Image-level lower-count(ILC)簡介 - Object Counting and Instance Segmentation with Image-level Supervision
Hisham Cholakkal, Guolei Sun (equal contribution), Fahad Shahbaz Khan, Ling Shao. “Object Counting and Instance Segmentation with Image-level Supervision”. In CVPR’19.
CVPR’19 paper
Paper link : https://arxiv.org/abs/1903.02494

簡介
本文提出用於自然場景的計數模型,
以往常見的計數模型是人群數測量,
但自然場景測量與人群數測量的困難點不一樣,
人群數測量的問題中,
人的數量通常很多,
並且會有人與人之間的遮擋問題,
但自然場景的計數模型的困難點為要學習不同種類 intra-class,
除此之外一張圖片還會出現不同種類多個物體的情況。
而本文提出基於 Image-level 的方式訓練,
相較於以往需要(Instance-level / point-level / bounding box level)等等的訓練方式來說,
此模型只要有出現的類別以及各自的數量即可進行訓練!!
還能夠輸出 Density map (可看作熱力圖),
藉由 Density map 能得知其物體是出現在圖片的哪個位置。
並且使用幾篇心理學為依據(這部分沒去探究),
大概就是說當人類看到一張照片有 1 ~ 4 個物件時,
可以即時算出數量,不需要一個一個數。
基於這個想法提出一個物件數量限縮的訓練方式。
稱作 ILC - Image-level lower-count (ILC) supervision.。
架構
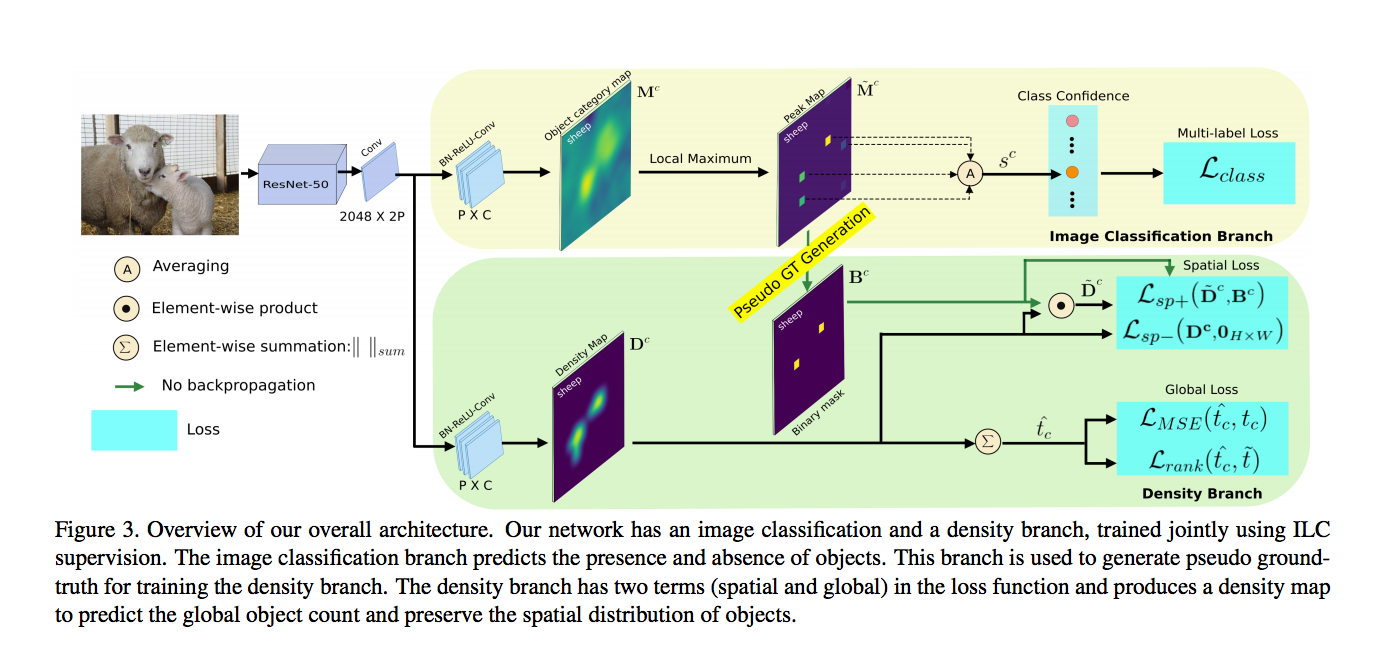
主要兩個部分
- Image classification branch (上半部,用於分類)
- Density map branch (下半部,用於計算數量)
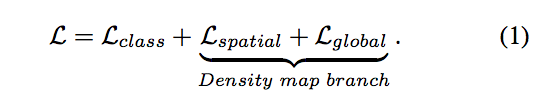
Image classification branch
最基本的想法是透過 image classification branch 學習分類,
而 CAM - Learning Deep Features for Discriminative Localization 以及 Grad-CAM: Visual Explanations from Deep Networks via Gradient-based Localization
兩篇論文展示分類器會學到最能夠辨別這個類別的區塊,
而上圖的 Mc 就是分類器認為黃色的部分是較能夠代表這個類別的區塊。
透過 CAM 的方法,
我們其實沒辦法明確地將 Instances 分隔出來,
單看黃色的部分,沒辦法很直覺的知道這張圖片有幾個羊。
因此透過透過下面這個公式找出哪些位置可能高機率是一個物體,
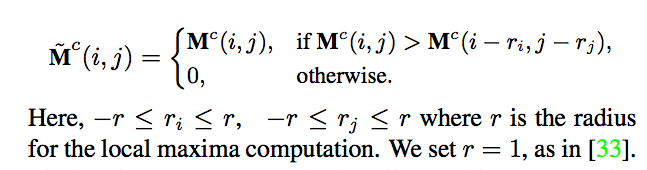
舉例來說辨認鳥的時候,
CAM 的結果可能會集中(能量最強)在鳥嘴的部分,
而上面就是用簡單的方法找出哪個點是最強的點 - peak
透過這個方式我們可以將 Mc 轉換成 M^c,
使用 local maximum 的點,
就可以將每個物體的熱力圖分隔出來,
使用 multi-label soft-margin loss
備註: local maxima (peaks) 細節請看 Y. Zhou, Y. Zhu, Q. Ye, Q. Qiu, and J. Jiao. Weakly Supervised Instance Segmentation using Class Peak Response. In CVPR, 2018
Density Branch
我們可以經由 Image classification branch 的分數得知哪些物件是有出現或是沒出現,
但是我們無法得知一張照片會出現多少數量的 instance,
可能一張照片只有兩隻羊,
但是看 Peak map 卻有 10 幾個點在上面的情況。
而我們的 Density map 就是希望能夠畫出圖片中物件的位置,
還要知道圖片中出現幾個物件。
定義 set
- A: 此類別沒有出現在這張圖片
- S: 此類別有出現 1 ~ 4 個物件
- S+: 此類別有出現 5 個以上物件
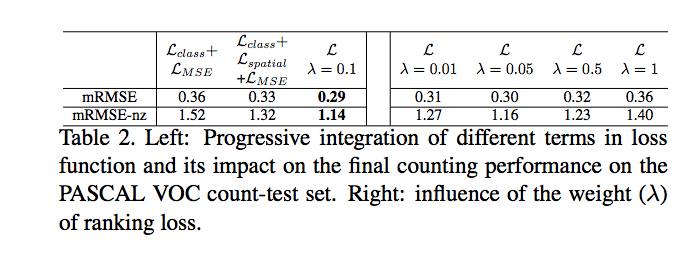
因此提出 2 個 loss
- Spatial loss
- Lsp+ : 確保 peak map 的出現都是對應到一個物體 set {S}
- Lsp- : 確保不會出現分類器沒出現的類別數量 set {A}
- 而對於 set {S+} 我們就不會處理。((本文 ILC 方法的特色
- Globle loss 確保整體物件數量一致
- Lmse
- Lrank
Spatial loss
確保物件能保留對應的空間資訊。
首先依照 GT 中該類別的數量 t 來提取出第 t 個高的 peak value 當作 hc,
因此能確保產生出來的 Pseudo ground-truth 個數會等於實際出現的物件數量。
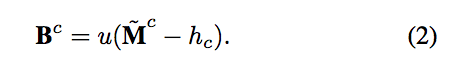
u(n) is the unit step function which is 1 only if n ≥ 0.
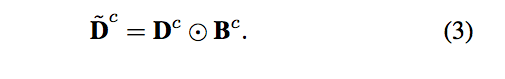
Lsp+ 使用 logistic BCE loss 讓 Density map 可以相似 peak map,
可使 Density map 的能量集中在該物件最能辨別的部分上。
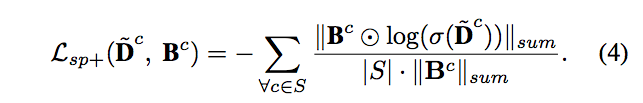
Lsp- 用 GT 提供的數量,針對沒有出現的類別{A}將它所預測的 Density map 逼近於0,因此時所預測出的 Density map 都是誤判的。
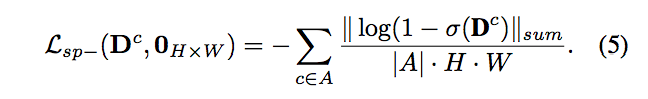
透過上述兩個 Spatial loss 確保物件能保留對應的空間資訊,主要是 Lsp+ 的部分。
Global Loss
確保預測出來的數量 t^c 是相當於 GT 的 tc。
本文有趣的做法是將 Density map 的能量加總當作預測的數值。
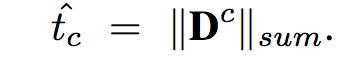
Lmse: 讓 Density map 的加總數量能趨近於 tc。
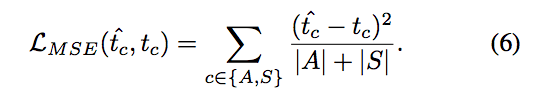
Lrank: 針對 {S+} 的類別,即為在圖片中出現數量 5 以上的類別,我們希望我們所預測出的 t^c >= 5。
下方的 t^ = 5
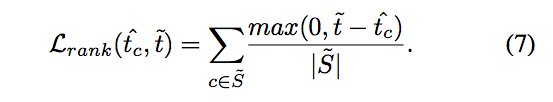
透過 Spatial loss 確定每個物件的空間資訊,
再透過 Global loss 的 MSE loss 確保其 density map 可以抓出物件的熱力圖,
兩個 loss 相互協調下就能達成定位 object instances 的功能。
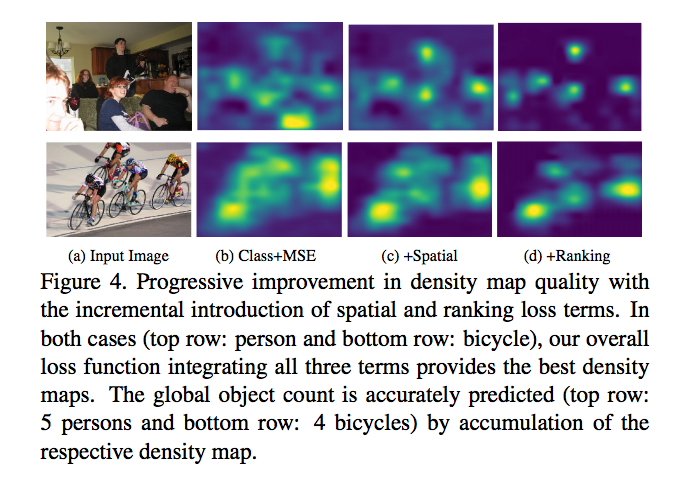
還有個特點是雖然我們的訓練時只在 t <= 4 的時候做 mse loss,
但最終在預測時,也能準確預測出超過 t(t=4) 個物件的類別。

備註:這張圖應該是基於 PRM - Weakly Supervised Instance Segmentation using Class Peak Response 的方法,搭配 Spatial 以及 Global loss 去修改 PRM 的 Score matrix,才達到這個效果的。
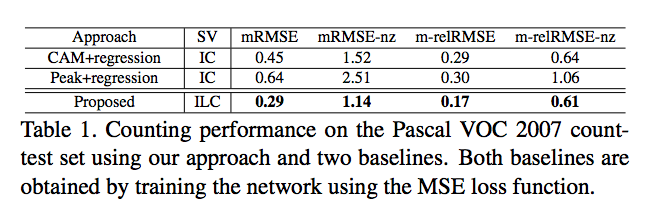
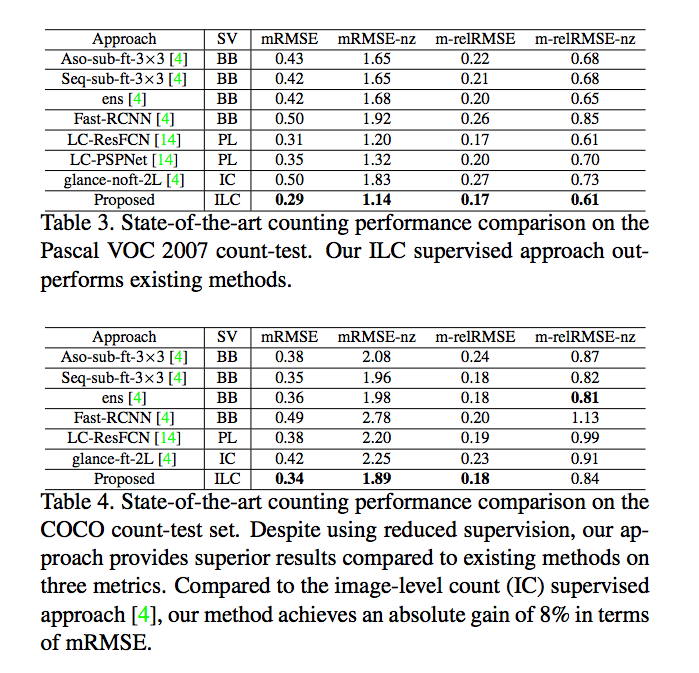
成果
但是對於有遮擋到的還是沒辦法準確預測

其他結果看起來還不錯

參考資料:
Object Counting and Instance Segmentation with Image-level Supervision
Weakly Supervised Instance Segmentation using Class Peak Response
Learning Deep Features for Discriminative Localization
Grad-CAM: Visual Explanations from Deep Networks via Gradient-based Localization