簡介 - Structured Knowledge Distillation for Semantic Segmentation
Yifan Liu, Ke Chen, Chris Liu, Zengchang Qin, Zhenbo Luo, Jingdong Wang. “Structured Knowledge Distillation for Semantic Segmentation”. In CVPR’19.
CVPR’19 paper
Paper link : https://arxiv.org/abs/1903.04197
簡介
本文提出透過知識蒸餾(Knowledge Distillation)的方式訓練小型的語意分割模型,
其目的是希望訓練出小型且精準的模型(Neural network),
主因是近年來嵌入式/手機的廣泛使用,
若在其裝置上使用大型的模型可能會負擔過大,
因此使用小型且精準的網路是必要的。
為了達成這個目的,
提出知識蒸餾(Knowledge Distillation)架構,
主要是透過一個大型的模型,本文稱作 Teacher,
以及一個小型的模型,本文稱作 Student,
目的是希望 Student 的準確度可以逼近於 Teacher,
為了達成這個效果提出兩種知識蒸餾方式
- pair-wise distillation
- holistic distillation
本文使用語意分割模型(Semantic segmentation)的任務作為研究,
使用 ResNet 18 當作小型模型 - Student(S),
而 PSPNet with ResNet 101 當作大型模型 - Teacher(T)。
備註:
針對物件分類任務有其他篇論文。
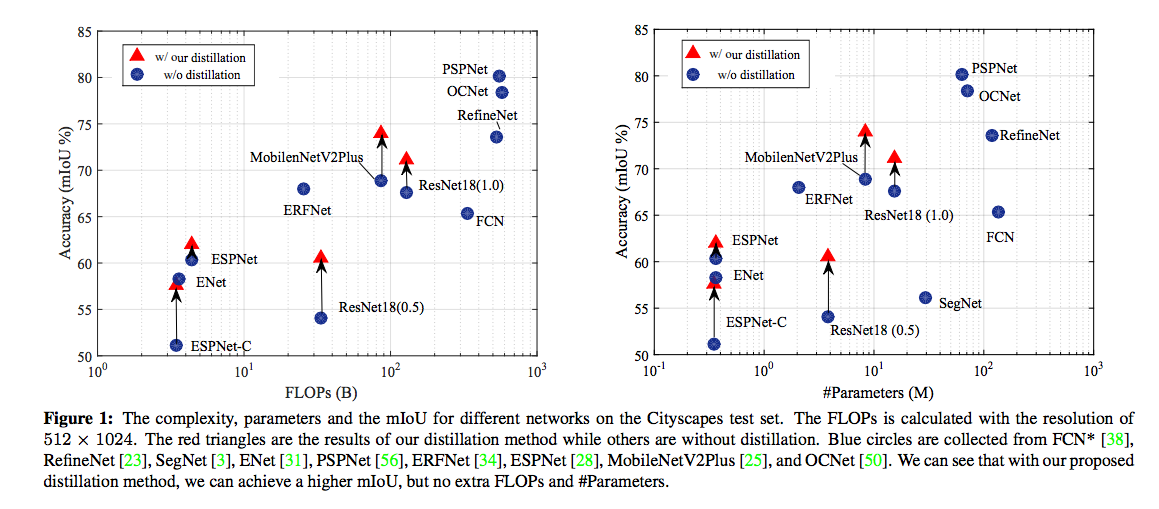
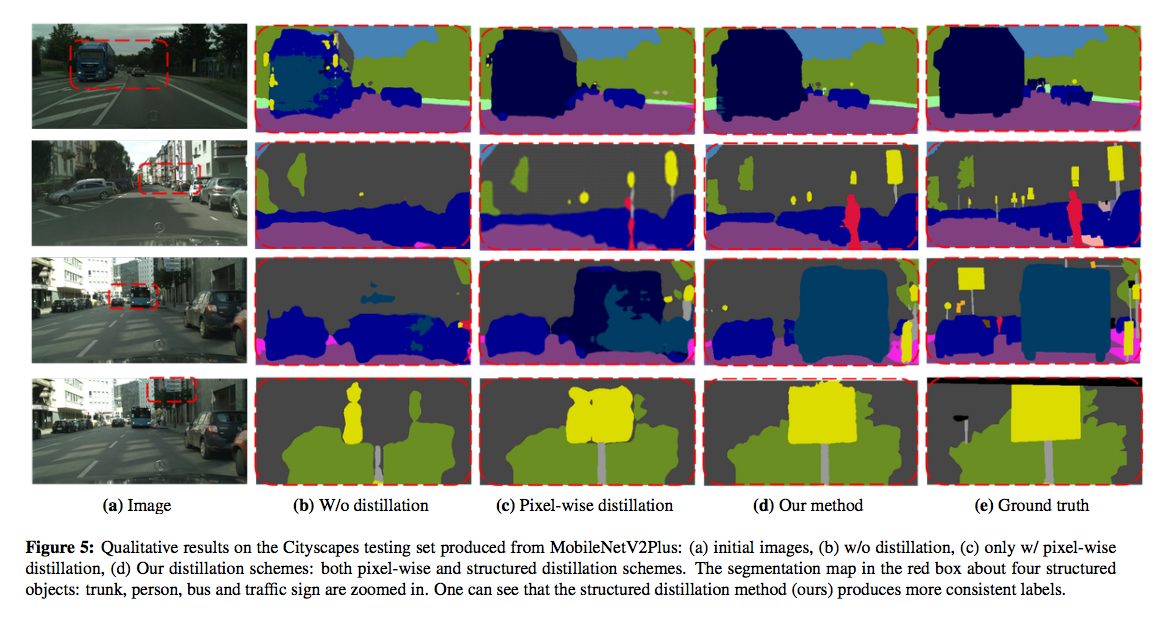
從下圖可看紅色箭頭的部分,
就是採用了本文提出的知識蒸餾都有效提升的 Student 的準確率,
架構
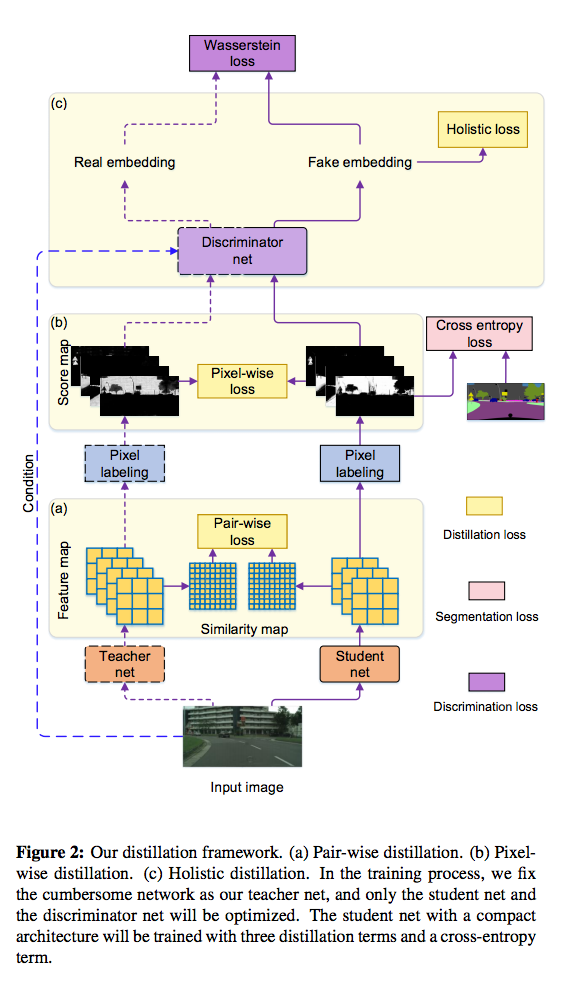
主要描述三個知識蒸餾方式
- Pixel-wise distillation
- Pair-wise distillation
- Holistic distillation
值得注意的是在訓練過程中 Teacher 的模型是被 Freeze 的,不會被訓練到(紫色虛線箭頭)。
Pixel-wise distillation
針對預測出的 Semantic segmentation 的輸出做 KL divergence,
因為我們的輸入都是同一張圖,
只是輸入進兩個不同的模型 Teacher 和 Student,
基本上都是 Teacher 的結果比 Student 的準確,
所以可以讓 S 去向學習 T 。
使用 KL divergence 讓 S 可以朝向 T 的輸出分佈去學習。
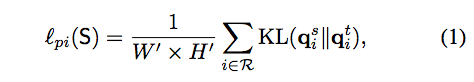
備註:
可看 Distilling the Knowledge in a Neural Network
寫的不錯的中文介紹 論文 - Distilling the Knowledge in a Neural Network
至於這邊為什麼不搭配 Distilling the Knowledge in a Neural Network 有提到的 soften softmax 這我就不清楚了。
Pair-wise distillation
針對 Pair-wise 之間的知識蒸餾
看 S 和 T 模型各自輸出的 feature maps,
計算出 pixel 間(ith -> jth)所對應的關係 - a,
之後再讓 S 去學習 T 的 pair-wise similarities。
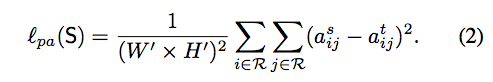
實務上的作法就是把 H x W 攤平 => N, 然後轉置相乘變為 N * N 的矩陣,
而這邊 N x N 每個 pixel => aij 代表第 i 個 pixel 與第 j 個 pixel 的相關性 。
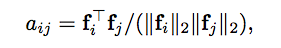
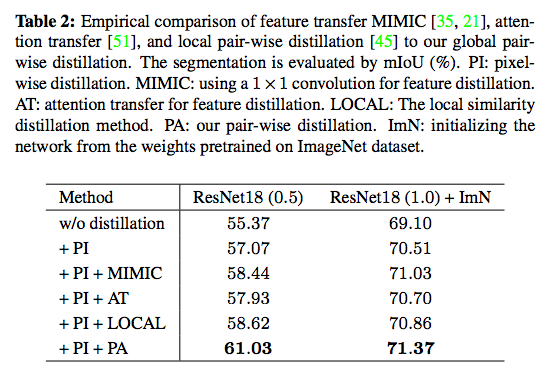
和其他方法的比較,
- MIMIC - 是直接將 Feature map 做 L1 loss
- AT - 使用 attention transfer 的方式
- LOCAL - local pair-wise 使用鄰近 8 個 pixels 的方式
備註:
原文的概念如下:
Inspired by the pair-wise Markov random field framework that is widely adopted for improving spatial labeling contiguity.
Holistic distillation
簡單來說,為了明白整體之間的差異,
透過一個 Discriminator 來理解 S 和 T 輸出的 Semantic Segmentation 的差別,
這邊採用的是 cgan 的方式,
Input(RGB) + Q(Semantic segmentation) 作為 Discriminator 的輸入,
希望 Discriminator 可以分辨出來並且透過對抗式學習(loss_ho)改善 S,
主要使用 Wasserstein GAN 的方式去學習
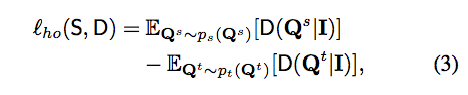
而 Discriminator 的最後 3 層是 Self-attention - conv - Self-attention 的架構,
這邊有興趣的去看 SA-GAN 的論文 - Self-attention generative adversarial networks
Objective function
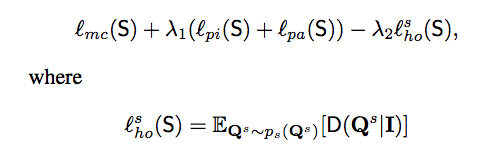
簡單來說會對 S 的 output 做 segmentation loss,
再本文提出的透過 Pixel-wise / Pair-wise distillation / Holistic distillation 進行優化
- mc : multi-classes loss 當作正常的 Loss_seg 就好了
- λ1 : 10
- λ2 : 0.1
Result


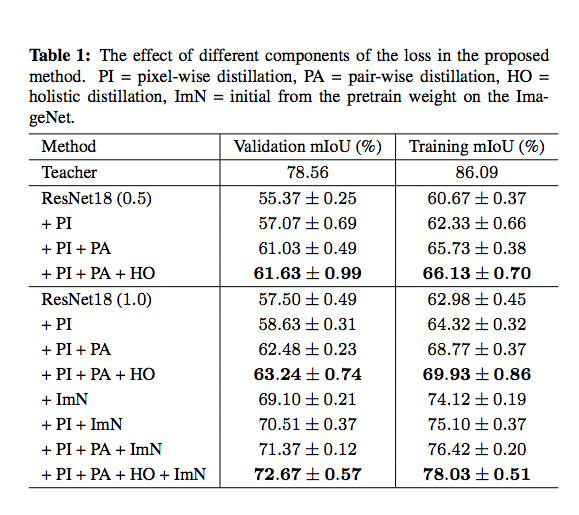
0.5 以及 1 可理解模型參數量砍半以及正常模型,
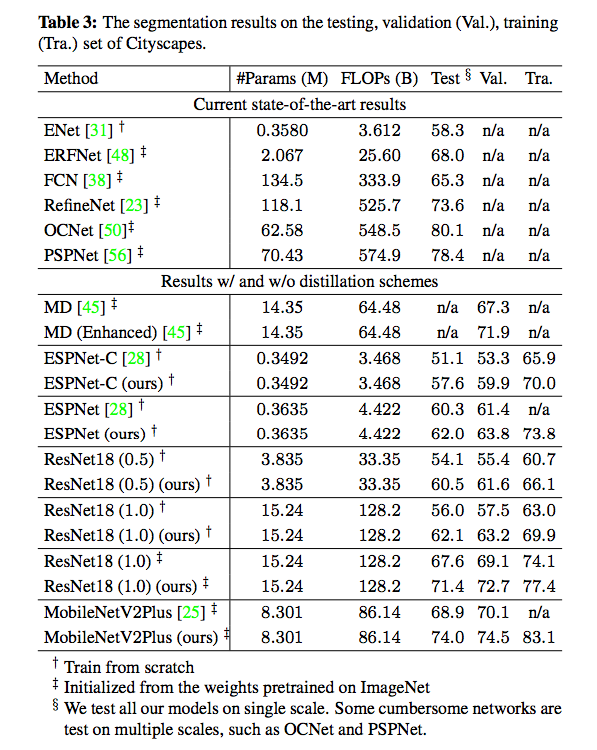
參考資料:
Structured Knowledge Distillation for Semantic Segmentation