SC-FEGAN人臉圖像修復任務簡介 - Face Editing Generative Adversarial Network with User's Sketch and Color
Youngjoo Jo, Jongyoul Park. “SC-FEGAN: Face Editing Generative Adversarial Network with User’s Sketch and Color”. In ArXiv preprint.
此論文於 18 Feb 2019 提交至 Arxiv,目前尚未被 Conference 接收。
Paper link : https://arxiv.org/abs/1902.06838
Github code(Tensorflow) : https://github.com/JoYoungjoo/SC-FEGAN
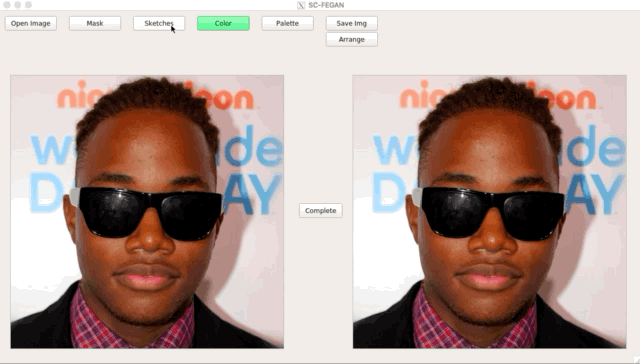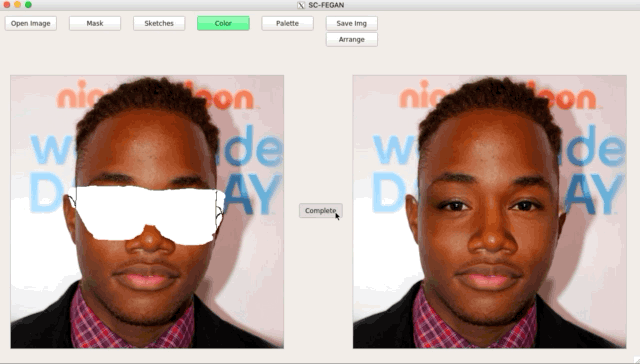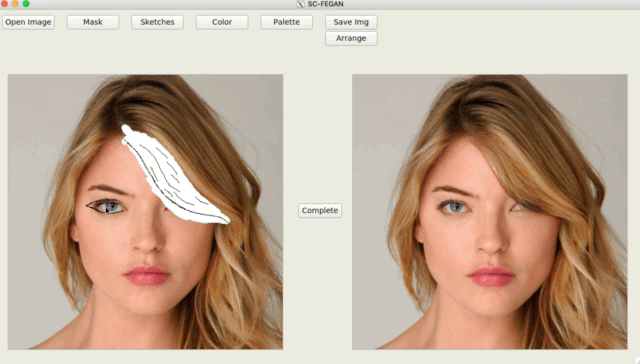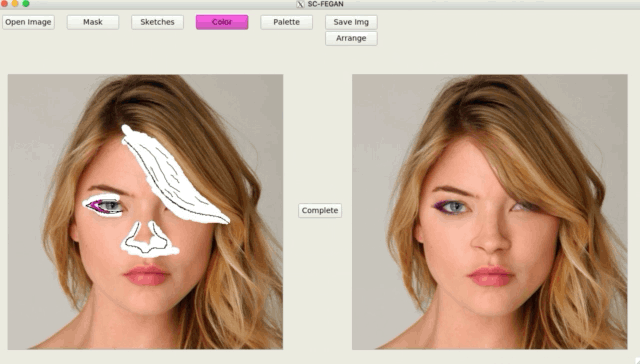
簡介
本文提出名為 SC-FEGAN 的人臉編輯模型,
可讓使用者輸入素描以及顏色來達到客製化的修改人臉,
從展示圖片可以看到效果十分令人驚艷,
以往人臉編輯模型可能都有其一以上的限制:
- 只接受長方形的遮罩進行修補
- 只接受素描
- 只接受RGB顏色
- 無法生成高解析度or細節
而這個模型可接受任意形狀(Free-Form)的素描+RGB顏色,
看下圖可以隨意的更改髮型,甚至髮色!!

整體與 Deepfillv2 - Free-Form Image Inpainting with Gated Convolution 相似,
同樣使用了 Deepfillv2 的 Gated-convolutional,
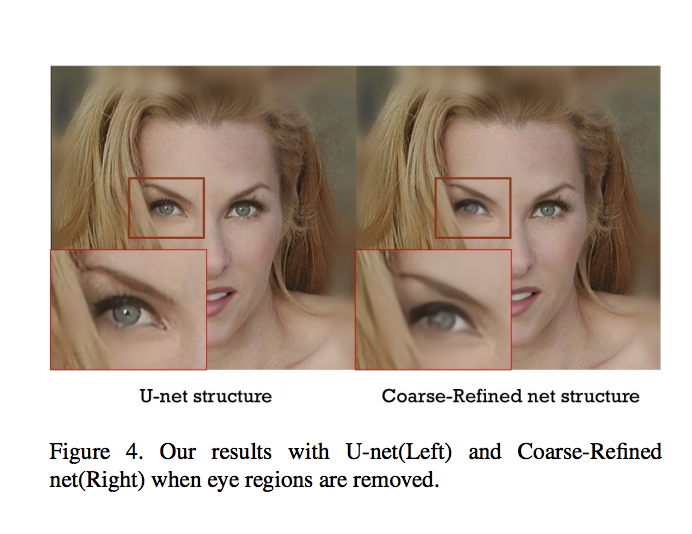
但捨棄了 Deepfill 系列的 coarse-to-fine 架構,
改而使用 U-Net 架構來生成高解析度圖片(512x512),
在 loss function 的部分,
強調使用了 Style loss 以及 VGG loss 來讓最終生成的圖片效果趨於真實。
執行時間 - 512x512解析度
- 使用 NVIDIA(R) Tesla(R) V100 GPU : 44ms
- 使用 Power9 @ 2.3GHz CPU : 53ms
整篇論文的貢獻
- 提議使用 Unet 結合 Gated convolutional layers,與 Coarse-Refined 的架構相比運行速度更快以及架構簡單
- 創建 Free-form mask 的資料集
- 使用 SN-patchGAN discriminator 並結合 Style loss 來讓大範圍的圖像修復區塊處理得更精細(如髮型, 耳朵部分
架構
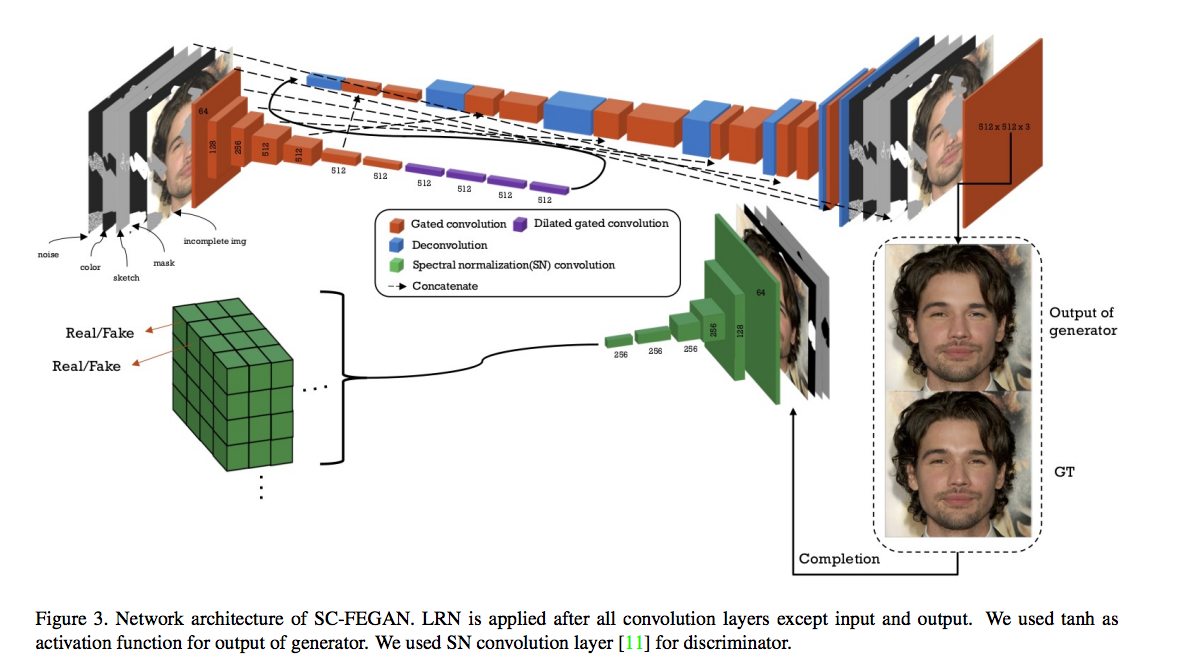
主要架構是使用 Unet 結合 Gated Convolution,
比較特別的是最後的輸出層是採用 Tanh。
而 Discriminator 使用 DeepFillv2 的 SN-patchGAN。
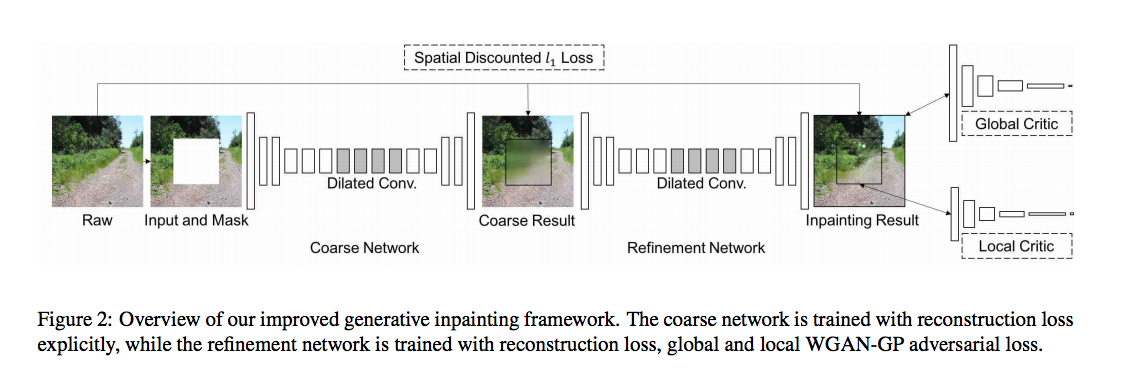
先提一下 Unet 突破了 Deepfill 的 coarse-to-fine 架構如下。
圖片出自 Deepfill - Generative Image Inpainting with Contextual Attention
Jiahui Yu, Zhe Lin, Jimei Yang, Xiaohui Shen, Xin Lu, Thomas S. Huang. Generative Image Inpainting with Contextual Attention.) In CVPR’18
我們的輸入資料共有 9 個 Channel
- 破損的 RGB 圖像 : 3 channels
- Mask 圖像: 1 channel
- Sketch 圖像: 1 channel
- 欲填補的 Color 圖像: 3 channels
- Noise : 1 channel
上述的輸入資料會介紹在下方的訓練資料部分 
loss function
這些 loss functions 可去看 partial convolutional 的圖像修復論文: per-pixel losses, perceptual loss, style loss and total variance loss.
G. Liu, F. A. Reda, K. J. Shih, T.-C. Wang, A. Tao, and B. Catanzaro. Image inpainting for irregular holes using partial convolutions. In ECCV’18
- 先定義一些參數
M 遮罩: 1 = 不需修復的部分(Valid), 0 = 需修復的部分(Erased)
Igen: 為我們所生成的圖片
Icomp: 基於 Igen 的圖片,將 Valid 的 Pixels 都填回 Ground Truth
Per-pixel loss 用意為希望不要改動到 Valid 的部分。
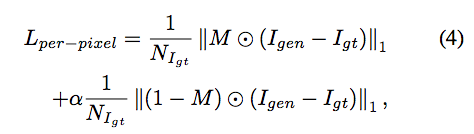 此處 σ = 0.05 ((如果 σ > 1 代表我們對 Erased 的部分更注重。
此處 σ = 0.05 ((如果 σ > 1 代表我們對 Erased 的部分更注重。Perceptual loss 使用 Vgg16 的特徵萃取器, 對生成出的圖像與原圖的特徵作 L1 loss。
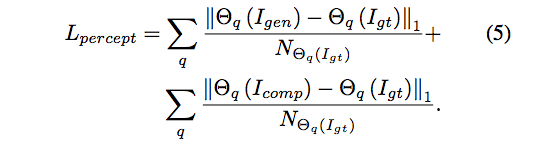
- Style loss 使用 Vgg16 的特徵萃取器, 對生成出的圖像與原圖的特徵作 Gram matrix。
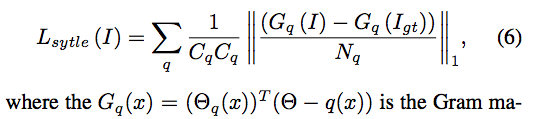
註:
Style loss 是出自畫風轉換的任務 Leon A. Gatys, Alexander S. Ecker, Matthias Bethge. Image Style Transfer Using Convolutional Neural Networks. In CVPR’16
TV loss
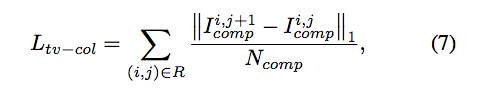

Adversarial loss 透過 GAN 的 Discriminator 做訓練
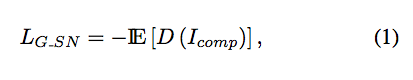
Total Generative loss
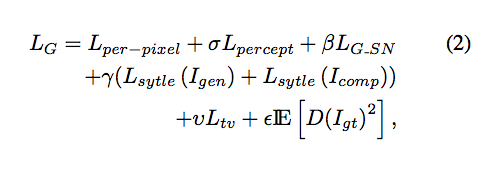
σ = 0.05, β = 0.001, γ = 120, υ = 0.1, ε= 0.001.
個人理解透過 Per-pixel loss 確保 Valid 的 Pixels,
而透過 Icomp 就可以專注改善 Erased 的 Pixels - local,
Igen 就可看作整張圖片是否一致 - global。
- Discriminator loss - WGAN-GP
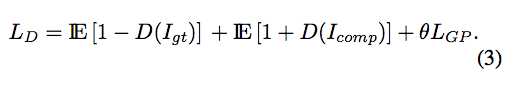 θ = 10
θ = 10
我目前對於這個 U 沒什麼想法,
不知道為什麼透過這個 U 會改善。
原文:
Here, U is a data point uniformly sampled along the straight line between discriminator inputs from Icomp and Igt.

訓練資料
其實對於圖像修復或是編輯的任務,
對於資料集的準備是較為複雜的,
尤其是針對 Free-form 的任務,
要如何生成出相似人會畫出的 Free-form Mask 是一大難題。
此次使用 CelebA-HQ 的資料集,
訓練集使用 29,000 圖片,
測試集使用 1,000 張圖片。
首先會 Resize 成 512 x 512
之後再生成下述的資料
- 破損的 RGB 圖像 : 3 channels
- Mask 圖像: 1 channel
- Sketch 圖像: 1 channel
- 欲填補的 Color 圖像: 3 channels
- Noise : 1 channel
演算法如下 
幾個重點,我大致提一下就好(建議有興趣的去看論文)
Free-form : 隨機畫線,而非以往的給定長方形 Mask
GFC segmentation : 定位出人臉/髮型的 Mask,看圖可發現我們的 Color 只會看人臉的部分,超出人臉的部分無視。
HED edge detector : 將人臉的邊緣化出來,以製造 Sketch 的圖片。
眼睛部分比較複雜多畫個幾撇
頭髮部分的 Mask 隨機給定
成果




參考資料:
SC-FEGAN: Face Editing Generative Adversarial Network with User’s Sketch and Color
Deepfill - Generative Image Inpainting with Contextual Attention
Deepfillv2 - Free-Form Image Inpainting with Gated Convolution