DLOW簡介 - Domain Flow for Adaptation and Generalization
Rui Gong, Wen Li, Yuhua Chen, Luc Van Gool. “DLOW: Domain Flow for Adaptation and Generalization”. In CVPR’19.
CVPR 2019 Paper
Paper link : https://arxiv.org/abs/1812.05418
Github (Apr.20.2019,尚未釋出) : https://github.com/ETHRuiGong/DLOW
前備知識
Cycle-GAN,
如果不清楚 Domain Adaptation 或是 Domain Shift 的,
可以先看我之前寫過的 AdaptSegNet簡介
簡介
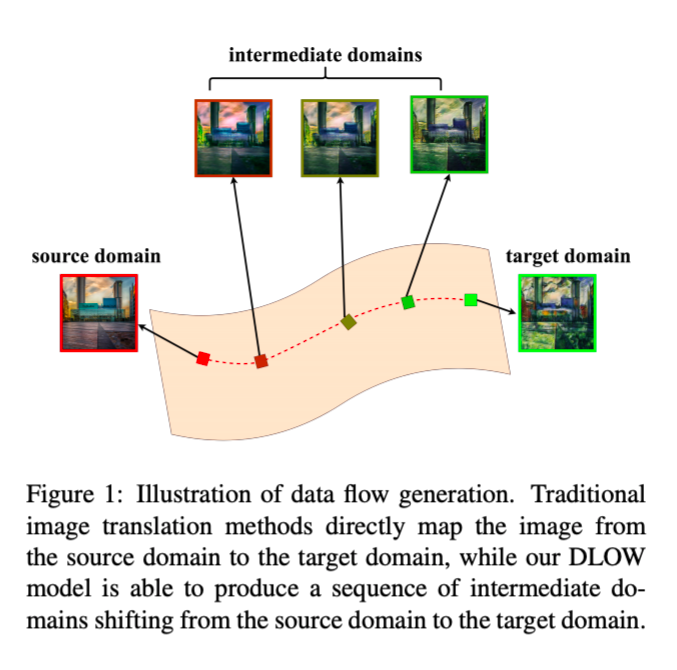
提出 DLOW - domain flow generation 來達成 Domain Adaptation 以及 Domain Generalization 的效果,
對於 Domain Shift 問題,
最簡單的想法是將 Source domain(S) 的畫風轉換為 Target domain(T) 的樣子,
這可以有效的減緩 domain shift 所帶來的傷害(降低準確度)。
本文提出的是產生介於 S 以及 T 之間的圖片來減緩 S 與 T 之間的 domain Shift 的差異,
這邊將它視為 Data Augmentation 可能更好理解。

因此主要想法是透過提出一個 Image to Image Translation Model 來達到上述的效果。
本文的 Image to Image Translation 是基於 Cycle-GAN 的延伸,
配合 AdaptSegNet:Learning to Adapt Structured Output Space for Semantic Segmentation 的方法。
突破之處:
- 圖片可產生介於 S ~ T 之間的圖片,
並非像以往 Cycle-GAN 以及 CyCADA(DA 的任務) 只是單純的轉換至 Target Domain。
- DLOW 可接受多個 Target Domain 的圖像,
超越 Cycle-GAN One-to-One 的轉換,
成為 One-to-Many 的圖像轉換,
藉此可生成出更多種不同風格的圖像,
甚至是混合不同 Domain 的圖像產生出沒看過的圖像,
以達成 Domain Generalization。
概念
基於 Cycle-GAN 作延伸,
原本是 Source Domain 與 Target Domain 轉換,
而現在我們希望能夠生成出 Source Domain 與 Target Domain 之間的圖片,
舉例來說 40% 的 Source Domain 與 60% 的 Target Domain。
而這邊的做法也很直覺,
加入一個常數 z in [0, 1] 來控制模型。
希望求得一個 M, 其介於與 S 的距離為 z 而與 T 的距離為 (1-z),
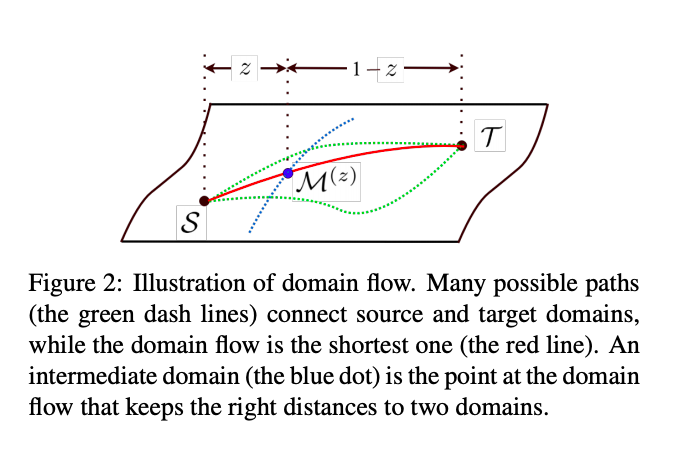
寫成式子變成
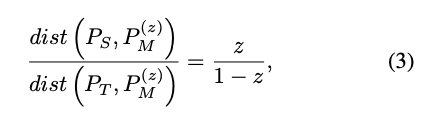
而訓練的方式其實是相像 Cycle-GAN,只是我們多了 z 這個權重
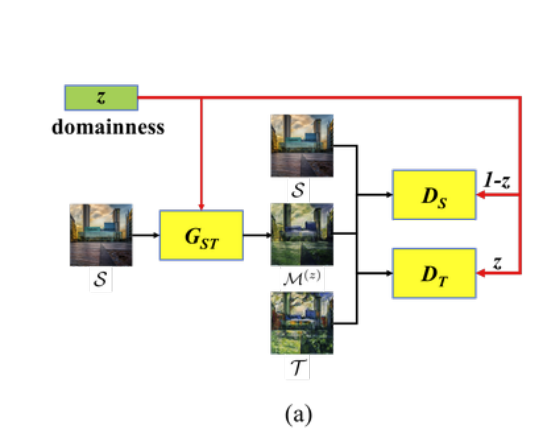
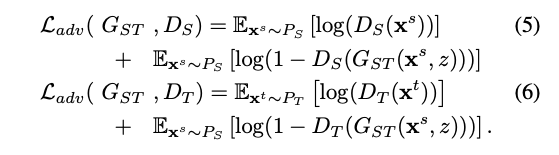
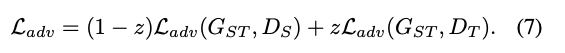
還有 L1 loss 來確保轉換後再還原還是相像的圖片
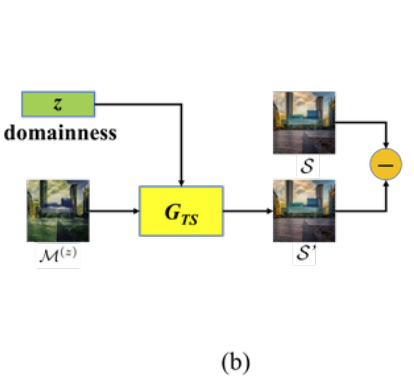
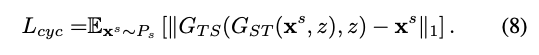
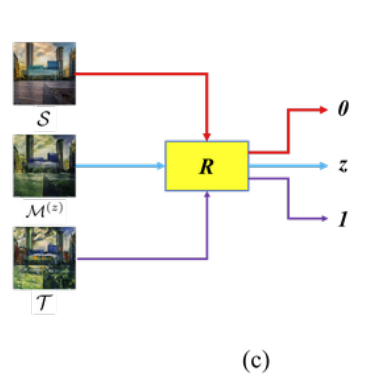
為了確保轉換後再還原的圖片還保有著 z 這個權重,
提出再訓練一個 Regressor - R 來評估
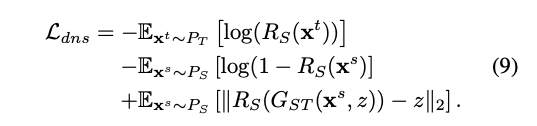
最終的 Objective Function
Domain Adaptation 部分
其想法是透過上面的方法生成介於 S ~ T 的影像 S˜ 來訓練模型,
藉此來緩和 S 與 T 之間的 Domain shift 問題。
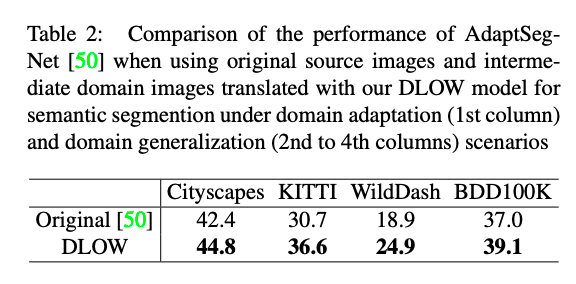
我們看看直接將 S 轉成 T (DLOW(z = 1)) 以及 生成介於 S ~ T 的影像 S˜ (DLOW) 來訓練模型的比較。
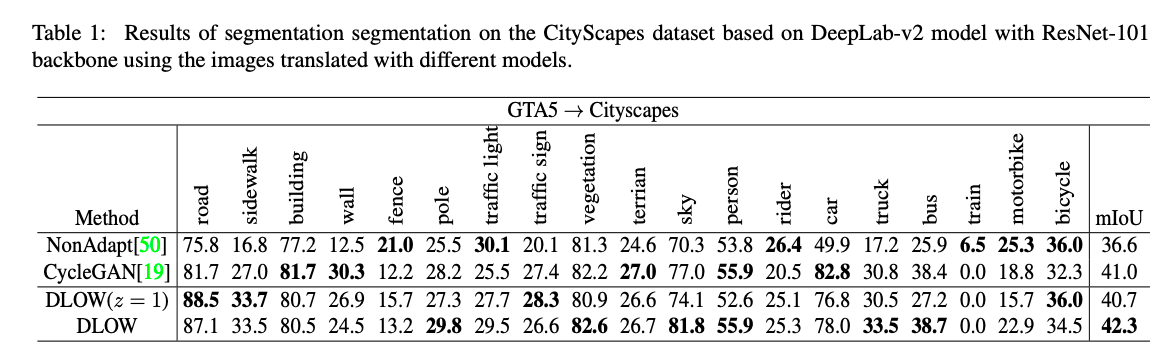
細節部分:
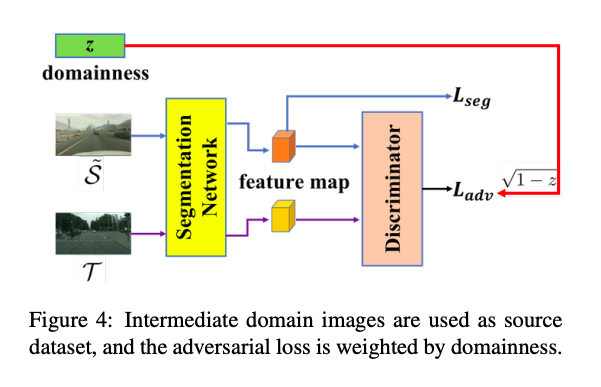
使用 Conditional Instance Normalization (CN) layer 將 z => [0, 1] 的參數加入至模型中。
在最後使用 sqrt(1-z) 當作權重去訓練 Adversarial loss,
當 z 越大時代表圖片越相像 Target Domain,那 adv loss 的權重就要小一點,
其實這邊論文沒有描述得太多,我看了也沒有很有感覺就是了。
Style Gerneralization 部分
許多現存的 Image-to-Image Translation 方法都只能夠轉換 2 個不同的 Domain,
而此文的 DLOW 架構可以訓練不同 Domain 的資料集,
想法也很簡單,原本我們給的 z 是個純量 scalar,
現在改成 Vector 的方式用 One hot encoding 的方式訓練即可,
因此公式如下

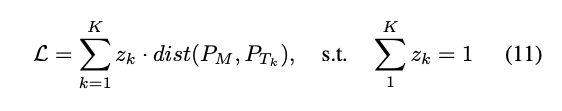
透過這個特性,我們可以設定不同 Domain 的權重,
藉此混搭出沒有看過的圖片。

成果
參考資料:
DLOW: Domain Flow for Adaptation and Generalization
AdaptSegNet:Learning to Adapt Structured Output Space for Semantic Segmentation