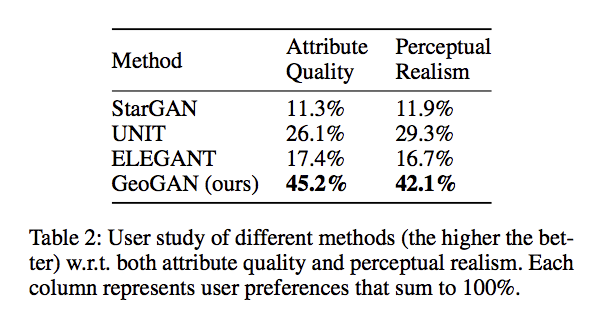
成果




參考資料:
Instance-level Facial Attributes Transfer with Geometry-Aware Flow