DANet簡介 - Dual Attention Network for Scene Segmentation
Jun Fu, Jing Liu, Haijie Tian, Yong Li, Yongjun Bao, Zhiwei Fang, Hanqing Lu. “Dual Attention Network for Scene Segmentation”. In CVPR’19.
CVPR’19 paper
Paper link : https://arxiv.org/abs/1809.02983
Github code(PyTorch) : https://github.com/junfu1115/DANet
簡介
本文提出名為 DANet 的語意分割模型,
靈感是來自取自 NLP 領域近期相當有名的 Self-Attention 的架構,
提出使用兩個 Self-Attention 的架構,
Position attention module 以及 Channel attention module。
其想法是使用 Self-attention 的特性,
找出每個 pixel / feature 之間的相關性,
目的是為了克服以往語意分割模型都是使用空間上的鄰近資訊來優化。
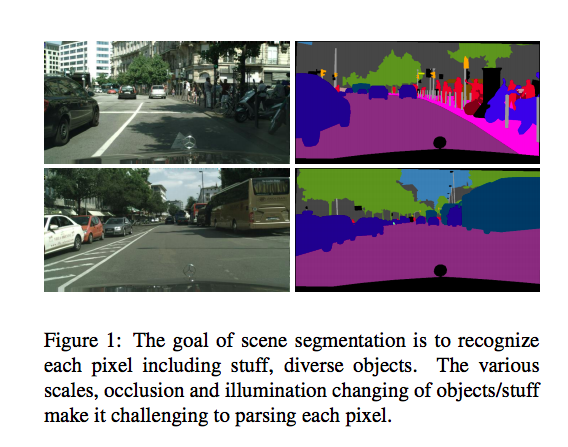
概念
備註:
這部分可看 OCNet,那篇論文所給出的概念比較詳細。
如 PSPNet 的 Pyramid Pooling Module 或是 Deeplab 透過 ASPP 來增加感知視野提升準確度,
但上述兩種方式都會帶來一個問題,
空間上的鄰近資訊並不見得代表同一個類別,
舉例來說車子在道路上跑,
那在兩者的邊界處時,使用上述得方法,
所得出的結果是會混合著兩種類別的資訊,
該結果可能會降低模型的準確度。
但此文使用 Self-attention 的方式,
讓模型可以擺脫空間上的鄰近資訊,
變為更長範圍(long-range)。
我認為這篇文章應該要搭配 Self-Attention Generative Adversarial Networks 一起看,
才會對 Self-attention 在電腦視覺上的應用有更好的理解。
下圖取自 Self-Attention Generative Adversarial Networks
使用 Self-Attention 的特點為長範圍(long-range),
並且可以擺脫以往 CNN 只能空間上鄰近的限制。

如果我們只使用鄰近資訊來做判斷的話,
我們遇到物件被遮擋、物體的大小不同、光線不同的情況都可能會造成語意分割模型誤判,
但如果能找到圖片中較為相像的部分作為依據的話,
或許可以提升準確度。
舉例來說:
A 與 B 的 pixel/feature 在圖像中的距離有點遠但是很像,
模型覺得 A 是車子,但是他對於 B 不太肯定,
如果使用 Position attention module 會認為雖然遠了一點但既然 A 與 B 很像的話,
那 B 也可能是車子。
以及另一個情況
樹木和草地在模型中可能會有誤判的問題,
因為長得很像,
這時候如果有個 Channel attention module 透過學會每個類別間的相關性,
那是不是就能改善這件事了。
因此模型提出使用 2 個 Attention module 來緩解這個問題。

架構
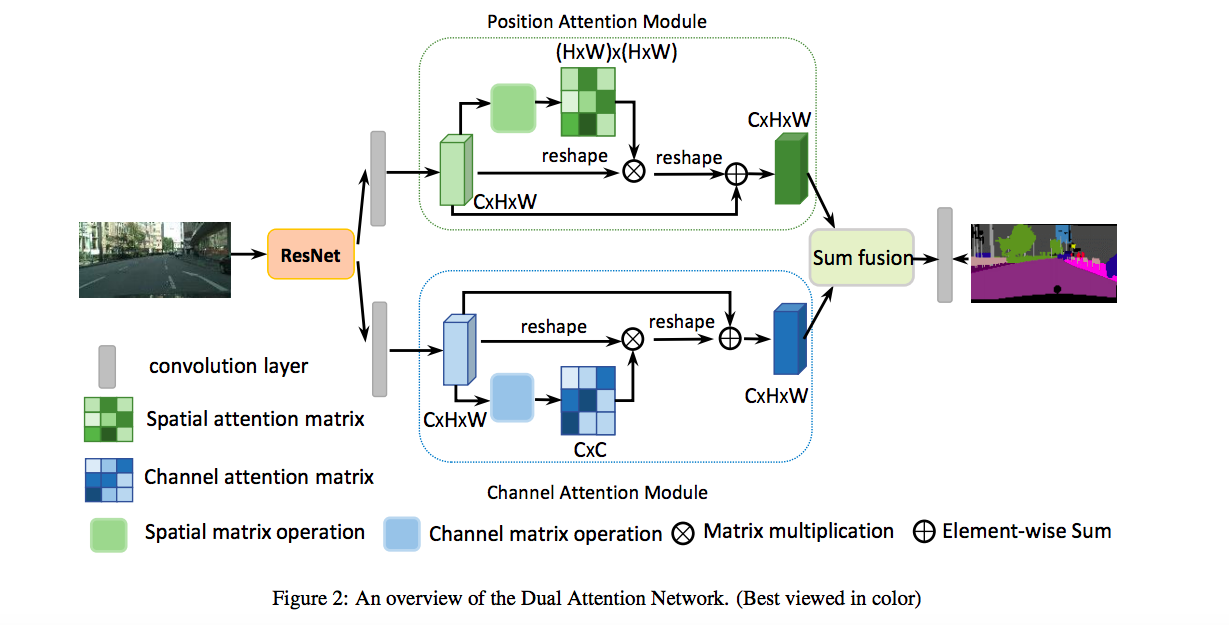
基本上與 SA-GAN 的 Self-attention 架構挺像的
主要是透過 Self-Attention 的概念做延伸,
先說明什麼叫 Self-Attention,
即為輸入只有一個,自己對自己做 Attention。
其實這邊我們看 SA-GAN 的架構圖會比較好理解
下圖架構圖出自 Self-Attention Generative Adversarial Networks
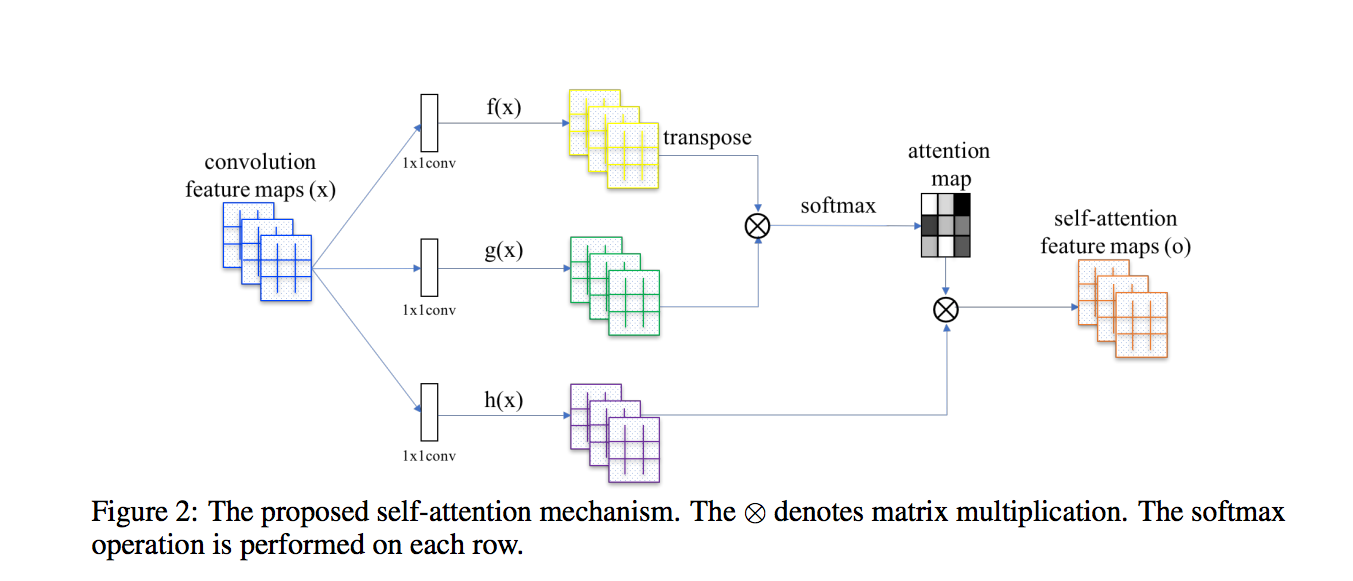
看懂上面圖之後,
我們來看一下本文所給出的架構圖,
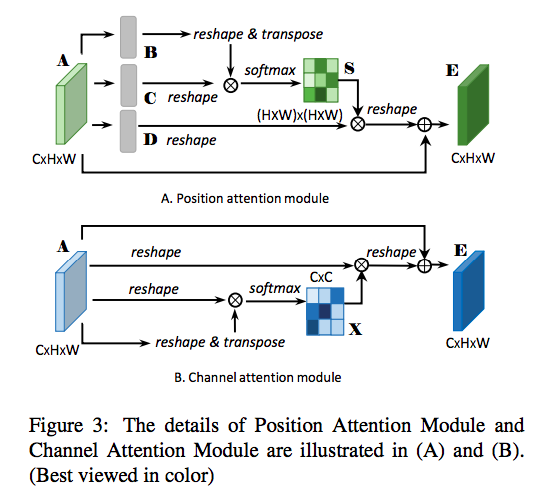
其實跟前面 SA-GAN 很像對不對~
其實概念也差不多,
我們可以看一下上半部的 Key and Query CNN,
Key and Query 這兩個在做的是將相同類別的物件視為一體,
模型學習相像的關鍵是基於 Feature 之間相不相像,
因此使用 Key and Query 學習在 Feature maps 中的相像程度,
最終得出的相像程度就為 S,
這邊的熱力圖其實是有意義的,
可以想成這個是代表著每個像素之間的相似性,
Si,j = 第 i 個 pixel 與第 j 個 pixel 的相似性。(如果兩個是同類別的話,分數會高。
寫成數學式會長這樣(v1版本的),
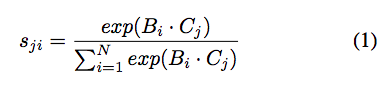
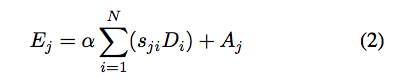
α 是一個參數,會從 0 開始增加權重,
這部分的設定跟 SA-GAN 當初的設定一樣,
因為一開始 Attention 可能還沒學好,
如果直接採用這個熱力圖的話,
可能不會有很好的結果或是訓練過程不穩定之類的。
Channel attention(CAM) 的計算其實挺相像 Position attention module(PAM) 的,
只是改成算出 C X C 的 Channel 熱力圖,
這邊就不多贅述了。
來看看每個 Module 所帶來的影響。

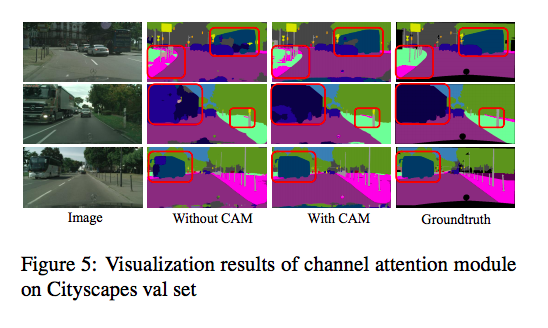
實驗結果
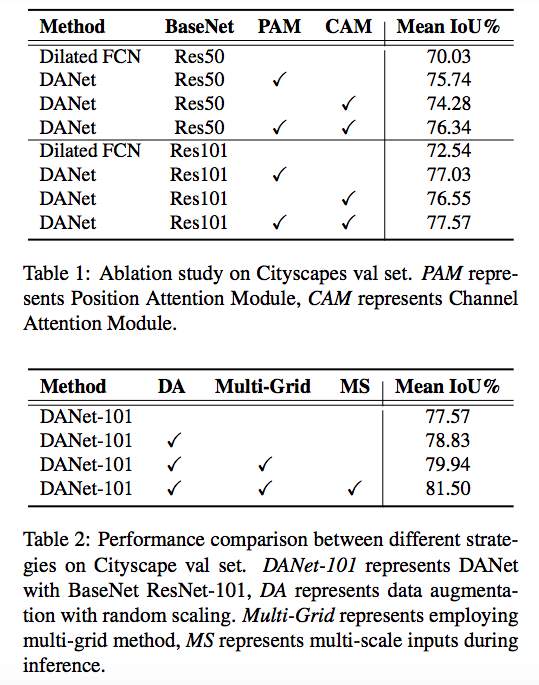
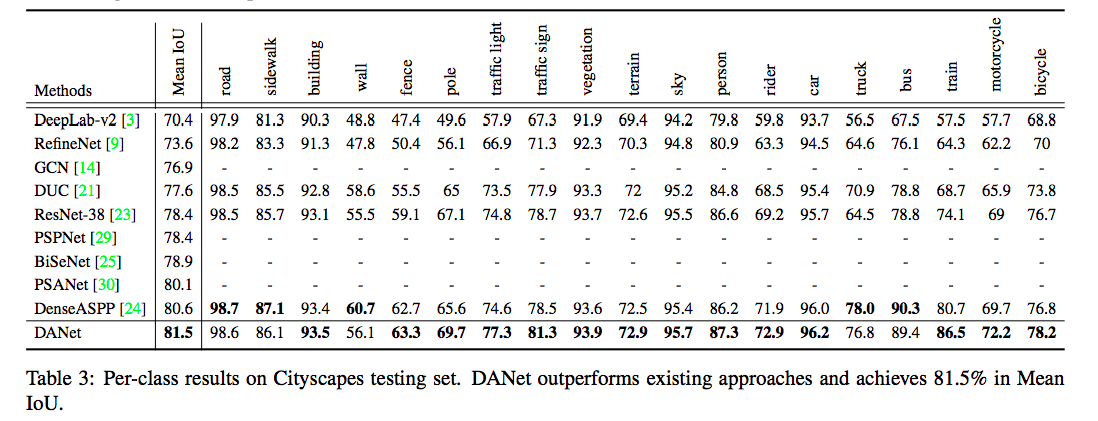
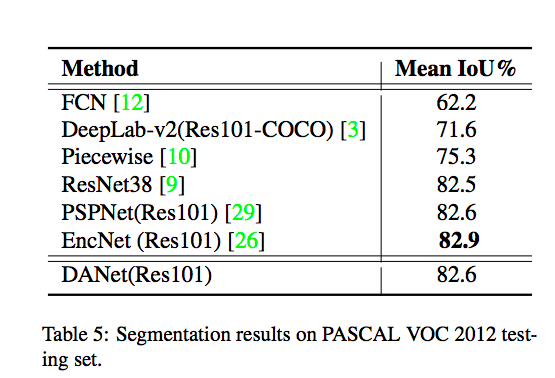
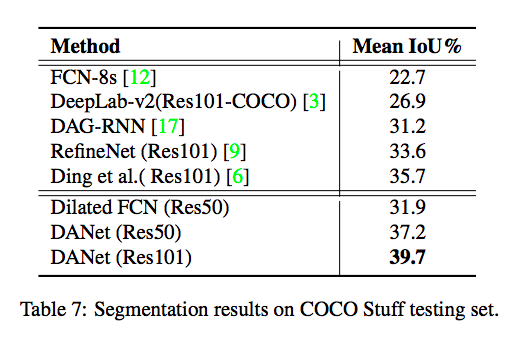
補充資料:
與此論文較相近的是 OCNet。((4 Sep 2018 提交至 Arxiv
同樣是使用 Self-attention 的架構,
有興趣的可以去看看。
參考資料:
Dual Attention Network for Scene Segmentation