HRNet 簡介 - Deep High-Resolution Representation Learning for Human Pose Estimation
Ke Sun, Bin Xiao, Dong Liu, Jingdong Wang. “Deep High-Resolution Representation Learning for Human Pose Estimation”. In CVPR’19.
CVPR’19 paper
Paper link : https://arxiv.org/abs/1902.09212
Github (PyTorch) : https://github.com/leoxiaobin/deep-high-resolution-net.pytorch
Github 模型架構(PyTorch) : https://github.com/leoxiaobin/deep-high-resolution-net.pytorch/blob/master/lib/models/pose_hrnet.py
簡介
本文提出使用一個可提供高解析度的模型架構 - HRNet( (High-Resolution Net) ),
來解決人的骨架測量問題,
整體上就是提出這模型架構,
其骨架的訓練方法都與他們團隊的前作相同,
ECCV’18 - Simple baselines for human pose estimation and tracking 相同,
因此本文會介紹模型的部分,
其核心想法是我們要維持模型中高解析度的部分,
以常用的模型 VGG, ResNet 為例,
我們都是經過 Stride, pooling 來不斷的縮小 Feature maps 的大小,
最終才輸入進分類器,
但經過不斷的縮小,高解析度的資訊也不斷的丟失,
因此本文所提出的架構就是為了保留高解析度的特徵而設計的。
從下圖可看出,我們最上面那層並沒有經過任何的 Stride/pooling,
還是保存著同樣的尺寸。
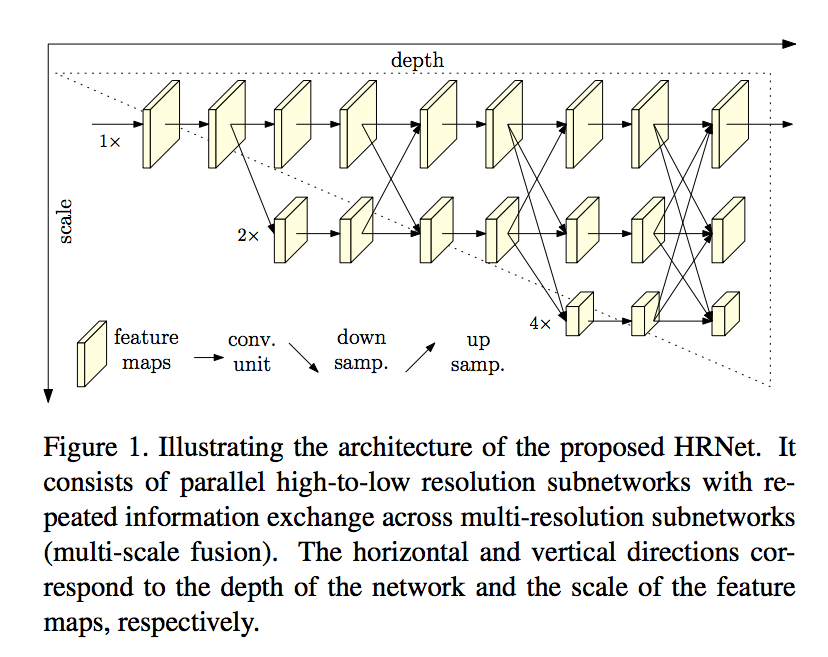
概念
先來簡單講一下過去的模型架構,
以深度學習的模型來說,
通常都會使用分類任務的模型作為骨幹再去延伸
較為著名的骨幹如 VGG, ResNet。
而上述的兩種都有 Stride/pooling 的動作壓縮影像尺寸,
針對本文的所希望處理的高解析度任務來說,
上述的縮小尺寸的特性會造成我們測量準確度下降。
下圖為以往處理 pose estimation 的網路架構。
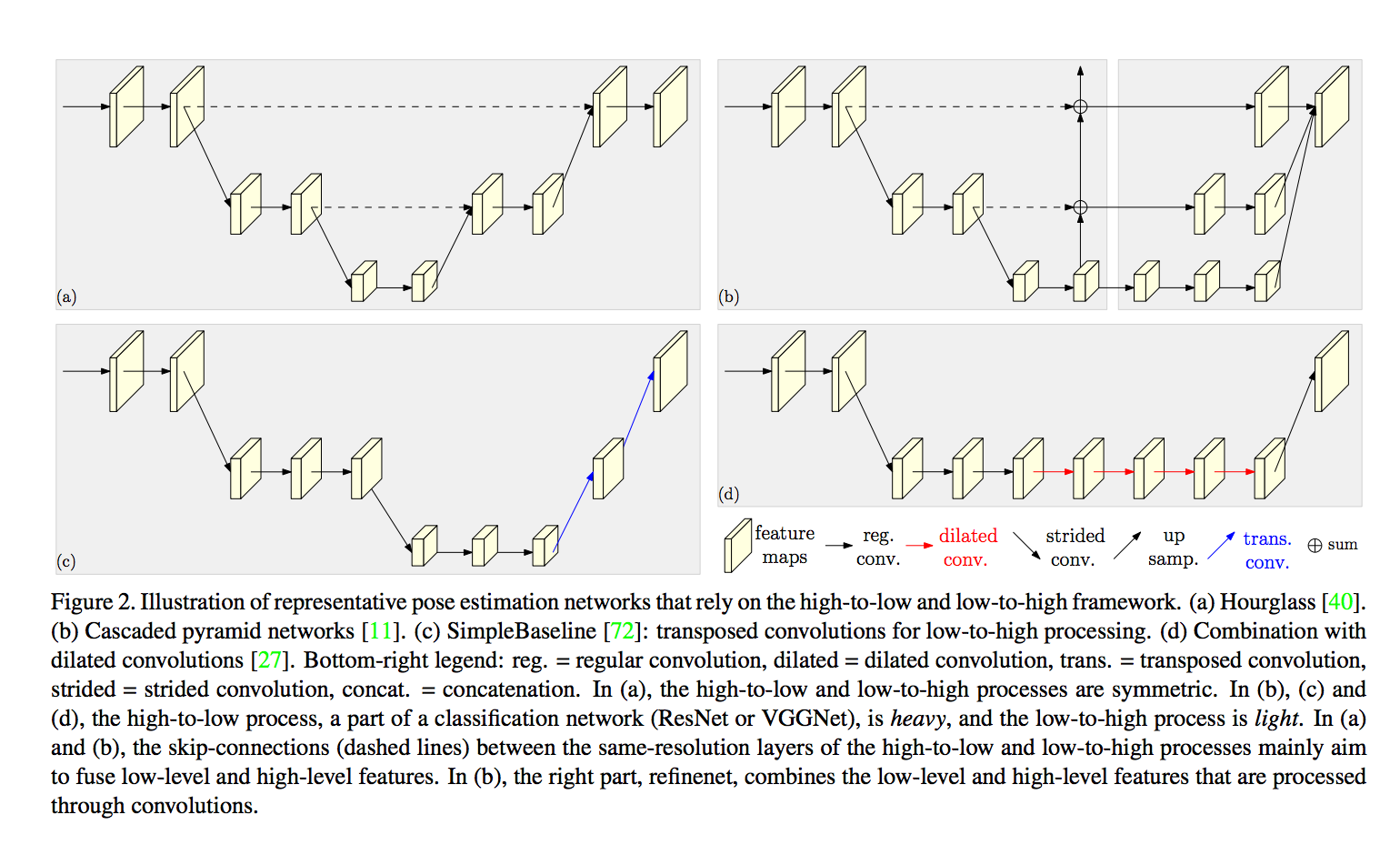
左上角是 (a) Hourglass 的架構,
右上角是 (b) Cascaded pyramid networks 的架構,
左下角是 (c) SimpleBaseline 的架構,
右下角是 (d) 使用 dilated convolutions 的架構,
主要就幾種處理方式
- 對稱式的模型,縮小和放大。(a)
- 用大量的資源萃取特徵,再用少部分的 CNN 做放大,回復到原本的解析度。(b) (c)
- 在 backbone 的最後使用 dilated convolutions (d)
而本文提出的是,
我們目的是要維持住高解析度的特徵,
但是只使用高解析度的特徵很難有效解決多尺度的問題,
因此提出的架構是保持著高解析度的特徵,
但是也會有一部分的網路是透過不斷地縮小來解決多尺度的問題。
基本上的架構我認為與 ICLR’18 - MSDNet 相似,
下圖出自 MSDNet - Multi-Scale Dense Networks for Resource Efficient Image Classification
都是透過多尺度融合,並且保存著大的解析度。((最上面那層
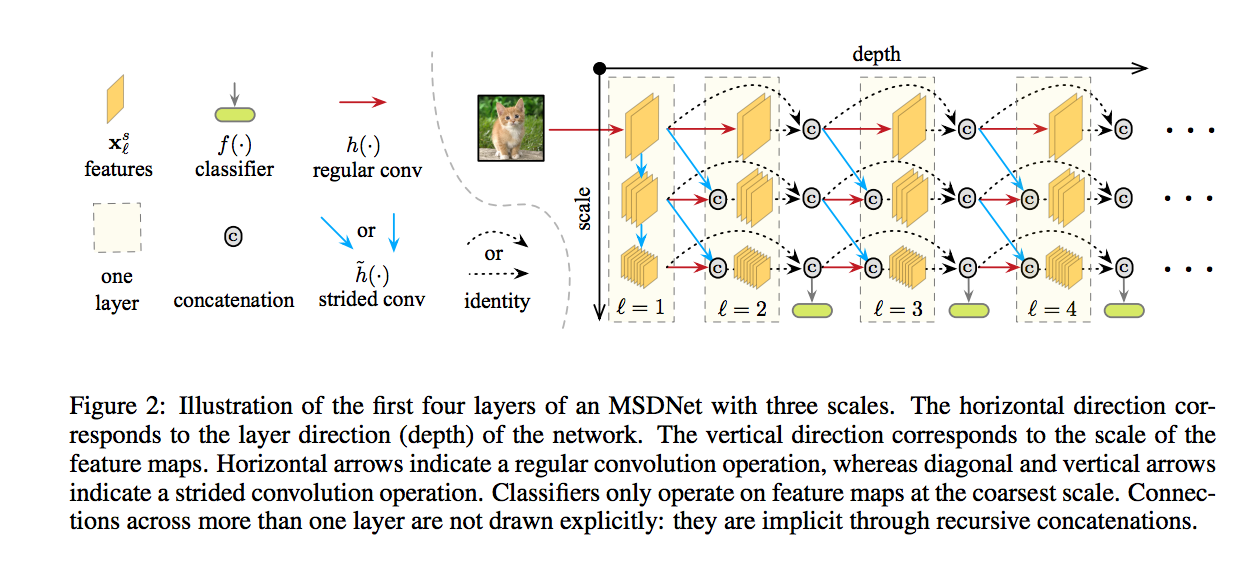
只是說 MSDNet 少了每個 Branch 之間的融合,
而 HRNet 多了 Multi-scale fusion 的動作,
Multi-scale fusion 策略,下圖右方
下圖出自 Deeply-Fused Nets

簡單來說就將每個 branch feature maps 做融合,
要注意的就是每個 feature maps 的解析度不同,
因此實際操作會搭配 upsampling 以及 downsampling。
總結來說雖然每個 branch 的解析度不同,
但是透過 Multi-scale fusion 的方式所融合出來的特徵,
對於此任務(pose-estimated)來說是能帶來更有意義的資訊的。
架構
可以看一下示意圖,
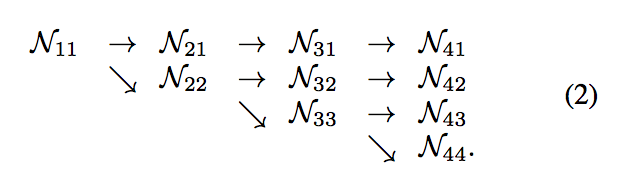
可以看到我們的模型保存著高解析度的特徵 N11 -> N21 -> N31 -> N41,
也有不斷的壓縮解析度 N11 -> N22 -> N33 -> N44
而本文的特點就是將每個平行的 branch 都輸入進 multi-scale fusion - 本文稱作 exchanged unit,
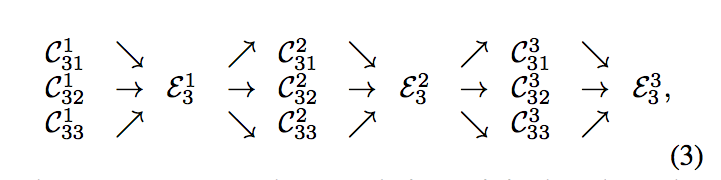
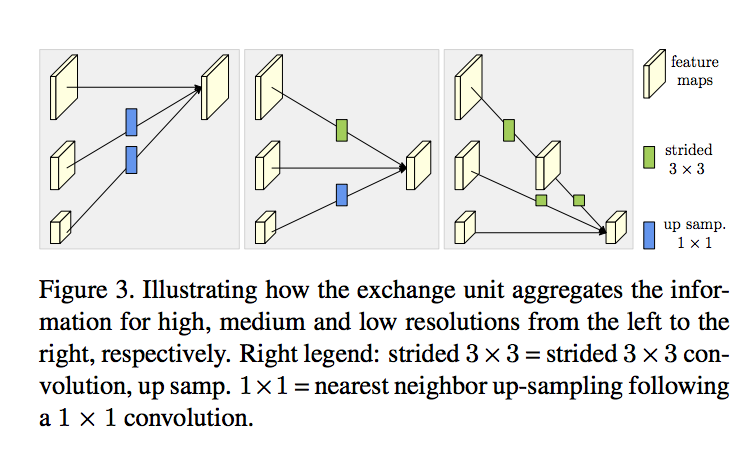
原本輸入 4 個 branch,經過 multi-scale fusion 出來也會是 4 個 branch。
那它的作用就是將每個 branch 的尺寸都先轉換成該 branch 的尺寸後,再進行相加。
而本文提出的策略是 Repeated multi-scale fusion,
代表經過一次 multi-scale fusion 完之後還會再進行一次,
因為 n 個 branch 輸入進 multi-scale fusion 後還是 n 個 branch 解析度也不變,
因此可以不斷的重用來讓模型可以學會更多的資訊。
以本文為例,
在 stage-2 加入 1 個 exchanged unit,
在 stage-3 加入 3 個 exchanged units,
在 stage-3 加入 4 個 exchanged units,
本文有一堆細節,有興趣請看論文,或看 github - HRNet 模型架構(PyTorch)
未來延伸
高解析度的網路其實是相當好用的,
因此作者說未來會延伸至 semantic segmentation, object detection, face alignment, image translation 等等的方向。
成果

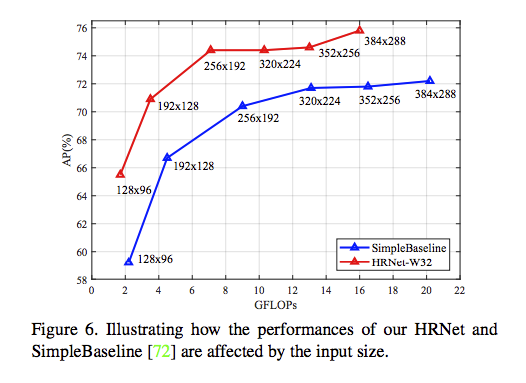
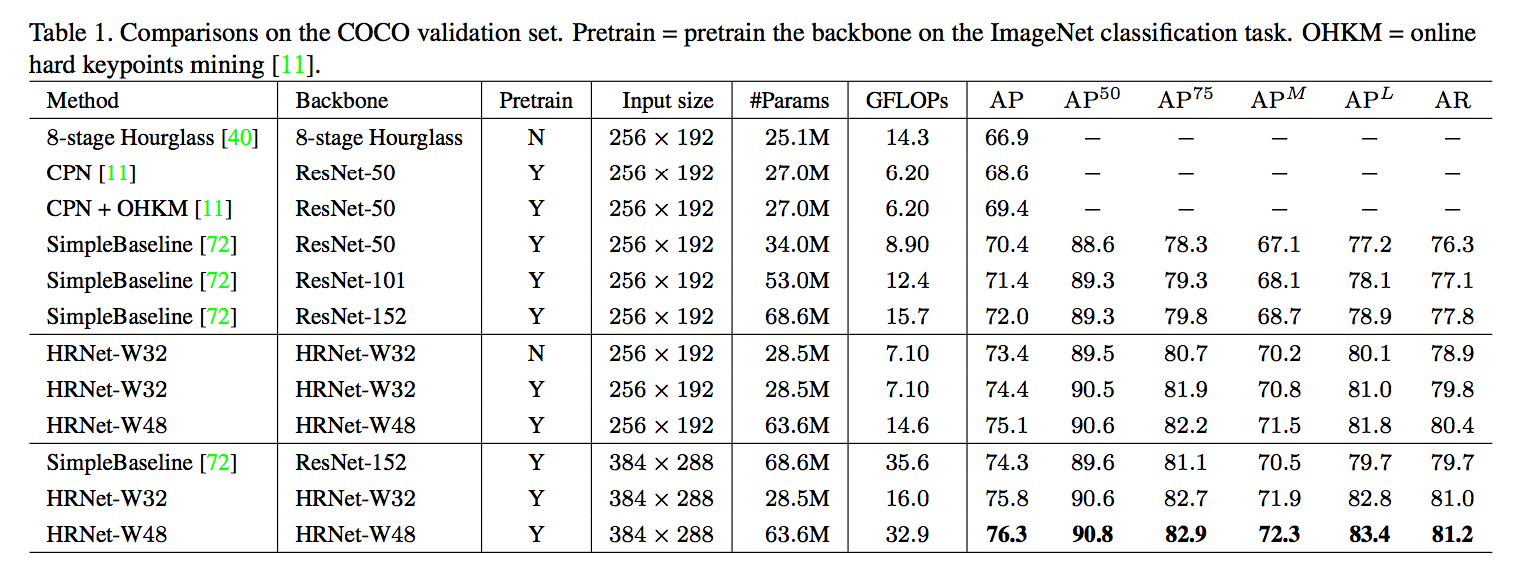
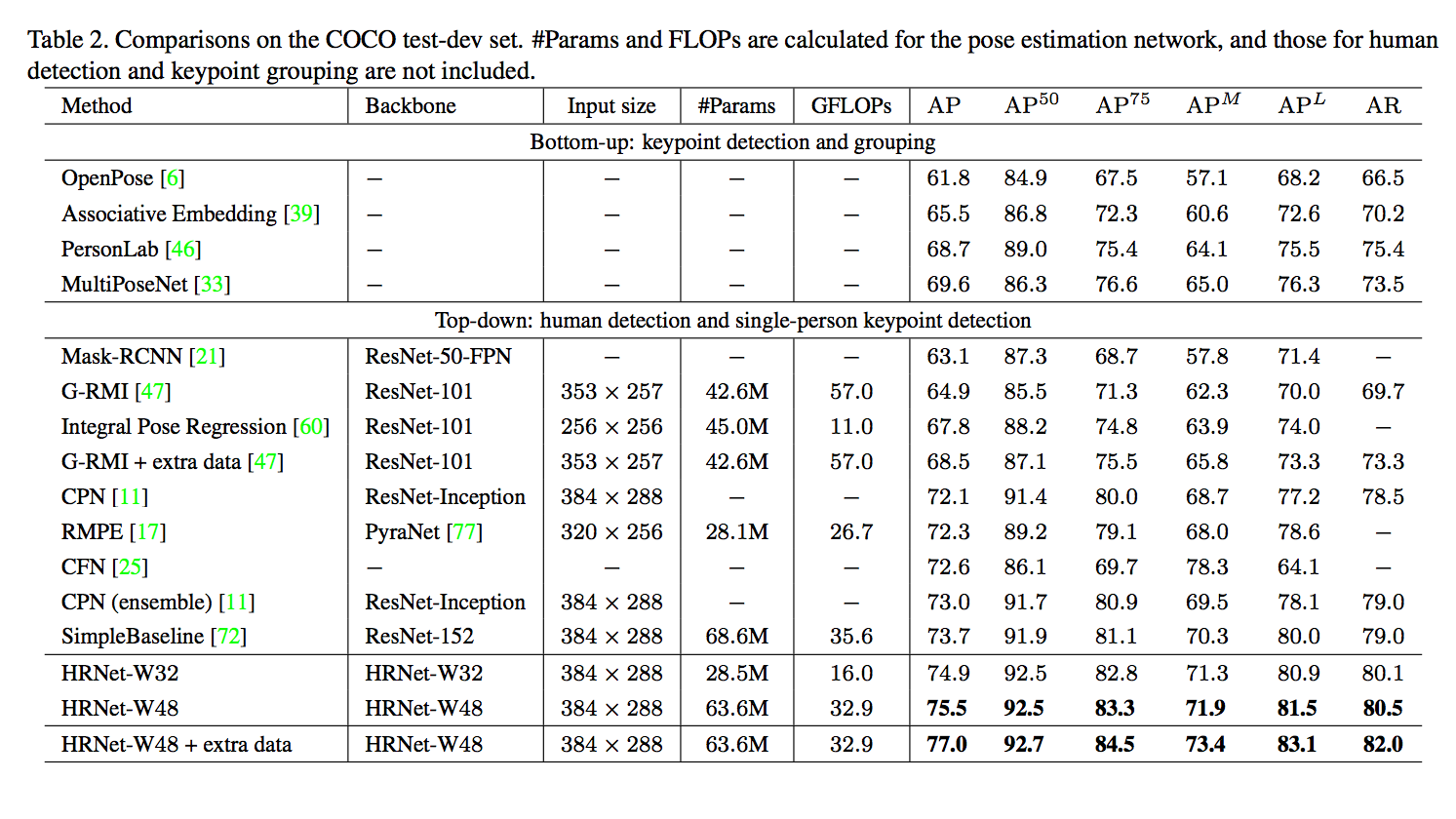
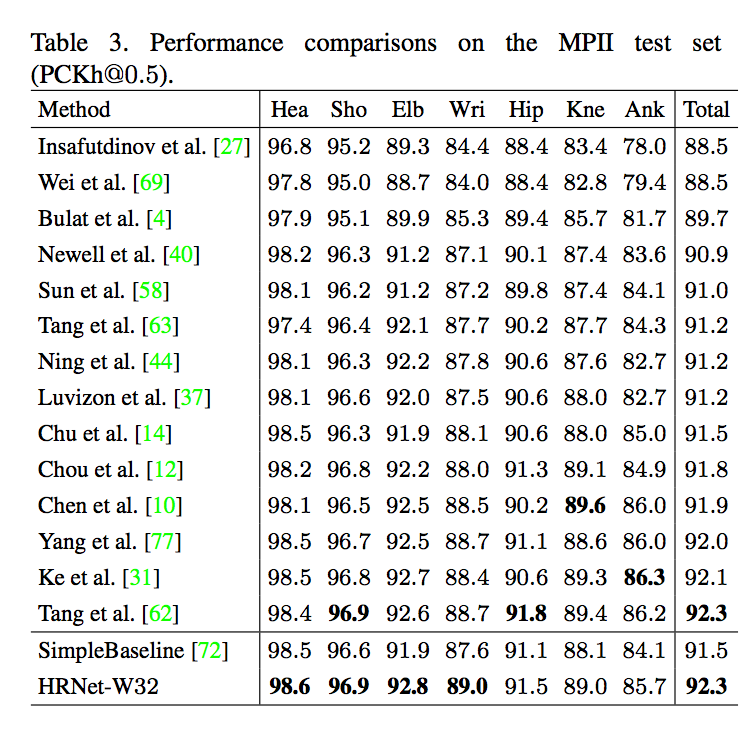
參考資料:
Deep High-Resolution Representation Learning for Human Pose Estimation
Simple baselines for human pose estimation and tracking
MSDNet - Multi-Scale Dense Networks for Resource Efficient Image Classification