YOLACT簡介 - Real-time Instance Segmentation
Daniel Bolya, Chong Zhou, Fanyi Xiao, Yong Jae Lee. “YOLACT: Real-time Instance Segmentation”. In ArXiv preprint.
此論文於 4 Apr 2019 提交至 Arxiv,目前尚未被 Conference 接收。
Paper link : https://arxiv.org/abs/1904.02689
Github (PyTorch) : https://github.com/dbolya/yolact

簡介
本文提出一個可即時解析實例分割模型 - instance segmentation,
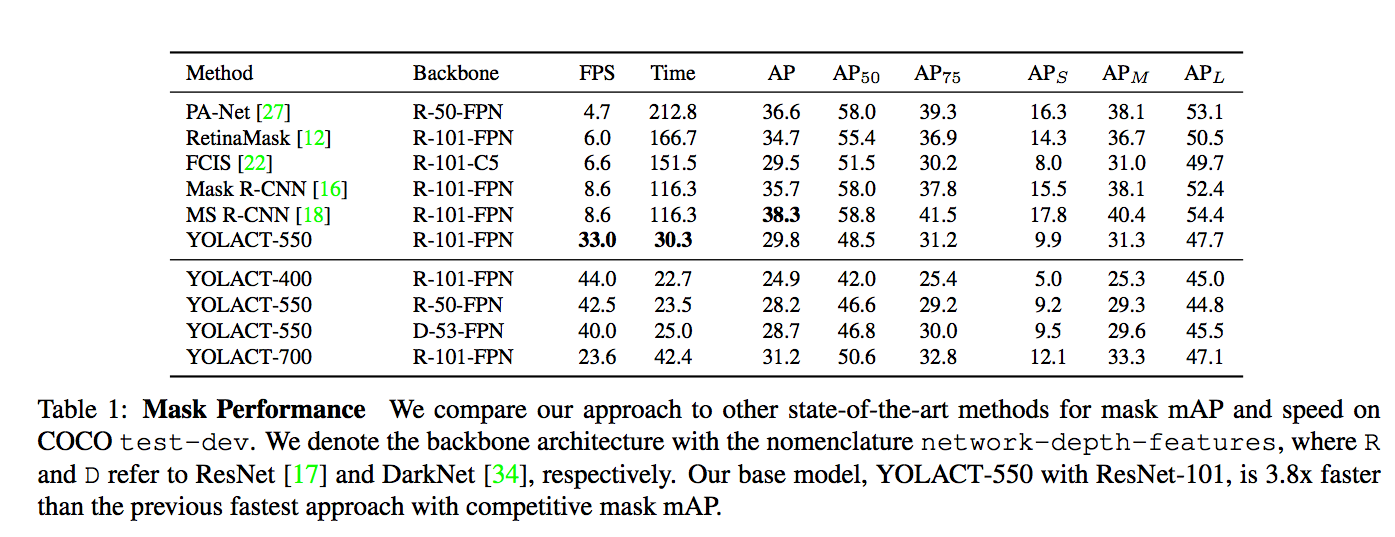
運行速度:basemodel - 33 fps on a Titan Xp and 29.8 mAP on COCO’s test-dev
此外這個模型只要一個 GPU 即可訓練!!
以往的實例語意分割模型(如:Mask R-CNN) 追求的精準度,
但 YOLACT 追求的是運行速度,
而目前沒有任何一個實例分割模型像是 YOLACT 追求速度而且準確度還不錯的!
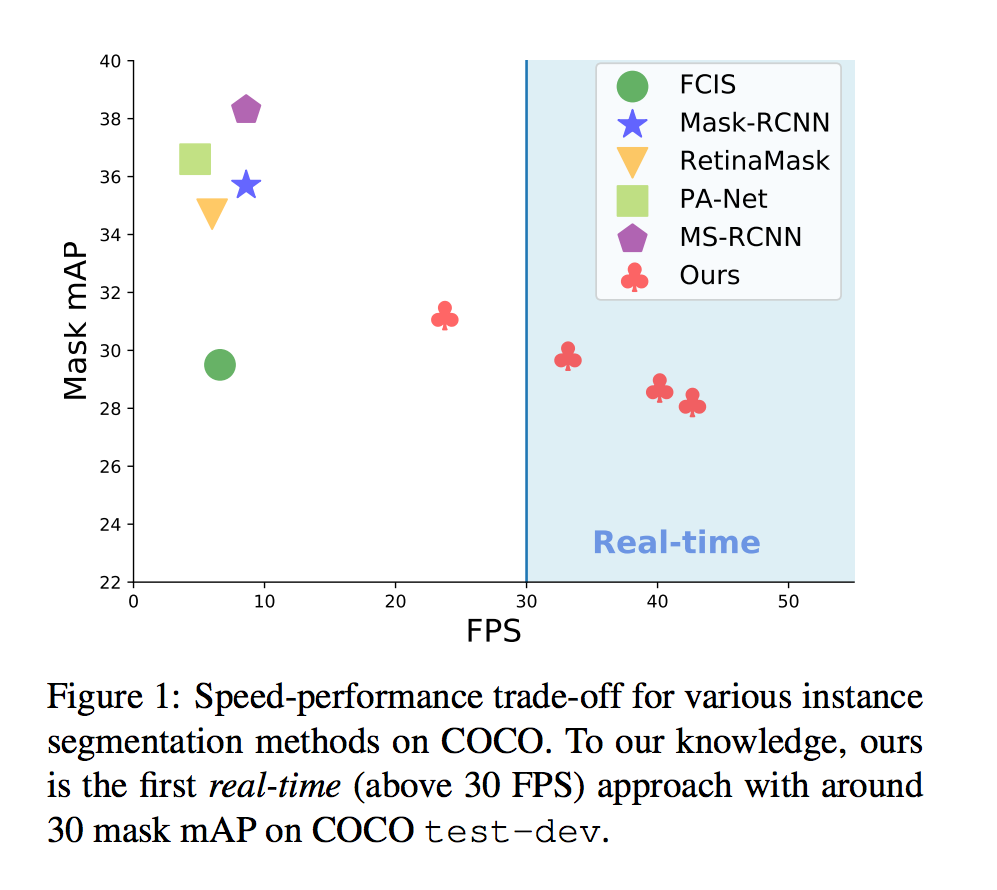
看下圖可明白各個模型的差距,雖然此模型快但準確度差了一點。
主要構想是參考 SSD 和 YOLO 的想法。
將原本 two-stage model 變成 one-stage model 進行加速。
此模型提升速度的方法也是這個概念。
原文一開始就用 Joseph Redmon, YOLOv3 的話破題
Boxes are stupid anyway though, I’m probably a true believer in masks except I can’t get YOLO to learn them.
想藉由移除 localization step - Feature repooling 的動作(e.g. Mask R-CNN 的 RoI-Align)來達成加速,
主要概念是使用多個遮罩(Mask,此文稱作 Prototype)搭配多個係數(coefficients)來進行改善。
這也是為什麼此模型稱作 YOLACT:You Only Look At CoefficienTs,
特色
- 即時實例分割模型 Realtime instance segmentation。
- 只需使用一張 GPU - batch size 8 即可訓練。
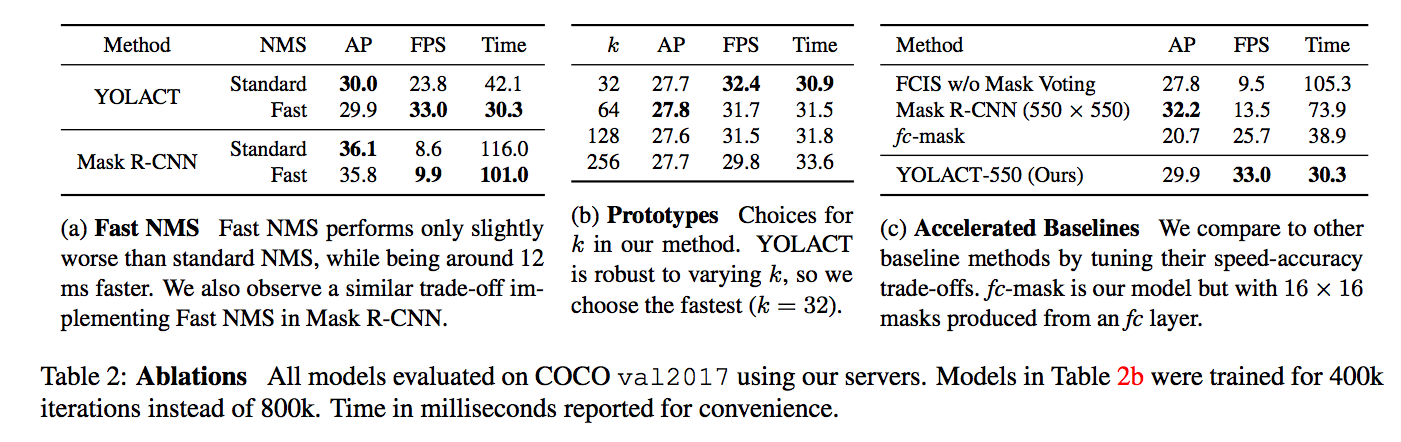
- Fast NMS 加速原本的 NMS,比原本的快約 11.8ms 並且準確度只損失一點點。
- 對 Prototype 的行為做解析,發現它即便是 Fully Covolutional 卻具備平移變化!!
Instance segment 概念
- Two Stage Instance segment
首先會透過物件偵測模型的 RPN 產生出 ROI,
再經由這些 ROI 進行分類及分割,
如 Mask R-CNN,使用 ROI-Align 來保存空間資訊,
但這樣做速度慢,耗費大量的時間。
- One Stage Instance segment
缺點是使用 fully connected layer 輸出預測的類別以及box的四個點,
但這樣會喪失了空間的資訊。
因此使用在 Instance segment 的任務時,
還需要大量的後處理才有不錯的效能,
因此就算是 one-stage 還是耗費非常多的時間。
綜合以上兩點,
作者認為以 Instance segment 的任務來說,
使用 fc 去預測該區塊的類別,
使用 Conv 來獲得空間資訊(mask)以及係數(mask coefficients)是比較好的選擇。
Mask 會選用 Conv 來實作是因為 Conv 擁有空間連貫性,
舉例來說如果是同一個 Instance 的話,
鄰近的 Pixel 可能也會長得很相像。
除此之外,
作者認為可以將空間資訊(mask)以及係數(mask coefficients)分開計算,
之後再將兩者做矩陣相乘,能夠達到更快的速度。
題外話:
原本看程式碼時看到一段
https://github.com/dbolya/yolact/blob/master/yolact.py#L570
if cfg.mask_type == mask_type.lincomb and cfg.mask_proto_prototypes_as_features:
發現作者曾經有想過在計算係數時,考慮將 mask 的資訊也放入,
但最後論文的版本,還是將它分開看了。
可能是效能考量?
架構
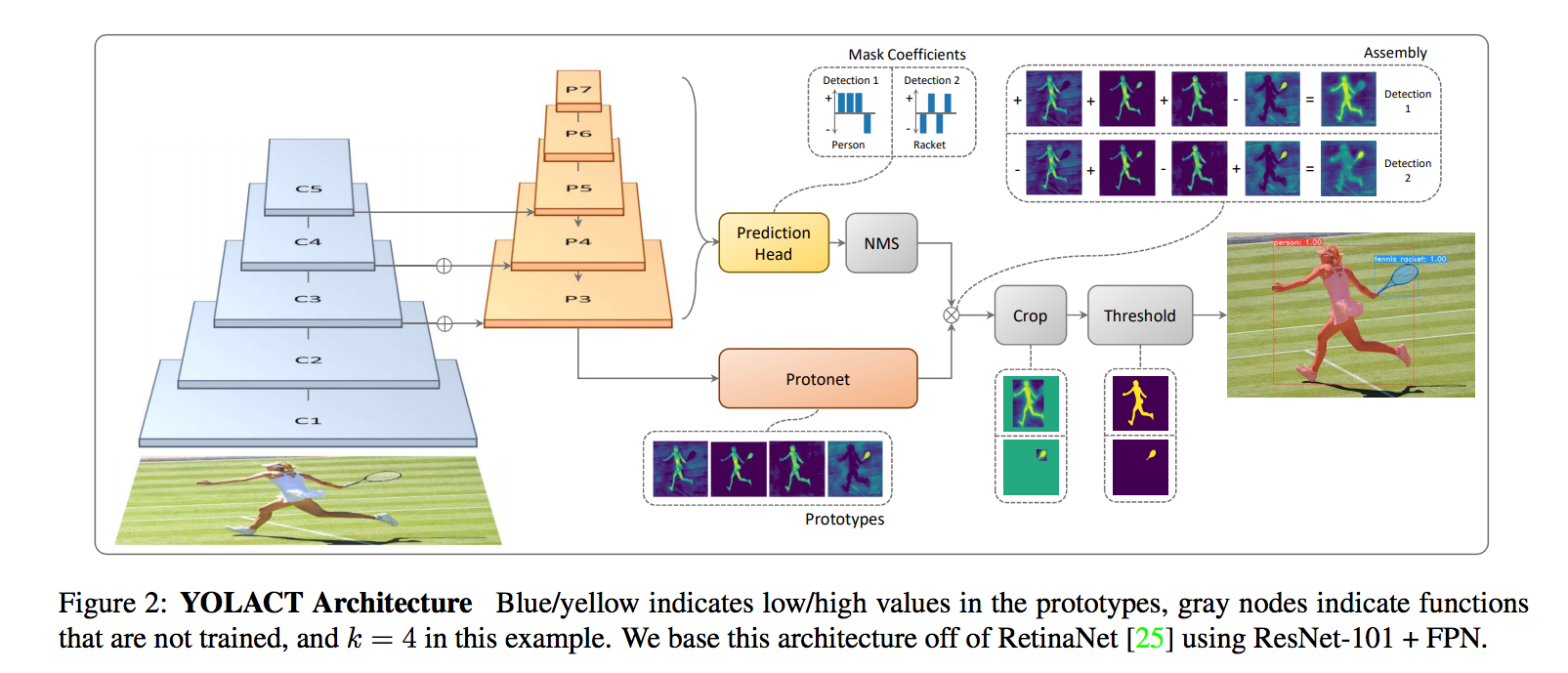
架構如上,
整體上是基於 RetinaNet(Backbone: ResNet-101+FPN)做小小的改良,
主要是分出上下兩個分支
- Prediction Head
- Prototype masks
Prediction Head
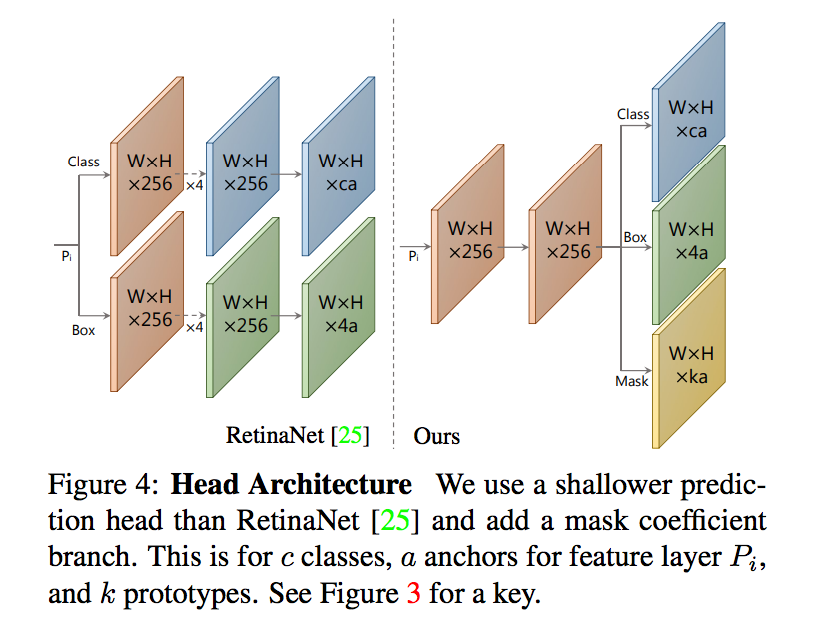
典型的 anchor-based 物件偵測模型會有兩個輸出
- 預測類別的機率 - c classes
- bbox - 4 classes
而本文增加了係數 mask coefficients
因此實際上的輸出為三個
- 預測類別的機率 - c classes,訓練時採用c+1(背景類別)
- bbox - 4 classes
- mask coefficients - k classes(對應到Prototype Masks的個數)
相較於 mask coefficients 輸出都為正數,
使用 mask coefficients 的輸出有 +- 的結果更好能組合出更多的選擇,
因此選用 tanh()

Prototype Masks
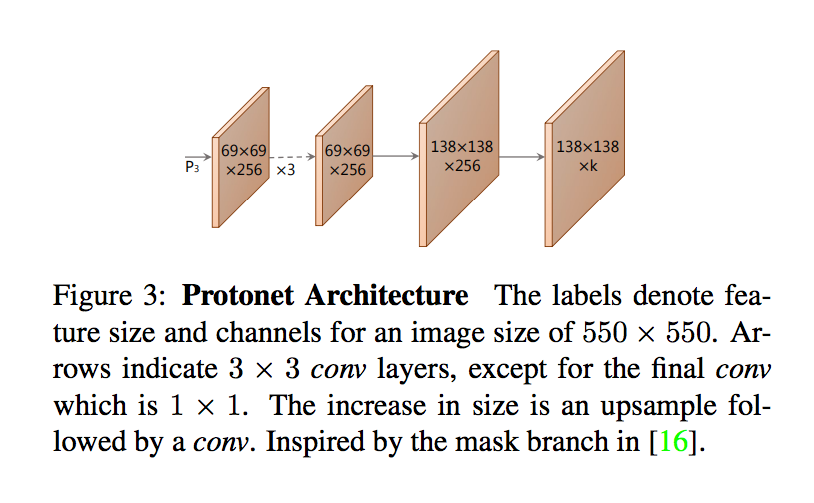
將 FPN 的 P3 輸入進 Protonet,
主要考量其一是該層是模型中最深層 layer,
能夠處理較為複雜的特徵,
其二是它有著較高的解析度,
因此對於較小的物件也會有較好的準確度。
輸出為 k 個 prototypes mask,
prototypes mask 並非與 Instance 對應,
需與 mask coefficients 搭配才能萃取出 Instance。
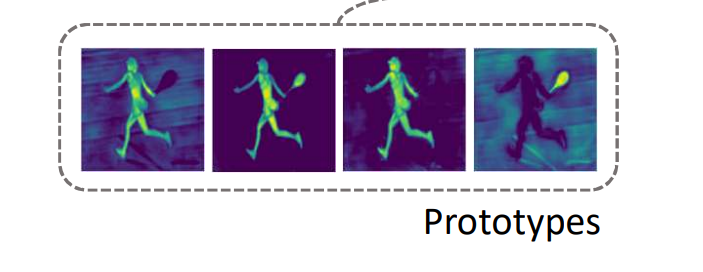
最終組合為 P(Prototype Masks) * C(Mask coefficients),
再經由 Sigmoid 輸出 0 ~ 1 的 mask
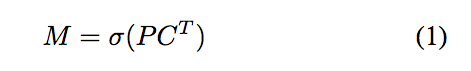
Prototype Behavior(04/16更新)
這部分挺有趣的,建議去看論文原文。
以 Fully Convolution 的特性有著平移不變性 - translation invariance,
而在 Segment 的問題上我們希望可以將空間的資訊保存好,
這樣我們分割的時候才能準確地在該 pixel 做分割。
以往 Mask R-CNN 是先做 RPN,
為了要得到精準的 Instance Segment 對 ROI 做 Repooling 的動作,
是為了要保持空間不變性所做的補強措施,
但是以此任務來說,我們所輸出的 Mask 是相當於 Image-Size 的大小,
並沒有額外做過 Translation 各種縮放等等的動作,
所以它保持著良好的空間資訊,也不需而外做處理,
只要將 Mask 與 Coefficents 做搭配即可得到結果,
所以做起來應該是更快的,
因為 Mask X 係數的範圍算完就有 Instance Segment,
再搭配 fc 所預測出的 class,
就完成了 Instance Segment 的結果,
但最終為了小物體的準確度,
還是有搭配 bbox 做裁切(唯一有做 Translation 的部分)。
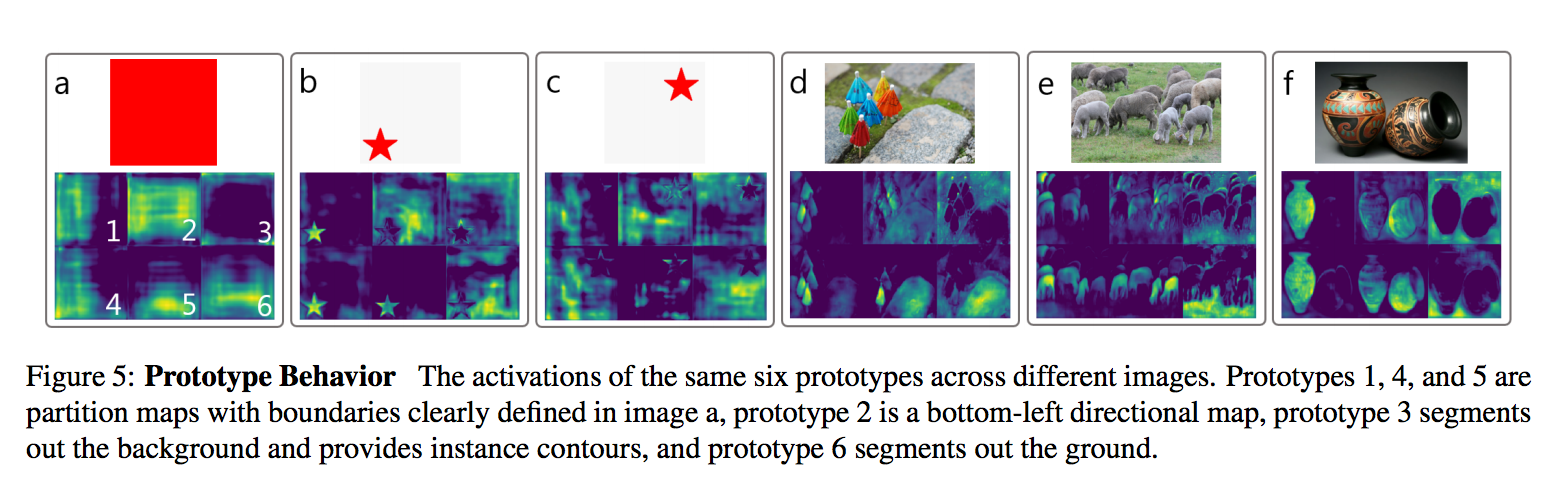
我們可以看一些例子來明白我們的 Mask 是如何運作的,
以左上角整個圖片都是紅色的例子來說,
單純以 FCN 不採用 padding 的情況下,
是不會有下面那 1 ~ 6 的結果的!!
因為如果輸入一樣的話,單純使用 Conv 出來的結果也會是一樣的!
因為 FCN 的特性是平移不變性。
但因為有 Padding 的動作,(舉例來說邊界 padding 0,但是整張圖片都是 1。)
讓 Prototype 有辦法學會邊界的距離這項特徵,
我們可以看到 a 圖的 1, 4, 5,
Prototype 有將整張圖拆分成左右或是上下兩部分。
這是經由一層一層的 layer 將邊界的資訊傳遞下去。
最終才有辦法學到將一張圖片切分成兩大部分。
雖然發現了 Prototype 有了平移敏感性的特性,
但作者在這段落寫著 Emergent Behavior(緊急行為),
或許未來能夠針對這個方法再做一個主題延伸!?
我們來看看 b 和 c 圖都是星星,但是擺放的位置不同,
會發現輸出的 Prototype 都長得不一樣呢。
除此之外藉由結合這些 Prototype 能得到不同的結果,
那如何結合就是依靠 mask coefficent 的係數決定,
舉例來說 d 圖的小雨傘,
我們可以透過 prototype 5 - prototype 4 來分割出小綠傘的部分。
prototype 3 學會的是前背景分離,
prototype 6 學會的是辨認地面的部分,
而我們也能發現每個 prototype 其實擁有的特性不只一個,
舉例來說 prototype 4 不只能把左右分開,還能將左下角的物件 highlight。
整體 Loss
- Loss cls - 分類
- Loss box - bounding box
- Loss mask - 比對我們最終的 Mask 與 GT 的物件Segment,單純做 BCE Loss,為了要讓尺度較小物件也能夠被準確的偵測,因此會先將各個物件的範圍使用 GT 的 bbox 先切出來再做比對。
- Loss seg - 將 P3 的 Feature maps 接上 1x1 conv 當作分類層輸出,用意在於增加特徵的豐富度。
Fast NMS
這部分這邊不提,有興趣自己看論文。
成果
第一張圖片的左上角,藍色車子沒有切好,此模型在太多相同類別或是尺度較小時表現不佳。