簡介 - Open Set Domain Adaptation by Backpropagation
Kuniaki Saito, Shohei Yamamoto, Yoshitaka Ushiku, Tatsuya Harada. “Open Set Domain Adaptation by Backpropagation”. In ECCV’18.
ECCV 2018 Paper
Paper link : https://arxiv.org/abs/1804.10427
簡介
此文針對 Open Set Domain Adaptation 問題進行研究,
以往 DA 的設定都是針對兩個資料集中相同/共有的類別(Closed-set)去做適應,
而本文的設定是採用 Open-set,
以往的 Open-set 的定義為 Source 及 Target Domain 都包含著未知的類別,
而本文的 Open-set 只考量 Target Domain 有著未知的類別(unknown)。
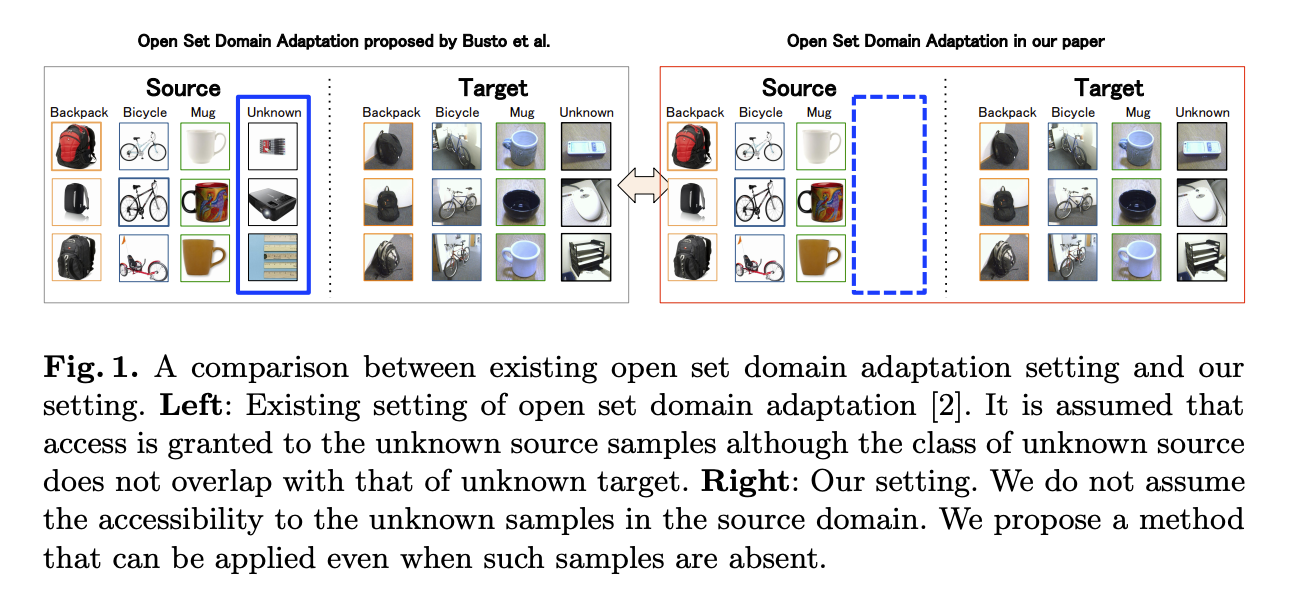
上圖左方為之前 Busto 提出的 Open-set 設定,Source domain 以及 Target domain 都有 Unknown。
上圖右方為此論文提出之設定,Source domain 並沒有 unknown 類別。
提出以往 Close-set DA 沒辦法很好的作用至 Open-set DA 的設定,
因此作者認為無法確定 Unknown 類別特徵是能夠貼近 Source Domain 的分佈,
希望在特徵萃取時,能夠將 Unknown 類別的特徵分佈遠離原有的類別(兩個資料集中相同/共有的類別)。
其論文主要想法是透過訓練一個分類器輸出 K + 1 個類別(+1 是指 Unknown),
我們會透過 Objective Function 讓 Feature exactor 與 Classifier 做對抗式的學習,
Classifier 目標是讓 Unknown 這類別的輸出機率符合我們所定義的 t(threshold),鼓勵猜測 Unknown。
Feature exactor 目標是讓 Unknown 的分佈遠離既有的 K 的類別,讓 Classifier 無法推估是否為 Unknown。
藉由兩者的對抗式學習使 Feature extractor 分離已知類別以及 Unknown 的類別(下圖 c),
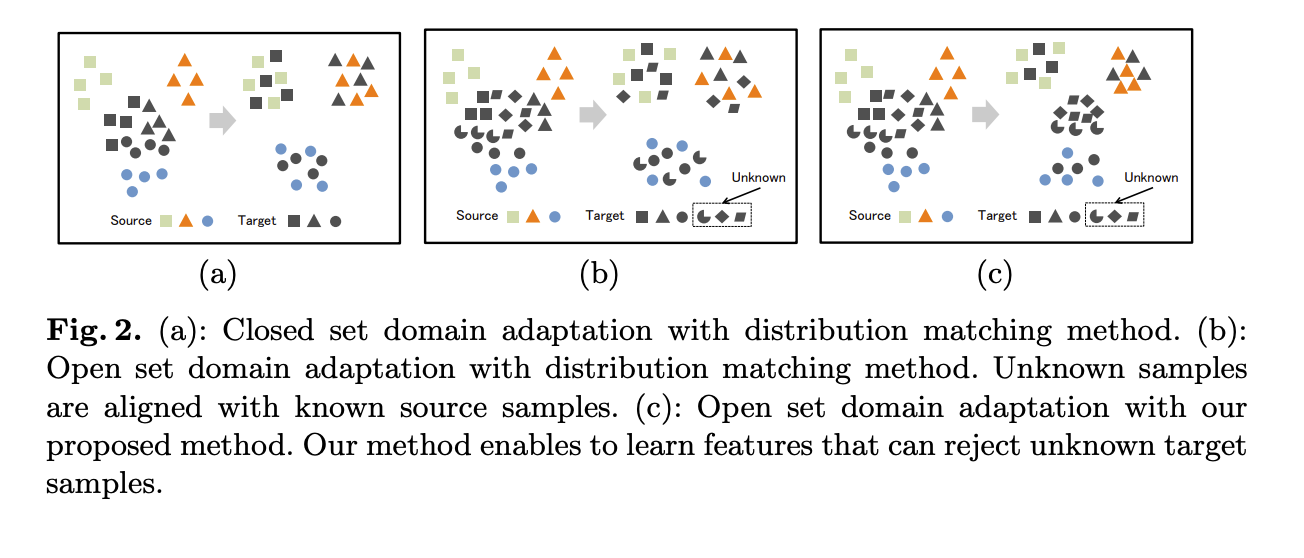
(a) Closed set domain adaptation ,兩資料集類別一樣,希望集中相同類別的特徵分佈
(b) Open set domain adaptation,有未知的類別,希望未知的類別也能對應至類似的類別。
(c) Open set domain adaptation - 本文方法,有未知的類別,希望將未知的類別遠離既有之類別。
本文貢獻
- 提出一個 Open-set DA 的方法,即便沒有提供 unknown 在 source domain,也能夠將 unknown 類別分開。
- 提出新的對抗式學習方法,可讓 Feature generator 分離已知及未知類別的特徵分佈。
- 在各種 DA 的資料集都證明了此方法可行
問題設定
通常 Unsupervised domain adaptation (UDA) 的任務中的定義如下
- Source Domain:圖片 Xs,有標注正解的圖片 Ys
- Target Domain:圖片 Xt,沒標注正解圖片
Closed set:兩者的類別相同
而此文特別的部分是 Open-set,
而此部分的 Open-set 定義如下
Source Domain 沒有 unknown 類別,
而 Target Domain 有 unknown 的類別,
因為作者認為在 Source Domain 收集 Unknown 的資料是非常麻煩的,
收集 Unknown 類別需要一定的資料量還要考量是否有多樣性。
架構
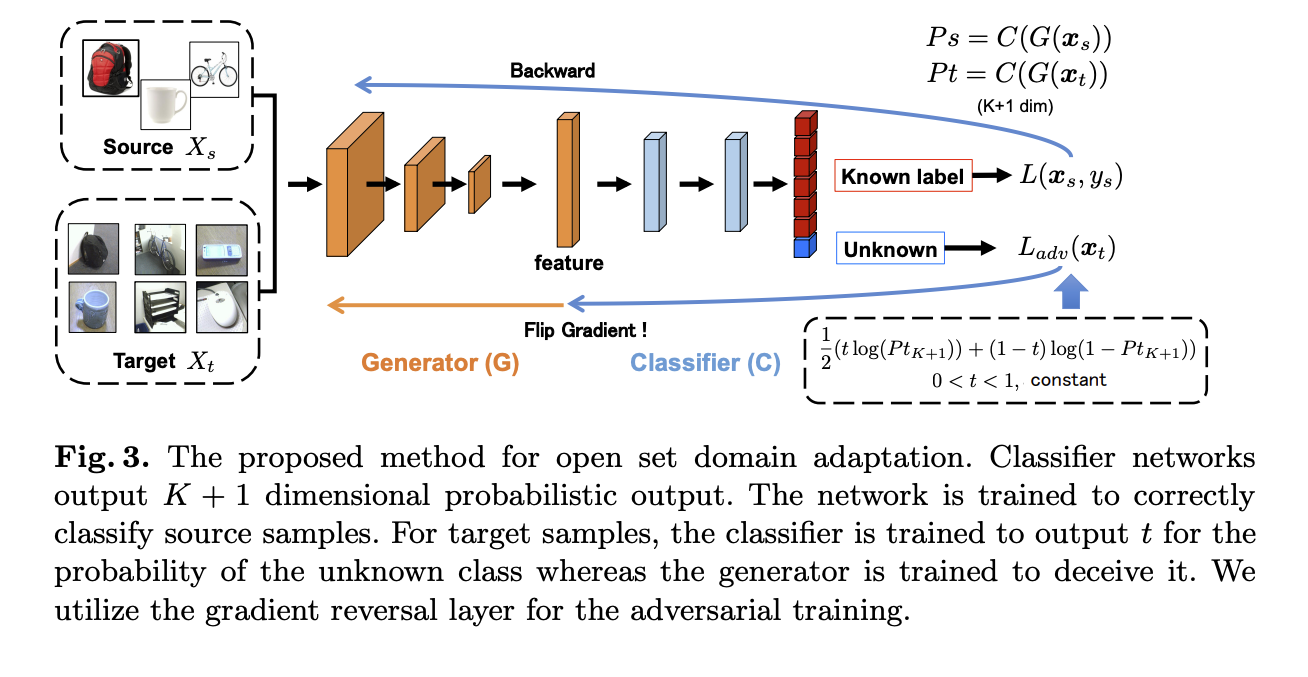
模型架構有兩個部分
- G : Generator(Feature exactor)
- C : Classification
架構很簡單,特別的地方是分類器是分出 K + 1 個類別(+1 指的是 Unknown 類別)
訓練時主要是經由 Source domain dataset 去做訓練,
使用 Source Domain 的 GT 去做 cross-entropy loss,
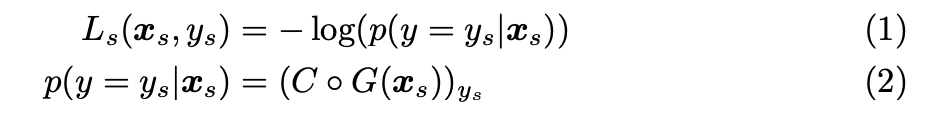
而 Target Domain dataset 被用作訓練未知類別 - Ladv,
其想法是使用分類器來辨別是否為 Unknown label,
透過 binary cross entropy function 來訓練 C 能將 Unknown 類別靠近邊界(0.5),
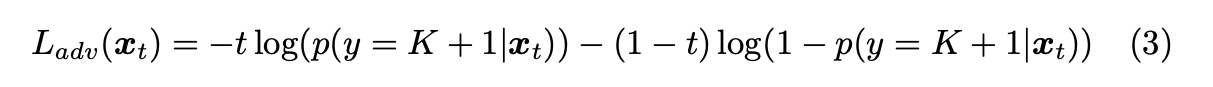
Note: t = 0.5
Ladv 當分類器的輸出 p 為 t 時, Ladv 才會最小。
Objective Function
上述的 Ladv 透過 binary cross entropy function 來將訓練 Unknown 類別靠近邊界(0.5),
但我們換個想法,這樣算出來是算出 gradient 靠近邊界,
因此我們只要把 gradient 反向,就是遠離邊界。
其概念為讓 C -> Classifier 努力將 Unknown 輸出 p 趨近於 t 的機率(t 設為 0.5 作為邊界),
讓 G -> Feature exactor 朝著 loss_adv 的反方向訓練(即為遠離邊界,拉開已知以及未知類別的分佈),
透過這樣的訓練達到對抗式學習的目的,
最終期望 G 可達成拉開已知以及未知類別的分佈。
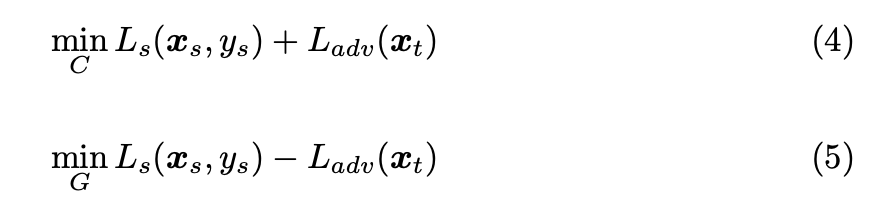
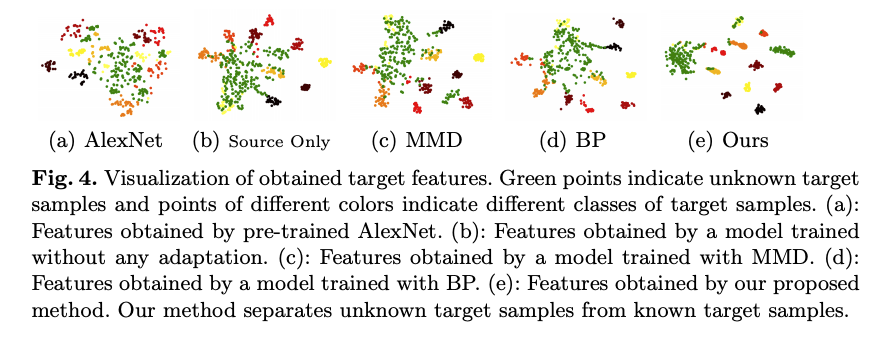
整體的訓練演算法如下,

最終整體的分佈會像下圖,
綠點為 Unknown,
我們希望綠點可以盡量的遠離其他群體,
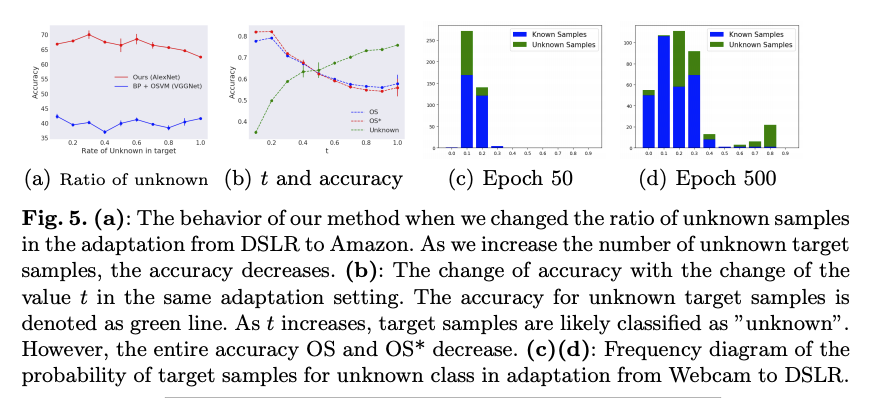
上圖 (b) 測試 boundary t 應該要設定在哪個值,
當 t = 0.5 時,有個黃金交叉。
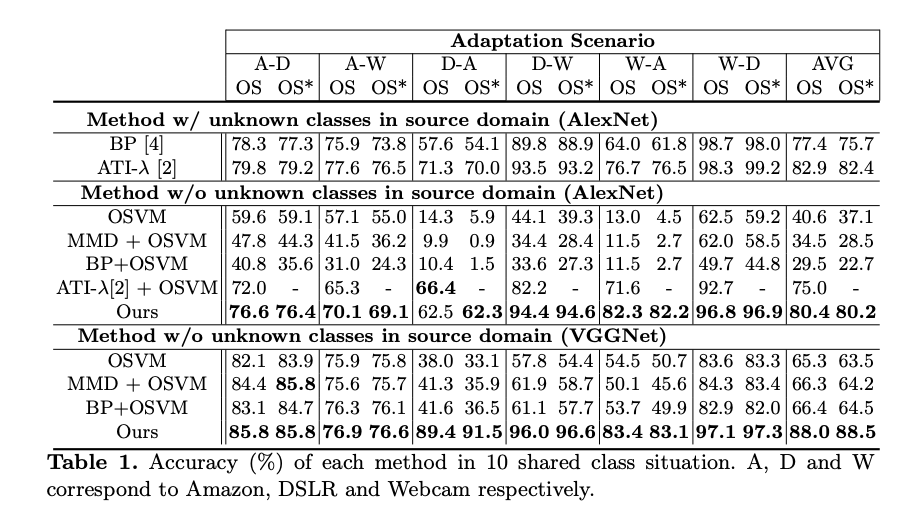
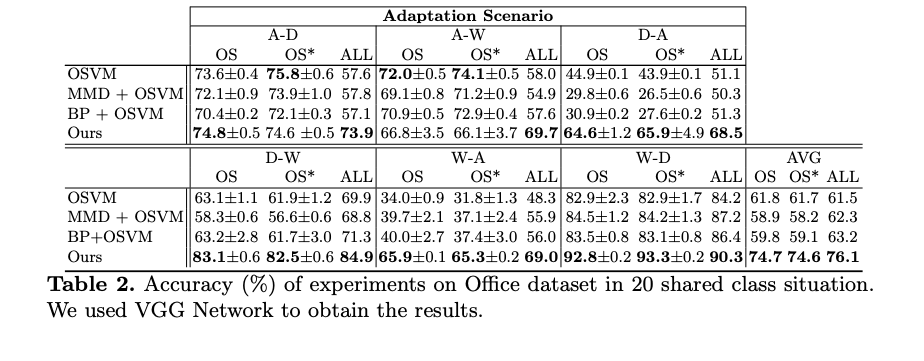
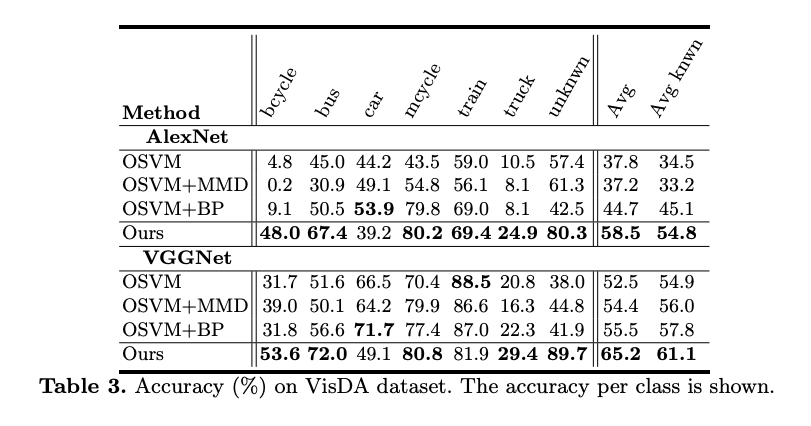
此時 Source domain(OS) / Target domain(OS * ) / Unknown 的準確度都不錯。
只是說撇開 Unknown 這個類別的話,
當 t = 0 時, OS 和 OS * 的準確度都最高,
至於這特性,可以想一下可以用在哪。
上圖 (c, d) 可發現訓練到後來,可以準確地將 Source domain 的資料分在 Unknown < 0.5 的部分,
但還是有些 Unknown 的資料被誤分在了 < 0.5。
成果