Self-ensembling DA簡介 - Self-ensembling for visual domain adaptation
Geoffrey French, Michal Mackiewicz, Mark Fisher. “Self-ensembling for visual domain adaptation”. In ICLR’18.
ICLR 2018 Paper
Github Code : https://github.com/Britefury/self-ensemble-visual-domain-adapt
Paper link : https://arxiv.org/abs/1706.05208
簡介
此文針對 Domain Adaptation 的任務做探討,
在 Domain Adaptation 的任務中會有兩個資料集 Source 及 Target Domain,
Source Domain 有圖片(Xs)以及標註(Ys - GT),
而 Target Domain 只有圖片(Xt)沒有標註,
希望能夠藉由 Domain Adaptation 的方式,
讓模型能在 Target Domain 也能表現良好,
難處是因為 Source Domain 可能是合成的資料集,其顏色、外觀和現實世界的圖片有著落差。
所以直接套用至真實世界的資料集 - Target Domain 時準確度往往會下降很多。
而本文提出 Self-ensembling 的架構就是為了緩解這問題所提出的 Domain Adaptation 方式。
Self-ensembling 主要是透過改良 Semi-supervised 的方法,

架構
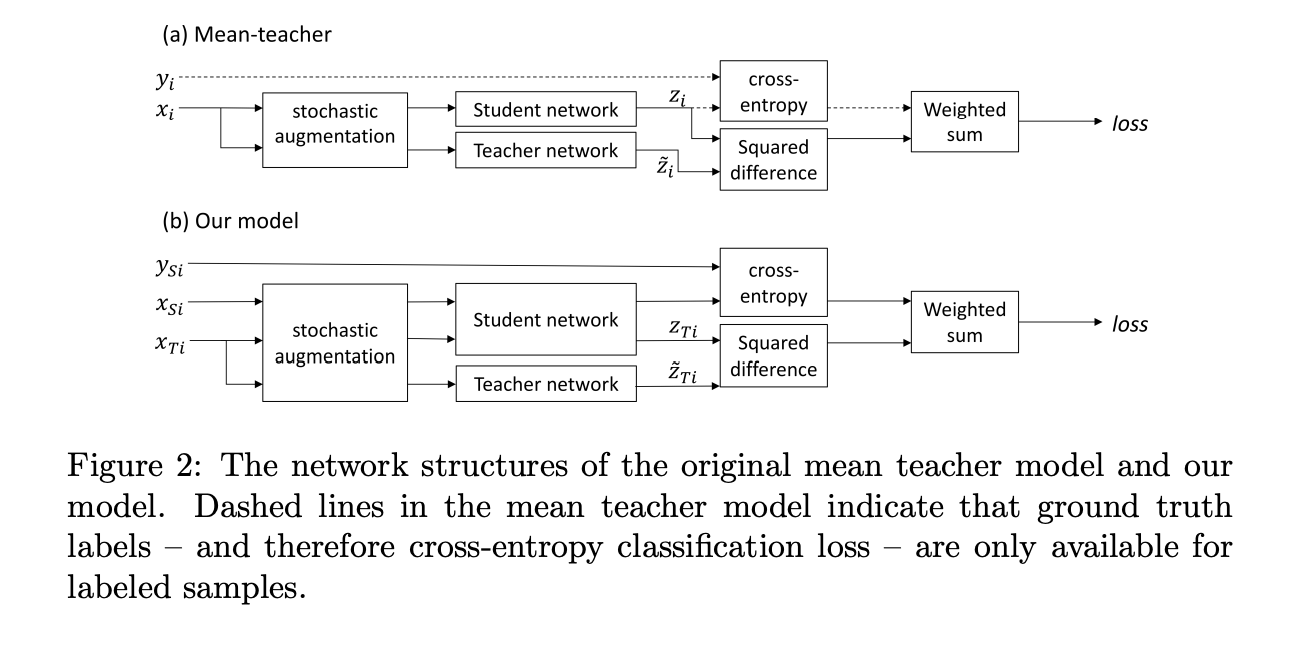
基本上就是承襲 NIPS’17 - Mean teachers are better role models: Weight-averaged consistency targets improve semi-supervised deep learning results,
整體的訓練方法與 Mean teachers 那篇論文差不多,
而本文將架構調整為應用於 Domain Adaptation 的任務,
將原本的架構結合 Target Domain 的部分,見上圖可明白差異,
Self-ensembling 主要是有兩個部分
- Student => 輸出稱作 z
- Teacher => 輸出稱作 z^
我們會使用 Source Domain Dataset 對 Student 的輸出(z)進行 Supervised 的訓練 - Cross-entropy loss(Supervised),
再使用 Source 以及 Target Domain Dataset,
希望兩個模型能夠輸出一致的結果(z 及 z^) - Self-ensembling loss(Unsupervised),
Mean-square-loss 用來確保兩個輸出要相似。
其概念為當 Teacher 模型能夠很肯定的說這張 Target Domain 的圖片是屬於哪個類別的話,
Teacher 就會透過 Self-ensembling loss 去訓練 Student,
讓 Student 慢慢適應至 Target Domain,
這樣一想就和 Semi-supervised 的任務真像呢~
Note:
1.其訓練過程為輸入同一張圖片(x)至兩個相同架構的模型,雖然輸入同一張圖片,但輸入至 Student / Teacher 時會經過不同的 batch normalize, droupout, noise, image augmentation 等等的設定。
如果對這部分想了解的更深入的可以看 Mean teachers are better role models: Weight-averaged consistency targets improve semi-supervised deep learning results。
Confidence thresholding
如果 Teacher 預測出的結果 probability < 0.968,
就將 Self-ensembling loss 設定為 0,
概念為當預測機率不夠高的話,
我們沒辦法確保預測出來的結果是準確,
可能會造成反效果,所以就不會給學生進行訓練。
Data augmentation
- 水平翻轉
- 圖片位移 [-2, +2]
- 高斯雜訊
實驗結果是 水平翻轉 以及 圖片位移 對準確度有比較顯著的提升。
圖片加入高斯雜訊的公式,
整篇論文唯一的公式呢。。。
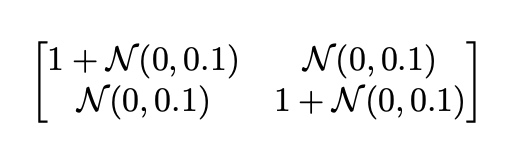
Class balance loss
主要是為了解決 SVHN 的圖片資料集中,
有某個類別過多的問題。
對每個 Target domain 的輸入 - N張圖片,
簡單來說就是看預測出來每個類別的機率,
如果那一個 batch 的某個類別機率太高,
就給懲罰 balance loss,
會將這 loss 當作權重如 0.75 乘上 self-ensembling loss。
成果
