CLAN簡介 - Taking A Closer Look at Domain Shift Category-level Adversaries for Semantics Consistent Domain Adaptation
Yawei Luo, Liang Zheng, Tao Guan, Junqing Yu, Yi Yang. “Taking A Closer Look at Domain Shift: Category-level Adversaries for Semantics Consistent Domain Adaptation”. In CVPR’19.
CVPR 2019 Paper
Paper link : https://arxiv.org/abs/1809.09478
Github (Apr.24.2019,尚未釋出) : https://github.com/RoyalVane/CLAN
前備知識
如果不清楚 Domain Adaptation 或是 Domain Shift 的,
可以先看我之前寫過的 AdaptSegNet簡介
簡介
以往常見的 Domain adaptation 的方式是透過 GAN-based 的方法,
但是作者認為 GAN 是針對 Global alignment,
卻沒有考量到各個類別(Category-level)的情況去做調整,
舉例來說,有一些類別原本已經很相近了,
但 Discriminator 為了整體考量要去貼近那些不相近的類別,
卻讓某些原本已經相近的類別走遠了,
看下圖的上半部,
可以發現原本 + 的類別已經相似了,
但因為整體的考量往左上移動,
這時候卻造成 + 的類別相差得比原本還多
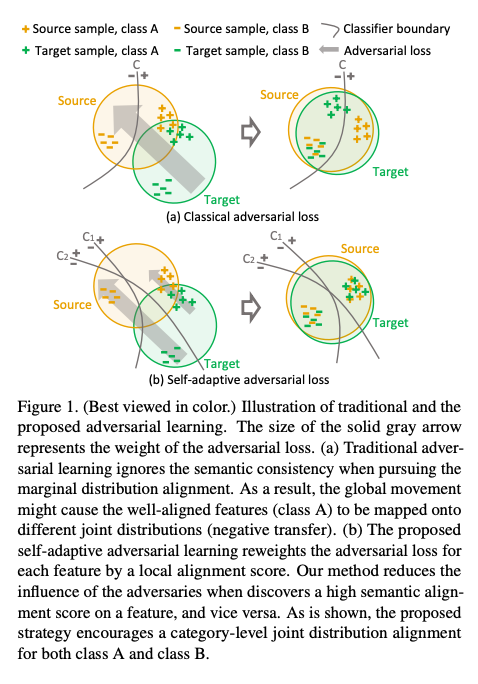
而此文提出的方式為上圖下半部的 Self-adaptive adversarial loss,
主要想法就是針對各個類別的情況,
去調整 loss 的權重。
從下圖可看橘色框框的部分,
原本 Non-adapted 的竿子可以準確的分類出來,
但使用傳統的 adversarial network(TAN)時,卻導致竿子的分類錯誤了,
而本文的 CLAN 仍然把竿子的部分準確的分類出來。
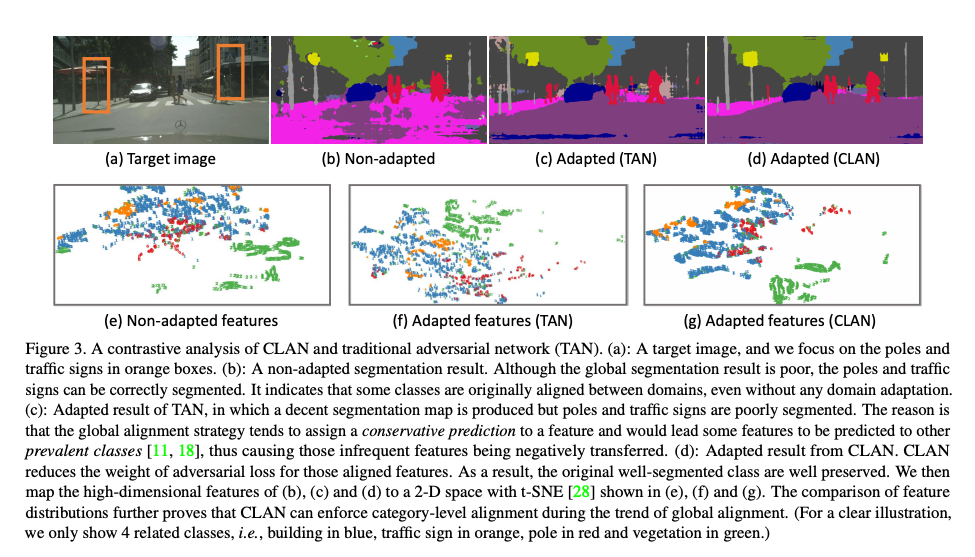
提出使用 co-training 的方式來得知各個類別是否貼近(align),
針對已經相差較多的類別給予較高權重的 adversarial loss,
而對於相近的類別權重就給低一點。
co-training 簡單來說可以說是訓練 2 個分類器,
當 2 個分類器的結果不一樣時,
可以理解成該類別的特徵是沒有貼近的,
導致兩個分類器的結果不同,
此時就給予較高的權重做訓練。
總結一下 CLAN 的想法
- 保護已經 well-aligned 類別的特徵,讓其不被 Global alignment 而影響到。
- 透過 Co-training 的方式得知 Feature 的語意(Semantic)特徵是否適用於 S 以及 T domain。如果兩個分類器的結果一致,表示模型對於 S 與 T Domain 的語意理解是相同的,那我們就會降低 Adversarial loss 的權重,避免學壞; 當分類器的輸出結果不一致時,表示模型對於 S 與 T Domain 的語意理解不同,此時就會增加 adversarial loss 的權重。
整體貢獻為
- 依據每個類別的特徵貼合(Align)情況,動態的調整權重,讓 Adversarial loss 可以有更好的貼合,透過此方式緩解 Domain shift 的問題。
問題設定
通常 Unsupervised domain adaptation (UDA) 在語義分割(Semantic segmentation)的任務中的定義如下
- Source Domain:圖片 Xs,有標注正解的圖片 Ys
- Target Domain:圖片 Xt,沒標注正解圖片
而常見的方法為 Traditional adversaries-based networks (TAN)
對於 Source domain 可以做 Segmentation loss
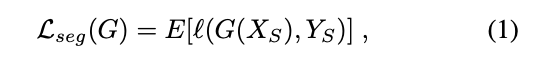
主要是依照 Discriminator 來讓 Source Domain 以及 Target Domain 的特徵分佈相同,因此寫作下方這樣。
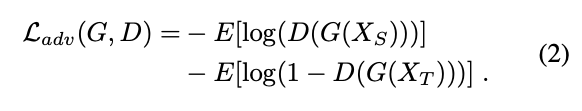
題外話:
他的 L_adv 的定義與常見的 DA 論文相反,
通常是 D(G(Xt)) 以及 (1-D(G(Xt))),
反正我主要就看看方法。
架構
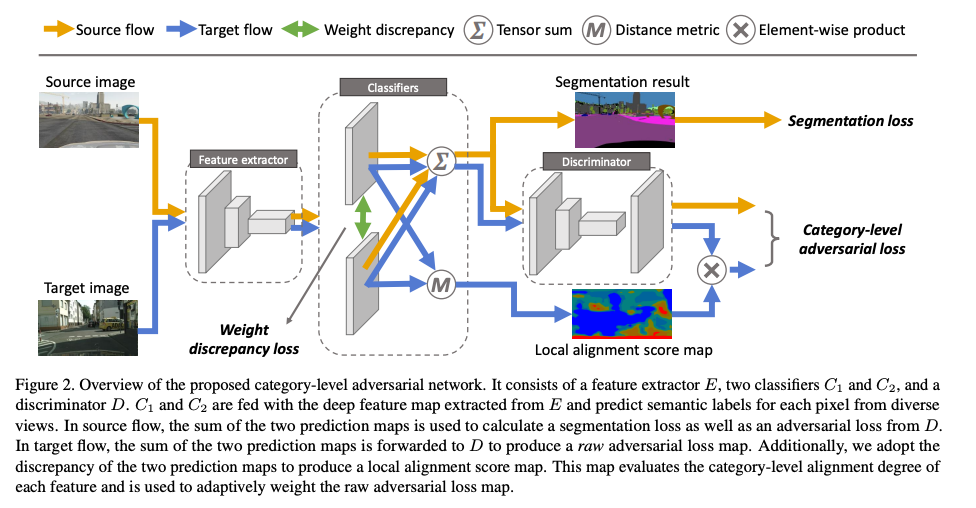
p = p(1) + p(2),這邊可以看做將分類器 ensemble。
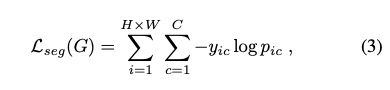
下方式遵循 co-training 的設定,
透過 Cosine distance loss 來強迫兩個分類器的 Kernal 權重不同。
當兩個 Kernel 的權重完全相同時為 1,各自獨立時為 0。
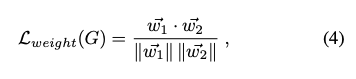
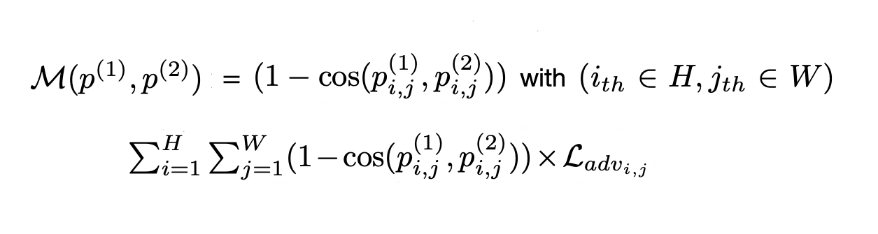
此為本文重點:Adaptively weight the adversarial loss。
M 可以看作測量 p(1) 及 p(2) element-wise 的差異,
這邊選用的 distance metric 為 cosine distance。
這部分就是看看他們 p(1) 及 p(2) 輸出的結果一致與否,
如果一致,adv loss 的權重調低,如果不同的話就會調高權重,
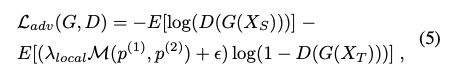
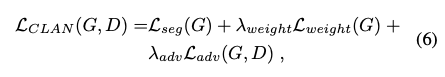
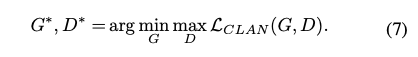
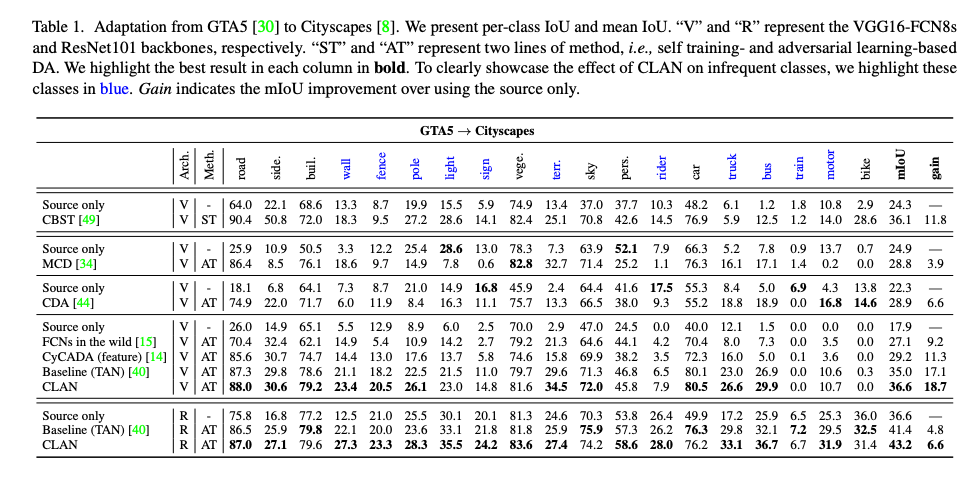
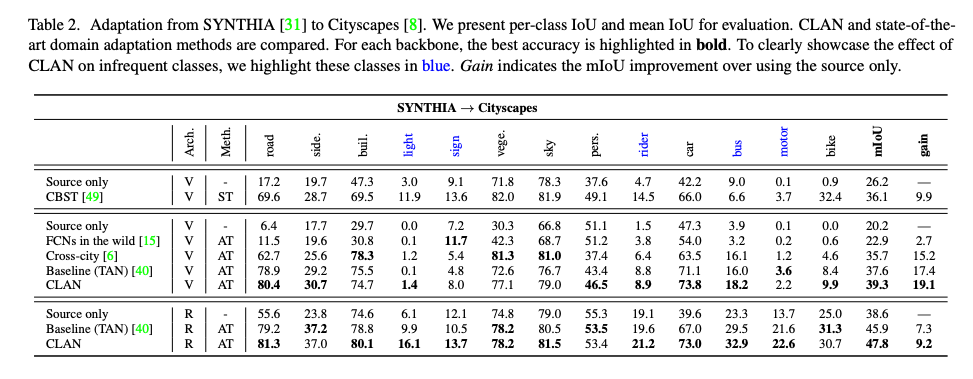
成果

參考資料:
AdaptSegNet:Learning to Adapt Structured Output Space for Semantic Segmentation